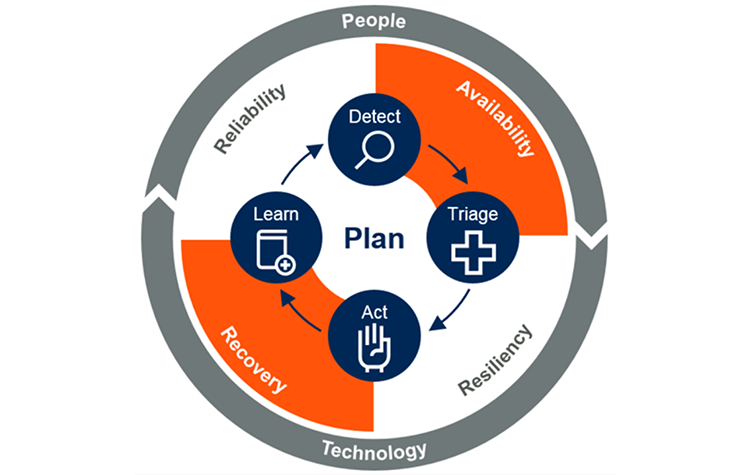
Esplorare operazioni continue
Operazioni continue è una delle otto funzionalità della tassonomia di DevOps.
Perché operazioni continue è necessaria
I sistemi complessi talvolta non funzionano e possono causare guasti e interruzioni costosi. Verranno ora esaminati alcuni esempi.
| Società | Evento |
|---|---|
Delta Air Lines |
Nell'agosto 2016 Delta è stata costretta ad annullare 2.300 voli quando un singolo componente di apparecchiatura malfunzionante ha causato un blackout nel centro operativo di Atlanta. Il costo per la compagnia è stato di 150 milioni di dollari USA. |
FedEx e Uk National Servizio integrità |
Nel maggio 2017, il ransomware WannaCry ha causato interruzioni operative a FedEx. Una sussidiaria di FedEx ha segnalato 300 milioni di dollari USA di perdite. Il Servizio sanitario nazionale del Regno Unito è stata un'altra vittima del ransomware, che ha bloccato l'accesso ai suoi computer e ad apparecchiature mediche essenziali e ha costretto alcuni ospedali a deviare le ambulanze ad altre località. |
Amazon S3 |
Nel febbraio 2017 l'errore di un operatore ha causato un'interruzione di quattro ore dei servizi di archiviazione di base di Amazon, il che ha avuto diversi effetti su alcune proprietà Web significative, ad esempio Alexa, IFTTT, Quora e Trello. |
| LinkedIn ha riscontrato un problema che ha ostacolato il lavoro del reparto di sviluppo per due mesi. | |
Equifax |
Nel 2017 Equifax ha riscontrato una violazione della sicurezza che ha comportato l'esposizione delle informazioni personali di oltre 160 milioni di utenti. Questo verrà discusso più dettagliatamente in Sicurezza continua. |
Impatto e costi di una violazione della sicurezza per le aziende
I costi di una violazione della sicurezza spesso vanno oltre la perdita di vendite e di attendibilità di un'azienda. Questi costi possono comprendere:
- Risposta e notifica
- Vi sono costi operativi e di servizio per informare le parti interessate, come previsto dalla legge. Questi costi includono spesso anche costi aggiuntivi per i call center, il supporto del reparto di pubbliche relazioni e i servizi di monitoraggio del credito.
- Perdita della produttività e del fatturato dei dipendenti
- Il consulente legale di Yahoo si è dimesso e il CEO non ha ricevuto il bonus annuale per il 2016.
- Cause e insediamenti
- Target ha pagato 18,5 milioni di dollari USA a 47 Stati americani.
- Multe e risposte normative
- Con i nuovi criteri di protezione dei dati in vigore nell'Unione europea dal 2018, la multa ammonta al 4% dei ricavi annuali o a 20 milioni di EUR, se questo valore è superiore.
- Costi di recupero del marchio
- La società mineraria Codan ha visto un calo del fatturato da 45 milioni a 9,2 milioni di dollari USA nel giro di un anno.
- Altre responsabilità
- Verizon ha pagato 350 milioni di dollari USA in meno per Yahoo dopo due massicce violazioni della sicurezza.
Potrebbero essere necessari anche ulteriori requisiti di sicurezza e controllo.
