Esercizio - Eseguire query sulle tabelle dei metadati coordinatore per comprendere la distribuzione dei dati
In questo esercizio si usano le tabelle di metadati e portale di Azure nel nodo coordinatore per esaminare il modo in cui le tabelle vengono distribuite tra i nodi di lavoro nel cluster.
Importante
Questo esercizio si basa sul database azure Cosmos DB per PostgreSQL e sulle tabelle distribuite create nell'unità 3 di questo modulo.
Connessione al database usando psql in Azure Cloud Shell
Passare alla risorsa azure Cosmos DB per PostgreSQL nella portale di Azure.
Nel menu di spostamento a sinistra selezionare Connessione stringhe di Impostazioni e copiare il stringa di connessione etichettato psql.
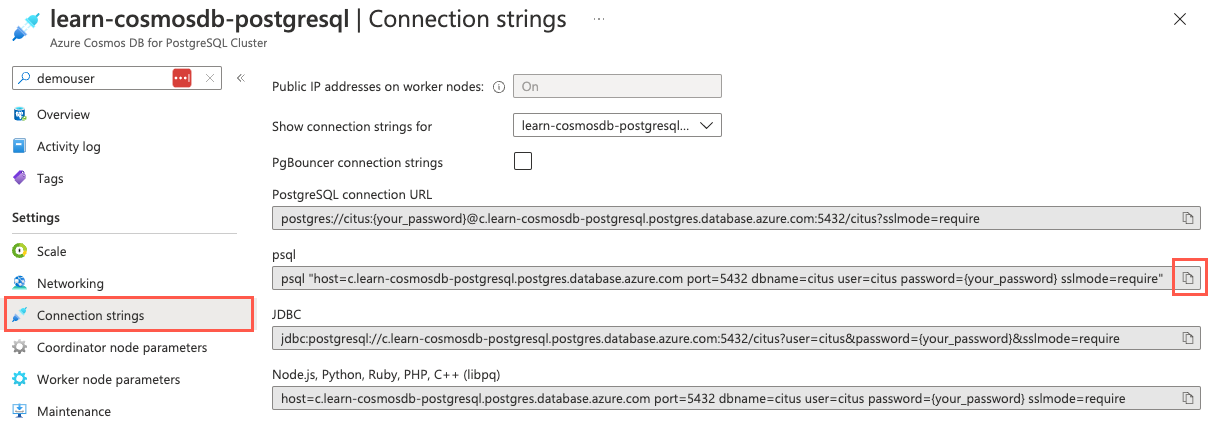
Incollare il stringa di connessione in un editor di testo, ad esempio Blocco note.exe, e sostituire il
{your_password}token con la password assegnata all'utente durante la creazione delcituscluster. Copiare il stringa di connessione aggiornato per usarlo di seguito.Dalla pagina delle stringhe di Connessione ion nella portale di Azure aprire una finestra di dialogo di Azure Cloud Shell selezionando l'icona di Cloud Shell sulla barra degli strumenti nella portale di Azure.
