Testare i modelli nei playground di Azure OpenAI Studio
I playground sono interfacce utili di Azure OpenAI Studio che è possibile usare per sperimentare con i modelli distribuiti senza la necessità di sviluppare un'applicazione client personalizzata. Azure OpenAI Studio offre più playground con diverse opzioni di ottimizzazione dei parametri.
Playground Completions
Il playground Completions consente di effettuare chiamate ai modelli distribuiti tramite un'interfaccia basata su "testo in ingresso, testo in uscita" e di regolare i parametri. È necessario selezionare il nome della distribuzione del modello in Deployments. Facoltativamente, è possibile usare gli esempi forniti per iniziare e quindi immettere le proprie richieste.
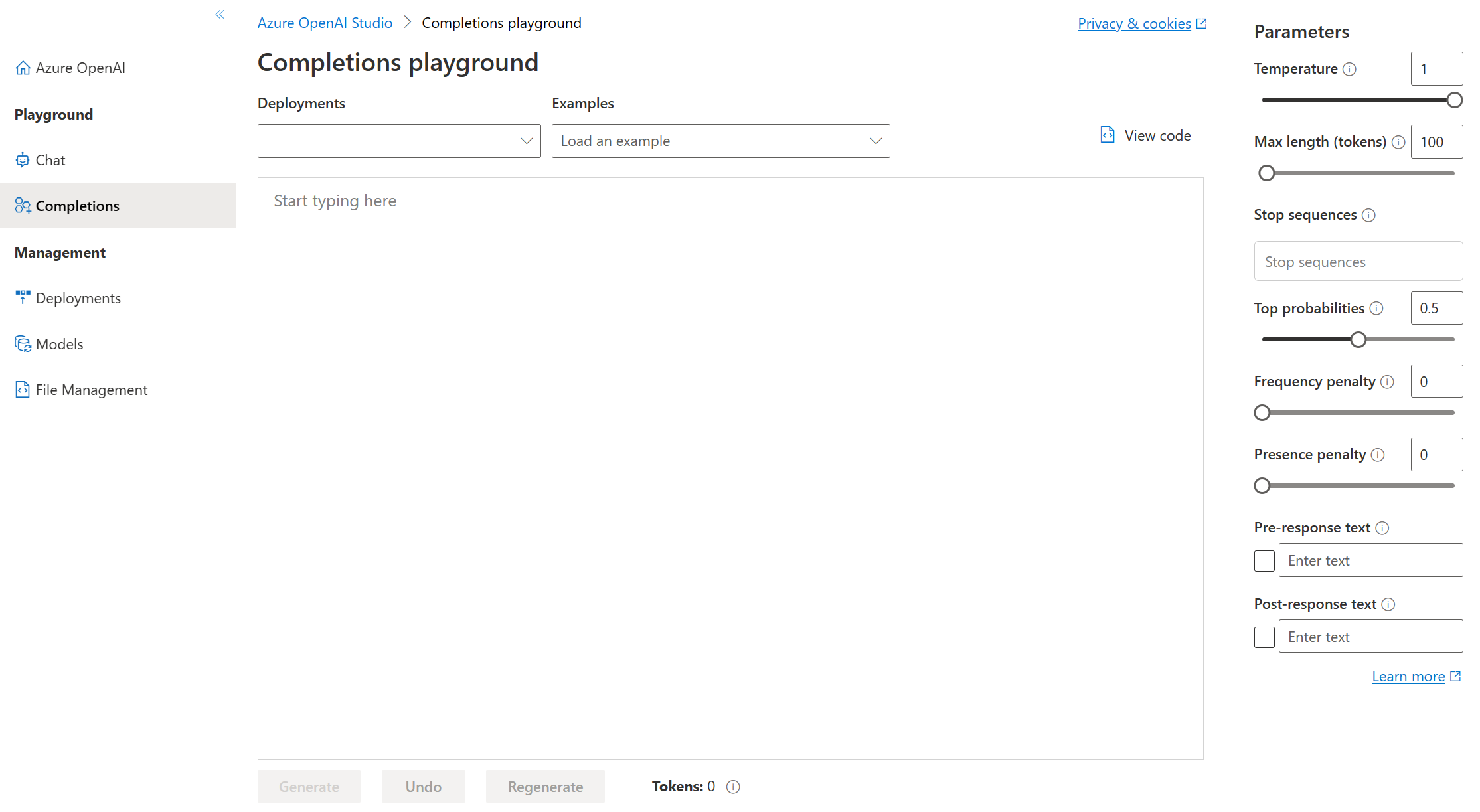
Parametri del playground Completions
Esistono molti parametri che è possibile modificare per cambiare le prestazioni del modello:
- Temperature: controlla la casualità. Abbassando la temperatura, il modello produce risposte più ripetitive e deterministiche. Aumentando la temperatura, vengono generate risposte più impreviste o creative. Provare a regolare la temperatura o Top P, ma non entrambi i parametri.
