Usare tabelle e viste dei metadati coordinatore per comprendere la distribuzione dei dati
Woodgrove Bank ha chiesto di esaminare e ottimizzare l'esecuzione delle query per le tabelle distribuite nel database Azure Cosmos DB per PostgreSQL. È possibile eseguire query sulle tabelle dei metadati che risiedono nel nodo coordinatore per visualizzare informazioni dettagliate sui nodi e sulle partizioni nel database distribuito. È possibile usare queste tabelle per ottenere informazioni dettagliate sulla struttura del database, sull'utilizzo dei nodi, sulla distribuzione dei dati e sulle prestazioni.
Il coordinatore gestisce queste tabelle e le usa per tenere traccia delle statistiche e delle informazioni sull'integrità e sulla posizione delle partizioni tra i nodi. Queste tabelle, precedute da pg_dist_*, contengono metadati diversi relativi al database distribuito e il coordinatore li usa durante la compilazione di piani di esecuzione delle query nei nodi di lavoro.
Questa unità evidenzia alcune delle tabelle seguenti, ma è possibile visualizzare l'elenco completo delle tabelle di metadati, altre informazioni e visualizzare i relativi schemi leggendo la documentazione Tabelle e viste di sistema.
Trovare la colonna di distribuzione per una tabella distribuita
Ogni tabella distribuita ha una colonna di distribuzione. Quando si inseriscono dati e si scrivono query sul database, è essenziale sapere quale colonna si tratta. Ad esempio, quando si unisce o si filtrano tabelle, è possibile che vengano visualizzati messaggi di errore con hint come "aggiungere un filtro alla colonna di distribuzione".
È possibile usare la vista tabelle distribuite, denominata citus_tables, nel nodo coordinatore per visualizzare il nome della colonna di distribuzione, insieme ad altri dettagli su ogni tabella distribuita nel database.
Ecco un esempio di uso della payment_events tabella dell'app contactless-payment di Woodgrove Bank:
SELECT table_name, distribution_column, table_size FROM citus_tables WHERE table_name = 'payment_events'::regclass;
table_name | distribution_column | table_size
----------------+---------------------+------------
payment_events | user_id | 5256 kB
Questa citus_tables vista fornisce anche altre informazioni utili, ad esempio il numero di partizioni, le dimensioni e il tipo di ogni tabella distribuita.
Informazioni sui nodi nel cluster
Le informazioni sui nodi di lavoro nel cluster sono contenute nella tabella dei nodi di lavoro , pg_dist_node. Per visualizzare informazioni sui nodi nel cluster di Woodgrove Bank, è possibile eseguire il comando seguente:
-- Turn on extended display to pivot results of wide tables
\x
Il \x comando ruota i risultati di query wide per evitare lo scorrimento orizzontale e l'output formattato in modo non corretto.
-- Retrieve node information
SELECT * FROM pg_dist_node;
-[ RECORD 1 ]----+-----------------------------------------------------------------
nodeid | 2
groupid | 2
nodename | private-w1.learn-cosmosdb-postgresql.postgres.database.azure.com
nodeport | 5432
noderack | default
hasmetadata | t
isactive | t
noderole | primary
nodecluster | default
metadatasynced | t
shouldhaveshards | t
-[ RECORD 2 ]----+-----------------------------------------------------------------
nodeid | 3
groupid | 3
nodename | private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com
nodeport | 5432
noderack | default
hasmetadata | t
isactive | t
noderole | primary
nodecluster | default
metadatasynced | t
shouldhaveshards | t
-[ RECORD 3 ]----+-----------------------------------------------------------------
nodeid | 4
groupid | 0
nodename | private-c.learn-cosmosdb-postgresql.postgres.database.azure.com
nodeport | 5432
noderack | default
hasmetadata | t
isactive | t
noderole | primary
nodecluster | default
metadatasynced | t
shouldhaveshards | f
Esaminando l'output della query vengono visualizzati i dettagli, inclusi l'ID, il nome e la porta associati a ogni nodo. Inoltre, è possibile verificare se il nodo è attivo e deve contenere partizioni, tra gli altri bit di informazioni. È possibile usare i nomi dei nodi e i numeri di porta per connettersi direttamente ai ruoli di lavoro, una procedura comune per ottimizzare le prestazioni delle query.
Esaminare l'asimmetria dei dati per comprendere l'utilizzo dei nodi
Il team di Woodgrove è preoccupato che nel corso del tempo la distribuzione dei dati nel database diventi asimmetrica, con conseguente riduzione delle prestazioni delle query. Gli utenti hanno chiesto di fornire loro una query che consentirà loro di valutare rapidamente l'asimmetria dei dati e un modo per risolverlo quando identificato.
