Identificare i piani di query problematici
L'approccio tipico da adottare per risolvere i problemi relativi alle prestazioni delle query comporta innanzitutto l'identificazione della query problematica, in genere quella che utilizza la maggior parte delle risorse di sistema e quindi il recupero del piano di esecuzione. Esistono due scenari principali. Uno scenario è che la query esegue costantemente prestazioni scarse. Ciò può essere dovuto a diversi problemi, ad esempio vincoli di risorse hardware (anche se questo in genere non influisce su una singola query in esecuzione in isolamento), struttura di query non ottimale, impostazioni di compatibilità del database, indici mancanti o scelte di piano scarse da parte di Query Optimizer. Il secondo scenario consiste nel fatto che la query funziona correttamente in alcune esecuzioni, ma in altre in modo non corretto. Questa incoerenza può essere causata da fattori come l'asimmetria dei dati in una query con parametri, che ha un piano efficiente per alcune esecuzioni e uno scarso per altri. Altri fattori comuni includono il blocco, in cui una query attende il completamento di un'altra query per ottenere l'accesso a una tabella o conflitti hardware.
Verranno ora esaminati in modo più dettagliato ognuno di questi scenari.
Vincoli hardware
I vincoli hardware in genere non si manifestano durante le singole esecuzioni di query, ma diventano evidenti nel carico di produzione quando i thread e la memoria della CPU sono limitati. La contesa della CPU può essere rilevata osservando il contatore del monitoraggio delle prestazioni '% tempo processore', che misura l'utilizzo della CPU del server. In SQL Server, i tipi di attesa SOS_SCHEDULER_YIELD e CXPACKET possono indicare un utilizzo elevato della CPU. Le prestazioni del sistema di archiviazione scarse possono rallentare anche le esecuzioni di singole query ottimizzate. Le prestazioni di archiviazione sono meglio monitorate a livello di sistema operativo usando contatori di monitoraggio delle prestazioni Disk Seconds/Read e Disk Seconds/Write, che misurano i tempi di completamento dell'operazione di I/O. SQL Server registra prestazioni di archiviazione scarse se un I/O richiede più di 15 secondi. Attese PAGEIOLATCH_SH elevate in SQL Server possono indicare problemi di prestazioni di archiviazione. Le prestazioni hardware vengono in genere valutate all'inizio del processo di risoluzione dei problemi a causa della facilità di valutazione.
La maggior parte dei problemi di prestazioni del database deriva da modelli di query non ottimali, che possono comportare una pressione eccessiva sull'hardware. Ad esempio, gli indici mancanti possono causare un utilizzo elevato di CPU, archiviazione e memoria recuperando più dati del necessario. È consigliabile risolvere e ottimizzare le query non ottimali prima di affrontare i problemi hardware. Si esamini quindi l'ottimizzazione delle query.
Costrutti di query non ottimali
I database relazionali eseguono al meglio operazioni basate su set, che modificano i dati (INSERT, UPDATE, DELETE e SELECT) nei set, producendo un singolo valore o un set di risultati. L'alternativa è l'elaborazione basata su righe, l'uso di cursori o cicli while, che aumentano in modo lineare con il numero di righe interessate, una scalabilità problematica man mano che i volumi di dati aumentano.
Il rilevamento di un uso non ottimale di operazioni basate su righe con cursori o cicli WHILE è importante, ma esistono altri anti-pattern di SQL Server da riconoscere. Le funzioni con valori di tabella (TVFS), in particolare le funzioni con istruzioni multiple, causavano modelli di piano di esecuzione problematici prima di SQL Server 2017. Gli sviluppatori usano spesso funzioni con più istruzioni per eseguire più query all'interno di una singola funzione e aggregare i risultati in una singola tabella. Tuttavia, l'uso delle TVF può comportare penalità per le prestazioni.
