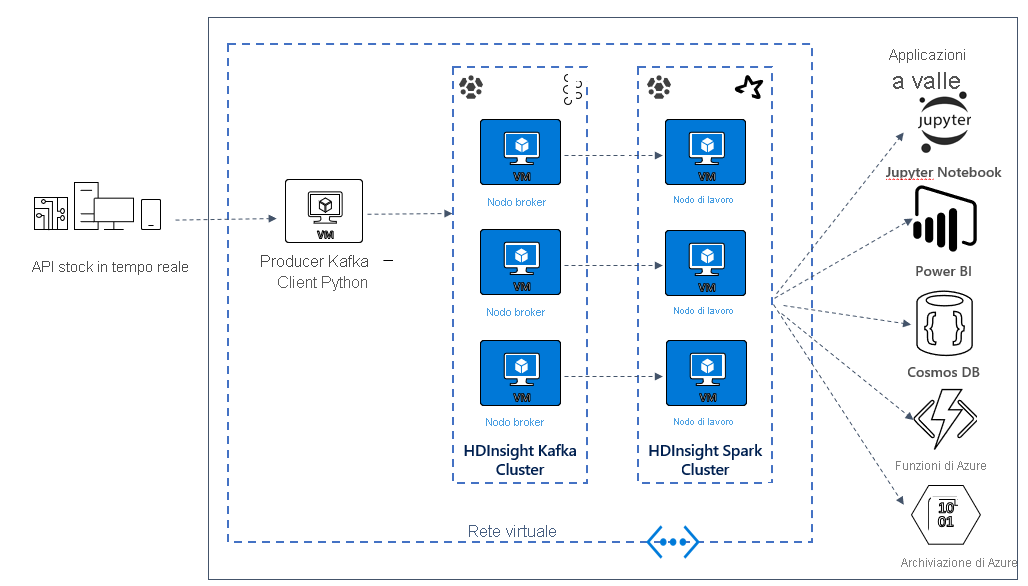
Creare un'architettura Kafka e Spark
Per usare Kafka e Spark in Azure HDInsight, è necessario inserirli all'interno della stessa rete virtuale oppure eseguire il peering delle reti virtuali per consentire il funzionamento dei cluster con la risoluzione dei nomi DNS.
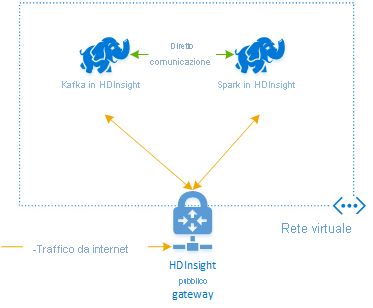
Per creare cluster nella stessa rete virtuale, seguire questa procedura:
- Creare un gruppo di risorse
- Aggiungere una rete virtuale al gruppo di risorse
- Aggiungere un cluster Kafka e un cluster Spark alla stessa rete virtuale o, in alternativa, eseguire il peering delle reti virtuali in cui questi servizi funzionano con la risoluzione dei nomi DNS.
Il metodo consigliato per connettere i cluster Kafka e Spark in HDInsight è il connettore Spark-Kafka nativo, che consente al cluster Spark di accedere a singole partizioni di dati all'interno del cluster Kafka, aumentando così il parallelismo disponibile nel processo di elaborazione in tempo reale e offrendo una velocità effettiva molto elevata.
Quando entrambi i cluster si trovano nella stessa rete virtuale, è anche possibile usare i nomi di dominio completi del broker Kafka nel codice di streaming Spark e creare nella rete virtuale regole NSG per la sicurezza aziendale.
Architettura della soluzione
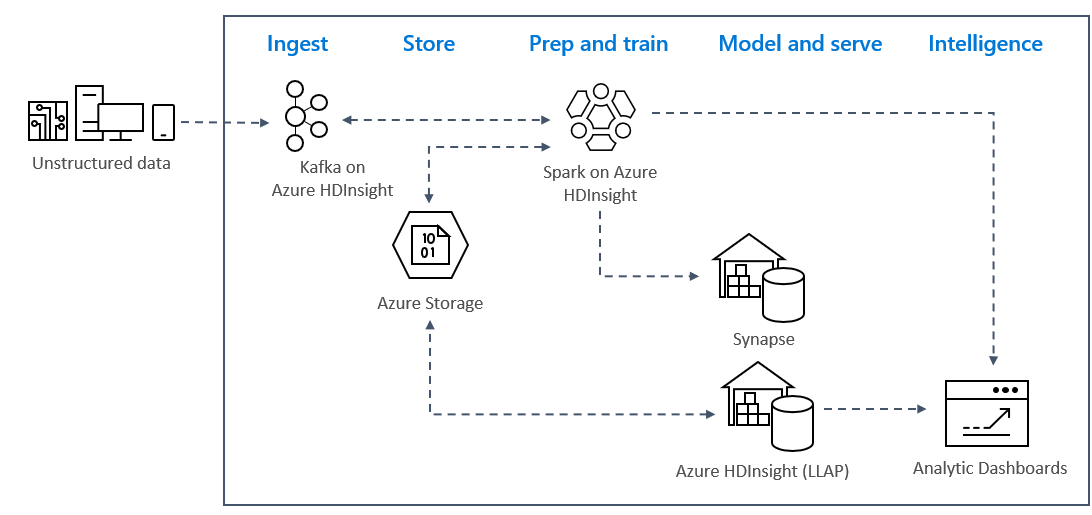
I modelli di analisi di flusso in tempo reale in Azure sono in genere basati sull'architettura seguente.
- Inserimento: i dati non strutturati o strutturati vengono inseriti in un cluster Kafka in Azure HDInsight.
- Preparazione e training: i dati vengono preparati e sottoposti a training con Spark in HDInsight.
- Modello e gestione: i dati vengono inseriti in un data warehouse, ad esempio Azure Synapse o HDInsight Interactive Query.
- Intelligence: i dati vengono passati al dashboard di analisi, ad esempio Power BI o Tableau.
- Archiviazione: i dati vengono inseriti in una soluzione di archiviazione a freddo, come Archiviazione di Azure, per un eventuale uso futuro.
Scenario di esempio dell'architettura
Nell'unità successiva si inizierà a creare l'architettura della soluzione per l'applicazione di esempio. L'esempio usa un file modello di Azure Resource Manager per creare il gruppo di risorse, la rete virtuale, il cluster Spark e il cluster Kafka.
Una volta distribuiti i cluster, è possibile connettersi tramite ssh a uno dei broker Kafka e copiare il file producer Python nel nodo head. Il file producer fornisce prezzi di titoli azionari fittizi ogni 10 secondi e scrive il numero della partizione e l'offset del messaggio nella console.
Quando il producer è in esecuzione, è possibile caricare il notebook di Jupyter nel cluster Spark. Nel notebook verranno connessi i cluster Spark e Kafka e verranno eseguite alcune query di esempio sui dati, inclusa la ricerca dei valori massimo e minimo per un titolo azionario entro una determinata finestra di eventi.