Sviluppare un piano di continuità aziendale e ripristino di emergenza
L'organizzazione vuole progettare una strategia di ripristino sito per le applicazioni. Per prima cosa, è necessario identificare i requisiti specifici per la creazione di un piano di ripristino sito per l'ambiente ibrido. È anche necessario identificare gli strumenti disponibili in Azure utili a questo scopo.
In questa unità verrà descritto come identificare le infrastrutture principali, gli obiettivi del tempo di ripristino e gli obiettivi del punto di ripristino. Verranno anche specificati i requisiti pertinenti per qualsiasi servizio di piattaforma distribuita come servizio (PaaS) usato. Si apprenderà anche come pianificare il backup e il ripristino di emergenza. Infine, verranno presentate alcune delle funzionalità di Azure utili per creare una soluzione di ripristino sito.
Continuità aziendale e ripristino di emergenza
È necessario sviluppare un piano BCDR per progettare una soluzione di ripristino del sito appropriata. Per BCDR si intende un processo che consente di ripristinare lo stato funzionale delle applicazioni dopo un evento significativo. Questo evento potrebbe essere una calamità naturale, ad esempio un terremoto. Oppure potrebbe essere di natura tecnica, ad esempio l'eliminazione di un database. Questi eventi hanno in genere un ambito più ampio e richiedono un impegno maggiore per ripristinare le applicazioni.
Per individuare un processo di ripristino di emergenza corretto, è necessario prima di tutto valutare il tipo di impatto aziendale che potrebbero avere potenziali errori. Automatizzare il processo di ripristino quanto più possibile. Inevitabilmente, alcune parti del processo di ripristino di emergenza comporteranno l'input umano e di conseguenza sarà necessario documentare completamente il processo stesso. È anche necessario simulare regolarmente le emergenze, in modo che il processo di ripristino resti efficace.
Identificare l'infrastruttura e gli stakeholder principali
Identificare tutte le figure che hanno interesse a che le applicazioni restino funzionali. Questi stakeholder possono essere utenti esterni o interni. Il personale di supporto, e chiunque debba intervenire manualmente nel processo BCDR, è uno stakeholder. Anche altri servizi e applicazioni che si basano sulle applicazioni dell'utente possono essere considerati stakeholder.
Identificare l'infrastruttura che costituisce l'ambiente per le applicazioni. Questa infrastruttura è in genere costituita da macchine virtuali, risorse di rete, risorse di archiviazione e qualsiasi altro servizio eseguito insieme.
Identificare gli obiettivi del punto e del tempo di ripristino
Un RPO rappresenta la quantità di perdita di dati accettabile per l'applicazione in caso di emergenza. Se, ad esempio, l'applicazione si arresta, si potrebbe considerare accettabile la sua esecuzione solo su dati vecchi meno di mezz'ora dopo il ripristino. Alcune applicazioni possono funzionare con dati meno recenti, ma per altre è essenziale essere eseguite sui dati più recenti possibile.
Un obiettivo del tempo di ripristino (RTO) è la durata massima del tempo di inattività accettabile per l'applicazione. Ad esempio, potrebbe non essere accettabile per l'applicazione restare inattiva per più di quattro ore, a causa della possibile perdita per l'azienda dopo questo periodo di tempo. Le applicazioni critiche richiedono un RTO inferiore.
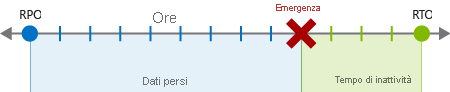
L'RTO e l'RPO per l'applicazione possono spesso dipendere da requisiti contrattuali o normativi. Anche RPO e RTO possono variare in base all'applicazione. Le applicazioni meno critiche possono avere valori maggiori per RPO e RTO, mentre le applicazioni più business critical per l'azienda possono avere una tolleranza minore per il tempo di inattività e la perdita di dati. L'RTO e l'RPO vengono calcolati in base all'identificazione da parte dell'organizzazione del rischio e dei costi dovuti alla perdita di dati e al tempo di inattività.
Identificare eventuali requisiti dei servizi PaaS
Anche se è possibile avere il controllo sui tempi di inattività e sul ripristino per le applicazioni gestite, si potrebbe non avere lo stesso controllo sui servizi PaaS. Tutti i servizi PaaS usati possono avere garanzie di disponibilità e piani di ripristino propri che è necessario prendere in considerazione nel piano BCDR.
Identificare i servizi da cui si dipende ed eseguirne l'inventario, in modo da poter integrarne le funzionalità di ripristino nel piano BCDR. È importante identificare i requisiti pertinenti e determinare in che modo influiscono sul processo BCDR.
Azure Site Recovery
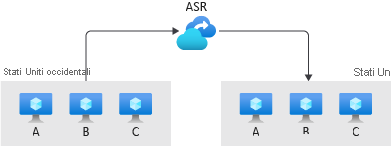
Azure Site Recovery è un servizio che offre funzionalità BCDR per le applicazioni in Azure, in locale e in altri provider di servizi cloud. Site Recovery prevede piani che consentono di automatizzare il ripristino di emergenza. Consente di definire il modo in cui i computer vengono sottoposti a failover e l'ordine in cui vengono riavviati dopo di esso. In questo modo, Site Recovery consente di automatizzare le attività e ridurre ulteriormente l'obiettivo del tempo di ripristino. È possibile usare Site Recovery anche per testare periodicamente i failover e l'efficacia complessiva del processo di ripristino.