SQL Server include due tipi di file CONF: inline e multi-statement. Le funzioni di tabella inline vengono considerate come viste, mentre le funzioni CONF con più istruzioni vengono considerate come tabelle durante l'elaborazione delle query. Poiché le funzioni con valori televisivi sono dinamiche e non dispongono di statistiche, SQL Server usa un conteggio delle righe fisso per stimare il costo del piano di query. Questo può essere corretto per i conteggi di righe di piccole dimensioni, ma inefficienti per migliaia o milioni di righe.
Un altro anti-pattern è l'uso di funzioni scalari, che presentano problemi di stima ed esecuzione simili. Microsoft ha apportato miglioramenti significativi delle prestazioni con l'elaborazione di query intelligenti, con livelli di compatibilità 140 e 150.
SARGability
Il termine SARGable nei database relazionali fa riferimento a un predicato (clausola WHERE) formattato per usare un indice per velocizzare l'esecuzione delle query. I predicati nel formato corretto sono detti argomenti di ricerca, in inglese 'Search Argument" da cui l'acronimo SARG. In SQL Server, l'uso di un SARG significa che l'utilità di ottimizzazione valuta l'uso di un indice non cluster sulla colonna a cui fa riferimento il SARG per un'operazione SEEK, invece di eseguire la scansione dell'intero indice o dell'intera tabella per recuperare un valore.
