Descrivere Spark Structured Streaming
Spark Structured Streaming è una piattaforma diffusa per l'elaborazione in memoria. Ha un paradigma unificato per l'elaborazione in batch e in streaming. Tutto ciò che si apprende e si usa per l'elaborazione in batch può essere usato per lo streaming ed è quindi facile passare da un tipo di elaborazione all'altro. Spark Streaming è semplicemente un motore che viene eseguito su Apache Spark.

Structured Streaming crea una query a esecuzione prolungata durante la quale è possibile applicare operazioni ai dati di input, tra cui la selezione, la proiezione, l'aggregazione, il windowing e l'aggiunta di DataFrame di riferimento al DataFrame di streaming. È quindi possibile restituire i risultati nell'archiviazione file (BLOB del servizio di archiviazione di Azure o Data Lake Storage) o in qualsiasi archivio dati usando codice personalizzato (come il database SQL o Power BI). Structured Streaming fornisce inoltre l'output alla console per il debug in locale e a una tabella in memoria per poter visualizzare i dati generati per il debug in HDInsight.
Flussi come tabelle
Spark Structured Streaming rappresenta un flusso di dati come tabella senza limiti di profondità. Ciò significa che la tabella continua ad aumentare con l'arrivo di nuovi dati. Questa tabella di input viene continuamente elaborata da una query a esecuzione prolungata e i risultati vengono inviati a una tabella di output:

In Structured Streaming i dati arrivano nel sistema e vengono immediatamente inseriti in una tabella di input. Si scriveranno query (usando le API DataFrame e Dataset) che eseguono operazioni su questa tabella di input. L'output della query produce un'altra tabella, denominata tabella dei risultati. La tabella dei risultati contiene i risultati della query, da cui è possibile ricavare i dati per un archivio dati esterno, come un database relazionale. Il periodo in cui i dati vengono elaborati dalla tabella di input viene controllato dall'intervallo di trigger. Per impostazione predefinita, l'intervallo di trigger è zero e di conseguenza Structured Streaming tenta di elaborare i dati non appena arrivano. In pratica, questo significa che non appena Structured Streaming ha completato l'elaborazione dell'esecuzione della query precedente, avvia un'altra elaborazione, eseguita su eventuali nuovi dati ricevuti. È possibile configurare il trigger per l'esecuzione in base a un intervallo specifico, in modo che i dati di streaming vengano elaborati in batch basati sul tempo.
I dati nella tabella dei risultati possono essere limitati ai nuovi dati dall'ultima elaborazione della query (modalità Append) oppure la tabella può essere aggiornata ogni volta che sono presenti nuovi dati, in modo da includere tutti i dati di output dall'inizio della query di streaming (modalità completa).
Modalità Append
In modalità Append la tabella dei risultati contiene solo le righe aggiunte alla tabella dall'ultima esecuzione della query e tali righe vengono scritte nell'archiviazione esterna. Ad esempio, la query più semplice copia solo tutti i dati, inalterati, dalla tabella di input alla tabella dei risultati. Allo scadere di ogni intervallo di trigger, i nuovi dati vengono elaborati e le righe che rappresentano i nuovi dati vengono visualizzate nella tabella dei risultati.
Si consideri uno scenario di elaborazione dei dati relativi ai prezzi dei titoli azionari. Si supponga che il primo trigger abbia elaborato un evento all'ora 00.01 relativo all'azione MSFT con un valore di 95 dollari. Al primo trigger della query, nella tabella dei risultati viene visualizzata solo la riga con l'ora 00.01. All'ora 00.02, quando si verifica un altro evento, l'unica riga visualizzata è la riga con l'ora 00.02 e pertanto la tabella dei risultati conterrà solo tale riga.
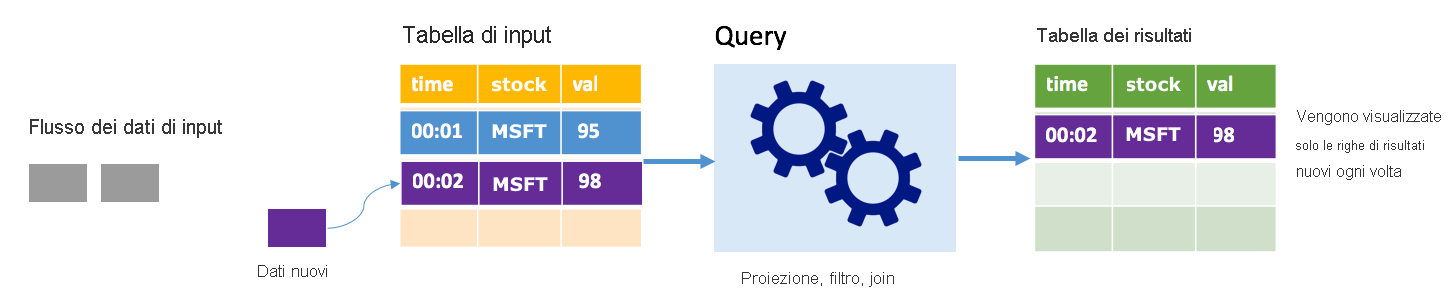
Quando si usa la modalità Append, la query applica proiezioni (selezionando le colonne rilevanti), filtra (selezionando solo le righe che corrispondono a determinate condizioni) o aggiunge (aumentando i dati con dati provenienti da un tabella di ricerca statica). La modalità Append semplifica il push nelle risorse di archiviazione esterne limitandolo ai soli nuovi punti dati rilevanti.
