Resilienza nella progettazione e nei criteri
L'espressione che più spesso viene associata a "ripristino di emergenza" è "continuità aziendale". Continuità ha una connotazione positiva. Si riferisce all'obiettivo di limitare l'ambito di un evento di emergenza, o di qualsiasi altro evento meno grave, all'interno delle pareti del data center.
"Continuità" tuttavia non è un termine tecnico, nonostante gli sforzi per renderlo tale. Non esiste una singola formula, metodologia o ricetta per la continuità aziendale. Ogni organizzazione dovrà adottare un set univoco di procedure consigliate in base al tipo di attività e alle modalità di lavoro. La continuità consiste nella corretta applicazione di queste procedure per ottenere un risultato positivo.
Significato di resilienza
I tecnici conoscono il concetto di resilienza. Quando un sistema funziona correttamente in circostanze diverse, viene definito resiliente. Per un responsabile della gestione dei rischi, un'azienda può essere considerata ben preparata quando ha implementato piani alternativi, misure di sicurezza e procedure di emergenza pronte a rispondere a qualsiasi evento dannoso. Un tecnico potrebbe non vedere l'ambiente in cui un sistema opera con un contrasto netto tra "normale" e "minacciato", "sicurezza" e "disastro". Questa persona considera il sistema che supporta un'azienda in uno stato di funzionamento appropriato quando fornisce livelli di servizio continui e prevedibili in presenza di circostanze avverse.
Nel 2011, mentre il cloud computing godeva di una diffusione sempre maggiore nell'ambito del data center, l'Agenzia europea per la sicurezza delle reti e dell'informazione (ENISA), un'agenzia dell'Unione europea, ha pubblicato un report in risposta a una richiesta governativa di dati sulla resilienza dei sistemi che il governo utilizzava per raccogliere informazioni. Il report affermava apertamente che il personale ICT (Information and Communications Technology) non era ancora d'accordo sull'effettivo significato del termine "resilienza" o su come questa dovrebbe essere misurata.
Questo ha portato ENISA a scoprire un progetto lanciato da un team di ricercatori presso l'Università del Kansas (KU), con a capo il Prof. James P. G. Sterbenz, con l'intenzione di essere distribuito presso il Dipartimento di Difesa degli Stati Uniti. Si tratta dell'iniziativa ResiliNets (Resilient and Survivable Networking Initiative)1, un metodo per visualizzare lo stato variabile della resilienza nei sistemi informatici in una serie di circostanze. ResiliNets è il prototipo di un modello di consenso per i criteri di resilienza nelle organizzazioni.
Il modello della University of Kansas utilizza una serie di metriche note e facilmente comprensibili, alcune delle quali sono già state introdotte in questo capitolo. che includono:
Tolleranza di errore: come illustrato in precedenza, è la capacità di un sistema di mantenere i livelli di servizio previsti quando sono presenti errori
Tolleranza di interruzione: capacità dello stesso sistema di mantenere i livelli di servizio previsti in circostanze operative imprevedibili e spesso estreme, non causate dal sistema stesso, ad esempio interruzioni elettriche, carenza di larghezza di banda Internet e picchi di traffico
Capacità di sopravvivenza: stima della capacità di un sistema di fornire livelli di prestazioni del servizio ragionevoli, anche se non sempre nominali, in tutte le circostanze possibili, incluse le calamità naturali
La teoria principale avanzata da ResiliNets è che i sistemi informatici vengano resi più resilienti in modo quantificabile grazie a una combinazione di ingegneria dei sistemi e sforzi umani. Ciò che le persone fanno, o meglio ciò che continuano a fare nella prassi quotidiana, rende i sistemi più forti.
