Introduzione
Ricerca di intelligenza artificiale di Azure consente di creare soluzioni di ricerca in cui viene usata una pipeline di competenze di intelligenza artificiale per arricchire i dati e popolare un indice. Gli arricchimenti dei dati eseguiti dalle competenze nella pipeline integrano i dati di origine con informazioni dettagliate, ad esempio:
- Lingua in cui viene scritto un documento.
- Frasi chiave che possono essere utili per determinare i temi principali o gli argomenti trattati in un documento.
- Punteggio del sentiment che quantifica il livello di positività o negatività di un documento.
- Posizioni specifiche, persone, organizzazioni o luoghi di interesse indicati nel contenuto.
- Descrizioni di immagini generate dall'intelligenza artificiale o testo dell'immagine estratto dal riconoscimento ottico dei caratteri (OCR).
I dati arricchiti nell'indice consentono di creare una soluzione di ricerca completa che va oltre la ricerca full-text di base del contenuto di origine.
Archivi conoscenze
Anche se l'indice può essere considerato l'output primario di un processo di indicizzazione, i dati arricchiti che contiene potrebbero essere utili anche in altri modi. Ad esempio:
- Poiché l'indice è essenzialmente una raccolta di oggetti JSON, ognuno dei quali rappresenta un record indicizzato, potrebbe essere utile esportare gli oggetti come file JSON per l'integrazione in un processo di orchestrazione dei dati usando strumenti come Azure Data Factory.
- Potrebbe essere necessario normalizzare i record dell'indice in uno schema relazionale di tabelle per l'analisi e la creazione di report con strumenti come Microsoft Power BI.
- Dopo aver estratto le immagini incorporate dai documenti durante il processo di indicizzazione, potrebbe essere necessario salvare tali immagini come file.
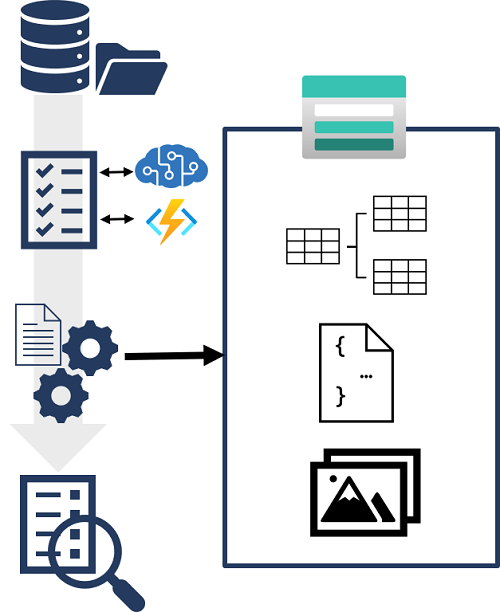
Ricerca di intelligenza artificiale di Azure supporta questi scenari consentendo di definire un archivio conoscenze nel set di competenze che incapsula la pipeline di arricchimento. L'archivio conoscenze è costituito da proiezioni dei dati arricchiti, che possono essere oggetti JSON, tabelle o file di immagine. Quando un indicizzatore esegue la pipeline per creare o aggiornare un indice, le proiezioni vengono generate e rese permanenti nell'archivio conoscenze.
In questo modulo si implementerà un archivio conoscenze per Margie's Travel, un'agenzia di viaggi fittizia che usa le informazioni contenute nelle brochure e nelle recensioni degli hotel per aiutare i clienti a pianificare i viaggi e si apprenderà come:
- Creare un archivio conoscenze da una pipeline di Ricerca intelligenza artificiale di Azure
- Visualizzare i dati nelle proiezioni in un archivio conoscenze
Nota
Questo modulo presuppone che si sappia già come creare e usare una soluzione di Ricerca di intelligenza artificiale di Azure che include competenze predefinite. In caso contrario, completare prima di tutto il modulo Creare una soluzione di Ricerca intelligenza artificiale di Azure.