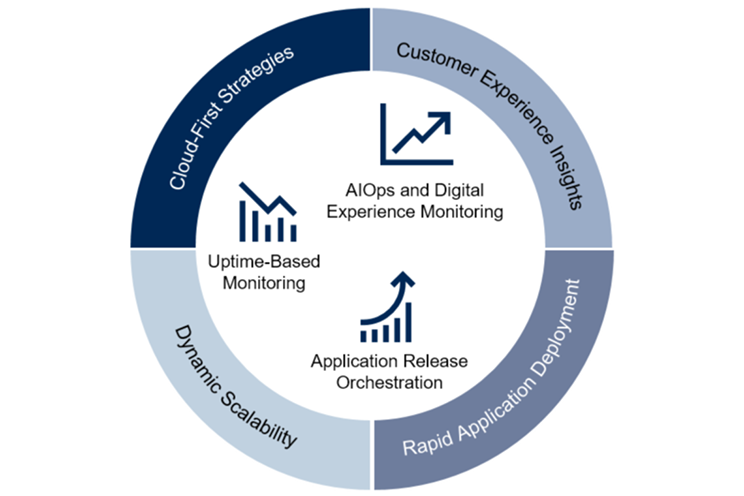
Disponibilità e ripristino in operazioni continue
In base a un sondaggio di Gartner, i responsabili IT e i dirigenti aziendali si aspettano che il 47% delle applicazioni di produzione venga eseguito in cloud pubblico entro il 2020.
In un momento in cui è possibile distruggere interi data center con una riga di codice, l'attenzione dei responsabili I/O sulla disponibilità e il recupero degli ambienti di produzione deve cambiare. I nuovi criteri di distribuzione stanno cambiando il modo in cui vengono garantite le funzionalità di disponibilità e ripristino di applicazioni e infrastrutture.
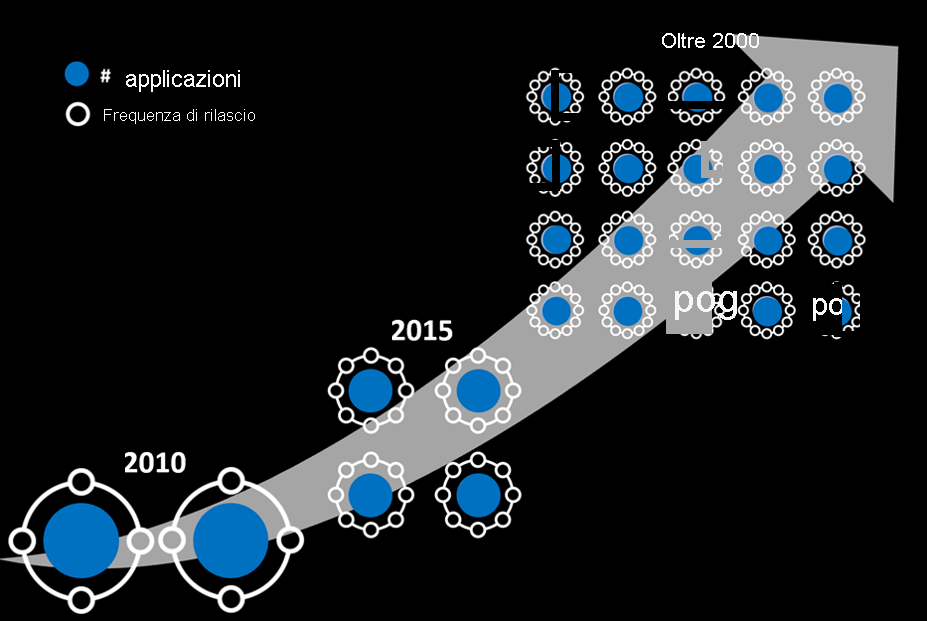
Un numero sempre maggiore di app e versioni nell'ambiente di produzione
Gli indicatori di prestazioni chiave per le prestazioni di recapito del software sono:
- Lead time per la modifica
- Frequenza di distribuzione
- Tempo medio di ripristino
- Tasso di errore delle modifiche
I team che lavorano per aumentare la velocità ma non investono a sufficienza nella creazione di qualità nel processo registreranno errori più gravi e tempi più lunghi per il ripristino del servizio. I team che integrano la qualità nel processo raggiungono sia velocità che stabilità.