L'asimmetria dei dati si riferisce al modo in cui i dati vengono distribuiti uniformemente tra i nodi di lavoro. La selezione corretta delle colonne di distribuzione dovrebbe comportare un utilizzo relativamente coerente delle risorse di archiviazione e di calcolo tra i nodi di lavoro. I cluster vengono eseguiti in modo più efficiente quando i dati vengono posizionati uniformemente tra i nodi e i dati correlati vengono raggruppati negli stessi ruoli di lavoro. È possibile usare la citus_shards vista per eseguire query sulle dimensioni dei dati in ogni partizione. Questa query fornisce informazioni dettagliate sul modo in cui i dati vengono distribuiti uniformemente tra le partizioni.
Delle tabelle distribuite associate all'app di pagamento senza contatto di Woodgrove Bank, la più probabile differenza nel tempo è la payment_events tabella. I commercianti e le tabelle degli utenti vengono distribuiti sulle chiavi primarie, quindi tali tabelle avranno sempre una riga per ogni colonna di distribuzione. Devono rimanere distribuiti in modo uniforme man mano che vengono aggiunti nuovi record. D'altra parte, la tabella degli eventi potrebbe visualizzare un numero non uniforme di righe immesse per ogni user_id, ovvero la colonna di distribuzione selezionata. Se alcuni utenti inviano molti più eventi rispetto ad altri, verranno restituite alcune partizioni contenenti quantità di dati maggiori rispetto ad altre. Quando le dimensioni dei dati delle partizioni sono diverse, indica che l'asimmetria dei dati è diversa.
Per visualizzare le dimensioni dei dati in ogni partizione della payment_events tabella, è possibile usare la query seguente:
SELECT shardid, shard_name, shard_size
FROM citus_shards
WHERE table_name = 'payment_events'::regclass
LIMIT 10;
shardid | shard_name | shard_size
---------+-----------------------+------------
102232 | payment_events_102232 | 770048
102233 | payment_events_102233 | 614400
102234 | payment_events_102234 | 647168
102235 | payment_events_102235 | 622592
102236 | payment_events_102236 | 638976
102237 | payment_events_102237 | 638976
102238 | payment_events_102238 | 598016
102239 | payment_events_102239 | 622592
102240 | payment_events_102240 | 729088
102241 | payment_events_102241 | 630784
L'output della query consente di confrontare le dimensioni di ogni partizione. Quando le partizioni sono di dimensioni approssimativamente uguali, come nell'output per la tabella precedente payment_events , è possibile dedurre che i nodi di lavoro contengono un numero approssimativamente uguale di righe.
Per ridurre al minimo l'asimmetria dei dati, la colonna di distribuzione selezionata deve:
- Possiede molti valori distinti maggiori o uguali al numero di partizioni (32 per impostazione predefinita).
- Avere un numero simile di righe associate a ogni valore univoco.
Qualsiasi scelta di colonna di tabella e distribuzione in cui una delle due proprietà non soddisfa questi criteri comporterà un'asimmetria dei dati. Quando si dispone di un'asimmetria dei dati, può comportare query meno efficienti, perché alcuni nodi di lavoro dovranno eseguire più lavoro rispetto ad altri e le query parallelizzate non funzioneranno in modo efficiente.
Correzione dell'asimmetria dei dati con il ribilanciamento della partizione
Per fornire un metodo senza codice per valutare l'asimmetria dei dati in Woodgrove Bank, è consigliabile usare il portale di Azure per verificare se i dati vengono distribuiti equamente tra i nodi di lavoro nel cluster. Nella portale di Azure selezionare la voce Ribilanciamento partizioni dal menu di spostamento a sinistra.
Se i dati sono asimmetrici tra i ruoli di lavoro, verrà visualizzato il messaggio Ribilanciamento consigliato e un elenco delle dimensioni di ogni nodo. In caso contrario, verrà visualizzato il messaggio Ribilanciamento non consigliato in questo momento.