Backup di dati
I backup aiutano a proteggere le applicazioni dall'eliminazione accidentale o dal danneggiamento dei dati. I backup hanno un ruolo importante in ogni piano BCDR.
L'RPO dipende da quanto spesso e quanto regolarmente vengono eseguiti i processi di backup. Se, ad esempio, è stato configurato un processo di backup per l'esecuzione ogni due ore e si verifica un'emergenza cinque minuti prima del backup successivo, si perderanno 55 ora e 55 minuti di dati. L'esecuzione di backup più frequenti permette di ottenere un RPO inferiore. Nel piano generale è necessario includere un processo di backup dettagliato.
È possibile usare Backup di Azure come processo di backup. Il servizio Backup di Azure offre il backup sicuro per tutti gli asset di dati gestiti da Azure. Usa soluzioni senza infrastruttura per abilitare backup e ripristini self-service, con una gestione su larga scala a un costo prevedibile.
Backup di Azure offre soluzioni di backup specializzate per le macchine virtuali di Azure e locali. Backup di Azure consente inoltre ai carichi di lavoro come SQL Server o SAP HANA in esecuzione nelle macchine virtuali di Azure di avere opzioni di backup e ripristino di classe enterprise.
Sia Backup di Azure che Azure Site Recovery mirano a rendere il sistema più resiliente agli errori e ai malfunzionamenti. Tuttavia, l'obiettivo principale di Backup di Azure è gestire copie di dati con stato che consentono di tornare indietro nel tempo. Site Recovery replica i dati in tempo quasi reale e consente un failover. Altre informazioni su Backup di Azure.
Funzionalità di resilienza di Azure
Azure include alcune funzionalità che consentono di garantire la resilienza delle applicazioni e dell'infrastruttura.
Associazione di aree
Ogni area di Azure è associata a un'area diversa. In una coppia di aree le aree non vengono mai aggiornate simultaneamente. Vengono invece aggiornate una per volta. Se si verifica un problema in un'area, diventa disponibile un'altra area.
Queste coppie di aree vengono usate anche per la replica. I servizi di archiviazione e molti servizi PaaS vengono replicati e hanno coppie di failover nell'area associata. Come parte della pianificazione BCDR, è importante usare l'associazione di aree per sfruttare l'isolamento fornito da questa funzionalità. È possibile ridurre la quantità di tempo necessaria per il ripristino da un errore e per aumentare la disponibilità.
Set di disponibilità
Un set di disponibilità è una funzionalità di raggruppamento logico in Azure. Garantisce che le risorse della macchina virtuale inserite all'interno siano isolate l'una dall'altra quando vengono distribuite all'interno di un data center di Azure. I set di disponibilità sono costituiti da domini di aggiornamento e domini di errore.
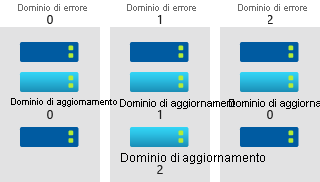
I domini di aggiornamento garantiscono che un subset dei server dell'applicazione resti sempre in esecuzione quando in un data center di Azure è necessario un tempo di inattività degli host delle macchine virtuali per attività di manutenzione. La maggior parte degli aggiornamenti agli host VM può essere eseguita senza influire sulle macchine virtuali in esecuzione, ma in alcuni casi questo tipo di aggiornamento non è possibile.
Per evitare che gli aggiornamenti vengano eseguiti in tutte le macchine virtuali contemporaneamente, il data center di Azure è suddiviso a livello logico in domini di aggiornamento. Quando è necessario applicare all'host un evento di manutenzione, ad esempio un aggiornamento per le prestazioni o una patch di sicurezza critica, l'aggiornamento viene eseguito in sequenza da un dominio di aggiornamento al successivo. L'applicazione in sequenza tramite i domini di aggiornamento evita che l'intero data center risulti non disponibile durante gli aggiornamenti della piattaforma e l'applicazione di patch.
I domini di errore rappresentano le sezioni fisiche del data center e garantiscono la diversità dei rack dei server in un set di disponibilità. I domini di errore sono allineati alla separazione fisica dell'hardware condiviso nel data center. Tale hardware include i componenti hardware per alimentazione, raffreddamento e rete a supporto dei server fisici nei rack.
Se l'hardware che supporta un rack del server diventa non disponibile, l'interruzione influisce solo sul rack del server. Quando si inseriscono le macchine virtuali in un set di disponibilità, vengono distribuite automaticamente tra più domini di errore. Se si verifica un errore hardware, questo influirà solo su alcune macchine virtuali.
Zone di disponibilità
Le zone di disponibilità sono data center fisici in località indipendenti all'interno di un'area geografica. Includono i propri sistemi di alimentazione, raffreddamento e rete. Tenendo conto delle zone di disponibilità al momento della distribuzione delle risorse, è possibile proteggere i carichi di lavoro dalle interruzioni dei data center, mantenendo al tempo stesso la presenza in un'area geografica.
I servizi di zona sono servizi (ad esempio macchine virtuali) che è possibile distribuire in zone specifiche all'interno di un'area. Altri servizi sono i servizi con ridondanza della zona e vengono replicati tra le zone di disponibilità nella specifica area di Azure. Entrambi i tipi evitano che in un'area di Azure siano presenti singoli punti di errore.