Il numero di applicazioni Web e per dispositivi mobili e la frequenza delle versioni delle applicazioni sono aumentati notevolmente. Anche il codice diventa sempre più complesso.
Nota
Una parte importante del valore di DevOps in generale consiste nella ricerca del giusto equilibrio tra l'innovazione (velocità) e la continuità aziendale (controllo).
Che cos'è operazioni continue?
Importante
Operazioni continue riduce o elimina la necessità di tempi di inattività o interruzioni pianificati, ad esempio la manutenzione pianificata. Il monitoraggio continuo dell'infrastruttura, delle applicazioni e dei servizi deve essere associato, se possibile, alla correzione automatica. Un utente non deve mai sapere quando si verifica un aggiornamento o un rilascio incrementale.
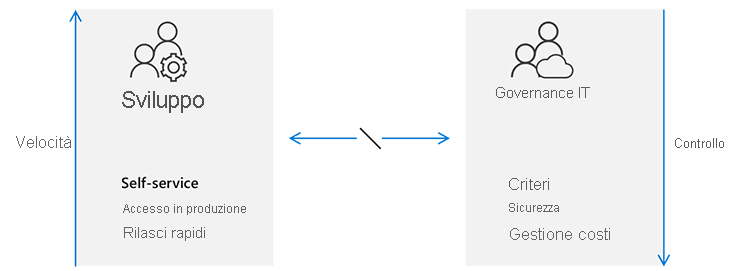
Confrontare le procedure operative tradizionali con quelle continue
In un modello aziendale tradizionale, IT impone le versioni rilasciate e controlla tutti gli utenti attraverso processi e procedure rigidi.
Questo approccio causa un disallineamento tra i team di sviluppo e la governance IT. I team di sviluppo sono per lo più agili, si concentrano sulla velocità e ci si aspetta che rilascino versioni ogni volta che vogliono. Per loro, la governance IT sembra essere un collo di bottiglia non allineato con gli obiettivi di commercializzazione delle esigenze aziendali attuali.
Importante
Quando viene implementato correttamente, DevOps può offrire sia l'innovazione (velocità) che la continuità aziendale (controllo).
In un ciclo di vita di sviluppo tradizionale:
- I test vengono eseguiti subito prima del go-live.
- Il monitoraggio viene spesso trasferito.
- La sicurezza viene spesso consultata nelle fasi di test.
- Durante il trasferimento, è necessario eseguire i controlli di sicurezza del codice e tutti i controlli di gestione dei servizi.
- La conformità spesso non fa parte del trasferimento, ma qualcosa che "compare" durante lo stato operativo di un servizio.
- La pianificazione della resilienza e della continuità viene eseguita come parte della fase di progettazione, ma il test effettivo degli scenari correlati viene spesso eseguito solo durante le fasi delle operazioni o di test, il che può causare modifiche alla configurazione, rielaborazioni e lavoro sprecato.
- La collaborazione tra operazioni, sicurezza e conformità e gli sviluppatori viene spesso eseguita in modo reattivo attraverso processi di gestione degli eventi imprevisti e dei problemi.
- Il fatto di lasciare l'automazione alle fasi finali fa spesso sì che rimangano poche risorse per completare l'operazione.
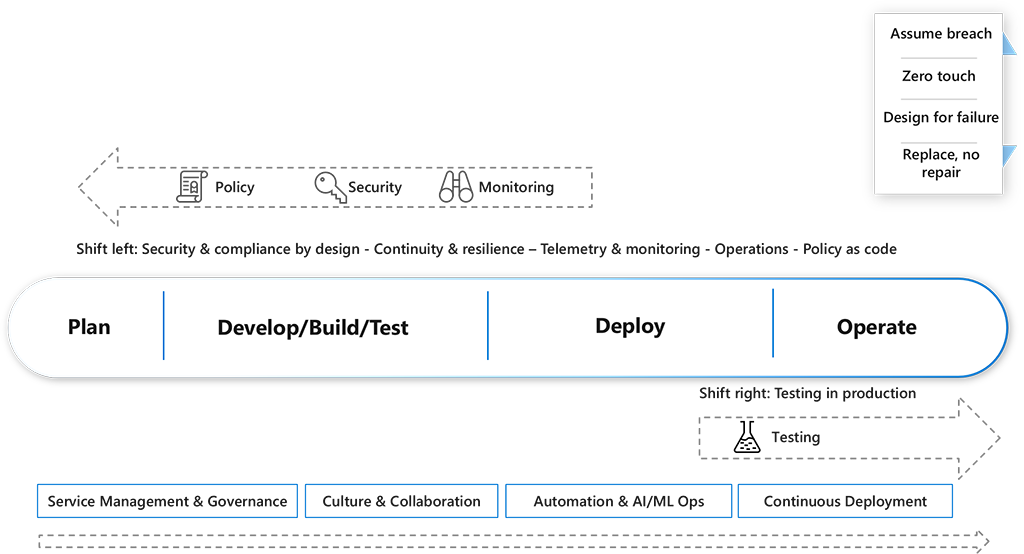
Nuovi metodi e modi di lavorare e nuove tecnologie richiedono un nuovo approccio alle operazioni continue. Le seguenti otto principali procedure di operazioni continue sono emerse e continuano a evolversi:
- Sicurezza e conformità by design riconoscono che determinati standard e requisiti normativi e aziendali, come la tracciabilità e la verificabilità, devono essere presi in considerazione in fase di progettazione durante la progettazione di ambienti cloud altamente automatizzati.