Prendendo un segnale da come soldati, marinai e Marines in un teatro attivo delle operazioni imparano e ricordano i principi di distribuzione tattica, il team KU ha proposto un back-of-the-napkin mnemonic per ricordare il ciclo di vita della pratica ResiliNets: D2R2 + DR. Come illustrato nella figura 9, le variabili qui rappresentate sono le seguenti, in questo ordine:**
Defend: difendere il sistema contro le minacce al normale funzionamento
Detect: rilevare l'occorrenza di effetti dannosi, causati da possibili errori e da circostanze esterne
Remediate: rimediare al conseguente possibile impatto di tali effetti sul sistema, anche se tale impatto deve ancora essere sostenuto
Recover: ripristinare i normali livelli di servizio
Diagnose: diagnosticare le cause radice degli eventi
Refine: affinare i comportamenti futuri, se necessario, per prepararsi al meglio a eventuali ripetizioni
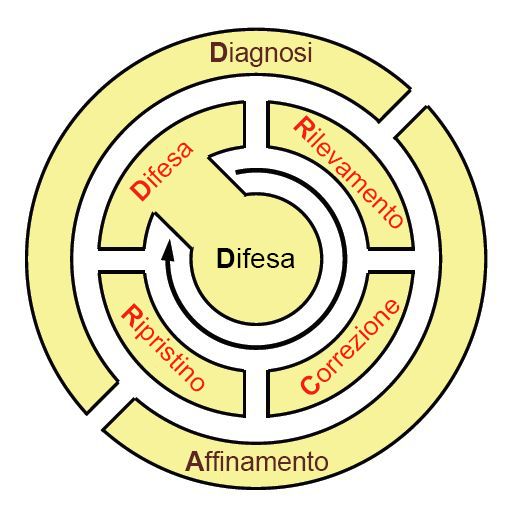
Figura 9: Ciclo di vita delle attività consigliate in un ambiente che usa ResiliNets.
Durante ogni fase, vengono ottenute alcune metriche delle prestazioni e operative, sia per gli utenti che per i sistemi. La combinazione di queste metriche restituisce punti che possono essere tracciati su un grafico, come quello nella figura 9.10, usando un piano geometrico euclideo. Ogni metrica può essere ridotta a due valori unidimensionali: uno che riflette i parametri a livello di servizio P e un altro che rappresenta lo stato operativo N. Poiché tutte e sei le fasi del ciclo ResiliNets vengono implementate e ripetute, lo stato del servizio S viene tracciato sul grafico in corrispondenza delle coordinate (N, P).
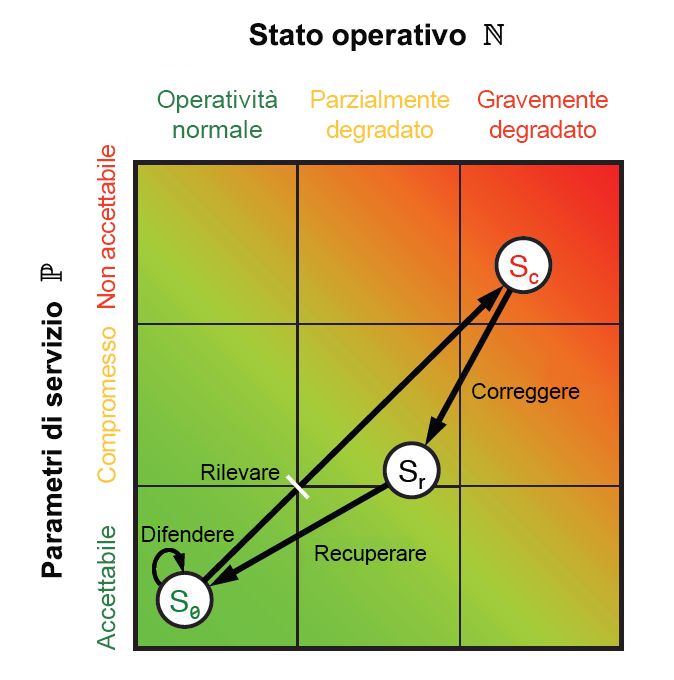
Figura 10: Ciclo interno dello spazio di stato e della strategia ResiliNets.
Lo stato S di un'organizzazione che soddisfa gli obiettivi di servizio si posizionerà molto vicino all'angolo inferiore sinistro del grafico, con la speranza che vi rimanga il più vicino possibile per tutta la durata del cosiddetto ciclo interno. Quando gli obiettivi di servizio vengono disattesi, lo stato si sposta lungo un vettore non auspicabile verso l'angolo superiore destro.
Anche se il modello ResiliNets non è diventato una rappresentazione universale della resilienza dell'IT nelle aziende, l'adozione da parte di alcune organizzazioni di rilievo, in particolare nel settore pubblico, ha dato vita ad alcuni dei cambiamenti che hanno catalizzato la rivoluzione cloud:
Visualizzazione delle prestazioni. Lo stato attuale della resilienza non deve essere comunicato agli stakeholder di rilievo in modo teorico. Può anzi essere dimostrato in meno di una parola. Le moderne piattaforme di gestione delle prestazioni che incorporano le metriche del cloud hanno anche dashboard e strumenti simili incorporati estremamente efficaci.