Modalità completa
Si consideri lo stesso scenario nella modalità completa. In modalità completa l'intera tabella di output viene aggiornata a ogni trigger in modo da includere non solo i dati dall'esecuzione del trigger più recente, ma da tutte le esecuzioni. È possibile usare la modalità completa per copiare i dati inalterati dalla tabella di input alla tabella dei risultati. A ogni esecuzione attivata, le righe dei nuovi risultati vengono visualizzate insieme a tutte le righe precedenti. La tabella dei risultati di output finirà con l'archiviare tutti i dati raccolti dall'inizio della query e si verificherà una condizione di memoria insufficiente. La modalità completa è pensata per l'uso con query di aggregazione che restituiscono un riepilogo dei dati in ingresso. In questo modo, a ogni trigger, la tabella dei risultati viene aggiornata con un nuovo riepilogo.
Si supponga che finora siano stati elaborati i dati relativi a cinque secondi e che sia il momento di elaborare quelli relativi al sesto secondo. La tabella di input include eventi per l'ora 00.01 e l'ora 00.03. L'obiettivo di questa query di esempio è fornire il prezzo medio del titolo azionario ogni cinque secondi. L'implementazione di questa query applica un'aggregazione che, partendo da tutti i valori compresi in ogni finestra di cinque secondi, calcola la media del prezzo del titolo azionario e genera una riga per tale valore nell'intervallo specifico. Alla fine della prima finestra di cinque secondi, sono presenti due tuple: (00.01, 1, 95) e (00.03, 1, 98). Di conseguenza, per la finestra 00.00-00.05, l'aggregazione genera una tupla con il prezzo medio del titolo azionario pari a 96,50 dollari. Nella successiva finestra di cinque secondi è presente un solo punto dati all'ora 00.06 e pertanto il prezzo medio risultante è 98 dollari. Alle ore 00.10, se si usa la modalità completa, la tabella dei risultati include le righe per entrambe le finestre, 00.00-00.05 e 00.05-00.10, perché la query restituisce tutte le righe aggregate e non solo quelle nuove. Di conseguenza, la tabella dei risultati continua ad aumentare con l'aggiunta di nuove finestre.
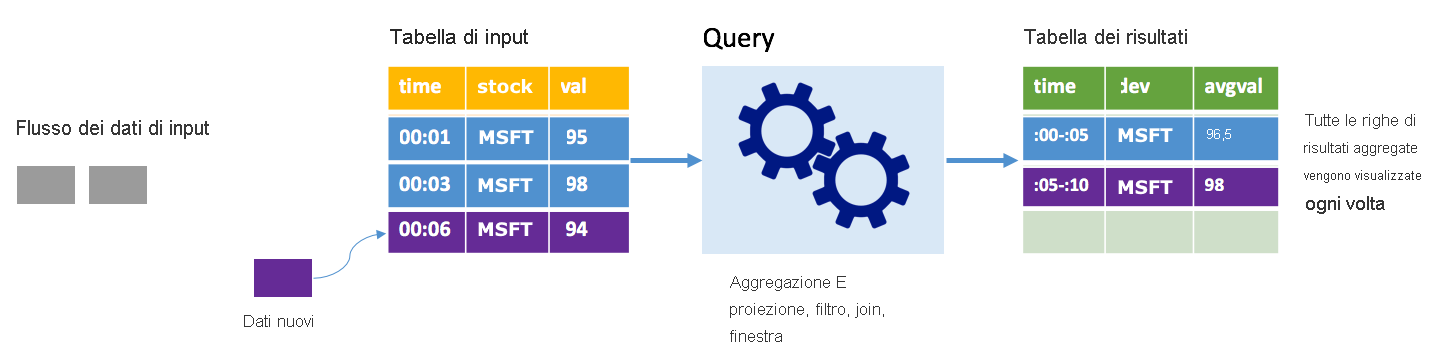
Non tutte le query che usano la modalità completa provocano un aumento illimitato della tabella. Nell'esempio precedente si supponga che la media del prezzo del titolo azionario venga calcolata in base al titolo, invece di essere calcolata in base alla finestra temporale. La tabella dei risultati contiene un numero fisso di righe (una per titolo azionario), con il prezzo medio relativo ai titoli azionari tra tutti i punti dati ricevuti dal dispositivo stesso. Man mano che riceve nuovi prezzi di titoli azionari, la tabella dei risultati viene aggiornata in modo da mostrare sempre i valori medi più recenti.
