Servizi di ripristino di emergenza
Il recupero dei dati di cui è stato eseguito il backup è, per ovvi motivi, una funzionalità standard dei servizi di backup. Una situazione di emergenza non è tuttavia limitata alla perdita di dati. Un'interruzione che impedisce ai server di un'organizzazione, che siano reali o virtuali, locali o basati sul cloud, di essere disponibili influisce sull'organizzazione in modo negativo, a volte anche irreversibile. Lo scopo di un servizio di ripristino di emergenza è fornire un backup non solo per i dati e per le singole risorse, ma per interi sistemi in modo che, se questi sistemi vengono disattivati o passano offline, il servizio possa essere ripreso reindirizzando il traffico alle repliche in standby pronte a gestire il carico.
Il vero scopo del cloud pubblico è dimostrato proprio dal ripristino di emergenza. Non si tratta solo di un'enorme unità nastro. Poiché le risorse cloud sono virtuali, le repliche possono essere attivate in un attimo per sostituire le risorse improvvisamente non più disponibili. Le repliche possono anche essere ospitate in parti del mondo diverse da quelle dei sistemi di cui eseguono il mirroring per ovviare alle interruzioni a livello di area. Inizia a diventare evidente il contrasto tra le spese necessarie per mantenere repliche fisiche di sistemi informatici fisici (per di più in località geografiche diverse) e il valore del cloud nel mantenere la continuità di questi sistemi.
I principali provider di servizi cloud offrono il ripristino di emergenza distribuito come servizio, ma questi servizi devono essere volutamente pianificati e configurati per fornire il supporto del failover desiderato dai clienti. Si inizierà quindi con l'esaminare gli obiettivi e le metriche utili per tale pianificazione.
Obiettivi e metriche
Durante un evento di emergenza, un'organizzazione e i clienti potrebbero perdere l'accesso a più classi di asset digitali simultaneamente, le più importanti delle quali sono:
Database e archivi dati, che oltre a registrare informazioni essenziali su clienti e beni e/o servizi in un inventario, mantengono lo stato attivo delle transazioni e dei processi aziendali per l'intera organizzazione
Dati in blocco, inclusi documenti, file multimediali e altri record salvati che sono i prodotti delle applicazioni usate dalle persone
Comunicazioni e connettività con persone e servizi aziendali, includendo quindi la parte essenziale di qualsiasi attività aziendale possa essere intrapresa
Applicazioni, che rappresentano le vetrine dell'organizzazione per clienti e membri, oltre che per gli stakeholder
Anche se il ripristino di emergenza viene presentato ai clienti come servizio singolo, il processo di ripristino per ognuna di queste classi è separato dagli altri. All'epoca dei client/server, molte organizzazioni conducevano le proprie attività quotidiane sui personal computer. Se un PC smetteva di funzionare ed esisteva un'immagine di backup nella risorsa di archiviazione locale del PC, in teoria era possibile ripristinarla in un nuovo PC e continuare a lavorare. Con i primi PC in rete connessi da sistemi operativi LAN e cavi Ethernet, era possibile ripristinare tutti i PC della rete da un'immagine di backup e quindi riprendere la rete stessa.
Il cloud non funziona in questo modo. Neppure una macchina virtuale che funge da server per le applicazioni di un'organizzazione incapsula interamente alcuna parte del lavoro svolto. I servizi di backup forniscono reti di sicurezza per i dati in blocco e, in modo limitato, per i dati transazionali e i database. Ognuna di queste entità è tuttavia un componente a sé, quindi per il ripristino delle funzioni aziendali durante un'emergenza è necessario riattivare la maggior parte delle funzionalità, se non tutte, di ognuno di questi componenti da una posizione protetta e sicura.
Il processo di ripristino di emergenza richiede quindi il coordinamento tra ognuna delle procedure intraprese perché un'organizzazione torni a essere completamente operativa. La natura delle attività svolte durante questo periodo è oltretutto più critica proprio in virtù della situazione di emergenza. Un evento in grado di arrestare l'infrastruttura critica ha probabilmente danneggiato altri aspetti funzionali della società, ovvero il magazzinaggio, la spedizione, la produzione e la distribuzione. È probabile che per ripristina l'attività, non sia sufficiente una semplice ripresa dell'attività svolta prima dell'evento di emergenza.