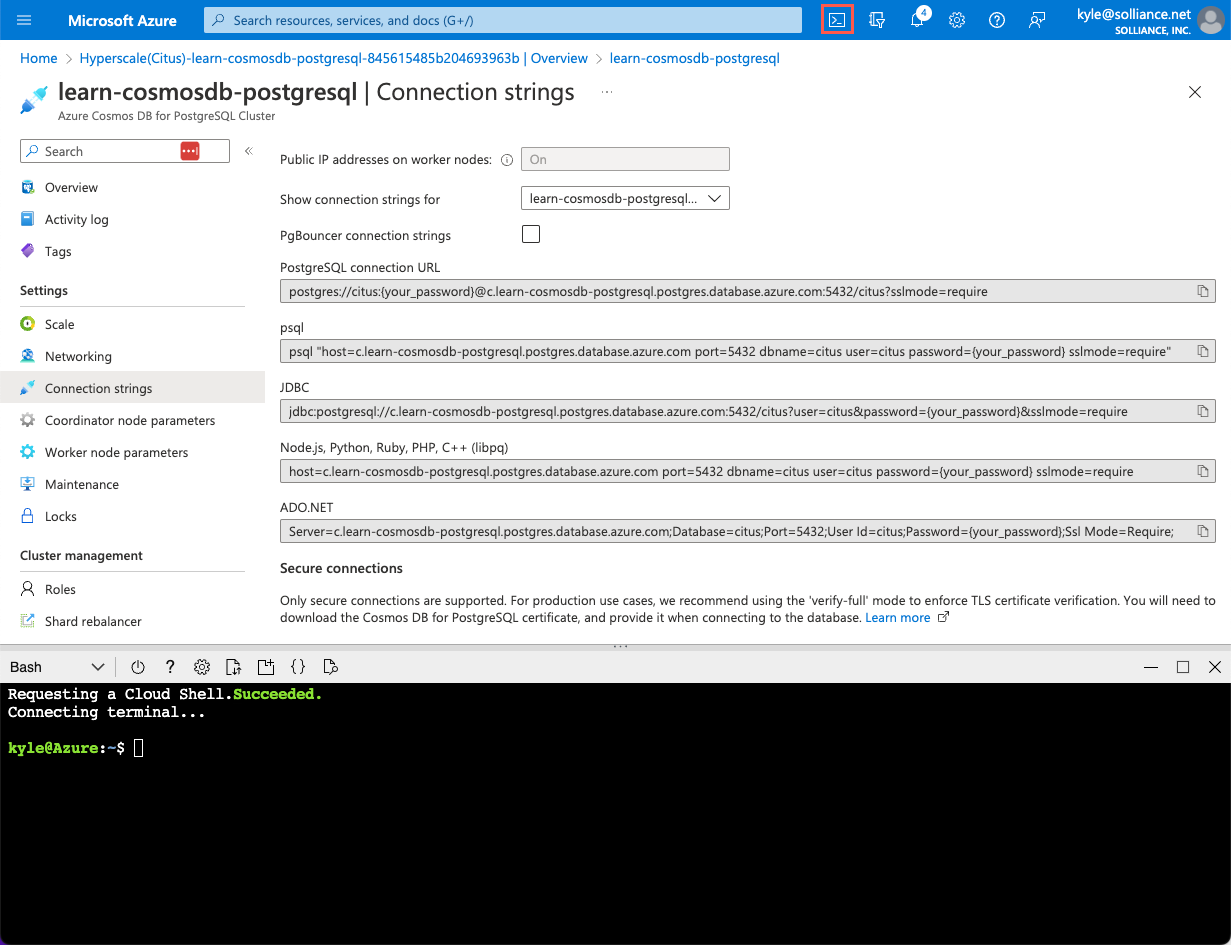
Cloud Shell verrà aperto come pannello incorporato nella parte inferiore della finestra del browser.
Se necessario, selezionare Bash come ambiente nella finestra di Cloud Shell.
Usare ora l'utilità della
psqlriga di comando per connettersi al database. Incollare il stringa di connessione aggiornato (quello contenente la password corretta) al prompt in Cloud Shell e quindi eseguire il comando , che dovrebbe essere simile al comando seguente:psql "host=c.learn-cosmosdb-postgresql.postgres.database.azure.com port=5432 dbname=citus user=citus password=P@ssword.123! sslmode=require"
Esaminare i nodi nel cluster
Durante il provisioning del database nell'unità 3, Azure ha richiesto ad Azure di creare un cluster con due nodi di lavoro e un nodo coordinatore. È possibile usare alcuni metodi per visualizzare i dettagli sui nodi nel cluster.
In primo luogo, è possibile usare il portale di Azure. Nel pannello portale di Azure della finestra del browser selezionare Panoramica dal menu di spostamento a sinistra.
