Raccogliere, eseguire query e visualizzare gli stati di integrità
Per rappresentare in modo accurato un modello di integrità, è necessario raccogliere vari set di dati dal sistema. I set di dati includono log e metriche delle prestazioni provenienti dai componenti dell'applicazione e dalle risorse di Azure sottostanti. È importante mettere in correlazione i dati tra i set i dati per creare una rappresentazione a livello dell'integrità per il sistema.
Strumentazione del codice e dell'infrastruttura
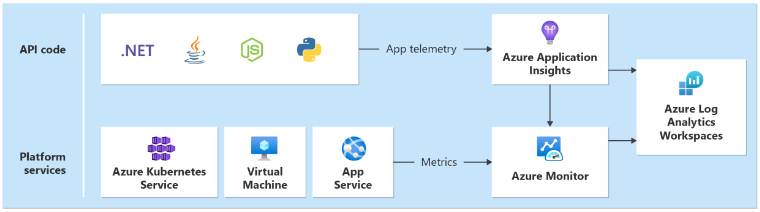
È necessario un sink di dati unificato per garantire che tutti i dati operativi vengano archiviati e siano disponibili in una singola posizione in cui vengono raccolti tutti i dati di telemetria. Ad esempio, quando un dipendente crea un commento nel suo Web browser, è possibile tenere traccia di questa operazione e verificare che la richiesta sia stata passata tramite l'API Catalogo a Hub eventi di Azure. Da qui, il commento è stato raccolto dal processore in background e archiviato in Azure Cosmos DB.
Log Analytics di Monitoraggio di Azure funge da principale sink di dati unificato nativo di Azure per archiviare e analizzare i dati operativi:
Application Insights è lo strumento consigliato di Application Performance Monitoring (APM) in tutti i componenti dell'applicazione per raccogliere i relativi log, le metriche e le tracce. Application Insights viene distribuito in una configurazione basata su area di lavoro in ogni area.
Nell'applicazione di esempio si usa Funzioni di Azure in Microsoft .NET 6 per i servizi back-end per l'integrazione nativa. Poiché le applicazioni back-end esistono già, Contoso Shoes crea solo una nuova risorsa di Application Insights in Azure e configura l'impostazione
APPLICATIONINSIGHTS_CONNECTION_STRINGin entrambe le app per le funzioni. Il runtime di Funzioni di Azure registra automaticamente il provider di registrazione di Application Insights, quindi i dati di telemetria vengono visualizzati in Azure senza interventi aggiuntivi. Per una registrazione più personalizzata, è possibile usare l'interfaccia ILogger.Il set di dati centralizzato è un antipattern per carichi di lavoro cruciali. Ogni area deve avere un'area di lavoro Log Analytics dedicata e un'istanza di Application Insights. Per le risorse globali, sono consigliate istanze separate. Per visualizzare il modello di architettura principale, vedere Modello di architettura per carichi di lavoro cruciali in Azure.
Ogni livello deve inviare dati alla stessa area di lavoro Log Analytics, per semplificare l'analisi e i calcoli di integrità.
Query di monitoraggio dell'integrità
Log Analytics, Application Insights ed Esplora dati di Azure usano il linguaggio di query Kusto (KQL) per le query. È possibile usare KQL per creare query e usare le funzioni per recuperare le metriche e calcolare i punteggi di integrità.
Per i singoli servizi che calcolano lo stato di integrità, vedere le query di esempio seguenti.