Ciò che accomuna queste procedure è la presenza di obiettivi condivisi e chiaramente definiti a livello di servizio. I servizi di ripristino di emergenza di AWS e Azure, oltre ai servizi di terze parti basati su Google Cloud, si distinguono per le caratteristiche seguenti:
Obiettivo del punto di rispristino (RPO): quantità minima consentita di dati che devono essere ridistribuiti ai clienti perché il servizio basato sugli asset di cui è stato eseguito il backup possa essere considerato recuperato. Al contrario, questa quantità può essere considerata la perdita massima accettabile di dati, espressa come percentuale sottratta da 100.
Obiettivo del tempo di ripristino (RTO): finestra temporale massima consentita per l'esecuzione di un processo di ripristino. Può anche essere considerata una misura del tempo massimo di inattività che l'organizzazione può permettersi.
Periodo di conservazione: periodo di tempo massimo consentito per la conservazione di un set di backup prima che sia necessario aggiornarlo e sostituirlo.
RTO e RPO potrebbero essere considerati bilanciati tra loro e un cliente potrebbe decidere di consentire tempi di ripristino più lunghi per ottenere punti di ripristino più elevati. Se il tempo di ripristino è un problema per un cliente a causa della larghezza di banda disponibile o del rischio derivante dal tempo di inattività, il cliente potrebbe non riuscire a raggiungere un obiettivo RPO elevato.
È probabile che un consulente della gestione dei rischi o un consulente della business continuity professionista suggerisca di basarsi su queste tre variabili per formulare i criteri di ripristino di emergenza. Nella maggior parte dei report di analisi di impatto aziendale, RTO e RPO si collocano al primo posto. Si tratta di variabili critiche nelle valutazioni dei consulenti relative alle potenziali perdite derivanti da eventi di emergenza. Alcuni consulenti usano una variabile aggregata denominata obiettivo a livello di servizio, anche se non esiste ancora un'unica formula per raggiungere tale obiettivo. La capacità dei provider di servizi cloud di specificare i livelli di servizio usando una terminologia già conosciuta e apprezzata dai consulenti semplifica la collaborazione tra le due parti, che spesso è ciò che spinge le organizzazioni a scegliere determinati provider di servizi di ripristino di emergenza.
Metodologie e procedure
Nella lezione precedente è stata illustrata la forma più semplice di ripristino del sistema informatico, che prevede il backup dei file pertinenti, dei volumi di archiviazione e delle immagini delle macchine virtuali. Anche se questa forma di ripristino continua a essere presentata come un'opzione del servizio di ripristino di emergenza, nella pratica si applica a sempre meno organizzazioni, principalmente perché gli obiettivi RTO non possono essere mantenuti in modo adeguato.
I servizi di ripristino di emergenza professionali offrono varie metodologie per la distribuzione e la gestione, alcune delle quali prevedono la manutenzione del servizio prima che si verifichi un evento di emergenza. Queste metodologie sono riepilogate di seguito. Tutte e tre si basano sulle varie opzioni di backup descritte nella lezione precedente e sono ugualmente applicabili a tutti i provider di servizi. Un cliente che vuole abilitare una di queste modalità di ripristino sceglierà le classi di replica, georilevazione e archiviazione più adatte a tale modalità.
Fiamma pilota
Con questa metodologia (figura 5), è possibile creare un data center in standby completo. In questo caso, alcuni servizi e applicazioni principali, insieme ai dati che li supportano, vengono mantenuti in un cluster di failover che può essere "acceso", spesso automaticamente, nel momento in cui si verifica un evento di emergenza. Nel frattempo, i server virtuali vengono distribuiti solo con le funzionalità di base necessarie a mantenerli attivi nell'eventualità che vengano chiamati. Questi server con funzioni ridotte possono essere dotati di funzionalità di posta elettronica e Web, per consentire le comunicazioni con i clienti oltre che all'interno dell'organizzazione. L'abilitazione di una modalità di ripristino di tipo "fiamma pilota" può richiedere la sincronizzazione continua degli archivi dati volatili, come i database transazionali e i volumi di posta elettronica.
