Creare servizi dati resilienti
L'organizzazione ha più carichi di lavoro distribuiti in ambienti diversi. Tutti i carichi di lavoro si basano su dati che vengono mantenuti protetti e tempestivi. È possibile adottare varie misure per creare la resilienza per i dati.
In questa unità viene descritto come i gruppi di disponibilità Always On semplificano la replica dei dati. Si vedrà come i backup automatici e il failover automatico nel database SQL di Azure contribuiscono a tenere al sicuro i dati. Si apprenderà anche come usare la funzionalità di replica geografica di Azure Cosmos DB per replicare in modo trasparente i dati in altre aree e renderli accessibili in lettura e scrittura.
Replicare database con i gruppi di disponibilità Always On
I gruppi di disponibilità Always On assicurano la disponibilità elevata per i database SQL di Azure in esecuzione su macchine virtuali.
È possibile archiviare gruppi specifici di database in repliche di disponibilità:
- La replica primaria contiene i database primari.
- La replica secondaria include copie secondarie sincronizzate dei database primari.
Se si verifica un errore, la replica secondaria diventa la destinazione del failover. La replica primaria è leggibile e scrivibile. I dati vengono sincronizzati tra ogni database primario e ogni database secondario associato.
È anche possibile impostare le repliche secondarie in modo che siano leggibili. In questo modo, i client possono accedere ai dati da più database e l'aumento della richiesta viene distribuito tra più repliche.
I gruppi di disponibilità Always On vengono eseguiti su un cluster di failover di Windows Server costituito da un gruppo di computer che operano all'unisono. Questa architettura offre disponibilità elevata per i carichi di lavoro in esecuzione su questi computer. Con i gruppi di disponibilità Always On, ogni nodo (computer) del cluster ospita una replica, primaria o secondaria. Ogni replica contiene un gruppo di database.
È possibile configurare gruppi di disponibilità Always On in Azure creando due set di disponibilità: uno per i nodi del cluster di failover di Windows Server e un altro per i controller di dominio.
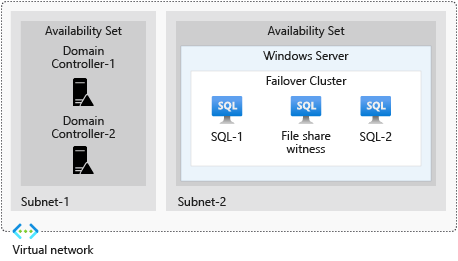
Il cluster di failover di Windows Server deve contenere almeno tre computer. Deve essere presente un computer SQL Server per la replica primaria e un altro per la replica secondaria nel cluster. È possibile usare un terzo computer come server di controllo della condivisione file oppure usare una condivisione file di Azure come server di controllo.
Failover per il database SQL di Azure
È possibile usare gruppi di failover automatico del database SQL per configurare il failover e la replica di gruppi di database in un server di database SQL. È necessario riunire criteri definiti in grado di eseguire i failover in base alle esigenze. Se necessario, si può anche attivare manualmente i failover. Se si verifica un errore, il database SQL può eseguire automaticamente il failover dei database in un server secondario in un'area secondaria.
I database secondari con failover automatico del database SQL possono essere usati come database leggibili. È possibile usare questi database secondari per rendere disponibile l'accesso in lettura ai dati per tutti i client che si connettono e per distribuire l'utilizzo e la richiesta tra database primari e secondari.
Se si usano criteri di failover automatico e si verifica un errore in almeno un database nel gruppo di database primario, viene attivato un failover automatico nei database secondari. Gli endpoint restano invariati durante il failover. Una volta che il problema che ha causato l'errore è stato risolto e si è pronti, è possibile eseguire il failback nella posizione originale. È possibile eseguire manualmente il failover dei gruppi nella posizione originale.
I database di un server di database possono essere inclusi in un unico gruppo di failover automatico. È anche possibile inserire tutti i database in un pool elastico in un unico gruppo di failover. Quando i database primari fanno parte di un pool elastico, anche i database secondari vengono sottoposti a provisioning in un pool elastico. Questo pool ha lo stesso nome del pool elastico primario.
Backup automatico per il database SQL di Azure
Il database SQL di Azure può eseguire backup dei database archiviati da un periodo di tempo compreso tra 7 e 35 giorni. Il database SQL usa l'archiviazione con ridondanza geografica per archiviare i backup e fornisce accesso in lettura ai dati in un'area diversa. I database sono sicuri anche se si verifica un problema in un data center.
È possibile estendere la conservazione dei backup per un massimo di 10 anni stabilendo criteri di conservazione a lungo termine su singoli database o pool elastici. Tutti i backup del database nel database SQL vengono crittografati nello stato inattivo. La tecnologia Transparent Data Encryption è abilitata per impostazione predefinita in tutti i database SQL creati.
Il database SQL esegue automaticamente i backup in background. Crea backup dei database a intervalli diversi, a seconda del tipo di backup. Ad esempio, crea:
- Backup dei log delle transazioni a intervalli di 5-10 minuti.
- Backup completi dei database ogni settimana. Il primo backup completo viene eseguito non appena viene creato il database. Il tempo necessario per completare un backup completo di un database SQL dipende dalle dimensioni del database.
- Backup differenziali di tutti i dati modificati dall'ultimo backup completo ogni 12 ore.
Il database SQL conserva i backup in BLOB di archiviazione che forniscono l'accesso in lettura. Copia quindi questi backup in un data center associato.
I database possono essere ripristinati a una versione di cui è stato eseguito il backup. Se è stata configurata la conservazione a lungo termine, questo backup potrebbe essere disponibile per un massimo di 10 anni. È possibile ripristinare i database eliminati fino al momento precedente all'eliminazione e fino al limite di conservazione indicato nei criteri di conservazione.
Il database SQL può ripristinare database in un'area geografica diversa. Questo processo viene eseguito tramite il ripristino geografico, che permette di ripristinare i database da un'area a un'altra se si verifica un problema in un'intera area.
Replica geografica con Azure Cosmos DB
Azure Cosmos DB è un servizio di database multimodello a bassa latenza che consente di distribuire i dati a livello globale e di dimensionare l'ambiente in modo elastico e rapido.
In Azure Cosmos DB tutti i dati vengono replicati in modo trasparente nelle aree impostate per l'account Azure Cosmos DB in uso. Azure Cosmos DB salva i dati all'interno di contenitori che costituiscono il database e tutti i contenitori sono partizionati.
Tutte le partizioni vengono replicate tra ogni area. All'interno di ogni area le partizioni vengono copiate prima della distribuzione di ogni copia tra i domini di errore.
I dati vengono replicati almeno quattro volte. È possibile configurare un account Azure Cosmos DB e impostare il database Azure Cosmos DB in modo da distribuirlo in cinque aree. Quando si configura questo database per cinque aree, Azure Cosmos DB garantisce la disponibilità di almeno 4 x 5 copie di tutti i dati.
È consigliabile configurare il database di Azure Cosmos DB in modo che si estenda almeno su due aree. Più sono le aree geografiche, più resilienti diventeranno i dati. È inoltre consigliabile impostare in modo esplicito il database Azure Cosmos DB affinché abbia più aree di scrittura, in modo da poter eseguire operazioni di lettura e scrittura da tutte le aree.
È anche possibile configurare la ridondanza della zona per alcune aree. Con questa funzionalità, Azure Cosmos DB inserisce le repliche dei dati in più zone di disponibilità in ogni singola area, per un livello di resilienza aggiuntivo.