Informazioni sull'esecuzione di query distribuite
Prima di ottimizzare le prestazioni delle query per Woodgrove Bank, è necessario comprendere come vengono eseguite le query distribuite in Azure Cosmos DB per PostgreSQL. È anche necessario comprendere i parametri del server che è possibile usare per ottimizzare l'esecuzione delle query. Ogni cluster è costituito da un singolo nodo coordinatore e da più nodi di lavoro. Questa architettura consente la scalabilità di calcolo, memoria e archiviazione in numerosi server PostgreSQL nel cloud, ma aggiunge anche complessità all'esecuzione delle query.

Il diagramma include anche frecce a destra e a sinistra, che illustrano come è possibile aggiungere altri nodi per aumentare il numero di istanze.
Il coordinatore usa una pipeline di elaborazione query costituita da uno strumento di pianificazione delle query distribuite e da un executor di query distribuito. Per ogni query emessa nel cluster, il coordinatore consulta le tabelle di metadati per compilare un piano di esecuzione e quindi passa tale piano all'executor per l'esecuzione.
Informazioni sulla pianificazione dell'esecuzione di query distribuite
Distributed-Query Planner nel coordinatore accetta ogni query emessa nel cluster e genera il piano per l'esecuzione distribuita. Questo piano viene quindi parallelizzato tra i nodi di lavoro. Le ottimizzazioni vengono applicate per garantire che le query vengano eseguite in modo scalabile e che l'I/O di rete sia ridotta a icona.
Per le query contenenti un WHERE filtro delle clausole per un valore di colonna di distribuzione specifico, il coordinatore usa le tabelle di metadati per determinare la partizione a cui indirizzare la query eseguendo l'hashing della colonna di distribuzione della riga o delle righe coinvolte nella query. Queste query raggiungeranno solo una partizione, quindi il processo di pianificazione è leggermente diverso.
Dopo aver identificato la partizione o le partizioni corrette, lo strumento di pianificazione dell'esecuzione riscrive il piano di query per fare riferimento a tabelle di partizione anziché alla tabella originale. Le tabelle di partizionamento combinano il nome della tabella originale con l'esempio shardid. , si supponga di eseguire una UPDATE query sulla tabella di payment_events Woodgrove Bank e che venga determinata che la partizione 102104 contiene la riga da aggiornare. In tal caso, la query sulla payment_events tabella verrà riscritta nella destinazione payment_events_102027 anziché payment_eventsin .
Lo strumento di pianificazione suddivide la query in una query coordinatore (che viene eseguita sul coordinatore) e frammenti di query di lavoro (che vengono eseguiti su singole partizioni). I frammenti di query vengono assegnati ai ruoli di lavoro per consentire l'uso efficiente delle risorse.

Il frammento di query modifica il nome della tabella nella query originale per aggiungere un carattere di sottolineatura seguito dall'ID partizione. I frammenti di query vengono quindi inviati ai nodi di lavoro per l'esecuzione.
Il passaggio finale consiste nel passare il piano di query distribuito all'executor distribuito per l'esecuzione.
Che cos'è l'executor di query distribuito?
Azure Cosmos DB per PostgreSQL usa un executor di query distribuite per suddividere le normali query SQL ed eseguirle in parallelo sui nodi di lavoro vicini ai dati. L'executor distributed-query è responsabile dell'esecuzione di piani di query distribuita e della gestione di eventuali errori.
L'executor distributed-query è ottimizzato per ottenere risposte rapide alle query che coinvolgono filtri, aggregazioni e join con colocating ed esecuzione di query a tenant singolo con copertura SQL completa. L'esecuzione di query su più partizioni richiede il bilanciamento dei vantaggi derivanti dal parallelismo con l'overhead di gestione delle connessioni di database. L'executor di query crea un pool di connessioni per ogni sessione, apre una connessione per ogni partizione ai ruoli di lavoro in base alle esigenze e invia tutte le query di frammento. Recupera quindi i risultati da ogni query di frammento, li unisce e invia i risultati finali all'utente.

Nel diagramma le sessioni di query vengono frammentate dal nodo coordinatore e aggiunte a una coda di attività. I frammenti di query vengono quindi inviati ai pool di connessioni di sessione per l'esecuzione nei nodi di lavoro.