La presenza di un SARG non garantisce l'uso di un indice per un seek. Gli algoritmi di costo di Optimizer potrebbero comunque determinare che l'indice è troppo costoso, soprattutto se un SARG fa riferimento a una percentuale elevata di righe in una tabella. L'assenza di un SARG indica che l'ottimizzatore non valuterà un seek su un indice non cluster.
Esempi di espressioni non SARGable includono quelli con una clausola LIKE che usa un carattere jolly all'inizio della stringa, ad esempio WHERE lastName LIKE '%SMITH%'. Altri predicati non SARGable si verificano quando si usano funzioni in una colonna, ad esempio WHERE CONVERT(CHAR(10), CreateDate,121) = '2020-03-22'. Queste query vengono in genere identificate esaminando i piani di esecuzione per le analisi di indici o tabelle in cui le ricerche devono verificarsi in caso contrario.
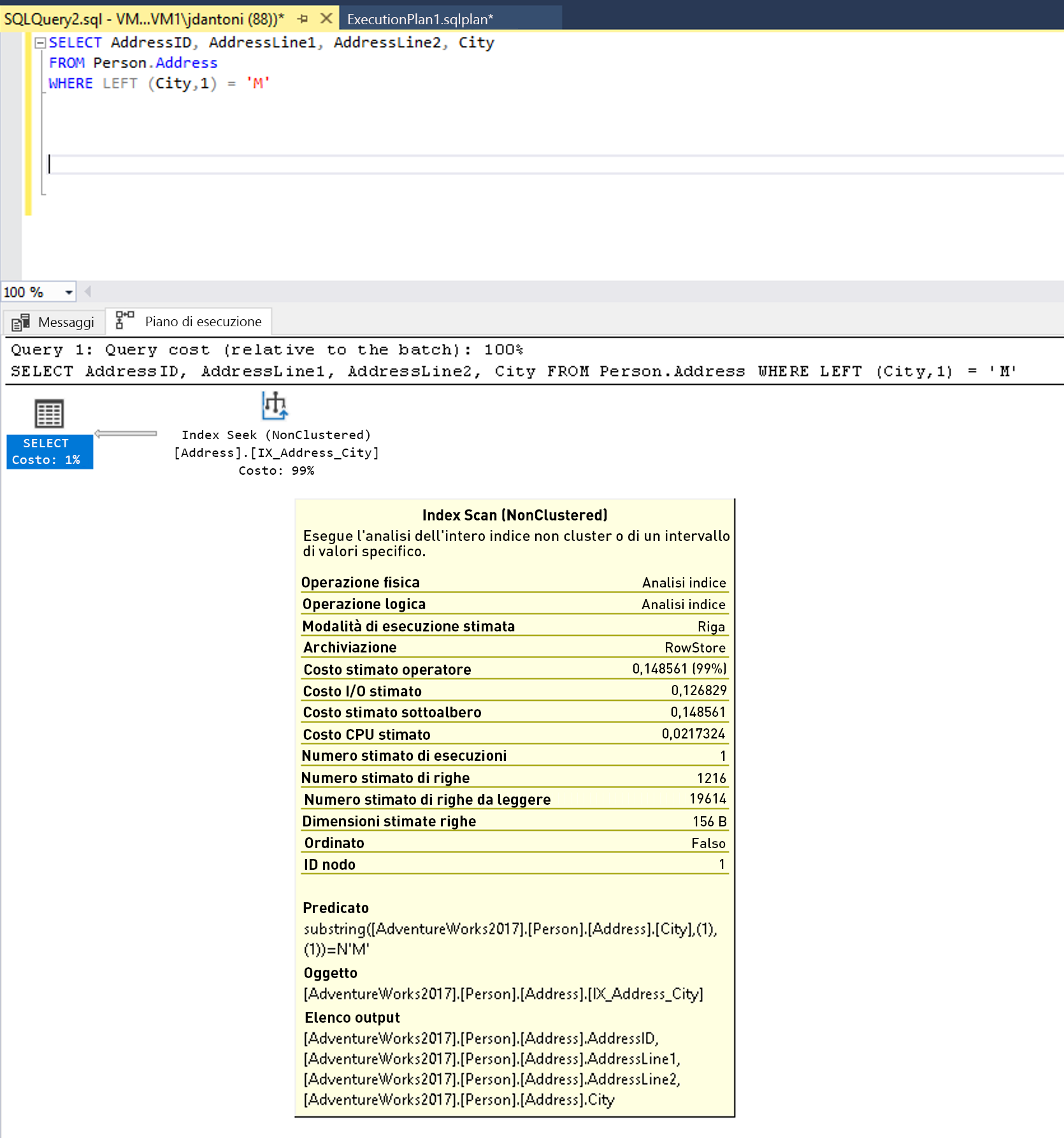
Nella colonna City è presente un indice che viene usato nella WHERE clausola della query e mentre viene usato in questo piano di esecuzione precedente, è possibile vedere che l'indice viene analizzato, ovvero l'intero indice viene letto. La funzione LEFT nel predicato rende questa espressione non SARGable. L'utilità di ottimizzazione non valuterà l'uso di una ricerca nell'indice sulla colonna City.
Questa query può essere scritta in modo da usare un predicato SARGable. L'ottimizzatore valuterà quindi un SEEK sull'indice della colonna City. Un operatore index seek, in questo caso, leggerebbe un set di righe più piccolo.
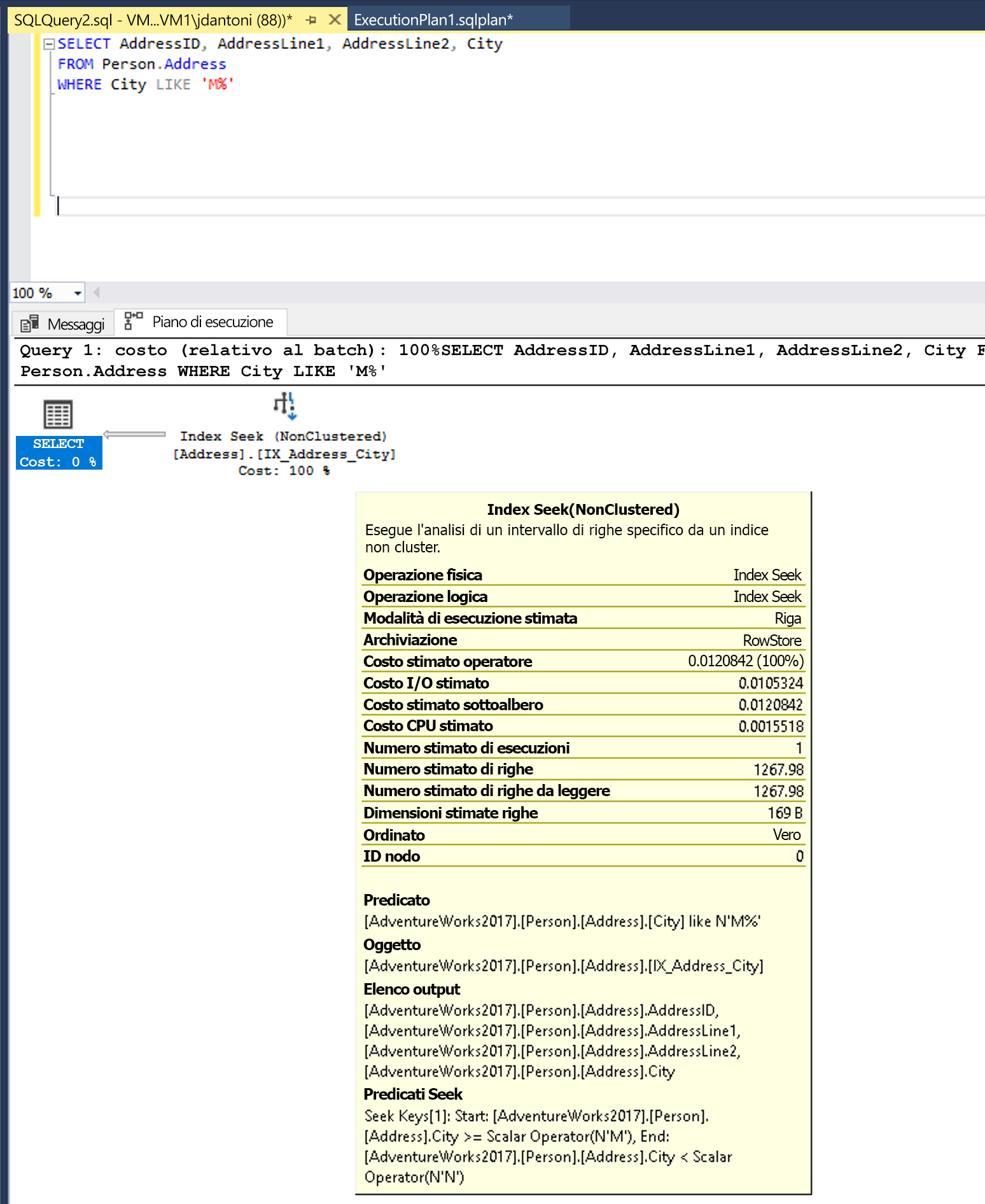
La modifica della funzione LEFT in LIKE ottiene una ricerca di indice.
Nota