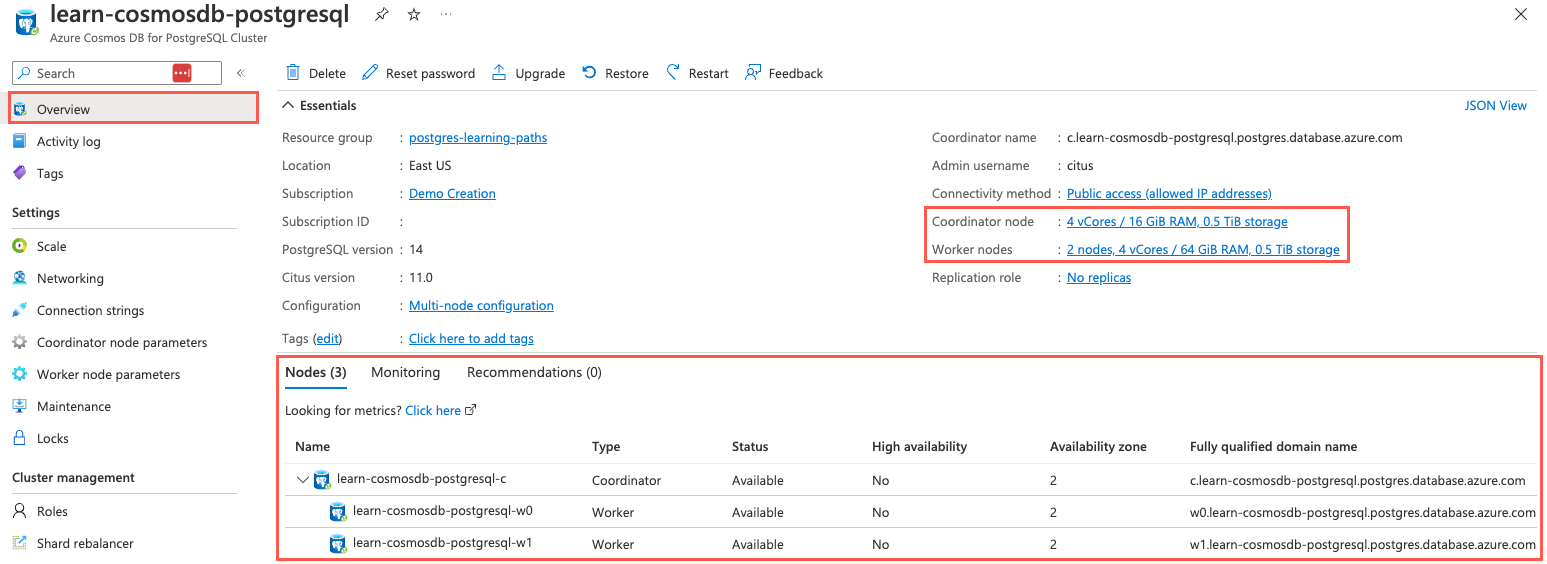
Nella pagina Panoramica le dimensioni dei nodi coordinatore e di lavoro vengono evidenziate nell'area Informazioni di base e nella scheda Nodi, in cui vengono visualizzati altri dettagli su ogni nodo.
Il portale di Azure fornisce dettagli generali sui nodi nel cluster. L'area Informazioni di base della pagina Panoramica fornisce informazioni dettagliate sulle dimensioni dei nodi coordinatore e di lavoro. Selezionando uno di questi riquadri verrà visualizzata la pagina Ridimensiona , in cui è possibile modificare la configurazione del cluster.
Inoltre, la scheda Nodi sotto l'area Informazioni di base mostra una suddivisione dei nodi, con i nodi di lavoro visualizzati sotto il nodo coordinatore. Qui è possibile visualizzare lo stato dei nodi e della zona di disponibilità e del nome di dominio completo per ognuno di essi.
psqlUsare quindi in Cloud Shell per esaminare i nodi. Nel pannello Cloud Shell nella parte inferiore della finestra del browser eseguire la query seguente sulla tabella dei metadati del nodo di lavoro (pg_dist_node) per esaminare informazioni più dettagliate sul nodo:SELECT * FROM pg_dist_node;Se la larghezza della finestra del browser è più stretta rispetto ai risultati della query, può comportare il wrapping delle righe e rendere difficile la visualizzazione. Per fornire una visualizzazione più chiara, eseguire questo comando SQL per abilitare la visualizzazione espansa, che ruota i risultati delle query a livello di larghezza:
\xEseguire ora la stessa query precedente sulla
pg_dist_nodetabella:SELECT * FROM pg_dist_node;Il
\xcomando fornisce una visualizzazione più chiara dei risultati per l'ispezione:-[ RECORD 1 ]----+----------------------------------------------------------------- nodeid | 2 groupid | 2 nodename | private-w1.learn-cosmosdb-postgresql.postgres.database.azure.com nodeport | 5432 noderack | default hasmetadata | t isactive | t noderole | primary nodecluster | default metadatasynced | t shouldhaveshards | t -[ RECORD 2 ]----+----------------------------------------------------------------- nodeid | 3 groupid | 3 nodename | private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com nodeport | 5432 noderack | default hasmetadata | t isactive | t noderole | primary nodecluster | default metadatasynced | t shouldhaveshards | t -[ RECORD 3 ]----+----------------------------------------------------------------- nodeid | 4 groupid | 0 nodename | private-c.learn-cosmosdb-postgresql.postgres.database.azure.com nodeport | 5432 noderack | default hasmetadata | t isactive | t noderole | primary nodecluster | default metadatasynced | t shouldhaveshards | fL'esecuzione di query sulla tabella dei metadati del nodo di lavoro offre molte più informazioni sui nodi del cluster di quanto sia possibile visualizzare nella portale di Azure. I nomi dei nodi e i numeri di porta possono essere usati per la connessione diretta ai nodi, che è una pratica comune quando si esegue l'ottimizzazione delle query. In alternativa, è possibile recuperare stringa di connessione per ogni nodo del cluster dalla pagina Connessione stringhe di Connessione ion della risorsa di Azure Cosmos DB per PostgreSQL nella portale di Azure. Nella pagina stringhe di Connessione ion è possibile selezionare il nodo desiderato dall'elenco a discesa Mostra stringa di connessione per e quindi copiare il stringa di connessione appropriato, che è quindi possibile usare per connettersi direttamente ai singoli nodi.
