Usare Azure Data Lake Storage Gen2 nei carichi di lavoro di analisi dei dati
Azure Data Lake Store Gen2 è una tecnologia abilitante per più casi d'uso di analisi dei dati. Si esaminino alcuni tipi comuni di carico di lavoro analitico e si identifichi come funziona Azure Data Lake Storage Gen2 con altri servizi di Azure per supportarli.
Elaborazione e analisi dei Big Data
Gli scenari di Big Data in genere fanno riferimento a carichi di lavoro analitici che coinvolgono volumi elevati di dati in un'ampia gamma di formati che devono essere elaborati a velocità rapida, ovvero il cosiddetto "three v's". Azure Data Lake Storage Gen 2 offre un archivio dati distribuito scalabile e sicuro in cui i servizi Big Data, ad esempio Azure Synapse Analytics, Azure Databricks e Azure HDInsight possono applicare framework di elaborazione dati come Apache Spark, Hive e Hadoop. La natura distribuita dell'archiviazione e del calcolo di elaborazione consente di eseguire attività in parallelo, con prestazioni elevate e scalabilità anche durante l'elaborazione di grandi quantità di dati.
Data warehousing
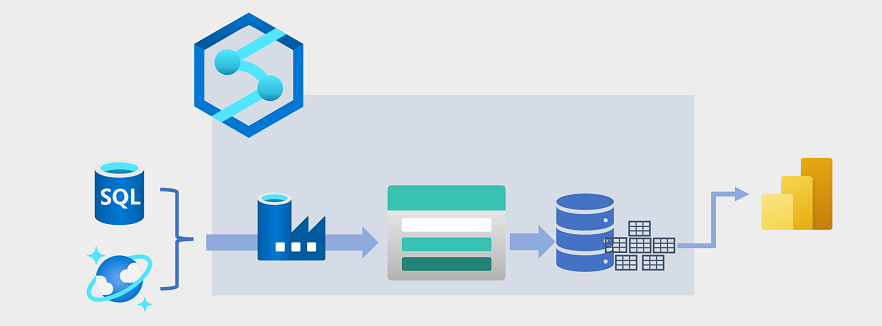
Il data warehousing si è evoluto negli ultimi anni per integrare grandi volumi di dati archiviati come file in un data lake con tabelle relazionali in un data warehouse. In un esempio tipico di una soluzione di data warehousing i dati vengono estratti da archivi dati operativi, ad esempio Azure SQL database o Azure Cosmos DB e trasformati in strutture più adatte per carichi di lavoro analitici. Spesso i dati vengono inseriti in un data lake per facilitare l'elaborazione distribuita prima di essere caricati in un data warehouse relazionale. In alcuni casi, il data warehouse usa tabelle esterne per definire un livello di metadati relazionali sui file nel data lake e creare un'architettura ibrida "data lakehouse" o "database lake". Il data warehouse può quindi supportare le query analitiche per la creazione di report e la visualizzazione.
Esistono diversi modi per implementare questo tipo di architettura di data warehousing. Il diagramma mostra una soluzione in cui Azure Synapse Analytics ospita pipeline per eseguire processi di estrazione, trasformazione e caricamento (ETL) usando Azure Data Factory tecnologia. Questi processi estraggono i dati dalle origini dati operative e lo caricano in un data lake ospitato in un contenitore Azure Data Lake Storage Gen2. I dati vengono quindi elaborati e caricati in un data warehouse relazionale in un pool SQL dedicato di Analisi Azure Synapse, da cui può supportare la visualizzazione e la creazione di report dei dati tramite Microsoft Power BI.
Analisi dei dati in tempo reale
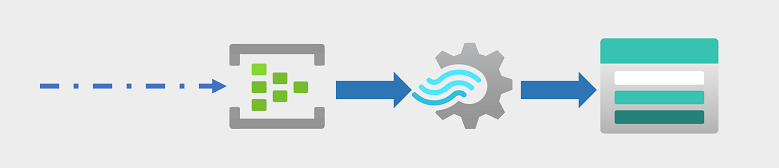
Sempre più spesso, le aziende e altre organizzazioni devono acquisire e analizzare flussi perpetui di dati e analizzarli in tempo reale (o quasi in tempo reale). Questi flussi di dati possono essere generati da dispositivi connessi (spesso definiti dispositivi internet-of-things o IoT ) o da dati generati dagli utenti in piattaforme di social media o altre applicazioni. A differenza dei carichi di lavoro di elaborazione batch tradizionali, i dati di streaming richiedono una soluzione in grado di acquisire ed elaborare un flusso illimitato di eventi di dati man mano che si verificano.
Gli eventi di streaming vengono spesso acquisiti in una coda per l'elaborazione. Sono disponibili più tecnologie che è possibile usare per eseguire questa attività, tra cui Hub eventi di Azure, come illustrato nell'immagine. Da qui, i dati vengono elaborati, spesso per aggregare i dati in finestre temporali (ad esempio per contare il numero di messaggi dei social media con un tag specificato ogni cinque minuti o per calcolare la lettura media di un sensore connesso a Internet al minuto). Analisi di flusso di Azure consente di creare processi che eseguono query e aggregano i dati degli eventi non appena arrivano e scrivono i risultati in un sink di output. Un sink di questo tipo è Azure Data Lake Storage Gen2, da cui è possibile analizzare e visualizzare i dati acquisiti in tempo reale.
Data Science e Machine Learning

La data science implica l'analisi statistica di grandi volumi di dati, spesso usando strumenti come Apache Spark e linguaggi di scripting, ad esempio Python. Azure Data Lake Storage Gen 2 offre un archivio dati basato sul cloud altamente scalabile per i volumi di dati necessari nei carichi di lavoro di data science.
L’apprendimento automatico è un subset di data science che riguarda la modellazione predittiva. Il training del modello richiede grandi quantità di dati e la possibilità di elaborare i dati in modo efficiente. Azure Machine Learning è un servizio cloud in cui i data scientist possono eseguire codice Python nei notebook usando risorse di calcolo distribuite allocate dinamicamente. Il calcolo elabora i dati in Azure Data Lake Storage Gen2 contenitori per eseguire il training dei modelli, che possono quindi essere distribuiti come servizi Web di produzione per supportare carichi di lavoro analitici predittivi.