Usare EXPLAIN per comprendere l'esecuzione di query
Il coordinatore partiziona una query in ingresso in query di frammento e le invia ai ruoli di lavoro per l'elaborazione parallela. I ruoli di lavoro sono solo server PostgreSQL e applicano la logica di pianificazione ed esecuzione standard di PostgreSQL per queste query. Per comprendere meglio come vengono generati ed eseguiti i piani di esecuzione, è possibile usare il EXPLAIN comando .
EXPLAIN consente di ottenere informazioni dettagliate sulle prestazioni delle query e visualizzare informazioni sulla pianificazione dell'esecuzione delle query. L'output EXPLAIN mostra come ogni ruolo di lavoro elabora la query e fornisce alcuni dettagli sul modo in cui il nodo coordinatore combina i risultati.
Per il dashboard, Woodgrove Bank desidera una query che consente di visualizzare il numero di eventi per tipo per utente, che possono anche filtrare in base a event_type. Nell'esempio seguente viene illustrato il piano per la query creata. È anche possibile visualizzare le query effettive inviate ai nodi di lavoro includendo il VERBOSE flag .
EXPLAIN VERBOSE
SELECT e.user_id, login, event_type, COUNT(event_id) AS event_count
FROM payment_events AS e
LEFT JOIN payment_users AS u ON e.user_id = u.user_id
WHERE event_type = 'GiftFunds'
GROUP BY e.user_id, login, event_type
ORDER BY event_count DESC
LIMIT 10;
L'output dell'istruzione EXPLAIN VERBOSE fornisce informazioni dettagliate sul modo in cui la query viene eseguita tra i nodi che è possibile usare per ottimizzare la query usando i parametri del server come indicato di seguito:
Limit (cost=2160.96..2160.99 rows=10 width=80)
Output: remote_scan.user_id, remote_scan.login, remote_scan.event_type, remote_scan.event_count
-> Sort (cost=2160.96..2410.96 rows=100000 width=80)
Output: remote_scan.user_id, remote_scan.login, remote_scan.event_type, remote_scan.event_count
Sort Key: remote_scan.event_count DESC
-> Custom Scan (Citus Adaptive) (cost=0.00..0.00 rows=100000 width=80)
Output: remote_scan.user_id, remote_scan.login, remote_scan.event_type, remote_scan.event_count
Task Count: 32
Tasks Shown: One of 32
-> Task
Query: SELECT worker_column_1 AS user_id, worker_column_2 AS login, worker_column_3 AS event_type, count(worker_column_4) AS event_count FROM (SELECT e.user_id AS worker_column_1, u.login AS worker_column_2, e.event_
type AS worker_column_3, e.event_id AS worker_column_4 FROM (public.payment_events_102232 e LEFT JOIN public.payment_users_102264 u ON ((e.user_id OPERATOR(pg_catalog.=) u.user_id))) WHERE (e.event_type OPERATOR(pg_catalog.=) 'GiftFunds'
::text)) worker_subquery GROUP BY worker_column_1, worker_column_2, worker_column_3 ORDER BY (count(worker_column_4)) DESC LIMIT '10'::bigint
Node: host=private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com port=5432 dbname=citus
-> Limit (cost=498.14..498.16 rows=10 width=37)
Output: e.user_id, u.login, e.event_type, (count(e.event_id))
-> Sort (cost=498.14..498.88 rows=298 width=37)
Output: e.user_id, u.login, e.event_type, (count(e.event_id))
Sort Key: (count(e.event_id)) DESC
-> HashAggregate (cost=488.72..491.70 rows=298 width=37)
Output: e.user_id, u.login, e.event_type, count(e.event_id)
Group Key: e.user_id, u.login, e.event_type
-> Hash Left Join (cost=334.93..485.74 rows=298 width=37)
Output: e.user_id, u.login, e.event_type, e.event_id
Inner Unique: true
Hash Cond: (e.user_id = u.user_id)
-> Seq Scan on public.payment_events_102232 e (cost=0.00..150.03 rows=298 width=27)
Output: e.event_id, e.event_type, e.user_id, e.merchant_id, e.event_details, e.created_at
Filter: (e.event_type = 'GiftFunds'::text)
-> Hash (cost=231.08..231.08 rows=8308 width=18)
Output: u.login, u.user_id
-> Seq Scan on public.payment_users_102264 u (cost=0.00..231.08 rows=8308 width=18)
Output: u.login, u.user_id
L'output EXPLAIN dell'istruzione rivela diversi aspetti relativi al piano di esecuzione della query. A partire dalla riga di analisi personalizzata, è possibile vedere che lo strumento di pianificazione ha scelto l'executor adattivo Citus per eseguire questa query. Il conteggio delle attività rivela che sono presenti 32 partizioni e si sta visualizzando una delle 32 attività nell'output.