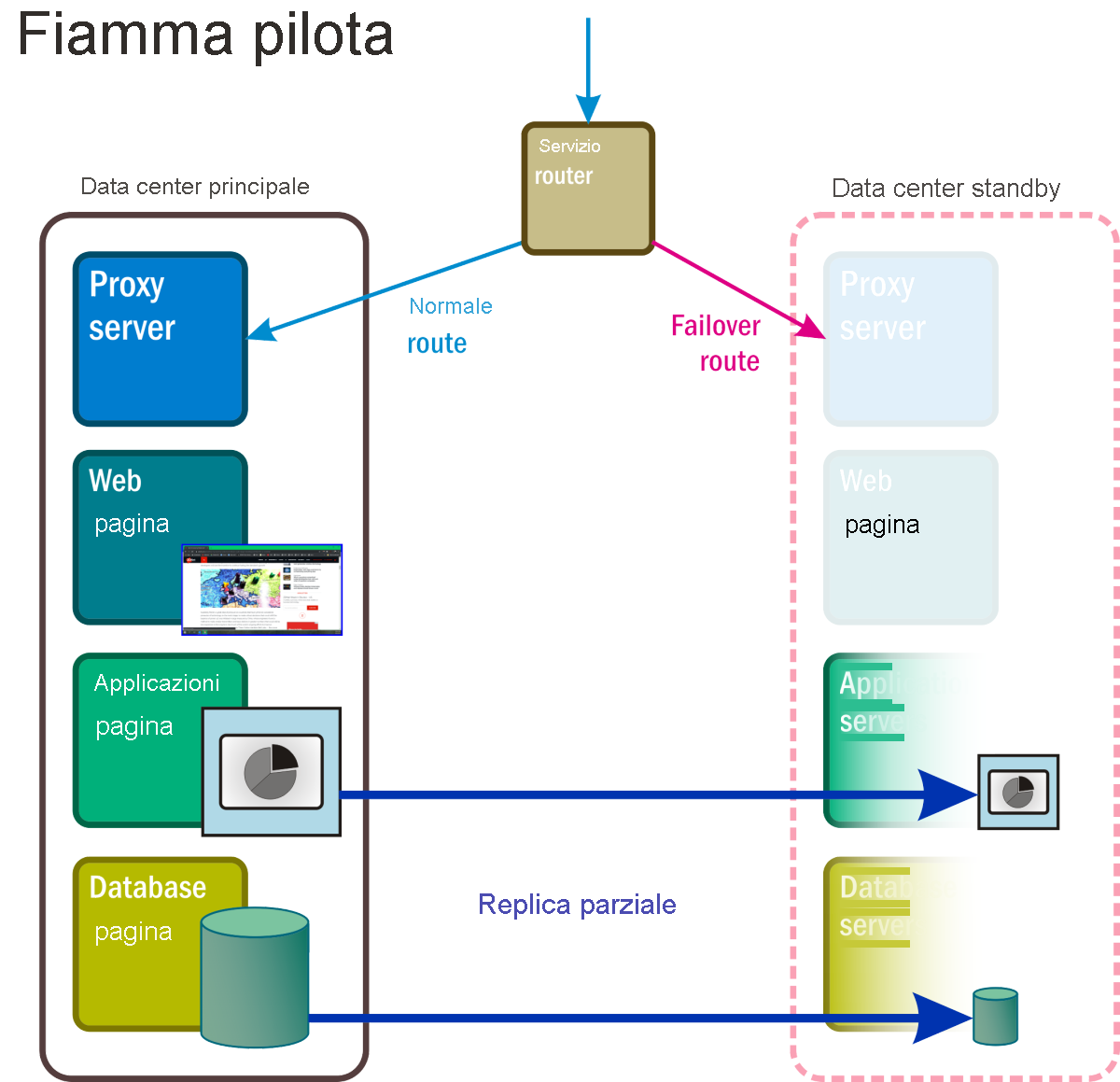
Figura 5: Componenti attivi e passivi di uno scenario di ripristino della luce pilota.
Warm standby
In questa modalità di ripristino, illustrata nella figura 6, le repliche in continua esecuzione di tutti i servizi e le applicazioni di sistema e di tutti i dati aziendali critici vengono mantenuti in almeno una posizione geografica separata. L'accesso a questa replica completa viene ignorato dal router attivo fino a quando l'evento di emergenza non attiva una regola che sostituisce l'indirizzo della rete attiva con quello nella route di bypass.