Non è necessario che le misure e le procedure di ripristino vengano attivate solo in caso di emergenza. Un sistema informatico completo e ben progettato, costantemente supportato da tecnici e operatori attenti, implementerà su base giornaliera procedure di manutenzione poco o per nulla diverse dalle procedure correttive adottate durante una crisi. In un ambiente di ripristino di emergenza hot standby, ad esempio, rimediare al problema a livello di servizio può diventare automatico: sarà sufficiente che il router principale reindirizzi il traffico lontano dai componenti interessati. In altri termini, prepararsi in vista di un guasto non significa aspettare che il guasto si verifichi.
I sistemi informatici dipendono dalle persone. L'automazione può rendere più efficace il lavoro delle persone e più efficiente la produzione, ma non può sostituire le persone in un sistema progettato per reagire a cambiamenti circostanziali e ambientali impossibili da prevedere.
Calcolo orientato al ripristino
ResiliNets è l'implementazione di un concetto che Microsoft ha contribuito a formulare all'inizio del nuovo secolo, denominato calcolo orientato al ripristino (ROC, Recovery-Oriented Computing).2 Questo concetto si basava sul principio che errori e bug fossero delle costanti nell'ambiente di calcolo. Invece di dedicare una quantità eccessiva di tempo a disinfettare questo ambiente, per così dire, potrebbe essere più vantaggioso per le organizzazioni applicare misure basate sul buon senso che contribuiscano a immunizzare l'ambiente. Si tratta dell'equivalente informatico del concetto rivoluzionario, introdotto subito prima dell'inizio del ventesimo secolo, secondo il quale le persone devono lavarsi le mani più volte al giorno.
Resilienza nel cloud pubblico
Tutti i provider di servizi cloud pubblico adottano principi e framework per la resilienza, anche se non li chiamano così. Una piattaforma cloud tuttavia aggiunge la resilienza al data center di un'organizzazione solo se assorbe interamente gli asset informativi di tale organizzazione nel cloud. La resilienza di un'implementazione di cloud ibrido dipende da quanto sono diligenti gli amministratori. Se si può presumere che gli amministratori del provider CSP saranno diligenti nel rispettare la resilienza (in caso contrario, violerebbero le condizioni del contratto di servizio), è sempre compito del cliente mantenere la resilienza dell'intero sistema.
Framework di resilienza di Azure
La guida internazionale standard per la strategia di continuità aziendale è ISO 22301. Come gli altri framework ISO (International Standards Organization), specifica le linee guida per procedure consigliate e operazioni, la conformità alle quali consente a un'organizzazione di ottenere una certificazione professionale.
Questo framework ISO non definisce di fatto la continuità aziendale né tantomeno la resilienza. Definisce invece il significato di continuità nel contesto dell'organizzazione. Nel documento principale si legge: "L'organizzazione deve identificare e selezionare le strategie di continuità aziendale in base agli output ottenuti dall'analisi di impatto aziendale e dalla valutazione dei rischi. Le strategie di continuità aziendale devono essere costituite da una o più soluzioni." Non è in grado di elencare ciò che queste soluzioni potrebbero o dovrebbero essere.3
La figura 11 è la rappresentazione di Microsoft dell'implementazione in più fasi di Azure della conformità allo standard ISO 22301. Si noti che sono inclusi gli obiettivi di tempo di attività del contratto di servizio. Per i clienti che scelgono questo livello di resilienza, Azure replica i data center virtuali nelle zone di disponibilità locali, ma effettua il provisioning di repliche separate, geograficamente situate a centinaia di chilometri l'una dall'altra. Per motivi legali tuttavia (soprattutto per garantire la conformità alle leggi sulla privacy dell'Unione europea) questa ridondanza suddivisa in base alla georilevazione è in genere limitata ai "confini di residenza dei dati", ad esempio America del Nord o Europa.