-> Custom Scan (Citus Adaptive) (cost=0.00..0.00 rows=100000 width=80)
Output: remote_scan.user_id, remote_scan.login, remote_scan.event_type, remote_scan.event_count
Task Count: 32
Tasks Shown: One of 32
Successivamente, EXPLAIN seleziona uno dei ruoli di lavoro e mostra un esempio rappresentativo del comportamento della query nei nodi di lavoro. Indica il nodo di lavoro (host, porta e nome del database) e include il frammento di query eseguito dal ruolo di lavoro:
-> Task
Query: SELECT worker_column_1 AS user_id, worker_column_2 AS login, worker_column_3 AS event_type, count(worker_column_4) AS event_count FROM (SELECT e.user_id AS worker_column_1, u.login AS worker_column_2, e.event_ type AS worker_column_3, e.event_id AS worker_column_4 FROM (public.payment_events_102232 e LEFT JOIN public.payment_users_102264 u ON ((e.user_id OPERATOR(pg_catalog.=) u.user_id))) WHERE (e.event_type OPERATOR(pg_catalog.=) 'GiftFunds'::text)) worker_subquery GROUP BY worker_column_1, worker_column_2, worker_column_3 ORDER BY (count(worker_column_4)) DESC LIMIT '10'::bigint
Node: host=private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com port=5432 dbname=citus
Dopo i dettagli del nodo di lavoro, è possibile visualizzare i risultati dell'esecuzione di un comando PostgreSQL EXPLAIN standard nel ruolo di lavoro per la query frammento:
-> Limit (cost=498.14..498.16 rows=10 width=37)
Output: e.user_id, u.login, e.event_type, (count(e.event_id))
-> Sort (cost=498.14..498.88 rows=298 width=37)
Output: e.user_id, u.login, e.event_type, (count(e.event_id))
Sort Key: (count(e.event_id)) DESC
-> HashAggregate (cost=488.72..491.70 rows=298 width=37)
Output: e.user_id, u.login, e.event_type, count(e.event_id)
Group Key: e.user_id, u.login, e.event_type
-> Hash Left Join (cost=334.93..485.74 rows=298 width=37)
Output: e.user_id, u.login, e.event_type, e.event_id
Inner Unique: true
Hash Cond: (e.user_id = u.user_id)
-> Seq Scan on public.payment_events_102232 e (cost=0.00..150.03 rows=298 width=27)
Output: e.event_id, e.event_type, e.user_id, e.merchant_id, e.event_details, e.created_at
Filter: (e.event_type = 'GiftFunds'::text)
-> Hash (cost=231.08..231.08 rows=8308 width=18)
Output: u.login, u.user_id
-> Seq Scan on public.payment_users_102264 u (cost=0.00..231.08 rows=8308 width=18)
Output: u.login, u.user_id
Spostamento dei dati per l'esecuzione di sottoquery
Azure Cosmos DB per PostgreSQL può anche raccogliere i risultati dalle sottoquery e dalle espressioni di tabella comuni nel nodo coordinatore e quindi eseguirne il push tra i ruoli di lavoro per l'uso da parte di una query esterna. Questa funzionalità offre supporto per un'ampia gamma di costrutti SQL.
Per altre informazioni su come usare l'istruzione EXPLAIN per visualizzare le query con sottopiani distribuiti, vedere la documentazione sull'elaborazione di query Citus.