La parola chiave LIKE, in questo esempio, non ha un carattere jolly a sinistra, quindi cerca le città che iniziano con M. Se fosse "a due lati" o iniziasse con un carattere jolly ('%M%' o '%M') sarebbe non SARGable. Si stima che l'operazione SEEK restituisca 1.267 righe o circa il 15% della stima per la query con il predicato non SARGable.
Altri anti-schemi di sviluppo del database trattano il database come servizio anziché come archivio dati. L'uso di un database per convertire i dati in JSON, manipolare le stringhe o eseguire calcoli complessi può causare un utilizzo eccessivo della CPU e una maggiore latenza. Le query che tentano di recuperare tutti i record e quindi di eseguire calcoli nel database possono causare un utilizzo eccessivo di CPU e I/O. Idealmente, è consigliabile usare il database per operazioni di accesso ai dati e costrutti di database ottimizzati come l'aggregazione.
Indici mancanti
I problemi di prestazioni più comuni per gli amministratori di database derivano dalla mancanza di indici utili, causando al motore di leggere più pagine del necessario per restituire i risultati delle query. Mentre gli indici usano risorse (che influiscono sulle prestazioni di scrittura e sullo spazio di utilizzo), le prestazioni spesso superano i costi aggiuntivi delle risorse. I piani di esecuzione con questi problemi possono essere identificati dall'operatore di query Clustered Index Scan o dalla combinazione di Ricerca indice non cluster e Ricerca chiave, che indica le colonne mancanti in un indice esistente.