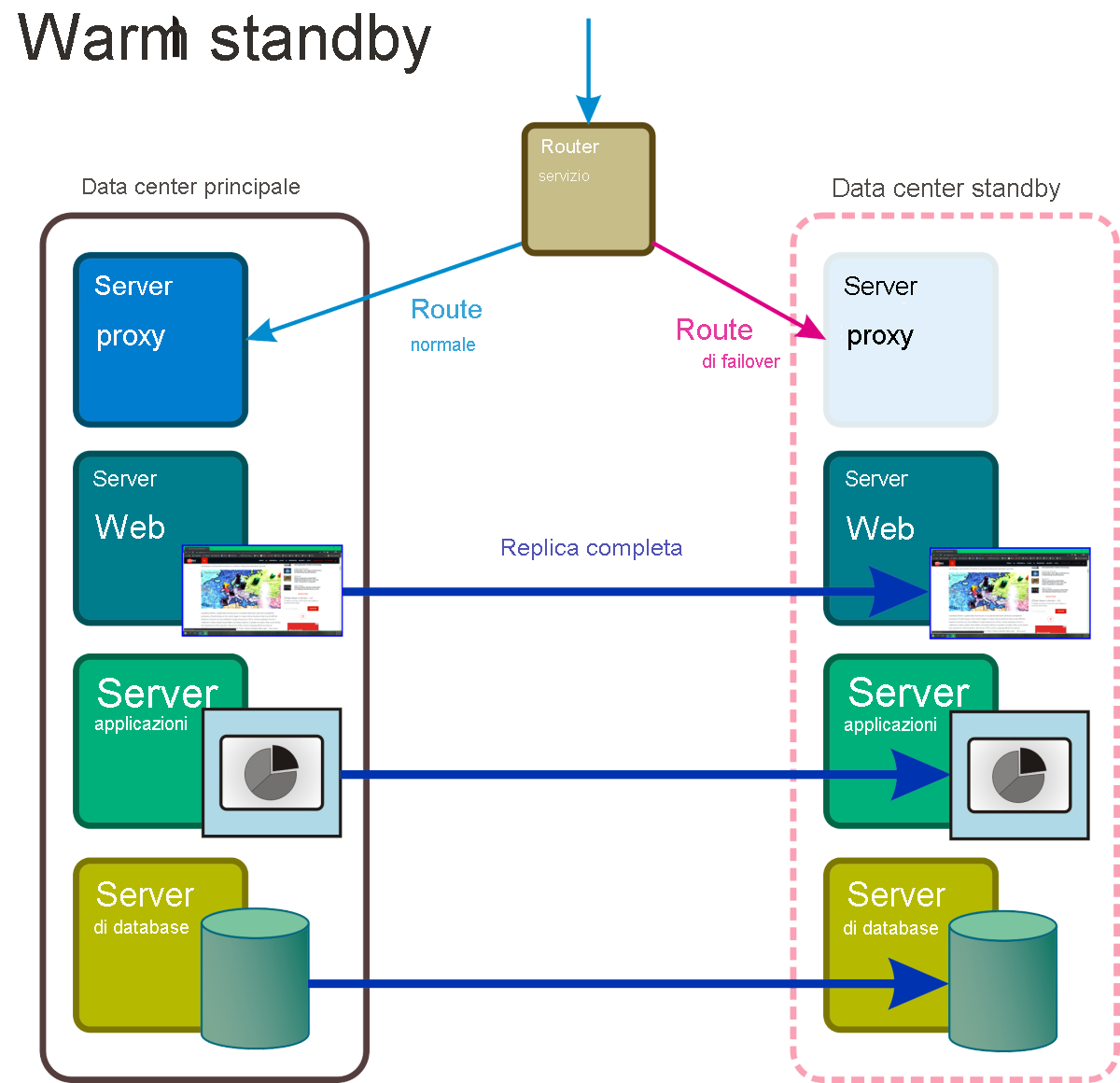
Figura 6: Scenario di ripristino warm standby con alcuni componenti nello spazio dei nomi standby completamente operativo.
Hot standby
In questo scenario (figura 7), almeno due repliche complete di tutti i servizi e di tutte le applicazioni sono sempre in esecuzione, con la sincronizzazione dei dati completa e continua tra di esse. Un router master viene usato come una sorta di servizio di bilanciamento del carico di grandi dimensioni, che distribuisce le richieste a tutti i percorsi del server in proporzioni più o meno uguali. L'occorrenza di un evento di emergenza attiva un processo simile a un firewall in cui l'indirizzo del sistema interessato viene rimosso dalla tabella di routing.
