Repository e sviluppo basato su trunk
Molti data scientist preferiscono usare Python o R per definire carichi di lavoro di apprendimento automatico. È possibile disporre di notebook o script di Jupyter per preparare i dati o eseguire il training di un modello.
L'uso di qualsiasi risorsa di codice diventa più semplice con il controllo del codice sorgente. Il controllo del codice sorgente consiste nella gestione del codice e nel rilevamento delle modifiche apportate dal team al codice.
Se si usano strumenti DevOps come Azure DevOps o GitHub, il codice viene archiviato in un componente definito repository o archivio.
Archivio
Quando si configura il framework MLOps, è probabile che un tecnico di apprendimento automatico crei il repository. Sia che tu scelga di utilizzare Azure Repos in Azure DevOps o i repository GitHub, entrambi usano repository Git per archiviare il codice.
L'ambito del repository generalmente può essere definito in due modi diversi:
- Monorepo: mantenere tutti i carichi di lavoro di machine learning nello stesso repository.
- Repository multipli: creare un repository separato per ogni nuovo progetto di apprendimento automatico.
L'approccio adottato dal team dipende da chi deve accedere alle risorse. Se si intende garantire un accesso rapido a tutte le risorse del codice, il repository singolo può soddisfare meglio i requisiti del team. Se si intende concedere agli utenti l'accesso solo a un progetto su cui lavorano attivamente, il team può preferire l'uso di più repository. Tenere presente che la gestione del controllo di accesso può comportare un sovraccarico maggiore.
Struttura il tuo repo
Indipendentemente dall'approccio adottato, è consigliabile concordare la struttura di cartelle di primo livello standard per i progetti. È possibile, ad esempio, che in tutti i repository siano presenti le cartelle seguenti:
.cloud: contiene codice specifico del cloud, ad esempio modelli per creare un'area di lavoro Azure Machine Learning..ad/.github: contiene artefatti Azure DevOps o GitHub, come pipeline YAML per automatizzare i carichi di lavoro.src: contiene qualsiasi codice (script Python o R) usato per carichi di lavoro di apprendimento automatico, come la pre-elaborazione dei dati o il training del modello.docs: contiene qualsiasi file markdown o altra documentazione usati per descrivere il progetto.pipelines: contiene definizioni di pipeline di Azure Machine Learning.tests: contiene unit test e test di integrazione usati per rilevare bug e problemi nel codice.notebooks: contiene notebook di Jupyter, usati principalmente per la sperimentazione.
Nota
I dati di training non devono essere inclusi nel repository. I dati devono essere archiviati in un database o in un data lake. Azure Machine Learning può accedere direttamente a un database oppure a un data lake archiviando le informazioni di connessione come un archivio dati.
Con una struttura standard usata da ogni progetto, per data scientist e altri collaboratori sarà più facile trovare il codice su cui devono lavorare.
Suggerimento
Vedere altre procedure consigliate per la strutturazione di progetti di data science.
Per imparare a lavorare con i repository in qualità di data scientist, imparerai lo sviluppo basato su trunk.
Sviluppo basato su trunk
Nella maggior parte dei progetti di sviluppo software viene usato Git come sistema di controllo del codice sorgente, sia da Azure DevOps che da GitHub.
Il vantaggio principale dell'uso di Git è la facilità di collaborazione sul codice, con la possibilità di tenere traccia contemporaneamente delle modifiche apportate. È anche possibile aggiungere controlli di approvazione per verificare che al codice di produzione vengano apportate solo le modifiche esaminate e accettate.
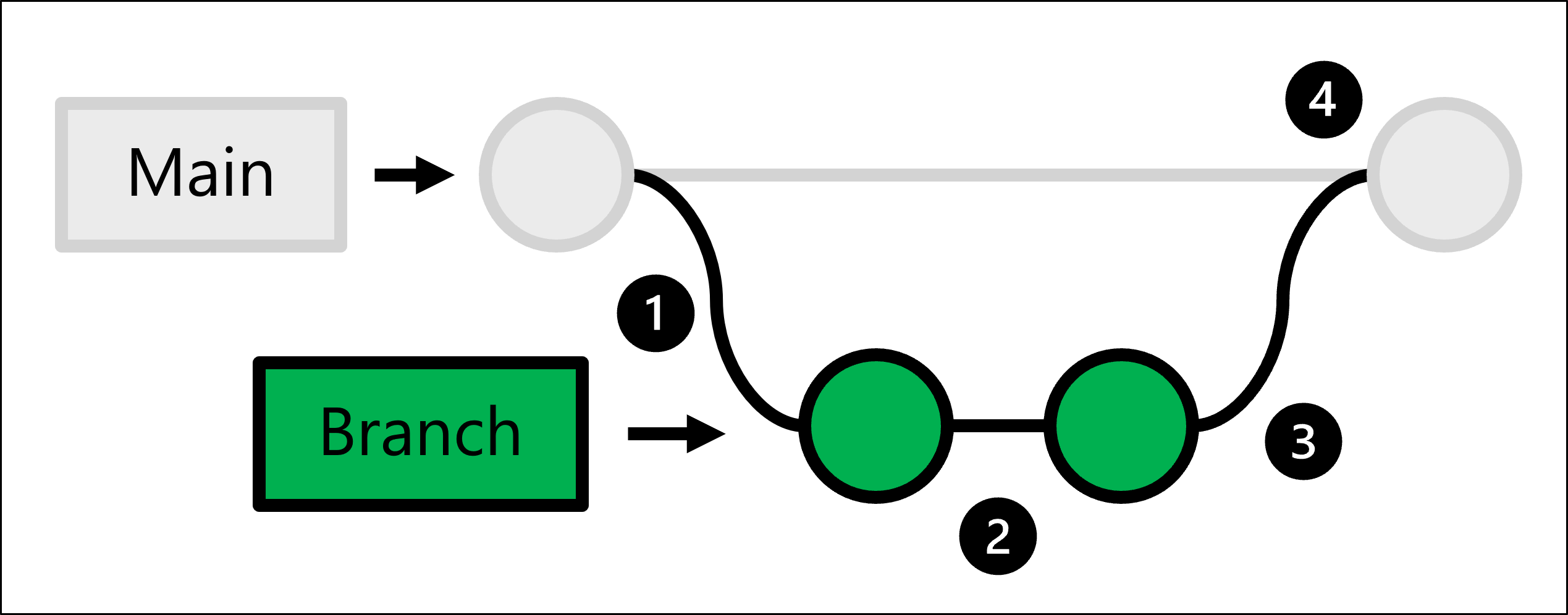
A tale scopo, Git usa lo sviluppo basato su trunk che consente di creare rami.
Il codice di produzione è ospitato nel ramo principale. Operazioni da eseguire ogni volta che si intende apportare una modifica:
- Creare una copia completa del codice di produzione definendo un ramo.
- Nel ramo che hai creato, apporti le modifiche e ne esegui il test.
- Dopo aver apportato le modifiche nel ramo, è possibile chiedere a qualcuno di rivederle.
- Se le modifiche vengono approvate, si unisce il ramo creato con il repository principale e il codice di produzione viene aggiornato per riflettere le modifiche apportate.