API Catalogo
L'esempio seguente illustra una query dell'API Catalogo:
let _maxAge = 2d; // Include data only from the last two days
let _timespanStart = ago(_maxAge); // Start time for the time span
let _timespanEnd = now(-2m); // Account for ingestion lag by stripping the last 2m
// For time frame, compare the averages to the following threshold values
let Thresholds=datatable(MetricName: string, YellowThreshold: double, RedThreshold: double) [
"failureCount", 10, 50, // Failed requests, anything non-200, allow a few more than 0 for user-caused errors like 404s
"avgProcessingTime", 150, 500 // Average duration of the request, in ms
];
// Calculate average processing time for each request
let avgProcessingTime = AppRequests
| where AppRoleName startswith "CatalogService"
| where OperationName != "GET /health/liveness" // Liveness requests don't do any processing, including them would skew the results
| make-series Value = avg(DurationMs) default=0 on TimeGenerated from _timespanStart to _timespanEnd step 1m
| mv-expand TimeGenerated, Value
| extend TimeGenerated = todatetime(TimeGenerated), Value=toreal(Value), MetricName= 'avgProcessingTime';
// Calculate failed requests
let failureCount = AppRequests
| where AppRoleName startswith "CatalogService" // Liveness requests don't do any processing, including them would skew the results
| where OperationName != "GET /health/liveness"
| make-series Value=countif(Success != true) default=0 on TimeGenerated from _timespanStart to _timespanEnd step 1m
| mv-expand TimeGenerated, Value
| extend TimeGenerated = todatetime(TimeGenerated), Value=toreal(Value), MetricName= 'failureCount';
// Union all together and join with the thresholds
avgProcessingTime
| union failureCount
| lookup kind = inner Thresholds on MetricName
| extend IsYellow = iff(todouble(Value) > YellowThreshold and todouble(Value) < RedThreshold, 1, 0)
| extend IsRed = iff(todouble(Value) > RedThreshold, 1, 0)
| project-reorder TimeGenerated, MetricName, Value, IsYellow, IsRed, YellowThreshold, RedThreshold
| extend ComponentName="CatalogService"
Insieme di credenziali chiave di Azure
L'esempio seguente illustra una query di Azure Key Vault:
let _maxAge = 2d; // Include data only from the last two days
let _timespanStart = ago(_maxAge); // Start time for the time span
let _timespanEnd = now(-2m); // Account for ingestion lag by stripping the last 2m
// For time frame, compare the averages to the following threshold values
let Thresholds = datatable(MetricName: string, YellowThreshold: double, RedThreshold: double) [
"failureCount", 3, 10 // Failure count on key vault requests
];
let failureStats = AzureDiagnostics
| where TimeGenerated > _timespanStart
| where ResourceProvider == "MICROSOFT.KEYVAULT"
// Ignore authentication operations that have a 401. This is normal when using Key Vault SDK. First an unauthenticated request is made, then the response is used for authentication
| where Category=="AuditEvent" and not (OperationName == "Authentication" and httpStatusCode_d == 401)
| where OperationName in ('SecretGet','SecretList','VaultGet') or '*' in ('SecretGet','SecretList','VaultGet')
// Exclude Not Found responses because these happen regularly during 'Terraform plan' operations, when Terraform checks for the existence of secrets
| where ResultSignature != "Not Found"
// Create ResultStatus with all the 'success' results bucketed as 'Success'
// Certain operations like StorageAccountAutoSyncKey have no ResultSignature; for now, also set to 'Success'
| extend ResultStatus = case ( ResultSignature == "", "Success",
ResultSignature == "OK", "Success",
ResultSignature == "Accepted", "Success",
ResultSignature);
failureStats
| make-series Value=countif(ResultStatus != "Success") default=0 on TimeGenerated from _timespanStart to _timespanEnd step 1m
| mv-expand TimeGenerated, Value
| extend TimeGenerated = todatetime(TimeGenerated), Value=toreal(Value), MetricName="failureCount", ComponentName="Keyvault"
| lookup kind = inner Thresholds on MetricName
| extend IsYellow = iff(todouble(Value) > YellowThreshold and todouble(Value) < RedThreshold, 1, 0)
| extend IsRed = iff(todouble(Value) > RedThreshold, 1, 0)
Punteggio di integrità del servizio Catalogo
Alla fine, è possibile associare varie query sullo stato di integrità per calcolare un punteggio di integrità di un componente. La query di esempio seguente illustra come calcolare un punteggio di integrità del servizio Catalogo:
CatalogServiceHealthStatus()
| union AksClusterHealthStatus()
| union KeyvaultHealthStatus()
| union EventHubHealthStatus()
| where TimeGenerated < ago(2m)
| summarize YellowScore = max(IsYellow), RedScore = max(IsRed) by bin(TimeGenerated, 2m)
| extend HealthScore = 1 - (YellowScore * 0.25) - (RedScore * 0.5)
| extend ComponentName = "CatalogService", Dependencies="AKSCluster,Keyvault,EventHub" // These values are added to build the dependency visualization
| order by TimeGenerated desc
Suggerimento
Vedere altri esempi di query nel repository GitHub Azure Mission-Critical Online.
Configurare gli avvisi basati su query
Gli avvisi richiamano un'attenzione immediata per i problemi che si riflettono o influiscono sullo stato di integrità. Ogni volta che si verifica una modifica dello stato di integrità, con il passaggio a uno stato danneggiato (giallo) o non integro (rosso), le notifiche devono essere inviate al team responsabile. Impostare avvisi nel nodo radice del modello di integrità per diventare immediatamente consapevoli di qualsiasi modifica a livello aziendale nello stato di integrità della soluzione. È quindi possibile esaminare le visualizzazioni dei modelli di integrità per ottenere altre informazioni e risolvere i problemi.