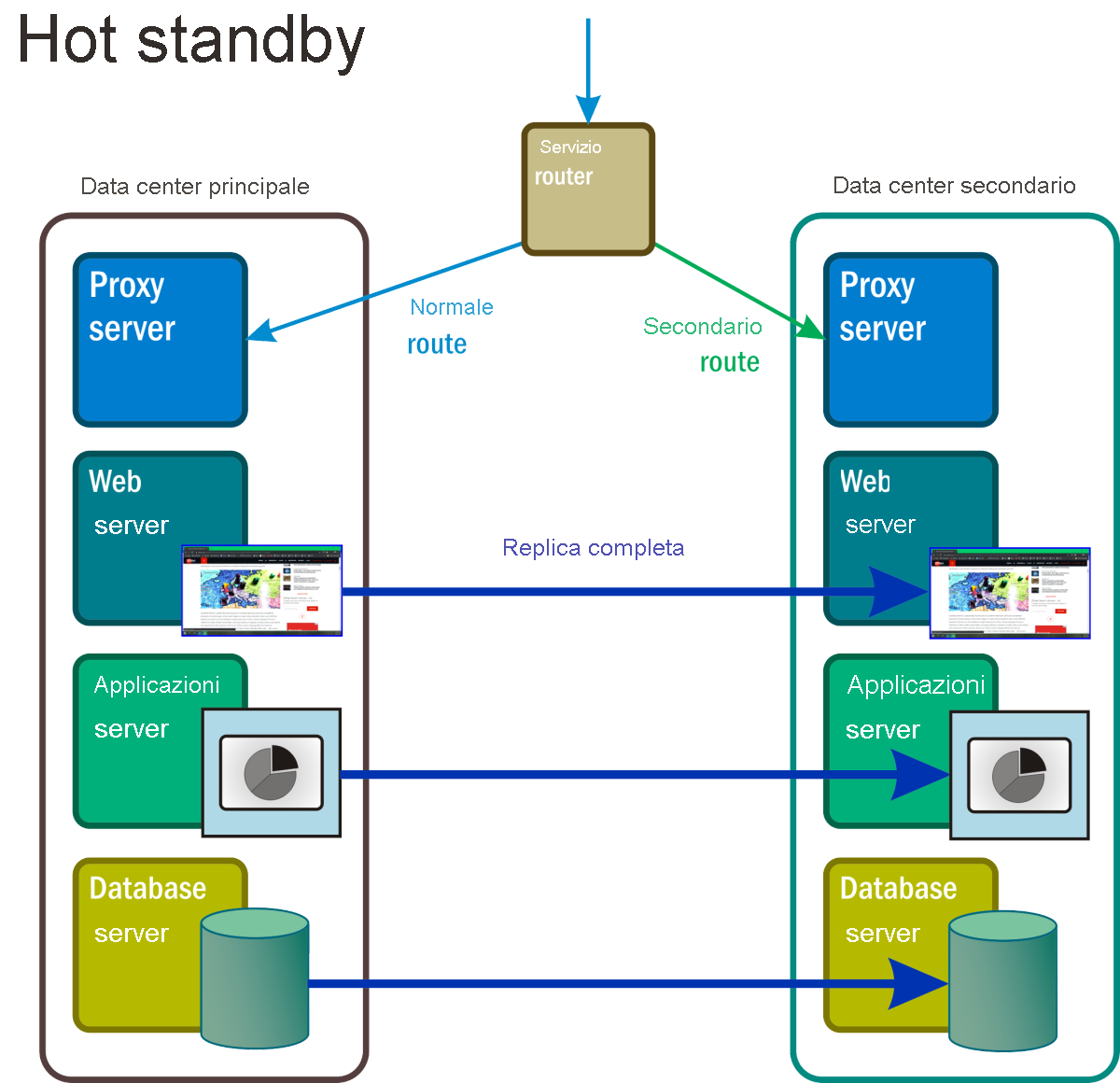
Figura 7: Con hot standby, tutti i componenti nello spazio dei nomi di ciò che normalmente sarebbe stato la riserva, lo spazio di standby, sono attivi, completamente operativi ed elaborano le repliche dei dati primari in tempo reale.
