Verificare il codice in locale
Ogni volta che si modifica il codice nel progetto di apprendimento automatico, si intende verificare la qualità del codice e del modello.
Durante l'integrazione continua, si creano e si verificano le risorse per l'applicazione. Il ruolo di data scientist prevede di concentrarsi sulla creazione di script usati per la preparazione dei dati e il training del modello. Il tecnico di apprendimento automatico usa gli script in seguito nelle pipeline per automatizzare questi processi.
Per verificare gli script, sono disponibili due attività comuni:
- Linting: consente di verificare la presenza di eventuali errori programmatici o stilistici negli script Python o R.
- Testing unità: consente di verificare le prestazioni del contenuto degli script.
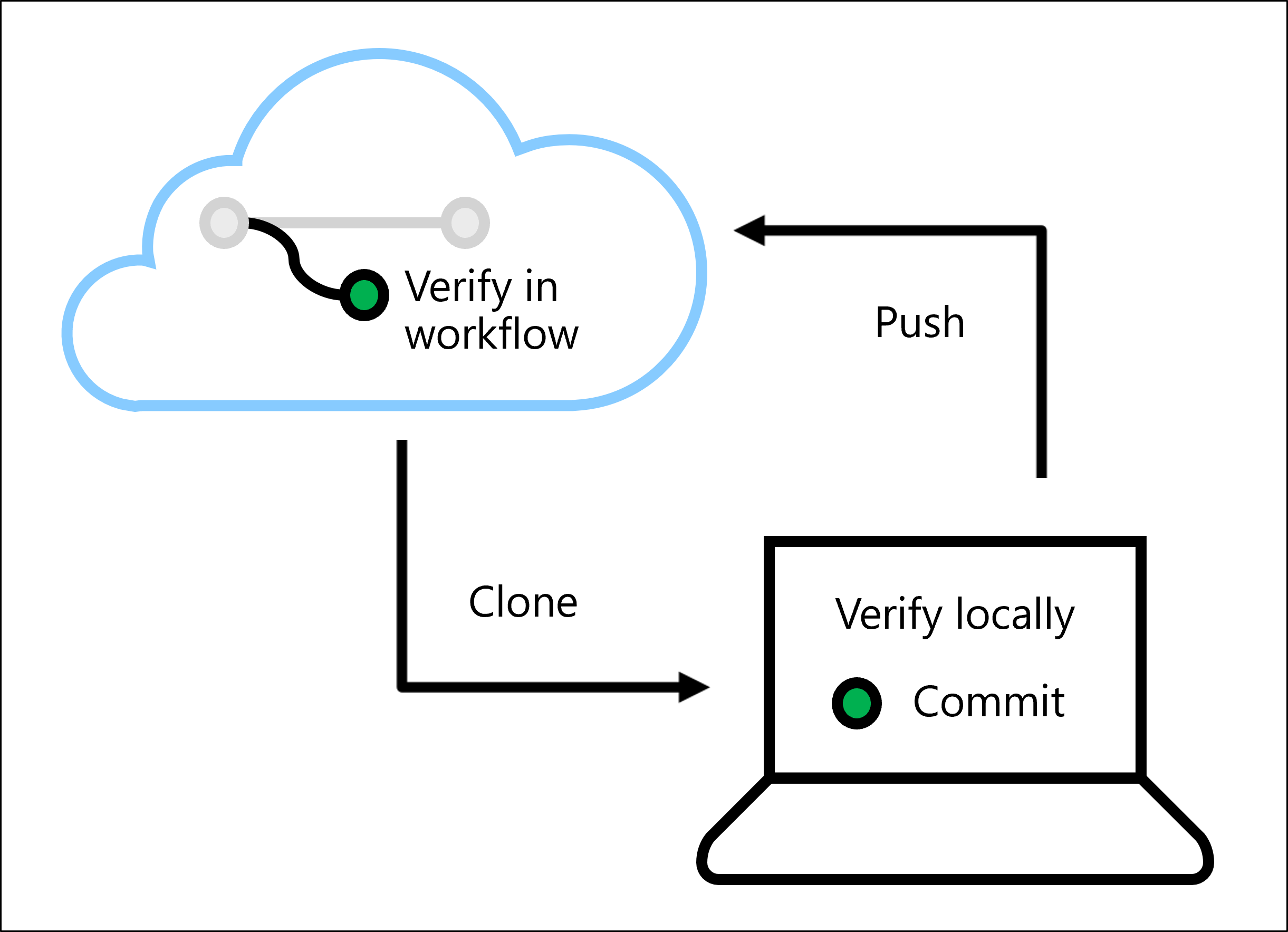
La verifica del codice permette di evitare bug o problemi quando il modello viene distribuito. È possibile verificare il codice in locale eseguendo linter e unit test in locale in un ambiente IDE, ad esempio Visual Studio Code.