Il motore di database consente di segnalare indici mancanti nei piani di esecuzione. I nomi e i dettagli degli indici consigliati sono disponibili tramite la vista a gestione dinamica sys.dm_db_missing_index_details. Altri DMV come sys.dm_db_index_usage_stats e sys.dm_db_index_operational_stats evidenziano l'utilizzo degli indici esistenti.
L'eliminazione di un indice inutilizzato può essere sensibile. Le DMV di indice mancanti e gli avvisi di piano devono essere punti di partenza per l'ottimizzazione delle query. È fondamentale comprendere le query chiave e compilare gli indici per supportarli. Non è consigliabile creare tutti gli indici mancanti senza valutarli nel contesto.
Statistiche mancanti e non aggiornate
Comprendere l'importanza delle statistiche di colonna e indice per Query Optimizer è fondamentale. È anche essenziale riconoscere le condizioni che possono causare statistiche non aggiornate e come questo problema può manifestarsi in SQL Server. Per impostazione predefinita, le offerte SQL di Azure hanno le statistiche di aggiornamento automatico impostate su ON. Prima di SQL Server 2016, il comportamento predefinito delle statistiche di aggiornamento automatico non era aggiornare le statistiche fino al numero di modifiche apportate alle colonne nell'indice pari a circa il 20% del numero di righe in una tabella. Questo comportamento potrebbe comportare modifiche significative ai dati che modificano le prestazioni delle query senza aggiornare le statistiche, causando piani non ottimali basati su statistiche obsolete.
Prima di SQL Server 2016, il flag di traccia 2371 poteva essere utilizzato per modificare il numero richiesto di modifiche in un valore dinamico, quindi man mano che la tabella cresceva, la percentuale di modifiche di riga necessarie per attivare un aggiornamento delle statistiche diminuiva. Le versioni più recenti di SQL Server, del database SQL di Azure e di Istanza gestita di SQL di Azure supportano questo comportamento per impostazione predefinita. La funzione sys.dm_db_stats_properties a gestione dinamica mostra l'ultima volta in cui sono state aggiornate le statistiche e il numero di modifiche apportate dall'ultimo aggiornamento, consentendo di identificare rapidamente le statistiche che potrebbero richiedere aggiornamenti manuali.
Scelte non ottimali dell'utilità di ottimizzazione
Anche se Query Optimizer esegue un buon lavoro per ottimizzare la maggior parte delle query, esistono alcuni casi limite in cui l'ottimizzatore basato sui costi può prendere decisioni di impatto che non sono completamente comprensibili. Esistono diversi modi per risolvere questo problema, tra cui l'uso di hint per le query, flag di traccia, forzatura del piano di esecuzione e altri aggiustamenti con lo scopo di ottenere un piano di query stabile e ottimale. Microsoft può contare su un team di supporto che può fornire assistenza per affrontare questi scenari.
Nell'esempio seguente del database AdventureWorks2017 viene utilizzato un suggerimento per la query per indicare all'ottimizzatore del database di usare sempre il nome della città di Seattle. Questo hint non garantisce il piano di esecuzione migliore per tutti i valori della città, ma è prevedibile. Il valore di "Seattle" per @city_name verrà usato solo durante l'ottimizzazione. Durante l'esecuzione viene utilizzato il valore effettivamente fornito (‘Ascheim’).
DECLARE @city_name nvarchar(30) = 'Ascheim',
@postal_code nvarchar(15) = 86171;
SELECT *
FROM Person.Address
WHERE City = @city_name
AND PostalCode = @postal_code
OPTION (OPTIMIZE FOR (@city_name = 'Seattle');
Come illustrato nell'esempio, la query usa un hint (la clausola OPTION) per indicare all'utilità di ottimizzazione di usare un valore di variabile specifico per compilare il piano di esecuzione.