Applicazioni native del cloud
È in teoria possibile per un'organizzazione scegliere il servizio di ripristino di emergenza di un provider come rete di sicurezza per i servizi ospitati da un altro provider. In altre parole, con l'adeguato livello di attenzione da parte del personale IT, l'infrastruttura di un provider di servizi cloud (ad esempio, Google) può fungere da destinazione di failover per una procedura warm standby ospitata nell'infrastruttura di un altro provider di servizi cloud, ad esempio Azure. Questo tipo di configurazione può essere necessario per motivi di contabilità oppure se le risorse di calcolo all'interno di un'azienda sono gestite da reparti distinti in parti diverse del mondo.
Per il momento, la presenza di un'infrastruttura in contenitori nel data center locale, oltre che nel cloud, può avere un impatto significativo su tutte queste metodologie di ripristino di emergenza. Una cosiddetta applicazione nativa del cloud, sviluppata esclusivamente per l'uso in una piattaforma cloud pubblico o in una piattaforma con uguale funzionamento (ad esempio, Microsoft Azure Stack), distribuisce le funzioni in più contenitori di replica, che funzionano tutti o in parte simultaneamente. Il motivo non è tanto abilitare una nuova classe di scenari di ripristino di emergenza quanto distribuire i carichi di lavoro tra i processori.
Un altro aspetto delle architetture native del cloud è la possibilità per i database, il cui contenuto viene già replicato automaticamente, di essere contattati tramite un indirizzo di rete la cui mappa è esclusiva dell'applicazione in questione. (In altre parole, anche se usa il protocollo Internet, il suo indirizzo non è una posizione su Internet pubblico più ampio. In questo modo, durante un evento di emergenza, mentre alcuni nodi collegati al database potrebbero andare inattivo, molti verranno mantenuti e altri prenderanno il posto dei nodi non disponibili. Forse non si può ancora parlare di ripristino di emergenza predefinito, ma si tratta certamente di una modalità di resistenza alle emergenze.
Ripristino di emergenza distribuito come servizio
Per un provider di servizi cloud pubblico, il ripristino di emergenza è un mezzo attraverso il quale i servizi di base di backup e trasferimento dei dati vengono usati. Ognuno dei principali provider di servizi cloud implementa una strategia diversa per facilitare il ripristino di emergenza accanto ai servizi di backup.
AWS CloudEndure
Per migrazione dei servizi si intende la rilocazione dei carichi di lavoro virtuali dall'infrastruttura privata locale all'infrastruttura cloud pubblico. Questa rilocazione è necessaria per consentire ad alcuni servizi di ripristino di emergenza che operano nel cloud pubblico di raggiungere gli obiettivi di missione relativi al failover e al ripristino entro pochi minuti dall'inizio di un'emergenza.
Nel gennaio 2019 Amazon ha acquisito il servizio di migrazione dei servizi privato CloudEndure, che usava già AWS come provider di infrastruttura. Da quel momento ha integrato CloudEndure nella propria linea di servizi principale, offrendo la migrazione gratuita dei servizi ai clienti Amazon. AWS implementa ora la migrazione dei servizi come mezzo per abilitare rapidamente un processo warm o hot standby. AWS non addebita ai clienti il costo del processo di migrazione, ma addebita le risorse ridondanti di cui viene effettuato il provisioning per ogni scenario di ripristino di emergenza. L'assenza di tariffe aggiuntive rende tuttavia estremamente competitivo CloudEndure rispetto a molti altri servizi di ripristino di emergenza di terze parti.
Azure Site Recovery
Il servizio di ripristino di emergenza di Microsoft, Azure Site Recovery, è una distribuzione gestita di un metodo di ripristino warm standby per gli ambienti basati su macchine virtuali e per i server fisici (locali) che eseguono Linux o Windows. Le macchine virtuali vengono replicate attivamente in un'area secondaria (figura 9.8), in cui è possibile avviare un failover con un semplice clic. Ai clienti viene addebitata una tariffa mensile (attualmente di circa 25 $) per ogni server o macchina virtuale protetta da Azure Site Recovery.