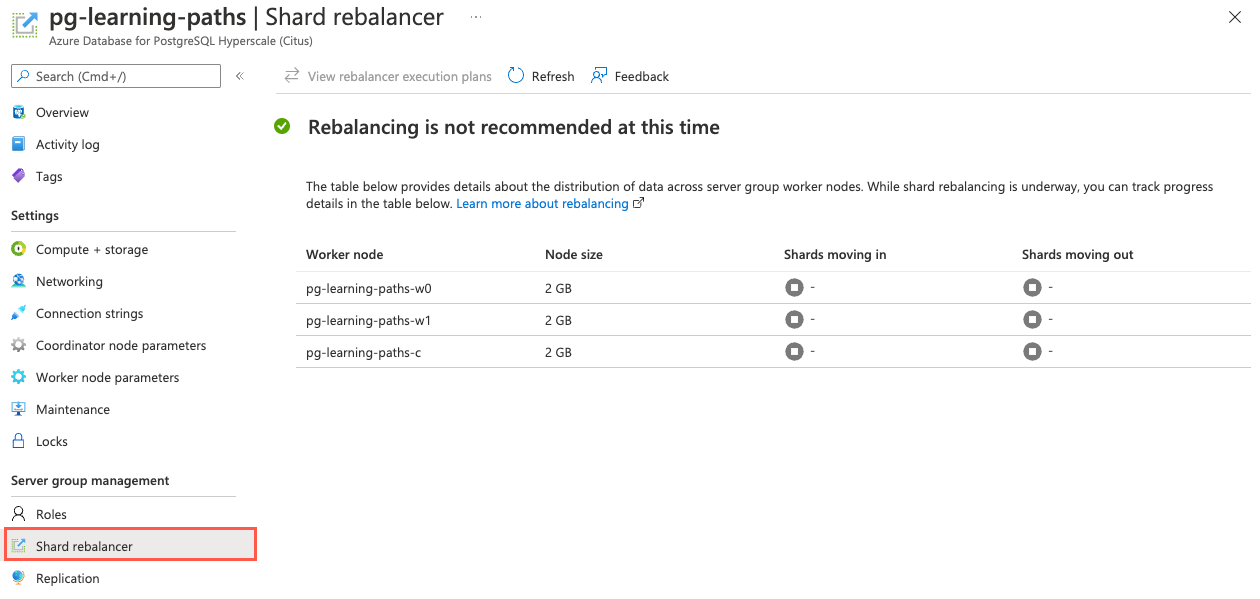
Se viene trovata l'asimmetria dei dati, è possibile avviare il ribilanciamento della partizione connettendosi al nodo coordinatore del cluster ed eseguendo la rebalance_table_shards funzione SQL nelle tabelle distribuite.
La funzione ribilancia tutte le tabelle nel gruppo di condivisione della tabella denominata nel relativo argomento. Non è necessario chiamare la funzione per ogni tabella distribuita. Chiamarlo invece su una tabella rappresentativa di ogni gruppo di condivisione.
Ad esempio, se si esegue il codice seguente sulla payment_events tabella verrà anche ribilanciato la payment_users tabella, perché vengono raggruppati.
SELECT rebalance_table_shards('payment_events');
È quindi possibile monitorare lo stato di avanzamento del ribilanciamento dal portale di Azure, in cui verrà visualizzato un messaggio che indica che è in corso il ribilanciamento, insieme ai dettagli sul numero di partizioni in movimento o all'esterno di un nodo e dello stato per tabella di database.
Identificare i posizionamenti delle partizioni
Azure Cosmos DB per PostgreSQL assegna ogni riga a una partizione in base al valore della colonna di distribuzione specificata. Ogni riga si troverà in una sola partizione e ogni partizione può contenere più righe. È possibile usare la pg_dist_placement tabella per visualizzare i dettagli dei posizionamenti delle partizioni.
La tabella di posizionamento delle partizioni tiene traccia della posizione delle repliche di partizioni nei nodi di lavoro. Ogni replica di una partizione assegnata a un nodo specifico è detta posizionamento di partizioni. Questa tabella archivia anche informazioni sull'integrità e sulla posizione di ogni posizionamento delle partizioni. Determinare il nodo di lavoro con le righe per una colonna di distribuzione specifica può essere utile in molti casi.
Si supponga che Woodgrove Bank abbia chiesto di trovare quale nodo di lavoro contiene i dati per user_id 5 nell'applicazione di pagamento senza contatto. In altre parole, si vuole identificare la posizione della partizione contenente righe la cui colonna di 5distribuzione ha il valore :
SELECT shardid, nodename, placementid
FROM pg_dist_placement AS p,
pg_dist_node AS n
WHERE p.groupid = n.groupid
AND n.noderole = 'primary'
AND shardid = (
SELECT get_shard_id_for_distribution_column('payment_users', 5)
);
La query restituisce l'oggetto shardid contenente i dati per l'oggetto user_id con un valore .5
shardid | nodename | placementid
---------+------------------------------------------------------------------+-------------
102014 | private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com | 7
Query di diagnostica utili
Oltre alle tabelle e alle viste dei metadati, sono disponibili molte query di diagnostica utili per comprendere le prestazioni e la risoluzione dei problemi del database.
Query attive
La citus_stat_activity vista mostra le query attualmente in esecuzione. È possibile filtrare per trovare quelli in esecuzione attivamente, insieme all'ID processo del back-end:
SELECT pid, query, state
FROM citus_stat_activity
WHERE state != 'idle';
Informazioni sul motivo per cui le query sono in attesa
È anche possibile eseguire query sui motivi più comuni per cui le query non inattive sono in attesa. Per spiegare i motivi, vedere la documentazione di PostgreSQL.
SELECT wait_event || ':' || wait_event_type AS type, count(*) AS number_of_occurrences
FROM pg_stat_activity
WHERE state != 'idle'
GROUP BY wait_event, wait_event_type
ORDER BY number_of_occurrences DESC;
Visualizzare l'attività di query distribuita
La documentazione Microsoft fornisce molti esempi di come usare le visualizzazioni dei metadati per controllare le query e i blocchi in tutto il cluster. Per altre informazioni su come usare queste viste per comprendere meglio le query distribuite nel database, vedere la documentazione relativa alle attività di query distribuite.