![Figure 11: Azure Resiliency Framework, which protects active components on multiple levels, in accordance with ISO 22301. [Courtesy Microsoft]](../../cmu-cloud-admin/cmu-disaster-recovery-backup/media/fig9-11.jpg)
Figura 11: Framework di resilienza di Azure, che protegge i componenti attivi su più livelli, in conformità con ISO 22301. [Per gentile concessione di Microsoft]
Anche se lo standard ISO 22301 è associato alla resilienza e spesso viene descritto come un set di linee guida per la resilienza, i livelli di resilienza per cui Azure è stato testato sono applicabili solo alla piattaforma Azure e non agli asset dei clienti ospitati in tale piattaforma. Gestire, eseguire la manutenzione e apportare continui miglioramenti ai processi, tra cui la modalità di replica delle risorse nel cloud di Azure e altrove, rimane responsabilità del cliente.
Google Container Engine
Fino a poco tempo fa, il software era percepito come lo stato di un computer identico all'hardware dal punto di vista funzionale, ma in forma digitale. Sotto questo punto di vista, il software è stato percepito come un componente relativamente statico in un sistema informatico. I protocolli di sicurezza richiedevano che il software fosse aggiornato regolarmente e con "regolarmente" si intendeva alcune volte all'anno, quando erano disponibili aggiornamenti e correzioni di bug.
Ciò che le dinamiche del cloud hanno reso possibile, ma che molti tecnici IT non avevano previsto, è stata l'evoluzione del software in modo incrementale oltre che frequente. Con integrazione continua e recapito continuo (CI/CD) si fa riferimento a un set di principi in fase emergente, in cui l'automazione consente lo staging frequente, spesso giornaliero, di modifiche incrementali al software, sia sul lato server che sul lato client. Gli utenti degli smartphone sperimentano regolarmente la tecnologia CI/CD, grazie alle app che vengono aggiornate più volte alla settimana negli app store. Ogni modifica apportata dalla tecnologia CI/CD può essere secondaria, ma il fatto che le modifiche secondarie possano essere distribuite rapidamente e senza difficoltà ha generato un effetto collaterale imprevisto, anche se vantaggioso: i sistemi informatici sono molto più resilienti.
Con i modelli di distribuzione CI/CD, vengono effettuati il provisioning e la manutenzione di cluster di server completamente ridondanti, spesso nell'infrastruttura cloud pubblico, esclusivamente come mezzo per testare i nuovi componenti software prodotti per rilevare eventuali bug e quindi per inserire tali componenti in un ambiente di lavoro simulato per individuare potenziali errori. In questo modo, i processi di correzione possono essere eseguiti in un ambiente sicuro senza effetti diretti sui livelli di servizio rivolti ai clienti o agli utenti, fino a quando le correzioni non sono state applicate, testate e approvate per la distribuzione.
Google Container Engine (GKE, dove "K" sta per "Kubernetes") è l'ambiente di Google Cloud Platform per i clienti che distribuiscono applicazioni e servizi basati su contenitori, invece di applicazioni basate su macchine virtuali. Una distribuzione completa in contenitori può includere microservizi ("μ-servizi"), database distinti dai carichi di lavoro e progettati per funzionare in modo indipendente ("set di dati con stato"), librerie di codice dipendenti e piccoli sistemi operativi usati nell'eventualità che il codice dell'applicazione debba utilizzare il file system del contenitore. La figura 9.12 illustra una distribuzione di questo tipo nello stile effettivamente suggerito da Google ai clienti GKE.
