Comprendere e testare il modello
È stato creato un modello di Machine Learning. Il modello verrà ora testato per verificarne le prestazioni.
Prestazioni modello
Quando si esegue il test del modello, Visione personalizzata visualizza tre metriche. Le metriche sono indicatori che consentono di comprendere le prestazioni del modello. Gli indicatori non segnalano il livello di attendibilità o di accuratezza del modello. Indicano solo le prestazioni del modello con i dati forniti. Le prestazioni del modello con i dati noti forniscono un'idea di come funzionerà il modello con nuovi dati.
Vengono fornite le metriche seguenti per l'intero modello e per ogni classe:
| Metrico | Descrizione |
|---|---|
precision |
Se il modello prevede un tag, questa metrica indica con che probabilità verrà previsto il tag corretto. |
recall |
Questa metrica indica la percentuale di tag predetti correttamente dal modello rispetto ai tag che richiedono una previsione. |
average precision |
Misura le prestazioni del modello calcolando la precisione e il richiamo in corrispondenza di soglie diverse. |
Quando si testa il modello di Visione personalizzata, vengono visualizzati valori numerici per ognuna di queste metriche nei risultati del test di iterazione.
Errori comuni
Prima di testare il modello, si esamineranno alcuni degli "errori da principiante" a cui fare attenzione quando si inizia a creare modelli di Machine Learning.
Uso di dati non bilanciati
Quando si distribuisce il modello può venire visualizzato questo avviso:
Unbalanced data detected. The distribution of images per tag should be uniform to ensure model performance.
L'avviso indica che non è disponibile un numero pari di campioni per ogni classe di dati. Sebbene in questo scenario siano disponibili più opzioni, un modo comune per risolvere il problema di dati non bilanciati consiste nell'usare la tecnica di sovracampionamento minoritario sintetico (SMOTE, Synthetic Minority Over-sampling Technique). Questa tecnica duplica gli esempi di training dal pool di training esistente.
Nota
Nel modello potrebbe non essere visualizzato questo avviso, soprattutto se è stata caricata solo una piccola parte del set di dati. Il subset di dati del modello Red-tailed Hawk (Dark morph) contiene meno di 60 foto rispetto agli altri modelli con più di 100 foto. L'uso di dati non bilanciati è un aspetto da controllare in qualsiasi modello di Machine Learning.
Overfitting del modello
Se non si hanno dati sufficienti o se i dati non sono abbastanza diversificati, possono verificarsi problemi di overfitting del modello. L'overfitting si verifica quando il modello conosce bene il set di dati fornito e si adatta eccessivamente agli schemi di tali dati. In questo caso, le prestazioni del modello sono buone sui dati di training, ma saranno scarse sui nuovi dati non usati in precedenza. Per questo motivo si usano sempre nuovi dati per testare un modello.
Uso dei dati di training per il test
Come nel caso dell'overfitting, se si testa il modello usando gli stessi dati usati per il training, le prestazioni risultano soddisfacenti. Quando tuttavia si distribuisce il modello nell'ambiente di produzione, è molto probabile che le prestazioni risultino scarse.
Uso di dati non validi
Un altro errore comune consiste nell'usare dati non validi per eseguire il training del modello. Alcuni dati possono effettivamente ridurre l'accuratezza del modello. L'uso di dati "non significativi" può ad esempio ridurre l'accuratezza di un modello. Nei dati non significativi sono presenti troppe informazioni non utili nel set di dati e ciò provoca confusione nel modello. L'uso di una quantità maggiore di dati è preferibile solo se si tratta di dati validi che il modello può usare. Può essere necessario eseguire la pulizia dei dati o rimuovere caratteristiche per migliorare l'accuratezza del modello.
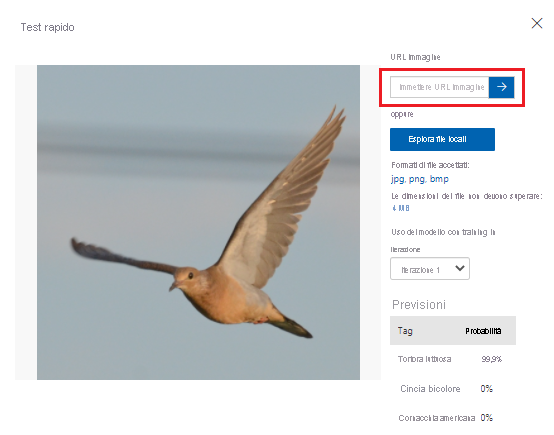
Test del modello
Secondo le metriche fornite da Visione personalizzata, le prestazioni del modello sono soddisfacenti. Ora si testerà il modello per verificarne le prestazioni con dati non visti in precedenza. Verrà usata un'immagine di un uccello ottenuta tramite una ricerca in Internet.
Nel Web browser cercare un'immagine di un uccello corrispondente a una delle specie che il modello dovrebbe riconoscere dopo il training. Copiare l'URL per l'immagine.
Nel portale di Visione personalizzata selezionare il progetto Bird Classification.
Nella barra dei menu in alto selezionare Test rapido.
In Test rapido incollare l'URL in URL immagine e quindi premere INVIO per testare l'accuratezza del modello. La stima viene visualizzata nella finestra.
Visione personalizzata analizza l'immagine per testare l'accuratezza del modello e visualizza i risultati:
Nel passaggio successivo si distribuirà il modello. Dopo la distribuzione del modello, è possibile eseguire altri test con un endpoint creato.