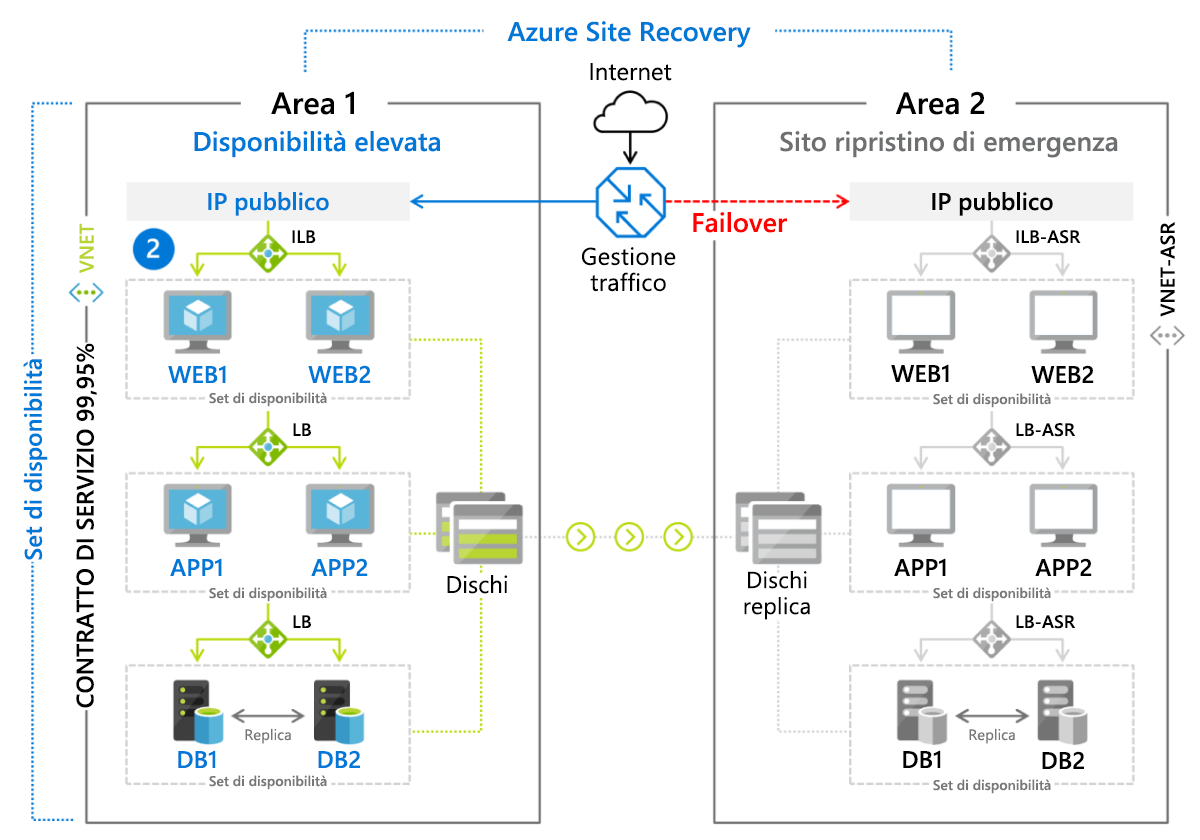
Figura 8: Scenario di failover implementato con Azure Site Recovery.
Ripristino di emergenza di Google Cloud
Come per il backup, Google non offre un servizio con marchio specifico per il ripristino di emergenza. Mette invece a disposizione gli strumenti e le risorse necessari per l'archiviazione dei dati e il trasferimento dei dati e fornisce indicazioni ai clienti sul modo migliore di usarli in diversi scenari di ripristino di emergenza.
Poiché Google offre opzioni di archiviazione Coldline, a cui applica uno sconto, GCP è applicabile a un'ampia gamma di scenari. Coldline è un'opzione interessante per le organizzazioni che gestiscono una quantità elevata di dati in blocco. I dischi magnetici sono contenitori poco pratici per i file multimediali le cui dimensioni medie richiedono decine di gigabyte. I componenti NAS forniscono una soluzione per l'accessibilità e la gestibilità per le organizzazioni che creano contenuti multimediali, ma solo a livello locale. Hanno ridondanza interna, ma non sono resistenti alle emergenze. E uno scenario di ripristino di emergenza come uno dei tre illustrati nei diagrammi precedenti non sarebbe utile (e forse nemmeno conveniente) per questa classe di clienti. L'opzione Coldline rappresenta quanto meno un metodo valido con cui questo tipo di cliente può ottenere un livello nominale di garanzia di continuità aziendale.