- Max length (tokens): consente di impostare un limite sul numero di token per ogni risposta del modello. L'API supporta un massimo di 4000 token condivisi tra la richiesta (inclusi messaggi di sistema, esempi, cronologia dei messaggi e query utente) e la risposta del modello. Ogni token consiste approssimativamente in quattro caratteri per il testo tipico in inglese.
- Stop sequences: consente di interrompere le risposte in un punto desiderato, ad esempio alla fine di una frase o di un elenco. Specificare fino a quattro sequenze in cui il modello interromperà la generazione di ulteriori token in una risposta. Il testo restituito non conterrà la sequenza di interruzione.
- Top probabilities (Top P): in modo simile alla temperatura, questo parametro controlla la casualità, ma con un metodo diverso. Abbassando Top P, la selezione di token del modello si restringe ai token più probabili. Aumentando Top P, il modello sceglie tra i token con probabilità alta e bassa. Provare a regolare la temperatura o Top P, ma non entrambi i parametri.
- Frequency penalty: consente di ridurre la probabilità di ripetere un token in modo proporzionale in base alla frequenza con cui è comparso nel testo finora. Ciò riduce la probabilità di ripetere esattamente lo stesso testo in una risposta.
- Presence penalty: consente di ridurre la probabilità di ripetere qualsiasi token comparso nel testo finora. Ciò aumenta la probabilità di introdurre nuovi argomenti in una risposta.
- Pre-response text: consente di inserire testo dopo l'input dell'utente e prima della risposta del modello. Ciò consente di preparare il modello per una risposta.
- Post-response text: consente di inserire testo dopo la risposta generata del modello per incoraggiare ulteriore input dell'utente, come quando si formula una conversazione.
Playground Chat
Il playground Chat si basa su un'interfaccia basata su "conversazione in ingresso, messaggio in uscita". È possibile inizializzare la sessione con un messaggio di sistema per configurare il contesto della chat.
Nel playground Chat è possibile aggiungere esempi few-shot. Il termine few-shot si riferisce alla specifica di alcuni esempi che consentono al modello di apprendere cosa deve fare. È il contrario di zero-shot, che significa che non vengono specificati esempi.
Nella configurazione dell'assistente è possibile fornire alcuni esempi few-shot di quello che può essere l'input dell'utente e di quale deve essere la risposta dell'assistente. L'assistente tenterà di simulare le risposte incluse nel tono, nelle regole e nel formato definiti nel messaggio di sistema.