Quali sono i vantaggi offerti da Spark Structured Streaming?
Nell'ambito del settore finanziario, la tempistica delle transazioni è molto importante. In una transazione azionaria, ad esempio, la differenza tra il momento in cui avviene la transazione sul mercato azionario, quello in cui si riceve tale transazione e quello in cui i dati vengono letti ha una notevole rilevanza. Le decisioni degli istituti finanziari dipendono da questi dati critici e dalla loro tempistica.
Ora dell'evento, dati in ritardo e definizione della soglia di ritardo
Spark Structured Streaming conosce la differenza tra l'ora di un evento e il momento in cui l'evento è stato elaborato dal sistema. Ogni evento è una riga della tabella e l'ora dell'evento è un valore di colonna nella riga. In questo modo, le aggregazioni basate su finestra (ad esempio, il numero di eventi ogni minuto) possono essere semplicemente un raggruppamento e un'aggregazione in base alla colonna relativa all'ora dell'evento. Ogni finestra temporale è un gruppo e ogni riga può appartenere a più finestre o gruppi. Pertanto, queste query di aggregazione basate sulla finestra temporale degli eventi possono essere definite in modo coerente sia su un set di dati statico sia su un flusso di dati, semplificando notevolmente la vita agli ingegneri dei dati.
Inoltre, questo modello gestisce in modo naturale i dati che sono arrivati più tardi del previsto in base all'ora dell'evento. Spark ha il controllo completo sull'aggiornamento delle aggregazioni obsolete in caso di dati in ritardo e sulla pulizia di tali aggregazioni per limitare le dimensioni dei dati rimasti allo stato intermedio. Inoltre, a partire dalla versione 2.1, Spark supporta la definizione di una soglia per i dati in ritardo e consente al motore di eseguire di conseguenza la pulizia dello stato precedente.
Flessibilità per caricare i dati recenti o tutti i dati
Come illustrato nell'unità precedente, quando si usa Spark Structured Streaming è possibile scegliere di usare la modalità Append o la modalità completa in modo che la tabella dei risultati includa solo i dati più recenti oppure tutti i dati.
Supporto per il passaggio da microbatch a elaborazione continua
Modificando il tipo di trigger di una query Spark, è possibile passare dall'elaborazione di microbatch all'elaborazione continua senza apportare altre modifiche al framework. Di seguito sono elencati i diversi tipi di trigger supportati da Spark.
- Non specificato. Questo è il trigger predefinito. Se nessun trigger è impostato in modo esplicito, la query viene eseguita in microbatch e verrà elaborata in modalità continua.
- Microbatch a intervalli fissi. La query viene eseguita a intervalli periodici impostati dall'utente. Se non vengono ricevuti nuovi dati, non viene eseguito alcun processo.
- Microbatch singolo. La query esegue un solo microbatch e quindi si arresta. Questo trigger è utile se si vogliono elaborare tutti i dati del microbatch precedente e può consentire un risparmio sui costi per i processi che non devono essere eseguiti in modalità continua.
- Modalità continua con intervallo di checkpoint fisso. La query viene eseguita in una nuova modalità di elaborazione continua a bassa latenza che consente una latenza end-to-end bassa (~1 ms) con garanzie di tolleranza di errore di tipo at-least-once. Questo trigger è simile a quello predefinito, che può ottenere garanzie di tipo exactly-once ma, nella migliore delle ipotesi, raggiunge latenze di ~100 ms.
Combinazione di processi in batch e streaming
Oltre a semplificare il passaggio dei processi di elaborazione in batch a quelli in streaming, è possibile combinare i due tipi di processi. Questa operazione è particolarmente utile quando si vogliono usare dati cronologici a lungo termine per stimare le tendenze future durante l'elaborazione di informazioni in tempo reale. Nel caso dei titoli azionari, può essere utile esaminare l'andamento del prezzo del titolo negli ultimi 5 anni oltre a quello attuale, per stimare le variazioni che possono verificarsi per effetto degli annunci relativi ai ricavi annuali o trimestrali.
Finestre temporali degli eventi
Spark Structured Streaming supporta anche la possibilità di acquisire i dati in finestre temporali, ad esempio il prezzo massimo e quello minimo di un titolo azionario entro una finestra di un giorno o di un minuto, indipendentemente dall'intervallo scelto. Sono supportate anche finestre sovrapposte.
Checkpoint per il ripristino in caso di errore
In caso di errore o di arresto intenzionale, è possibile ripristinare lo stato di avanzamento precedente e lo stato di una query precedente e continuare dal punto in cui è stata interrotta. Questo è possibile tramite la definizione di checkpoint e la creazione di log write-ahead. È possibile configurare una query con un percorso di checkpoint, in cui verranno salvate tutte le informazioni sullo stato di avanzamento (ovvero l'intervallo di offset elaborati in ogni trigger) e le aggregazioni in esecuzione. Il percorso di checkpoint deve essere un percorso in un file system compatibile con HDFS e può essere impostato come opzione in DataStreamWriter all'avvio di una query.