Analisi dei parametri
SQL Server memorizza nella cache i piani di esecuzione delle query per usi futuri. Poiché il processo di recupero del piano di esecuzione è basato sul valore hash di una query, il testo della query deve essere identico per ogni esecuzione della query per il piano memorizzato nella cache da usare. Per supportare più valori nella stessa query, molti sviluppatori usano parametri, passati tramite stored procedure, come illustrato nell'esempio seguente:
CREATE PROC GetAccountID (@Param INT)
AS
<other statements in procedure>
SELECT accountid FROM CustomerSales WHERE sales > @Param;
<other statements in procedure>
RETURN;
-- Call the procedure:
EXEC GetAccountID 42;
Le query possono anche essere parametrizzate in modo esplicito usando la procedura sp_executesql. Tuttavia, la parametrizzazione esplicita delle singole query viene eseguita tramite l'applicazione di una qualche forma di istruzione PREPARE ed EXECUTE (a seconda dell'API). Quando il motore di database esegue la query per la prima volta, ottimizza la query in base al valore iniziale del parametro, in questo caso 42. Questo comportamento, detto analisi dei parametri, consente di ridurre il carico di lavoro complessivo di compilazione delle query nel server. Tuttavia, in caso di asimmetria dei dati, le prestazioni delle query potrebbero variare notevolmente.
Ad esempio, una tabella con 10 milioni di record e il 99% di tali record ha un ID pari a 1 e l'altro 1% sono numeri univoci, le prestazioni si basano sull'ID usato inizialmente per ottimizzare la query. Queste prestazioni sensibilmente fluttuanti sono indicative della presenza di un'asimmetria dei dati e non rappresentano un problema intrinseco dell'analisi dei parametri. Questo comportamento è un problema di prestazioni piuttosto comune di cui è importante tenere conto. È necessario conoscere le opzioni a disposizione per arginare il problema. Esistono diversi modi per risolvere questo problema, ma ognuno presenta pro e contro:
- Usare l'hint
RECOMPILEnella query o l'opzione di esecuzioneWITH RECOMPILEnelle stored procedure. Questo hint determina la ricompilazione della query o della routine ogni volta che viene eseguita, che aumenterà l'utilizzo della CPU nel server, ma userà sempre il valore del parametro corrente. - È possibile usare l'hint per la query
OPTIMIZE FOR UNKNOWN. Questo hint fa sì che Optimizer scelga di non eseguire l'analisi dei parametri e di confrontare il valore con l'istogramma dei dati della colonna. Questa opzione non offrirà il migliore piano possibile, ma consentirà un piano di esecuzione coerente. - Riscrivere la stored procedure o le query aggiungendo la logica per i valori dei parametri in modo da usare RECOMPILE solo per i parametri problematici noti. Nell'esempio seguente, se il parametro SalesPersonID è NULL, la query viene eseguita con
OPTION (RECOMPILE).
CREATE OR ALTER PROCEDURE GetSalesInfo (@SalesPersonID INT = NULL)
AS
DECLARE @Recompile BIT = 0
, @SQLString NVARCHAR(500)
SELECT @SQLString = N'SELECT SalesOrderId, OrderDate FROM Sales.SalesOrderHeader WHERE SalesPersonID = @SalesPersonID'
IF @SalesPersonID IS NULL
BEGIN
SET @Recompile = 1
END
IF @Recompile = 1
BEGIN
SET @SQLString = @SQLString + N' OPTION(RECOMPILE)'
END
EXEC sp_executesql @SQLString
,N'@SalesPersonID INT'
,@SalesPersonID = @SalesPersonID
GO
Questo esempio è una buona soluzione, ma richiede un impegno di sviluppo abbastanza elevato e una conoscenza approfondita della distribuzione dei dati. Richiede manutenzione man mano che i dati cambiano.