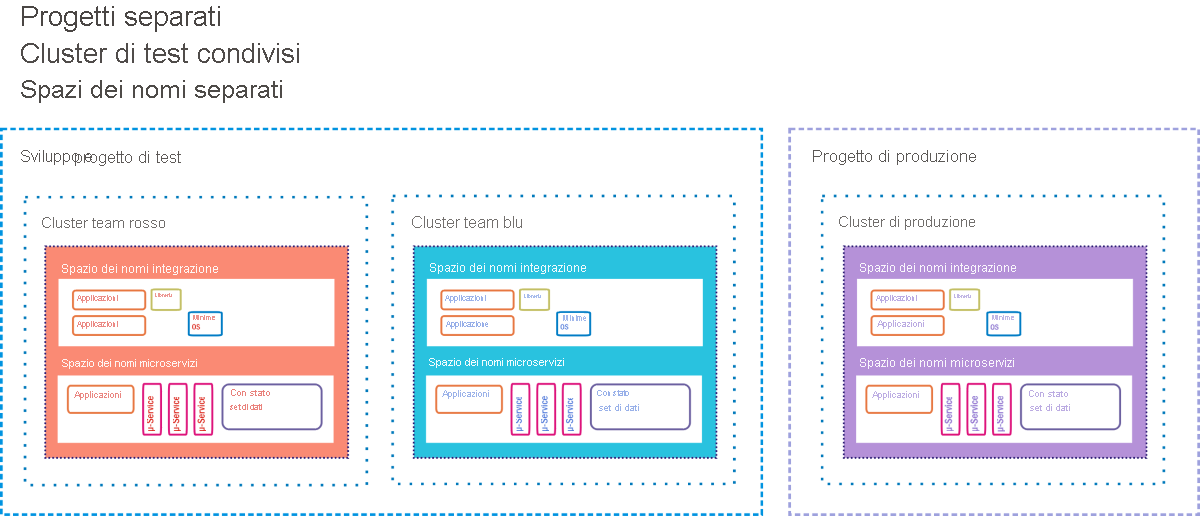
Figura 12: Opzione hot standby come ambiente di gestione temporanea CI/CD per Google Container Engine.
In GKE un progetto è analogo a un data center, perché viene percepito come dotato di tutte le risorse di un data center, ma in forma virtuale. A un progetto può essere assegnato uno o più cluster di server. I componenti in contenitori esistono nei rispettivi spazi dei nomi, simili a uno spazio personale. Ognuno è costituito da tutti i componenti indirizzabili ai quali possono accedere i contenitori membro e tutto ciò che si trova all'esterno dello spazio dei nomi deve essere indirizzato usando gli indirizzi IP remoti. I tecnici di Google suggeriscono che le applicazioni client/server di vecchio tipo (chiamate "monoliti" dagli sviluppatori di contenitori) possano coesistere con le applicazioni in contenitori, purché ogni classe utilizzi per motivi di sicurezza il proprio spazio dei nomi, pur condividendo lo stesso progetto.
In questo diagramma di distribuzione suggerito sono presenti tre cluster attivi, ognuno dei quali opera con due spazi dei nomi: uno per il software obsoleto, l'altro per quello nuovo. Due di questi cluster sono delegati per i test: uno per i test di sviluppo iniziali e l'altro per lo staging finale. In una pipeline CI/CD, i nuovi contenitori di codice vengono inseriti in uno dei cluster di test, dove devono superare una serie di test automatizzati, dimostrando di essere relativamente privi di bug, prima di essere passare allo staging, dove una seconda serie attende i nuovi contenitori di software. Solo il codice che ha superato i test di staging di secondo livello può essere inserito nel cluster di produzione live usato dai clienti finali.
Anche in questo caso sono tuttavia previsti piani alternativi. In uno scenario di distribuzione A/B, il nuovo codice coesiste con il vecchio codice per un periodo di tempo specificato. Se l'esecuzione del nuovo codice non rispetta le specifiche o introduce errori nel sistema, è possibile ritirarlo, lasciando il code-behind precedente. Se il periodo di validità scade e il nuovo codice viene eseguito correttamente, il codice precedente viene ritirato.
Questo processo è un modo sistematico e parzialmente automatizzato che consente ai sistemi informatici di evitare l'introduzione di errori che causano guasti. Non si tratta tuttavia di una configurazione a prova di emergenza, a meno che il cluster di produzione non venga replicato in modalità hot standby. Questo schema di replica utilizza ovviamente molte risorse basate sul cloud. I costi che ne derivano possono tuttavia essere molto più bassi di quelli che un'organizzazione dovrebbe sostenere se non fosse protetta da un'interruzione del sistema.
Riferimenti
Ster tutt'altro, James P.G., et al. "ResiliNets: Multilevel Resilient and Survivable Networking Initiative". https://resilinets.org/main_page.html
Patterson, David, et al. "Recovery Oriented Computing: Motivation, Definition, Principles, and Examples." Microsoft Research, marzo 2002. https://www.microsoft.com/research/publication/recovery-oriented-computing-motivation-definition-principles-and-examples/.
ISO. "Security and resilience - Business continuity management systems - Requirements." https://dri.ca/docs/ISO_DIS_22301_(E).pdf.