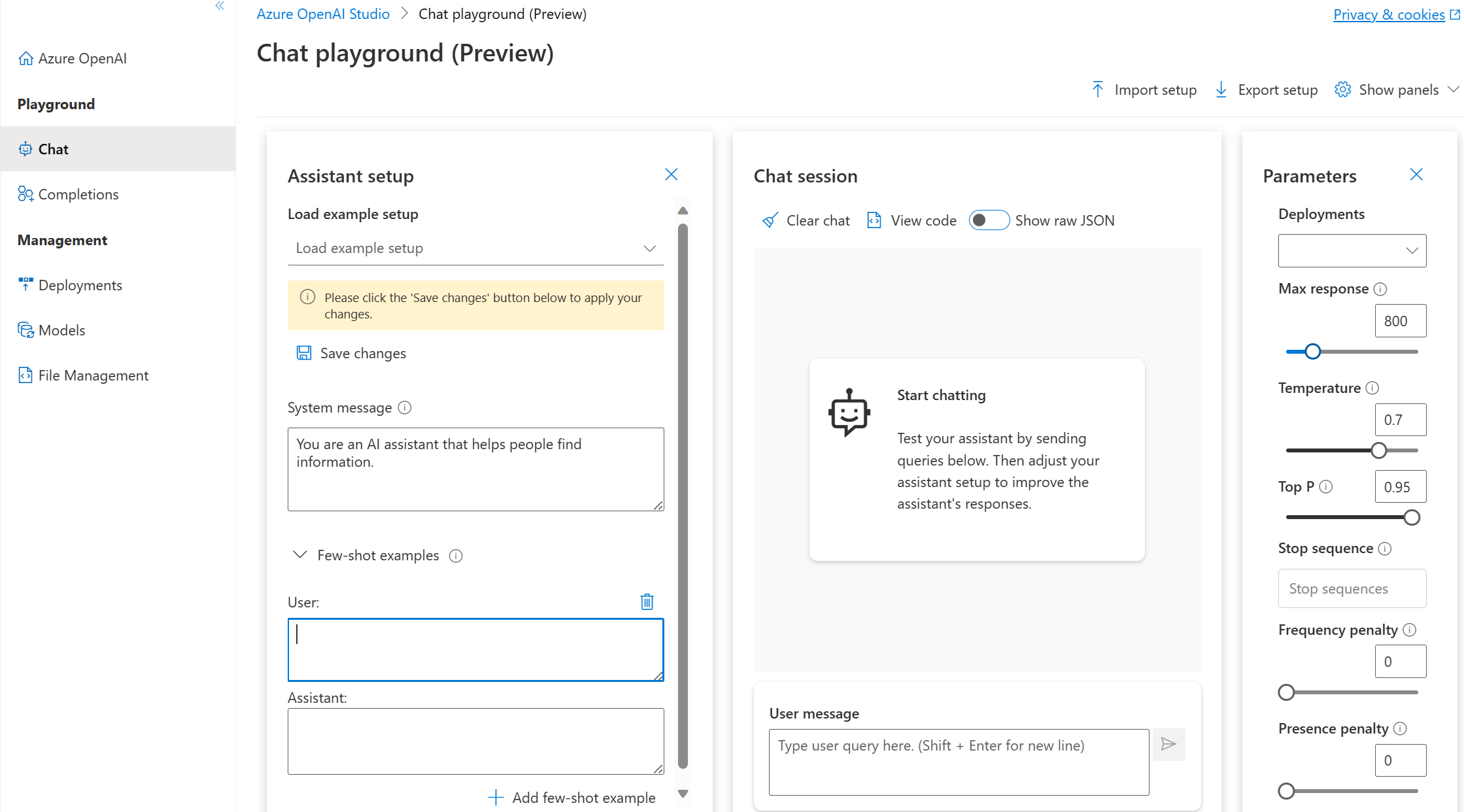
Parametri del playground Chat
Il playground Chat, analogamente a Completions, include il parametro Temperature. Il playground Chat supporta anche altri parametri non disponibili nel playground Completions. tra cui:
- Max response: consente di impostare un limite sul numero di token per ogni risposta del modello. L'API supporta un massimo di 4000 token condivisi tra la richiesta (inclusi messaggi di sistema, esempi, cronologia dei messaggi e query utente) e la risposta del modello. Ogni token consiste approssimativamente in quattro caratteri per il testo tipico in inglese.
- Top P: in modo simile alla temperatura, questo parametro controlla la casualità, ma con un metodo diverso. Abbassando Top P, la selezione di token del modello si restringe ai token più probabili. Aumentando Top P, il modello sceglie tra i token con probabilità alta e bassa. Provare a regolare la temperatura o Top P, ma non entrambi i parametri.
- Past messages included: consente di selezionare il numero di messaggi passati da includere in ogni nuova richiesta API. Includendo i messaggi passati si fornisce al modello il contesto per le nuove query degli utenti. L'impostazione di questo numero su 10 includerà cinque query degli utenti e cinque risposte di sistema.
Il conteggio corrente dei token è visualizzabile dal playground Chat. Poiché i costi delle le chiamate API sono basati su token ed è possibile impostare un limite massimo sui token delle risposte, è consigliabile monitorare il conteggio corrente dei token per assicurarsi che la conversazione in ingresso non superi il numero massimo.