Ottenere prestazioni massime delle query ottimizzando i parametri del server
Vari parametri del server influiscono sul comportamento del database. È possibile usare questi parametri per ottimizzare il cluster per ottenere prestazioni massime. È possibile modificare i valori dei parametri del server usando istruzioni SQL o nella portale di Azure. Nella categoria Impostazioni scegliere i parametri del Nodo di lavoro o i parametri deli Nodo coordinatore. Queste pagine consentono di impostare i parametri per tutti i nodi di lavoro o solo per il nodo coordinatore.
È possibile trovare informazioni dettagliate su tutti i parametri del server disponibili nella documentazione dei parametri del server. La documentazione dell'API Azure Cosmos DB per PostgreSQL fornisce anche raggruppamenti logici dei parametri del server in base alla funzione.
Il primo passaggio del processo di ottimizzazione consiste nell'eseguire il EXPLAIN comando dal nodo coordinatore nelle query rappresentative per controllare le prestazioni. Le informazioni da EXPLAIN cui derivare possono essere utili per comprendere i parametri da ottimizzare. La modifica dei parametri del nodo di lavoro è in genere la posizione in cui iniziare quando si tenta di ottimizzare le prestazioni delle query. È possibile modificare i valori dei parametri nei nodi di lavoro usando la pagina Parametri del nodo di lavoro nella portale di Azure o connettendosi direttamente al nodo di lavoro usando il nome di dominio completo e la porta del ruolo di lavoro.
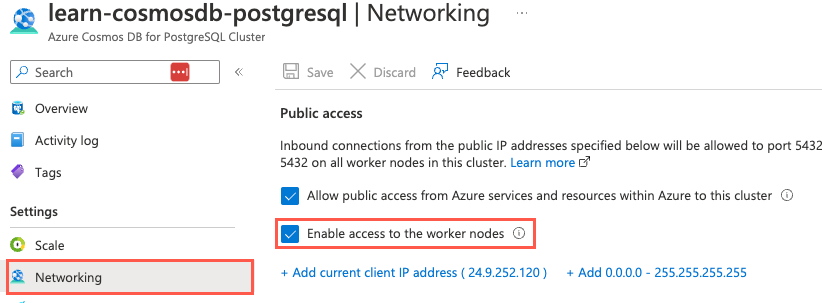
Nota
Connessione direttamente ai nodi di lavoro è necessario selezionare Abilitare l'accesso ai nodi di lavoro nella pagina Rete della risorsa Azure Cosmos DB per PostgreSQL nella portale di Azure.
L'ottimizzazione dei parametri del server richiede la sperimentazione e spesso richiede più tentativi di ottenere prestazioni accettabili. Quando si apportano modifiche, eseguire EXPLAIN di nuovo dal coordinatore o direttamente sul ruolo di lavoro per valutare l'effetto della modifica. Come raccomandazione generale, è consigliabile ottimizzare in modo iterativo il database usando solo una piccola parte dei dati. Dopo aver modificato un ruolo di lavoro per ottenere le prestazioni desiderate, è necessario applicare manualmente tali modifiche agli altri ruoli di lavoro nel cluster.
Per impostazione predefinita, i cluster all'interno di Azure Cosmos DB per PostgreSQL sono configurati con le impostazioni delle risorse conservatrici. Tra queste impostazioni, shared_buffers e work_mem probabilmente sono i parametri più critici per ottimizzare le prestazioni di lettura. Questi parametri sono descritti brevemente di seguito. Oltre a queste impostazioni, diversi altri parametri di configurazione possono influire sulle prestazioni delle query. Per altre informazioni su queste impostazioni, vedere la documentazione di Microsoft.
Ottimizzare le prestazioni di lettura
Il shared_buffers parametro PostgreSQL imposta la quantità di memoria allocata al database per la memorizzazione nella cache dei dati. Il valore predefinito per questa impostazione è 128 MB. Se si dispone di un nodo di lavoro con 1 GB o più di RAM, un valore iniziale ragionevole per shared_buffers è il 25% della memoria del sistema. Esistono alcuni carichi di lavoro in cui le impostazioni ancora più grandi per shared_buffers sono vantaggiose. Tuttavia, dato che Azure Cosmos DB per PostgreSQL si basa anche sulla cache del sistema operativo, è improbabile che l'uso di più del 25% di RAM fornisca vantaggi aggiuntivi in termini di prestazioni.
