Quando è consigliabile usare Interactive Query in HDInsight?
In qualità di analista aziendale, l'utente deve determinare il tipo di cluster HDInsight più appropriato da creare per compilare la soluzione. I cluster Interactive Query offrono numerose funzionalità e opzioni di interoperabilità che li rendono estremamente vantaggiosi per gli analisti aziendali con familiarità con SQL. Sono ideali per gli utenti che desiderano usare strumenti di business intelligence e richiedono query interattive veloci. Esistono altri vantaggi, ad esempio il supporto per un'ampia gamma di formati di file, concorrenza e transazioni ACID (Atomic, Consistent, Isolated e Durable), oltre all'integrazione con Apache Ranger per il controllo granulare a livello di riga e colonna sui dati.
Nota
Il contenuto di questo modulo riguarda i cluster Interactive Query creati per HDInsight 4.0, che usano Hive 3.1 e LLAP, noto anche come Hive LLAP.
Si dispone di un set di dati di grandi dimensioni pronto per essere sottoposto a query
I cluster Interactive Query sono ideali per set di dati di grandi dimensioni su cui è possibile eseguire query così come sono o con trasformazioni minime. Situazioni in cui è possibile eseguire una serie di query sui dati ed è necessario avere risposte immediate. I cluster Interactive Query non sono ottimizzati per l'esecuzione di calcoli batch con esecuzione prolungata. Interactive Query supporta i formati di file seguenti: ORC, Parquet, CSV, Avro, JSON, text e TSV.
Sono necessarie funzionalità simili a SQL
Quando è necessario eseguire query interattive e ad hoc con latenza inferiore al secondo sui Big Data di Archiviazione di Azure e Azure Data Lake Storage e si preferisce un'esperienza simile a SQL, i cluster Azure HDInsight Interactive Query rappresentano una scelta ottimale. Gli analisti aziendali hanno familiarità con le tabelle SQL e la creazione di query con SQL. Apache Hadoop è uno strumento potente per l'esecuzione di analisi di Big Data. Apache Hadoop usa il framework MapReduce e le relative API Java e questo può costituire un blocco se le competenze di programmazione Java sono leggermente arrugginite. In questo caso, HDInsight Interactive Query rappresenta una soluzione migliore in quanto si basa su Apache Hadoop, ma è più semplice per chiunque abbia esperienza SQL da usare. Interactive Query usa tabelle Hive simili a SQL per elaborare i dati e un linguaggio di query simile a SQL denominato HiveQL per eseguire query sui dati. L'uso di Hive è meno complesso rispetto all'elaborazione dei dati con MapReduce in Apache Hadoop. Hive rende più veloce ed efficiente implementare soluzioni per l'azienda.
Query interattive rapide con caching intelligente
I cluster Interactive Query usano tecniche di memorizzazione nella cache intelligente per spostare di livello i dati tra RAM dinamica, unità SSD del nodo cluster locale e sistemi di archiviazione remota, ad esempio BLOB di Azure e Azure Data Lake Storage, per ottenere risultati di query interattivi e veloci sui Big Data. Un esempio di tecnica avanzata di memorizzazione nella cache è la cache di testo dinamico, che converte i dati CSV in un formato in-memory ottimizzato in tempo reale, per cui la memorizzazione nella cache è dinamica e le query determinano quali dati vengono memorizzati. Questa funzionalità significa che non è necessario caricare e trasformare prima i dati. È possibile caricare i dati in Archiviazione di Azure nel formato originale e iniziare a eseguire query su di essi. Inoltre, le query sono più performanti la seconda volta che vengono eseguite. La prima volta che una query viene eseguita, i dati vengono letti dal livello di archiviazione dei dati aziendali in Archiviazione di Azure o Azure Data Lake Gen2. I dati vengono quindi memorizzati nella cache in-memory condivisa nel cluster. Alla successiva esecuzione della query, i dati vengono semplicemente recuperati dalla cache in-memory condivisa e si risparmia tempo senza recuperare i dati dal livello di archiviazione remoto.
Eseguire query usando gli strumenti più diffusi
Interactive Query consente di semplificare l'uso dei Big Data con gli strumenti di business intelligence con cui si ha familiarità, ad esempio Microsoft Power BI e Tableau. Nell'analisi dei Big Data, le organizzazioni sono sempre più preoccupate che gli utenti finali non abbiano un valore sufficiente per i sistemi di analisi, perché spesso questa è troppo complessa e richiede l'uso di strumenti non noti e difficili da apprendere. HDInsight Interactive Query risolve questo problema richiedendo un training minimo o nullo all'utente per ottenere informazioni cognitive dettagliate dai dati. Gli utenti possono scrivere query HiveQL simili a SQL negli strumenti già usati. Questi strumenti includono Visual Studio Code, Power BI, Apache Zeppelin, Visual Studio, Ambari Hive View, Beeline, Data Analytics Studio e Hive ODBC. Non è possibile eseguire query sul cluster Interactive Query usando la console Hive, Templeton, l'interfaccia della riga di comando di Azure classica o Azure PowerShell.
Sono necessarie la coerenza e la concorrenza delle transazioni
Con l'introduzione della gestione delle risorse con granularità fine, il pre-rilascio e la condivisione dei dati memorizzati nella cache tra query e utenti, Interactive Query supporta utenti simultanei in tutta semplicità. HDInsight supporta la creazione di più cluster in Archiviazione di Azure condivisa. Il metastore Hive facilita il raggiungimento di un livello elevato di concorrenza. È possibile dimensionare la concorrenza aggiungendo più nodi del cluster o aggiungendo più cluster che puntano agli stessi dati e metadati sottostanti. Interactive Query supporta inoltre le transazioni di database ACID (Atomic, Consistent, Isolated e Durable). Le transazioni ACID garantiscono che una transazione, anche se contiene più operazioni, sia contenuta in una singola unità. Pertanto, se una singola operazione nella transazione ha esito negativo, è possibile eseguire il rollback dell'intera operazione, in modo da mantenere i dati coerenti e accurati.
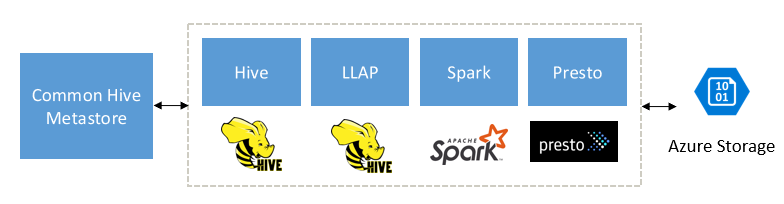
Progettato per integrare Spark, Hive, Presto e altri motori di Big Data
HDInsight Interactive Query è progettato per funzionare correttamente con i motori di Big Data più diffusi, ad esempio Apache Spark, Hive, Presto e molti altri. Questo tipo di query è particolarmente utile perché gli utenti possono scegliere uno di questi strumenti per eseguire le analisi. Con i dati condivisi e l'architettura dei metadati di HDInsight per le tabelle esterne, gli utenti possono creare più cluster con lo stesso motore o un altro motore che punta agli stessi dati e metadati sottostanti. Questa funzionalità è un concetto potente perché non è più legata a una tecnologia per l'analisi.