Esaminare la distribuzione delle tabelle
Per esaminare il modo in cui le tabelle vengono distribuite tra le partizioni, è possibile usare la citus_tables vista .
Eseguire la query seguente sulla
citus_tablesvista per altre informazioni sulle tabelle nel database Woodgrove:SELECT * FROM citus_tables;-[ RECORD 1 ]-------+------------------ table_name | payment_events citus_table_type | distributed distribution_column | user_id colocation_id | 1 table_size | 26 MB shard_count | 32 table_owner | citus access_method | heap -[ RECORD 2 ]-------+------------------ table_name | payment_merchants citus_table_type | reference distribution_column | <none> colocation_id | 2 table_size | 18 MB shard_count | 1 table_owner | citus access_method | heap -[ RECORD 3 ]-------+------------------ table_name | payment_users citus_table_type | distributed distribution_column | user_id colocation_id | 1 table_size | 44 MB shard_count | 32 table_owner | citus access_method | heapDai risultati è possibile notare che ogni tabella distribuita è distribuita in 32 partizioni, mentre la
payment_merchantstabella di riferimento si trova in una singola partizione. È anche possibile visualizzare le dimensioni di ogni tabella, che consente di decidere quando definire una tabella come tabella di riferimento anziché una tabella distribuita. Anche se non esistono linee guida impostate sui limiti di dimensioni di una tabella di riferimento, è importante prestare attenzione alle dimensioni, perché le tabelle più grandi non sono buoni candidati per la definizione come tabelle di riferimento. In base alle dimensioni inferiori dellapayment_merchanttabella, funzionerà come tabella di riferimento. Tuttavia, è necessario prestare attenzione a provarlo per le tabelle che potrebbero diventare troppo grandi.Esaminare quindi alcuni record della tabella partizioni,
pg_dist_shard, per visualizzare informazioni sulle singole partizioni dellapayment_eventstabella. Disabilitare prima di tutto la visualizzazione espansa usando il\xcomando .\xSELECT * FROM pg_dist_shard WHERE logicalrelid = 'payment_events'::regclass LIMIT 5;logicalrelid | shardid | shardstorage | shardminvalue | shardmaxvalue ----------------+---------+--------------+---------------+--------------- payment_events | 102232 | t | -2147483648 | -2013265921 payment_events | 102233 | t | -2013265920 | -1879048193 payment_events | 102234 | t | -1879048192 | -1744830465 payment_events | 102235 | t | -1744830464 | -1610612737 payment_events | 102236 | t | -1610612736 | -1476395009La
pg_dist_shardtabella fornisce informazioni sulle singole partizioni, incluso l'intervallo hash delle partizioni, usato dal coordinatore per determinare la partizione corretta da e verso cui scrivere e leggere i dati.
Esaminare la distribuzione dei dati
Esaminare ora come i dati dell'evento sono stati distribuiti tra le partizioni eseguendo una query sulla citus_shards vista.