Aumentare la memoria di lavoro
Se i modelli di query comuni includono molti ordinamenti complessi, l'aumento work_mem consente al database di eseguire ordinamenti in memoria più grandi, più velocemente rispetto agli equivalenti basati su disco. Il work_mem parametro imposta la quantità di memoria utilizzata dalle operazioni di ordinamento interne e dalle tabelle hash prima di scrivere nei file temporanei del disco. Se si dispone di un'attività di I/O su disco elevata nel nodo di lavoro nonostante abbia una quantità ragionevole di memoria, l'aumento work_mem a un valore più elevato può essere vantaggioso. L'aumento work_mem consente di generare piani di query più efficienti e di consentire l'esecuzione di più operazioni in memoria.
Oltre alle impostazioni dei shared_buffers parametri e work_mem , Query Execution Planner si basa su informazioni statistiche sul contenuto delle tabelle per generare piani validi. Queste statistiche vengono raccolte quando ANALYZE viene eseguito. Questa funzionalità è abilitata per impostazione predefinita.
Ottimizzare la gestione delle connessioni
Il numero di connessioni simultanee che possono essere aperte da singole query è limitato dal parametro del citus.max_adaptive_executor_pool_size (integer) server. Il valore predefinito per tale impostazione è 16, ma è configurabile a livello di sessione per la gestione della priorità. È consigliabile impostare citus.max_adaptive_executor_pool_size (integer) su un valore basso, ad esempio 1 o 2, per i carichi di lavoro transazionali con query con esecuzione breve, < ad esempio 20 ms di latenza. Lasciare questa impostazione al valore predefinito per i carichi di lavoro analitici in cui il parallelismo è critico.
È più veloce eseguire attività in sequenza sulla stessa connessione per attività brevi anziché stabilire nuove connessioni da eseguire in parallelo. Le attività a esecuzione prolungata, d'altra parte, traggono vantaggio dal parallelismo più immediato. Per bilanciare le esigenze delle attività brevi e a esecuzione prolungata, Azure Cosmos DB per PostgreSQL usa il citus.executor_slow_start_interval (integer) parametro . Questa impostazione specifica un ritardo tra i tentativi di connessione per le attività in una query su più partizioni. Quando una query prima accoda le attività, le attività possono acquisire una sola connessione. Alla fine di ogni intervallo in cui sono presenti connessioni in sospeso, il coordinatore aumenta il numero di connessioni aperte simultanee. È consigliabile impostare citus.executor_slow_start_interval (integer) un valore elevato come 100 ms per i carichi di lavoro transazionali costituiti da query brevi associate alla latenza di rete anziché al parallelismo. Per i carichi di lavoro analitici, lasciare questa impostazione al valore predefinito di 10 ms. È anche possibile disabilitare completamente il comportamento di avvio lento impostandone il valore su 0.
Al termine dell'utilizzo di una connessione, il pool di sessioni mantiene aperta la connessione per velocizzare i comandi successivi. La memorizzazione nella cache della connessione evita il sovraccarico della riattivazione della connessione tra coordinatore e ruolo di lavoro. Tuttavia, ogni pool non conterrà più di citus.max_cached_conns_per_worker (integer) connessioni inattive aperte contemporaneamente, per limitare l'utilizzo delle risorse di connessione inattive nel ruolo di lavoro. L'aumento di questo valore riduce la latenza delle query su più partizioni, ma aumenta anche il sovraccarico sui ruoli di lavoro. Il valore predefinito 1 per citus.max_cached_conns_per_worker (integer) è ragionevole. Un valore maggiore, ad esempio 2, potrebbe essere utile per i cluster che usano alcune sessioni simultanee, ma non è consigliabile andare molto oltre (ad esempio, 16 sarebbe troppo elevato). Se impostata su un valore troppo elevato, le sessioni inutilmente contengono connessioni inattive e usano le risorse di lavoro.
Il database di Woodgrove Bank viene usato sia per i carichi di lavoro transazionali che per i carichi di lavoro di analisi. Il modo più efficace per ottimizzare i parametri di connessione consiste nel seguire un approccio iterativo, modificare i valori dei parametri e osservare l'effetto della modifica. Per ogni caso d'uso, si osserverà l'effetto che la modifica ha sulle query e si identificheranno le impostazioni più adatte alle proprie esigenze.