L'esempio usa gli avvisi di Monitoraggio di Azure per attivare azioni automatizzate in risposta alle modifiche nello stato di integrità dell'applicazione.
Usare i dashboard per la visualizzazione
È importante visualizzare il modello di integrità in modo da comprendere rapidamente l'effetto di un'interruzione di un componente sull'intero sistema. L'obiettivo finale di un modello di integrità è facilitare la diagnosi rapida fornendo una visione informata delle deviazioni dallo stato stabile.
Un modo comune per visualizzare le informazioni sull'integrità del sistema consiste nel combinare una visualizzazione del modello di integrità a livelli con funzionalità di drill-down dei dati di telemetria in un dashboard.
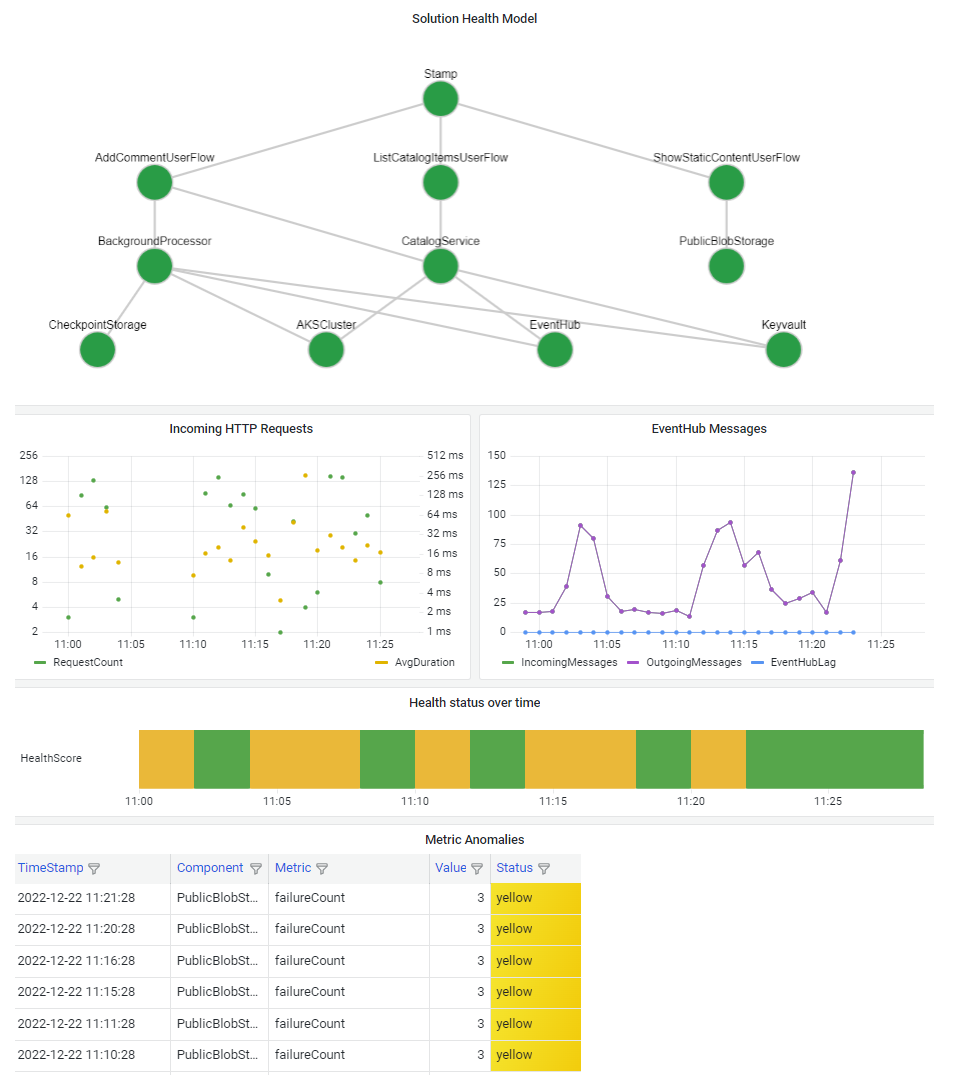
La tecnologia del dashboard deve essere in grado di rappresentare il modello di integrità. Le opzioni più comuni includono Dashboard di Azure, Power BI e Grafana con gestione Azure.