Eseguire questa query SQL per esaminare le dimensioni dei dati delle prime 10 partizioni per la
payment_eventstabella:SELECT shardid, shard_name, shard_size FROM citus_shards WHERE table_name = 'payment_users'::regclass LIMIT 10;Verranno visualizzati risultati simili all'output seguente:
shardid | shard_name | shard_size ---------+-----------------------+------------ 102040 | payment_events_102040 | 770048 102041 | payment_events_102041 | 614400 102042 | payment_events_102042 | 647168 102043 | payment_events_102043 | 622592 102044 | payment_events_102044 | 638976 102045 | payment_events_102045 | 638976 102046 | payment_events_102046 | 598016 102047 | payment_events_102047 | 622592 102048 | payment_events_102048 | 729088 102049 | payment_events_102049 | 630784Si noti che, mentre alcune delle partizioni hanno le stesse dimensioni, esistono alcune variabili nelle dimensioni dei dati. Queste differenze si verificano perché il numero di eventi per ogni univoco
user_idnon è perfettamente uguale.Per determinare se queste differenze sono sufficientemente asimmetriche da richiedere l'esecuzione del ribilanciamento della partizione, passare all'istanza di Azure Cosmos DB per PostgreSQL nella portale di Azure e selezionare Ribilanciamento partizioni dal menu di spostamento a sinistra.
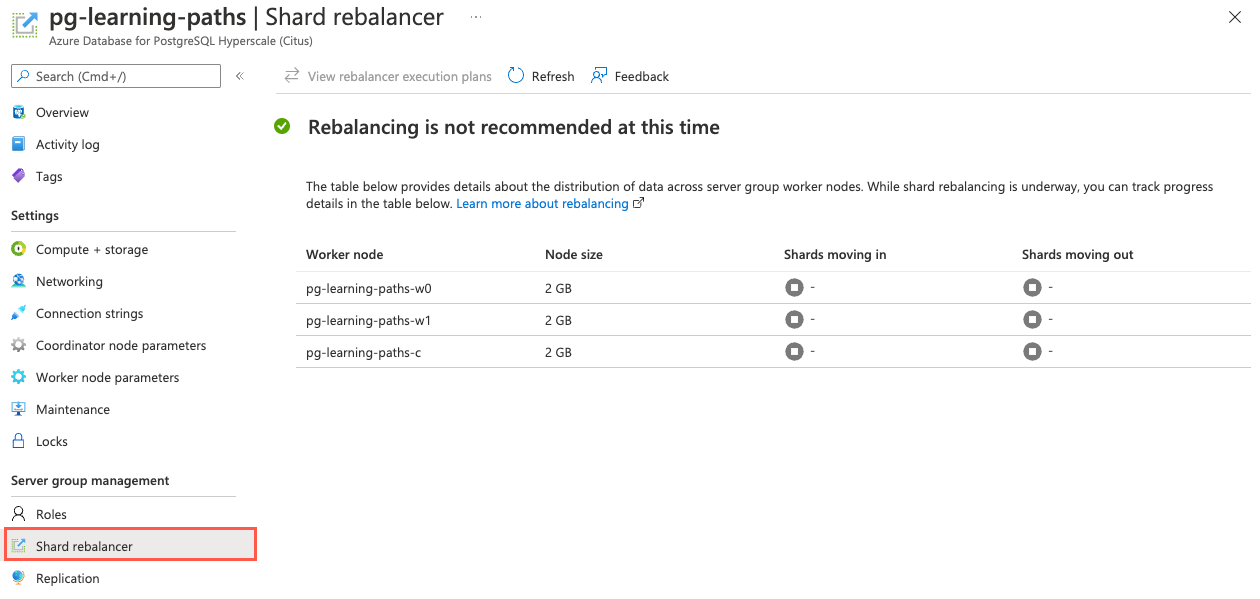
In base al ribilanciamento non è consigliabile visualizzare questo messaggio, le piccole differenze nelle dimensioni dei dati delle partizioni non sono ancora qualcosa che richiede il ribilanciamento delle partizioni nel cluster.
In questo esercizio sono state usate le portale di Azure e le query su tabelle e viste dei metadati coordinatore per individuare informazioni dettagliate sul database distribuito.
In Cloud Shell eseguire il comando seguente per disconnettersi dal database:
\qÈ possibile mantenere aperto Cloud Shell e passare all'unità 6: Comprendere l'esecuzione di query distribuite.