Tipi di modello di Machine Learning
Annotazioni
Per altri dettagli, vedi la scheda Testo e immagini .
Esistono più tipi di Machine Learning ed è necessario applicare il tipo appropriato a seconda di ciò che si sta tentando di stimare. Una suddivisione dei tipi comuni di Machine Learning è illustrata nel diagramma seguente.
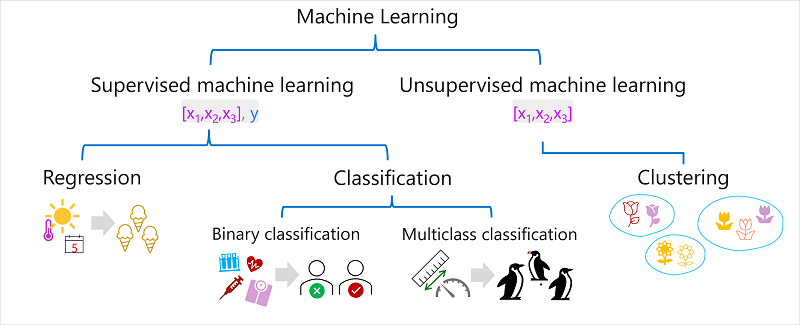
Apprendimento automatico con supervisione
L'apprendimento automatico supervisionato è un termine generale per gli algoritmi di Machine Learning in cui i dati di training includono valori di funzionalità e valori di etichetta noti. L'apprendimento automatico supervisionato viene usato per eseguire il training dei modelli determinando una relazione tra le funzionalità e le etichette nelle osservazioni precedenti, in modo che le etichette sconosciute possano essere stimate per le funzionalità nei casi futuri.
Regressione
La regressione è una forma di Machine Learning supervisionato in cui l'etichetta stimata dal modello è un valore numerico. Per esempio:
- Il numero di gelati venduti in un determinato giorno, in base alla temperatura, alle precipitazioni e alla velocità del vento.
- Il prezzo di vendita di una proprietà in base alle sue dimensioni in piedi quadrati, il numero di camere da letto che contiene e metriche socio-economiche per la sua posizione.
- L'efficienza del carburante (in miglia per gallone) di un'auto in base alle dimensioni del motore, al peso, alla larghezza, all'altezza e alla lunghezza.
Classificazione
La classificazione è una forma di Machine Learning supervisionato in cui l'etichetta rappresenta una categorizzazione o una classe. Esistono due scenari di classificazione comuni.
Classificazione binaria
Nella classificazione binaria, l'etichetta determina se l'elemento osservato è (o non è) un'istanza di una classe specifica. In alternativa, i modelli di classificazione binaria prevedono uno dei due risultati che si escludono a vicenda. Per esempio:
- Se un paziente è a rischio di diabete in base a metriche cliniche come peso, età, livello di glucosio nel sangue e così via.
- Indica se un cliente bancario non sarà in grado di saldare un prestito in base al reddito, alla storia creditizia, all'età e ad altri fattori.
- Indica se un cliente della lista di distribuzione risponderà positivamente a un'offerta di marketing in base agli attributi demografici e agli acquisti precedenti.
In tutti questi esempi, il modello stima una stima binaria true/false o positiva/negativa per una singola classe possibile.
Classificazione multiclasse
La classificazione multiclasse estende la classificazione binaria per stimare un'etichetta che rappresenta una delle più classi possibili. Ad esempio:
- Le specie di pinguino (Adelie, Gentoo o Chinstrap) basate sulle sue misurazioni fisiche.
- Il genere di un film (commedia, horror, romanticismo, avventura o fantascienza) basato sul suo cast, regista e budget.
Nella maggior parte degli scenari che coinvolgono un set noto di più classi, la classificazione multiclasse viene usata per stimare etichette che si escludono a vicenda. Ad esempio, un pinguino non può essere sia un Gentoo che un Adelie. Esistono tuttavia anche alcuni algoritmi che è possibile usare per eseguire il training di modelli di classificazione con più etichette , in cui possono essere presenti più etichette valide per una singola osservazione. Ad esempio, un film potrebbe essere categorizzato sia come fantascienza che come commedia.
Apprendimento automatico senza supervisione
L'apprendimento automatico non supervisionato prevede il training di modelli che usano dati costituiti solo da valori di funzionalità senza etichette note. Gli algoritmi di Machine Learning non supervisionati determinano le relazioni tra le funzionalità delle osservazioni nei dati di training.
Raggruppamento
La forma più comune di Machine Learning non supervisionato è il clustering. Un algoritmo di clustering identifica le analogie tra le osservazioni in base alle relative funzionalità e le raggruppa in cluster discreti. Per esempio:
- Raggruppa fiori simili in base alle loro dimensioni, numero di foglie e numero di petali.
- Identificare i gruppi di clienti simili in base agli attributi demografici e al comportamento di acquisto.
In alcuni modi, il clustering è simile alla classificazione multiclasse; in quanto classifica le osservazioni in gruppi discreti. La differenza è che, quando si usa la classificazione, si conoscono già le classi a cui appartengono le osservazioni nei dati di training; quindi l'algoritmo funziona determinando la relazione tra le funzionalità e l'etichetta di classificazione nota. Nel clustering non esiste un'etichetta cluster nota in precedenza e l'algoritmo raggruppa le osservazioni dei dati in base esclusivamente alla somiglianza delle funzionalità.
In alcuni casi, il clustering viene usato per determinare il set di classi esistenti prima di eseguire il training di un modello di classificazione. Ad esempio, è possibile usare il clustering per segmentare i clienti in gruppi e quindi analizzare tali gruppi per identificare e classificare classi diverse di clienti (valore elevato, volume basso, acquirente frequente e così via). È quindi possibile usare le categorizzazioni per etichettare le osservazioni nei risultati del clustering e usare i dati etichettati per eseguire il training di un modello di classificazione che prevede la categoria di clienti a cui potrebbe appartenere un nuovo cliente.