- Continuità e resilienza richiedono una stretta collaborazione con l'organizzazione per garantire che le esigenze aziendali si rispecchino nella progettazione e nell'implementazione.
- Telemetria e monitoraggio possono essere usati per individuare i criteri di utilizzo dei clienti, nuove esigenze potenziali e informazioni dettagliate sui punti in cui gli utenti rilevano errori. Questi strumenti consentono inoltre di garantire che il valore arrivi agli utenti.
- Gestione dei servizi è una conversazione diversa nelle impostazioni cultura di DevOps:
- Consente di passare ai mezzi di cui si è proprietari. Lo si crea, lo si esegue e quando si guasta lo si aggiusta.
- Concentra l'attenzione su ciò che è necessario.
- Dà forza alla governance.
- Semplifica la trasparenza.
- La cultura e la collaborazione sono essenziali per le operazioni continue. Spesso è necessario che le organizzazioni modifichino il modo in cui lavorano per semplificare la trasformazione in direzione dei team DevOps. La collaborazione è essenziale anche durante la progettazione per la sicurezza e la resilienza.
- Le Operazioni di AI e ML sono aspetti importanti che rendono DevOps (e cloud) diversi dai tradizionali team delle operazioni. L'attenzione deve essere incentrata sull'automazione dell'intero sistema (automazione sistemica) e non solo di un'area.
- La distribuzione continua usa pipeline di versione moderne per consentire ai team di sviluppo di distribuire nuove funzionalità in modo rapido e sicuro, consentendo un flusso continuo di valore al cliente e riducendo il tempo necessario per correggere i problemi.
- I test shift-right usano procedure come i lanci al buio, i flag funzionalità, il monitoraggio e i test A/B. I team possono quindi continuare a eseguire test per verificare che un'applicazione soddisfi le aspettative di comportamento, prestazioni e disponibilità durante l'uso in produzione.
Per evolversi in direzione dell'approccio DevOps, è necessario che si verifichi un importante cambio di paradigma nella cultura in modo da fornire valore aziendale con un approccio IT moderno.
| IT tradizionale | IT moderno | |
|---|---|---|
| DNA | Intermediazione | Rimozione dell'intermediazione |
| Recapito dei servizi | Basato su ondate | Basato sull'iterazione continua |
| Stabilità del servizio | Progettazione anticipando la riuscita (HA/ridondante) | Progettazione anticipando i problemi (resiliente) |
| Livelli di delega | Silos IT | Servizi end-to-end |
| Processi | In documenti, ottimizzati, riprogettati | Self-Service, conoscenza, a basso attrito, automatizzati |
| Automazione | Isolata, avviata manualmente | Sistemica, attivata, automatica |
| Monitoraggio | Elementi, incentrato sugli errori | Servizi, incentrato sulle funzionalità end-to-end |
| Supporto | Service Desk/centro contatti | Assistenza clienti/self-service |
| Ciclo di vita | N-1 o precedente | N, N+1 |
| Configurazione/gestione asset | Individuata/Configurazione manuale | Prescritta, dichiarativa, automatizzata |
Queste modifiche generano processi semplificati e automatizzati, incentivi ai risultati allineati, rischi ridotti e un approccio incentrato sul cliente.