È anche possibile eseguire linter e unit test in un flusso di lavoro automatizzato con Azure Pipelines o GitHub Actions.
Verrà descritto come eseguire linting e unit test in Visual Studio Code.
Eseguire il linting del codice
La qualità del codice dipende dagli standard definiti dall'utente e dal team. Per garantire che venga soddisfatta la qualità concordata, è possibile eseguire linter che verificheranno se il codice è conforme agli standard del team.
In base al linguaggio di codice usato, sono disponibili diverse opzioni per eseguire il linting del codice. Se si usa Python, ad esempio, è possibile usare Flake8 o Pylint.
Usare Flake8 per eseguire il linting del codice
Per usare Flake8 in locale con Visual Studio Code:
- Installare Flake8 con
pip install flake8. - Creare un file di configurazione
.flake8e archiviarlo nel repository. - Configurare Visual Studio Code per usare Flake8 come linter tramite le impostazioni (
Ctrl+,). - Cercare
flake8. - Abilitare Python > Linting > Flake8 abilitato.
- Impostare il percorso Flake8 su quello nel repository in cui è archiviato il file
.flake8.
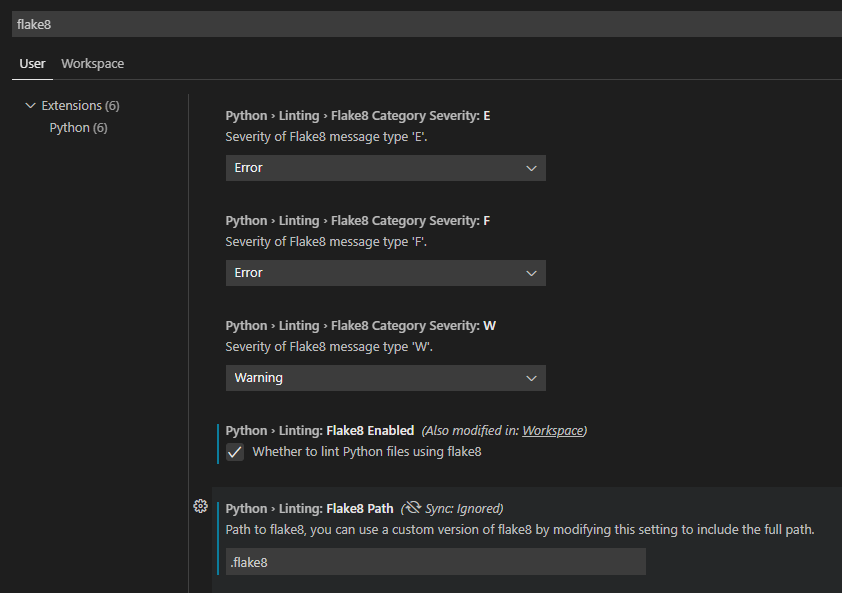
Per specificare gli standard del team per la qualità del codice, è possibile configurare il linter Flake8. Un metodo comune per definire gli standard consiste nel creare un file .flake8 archiviato con il codice.
Il file .flake8 deve iniziare con [flake8], seguito da una delle configurazioni da usare.
Suggerimento
Un elenco completo dei possibili parametri di configurazione è disponibile nella documentazione di Flake8.
Se ad esempio si intende specificare che la lunghezza massima di qualsiasi riga non può superare gli 80 caratteri, aggiungere la riga seguente al file .flake8:
[flake8]
max-line-length = 80
Flake8 include un elenco predefinito di errori che possono essere restituiti. È possibile inoltre usare codici di errore basati sulla guida di stile di PEP 8. È possibile, ad esempio, includere codici di errore che fanno riferimento all'uso appropriato dei rientri o degli spazi vuoti.
È possibile scegliere di selezionare (select) un set di codici di errore che faranno parte del linter o selezionare i codici di errore da ignorare (ignore) nell'elenco predefinito di opzioni.
Di conseguenza, il file di configurazione .flake8 può essere analogo all'esempio seguente:
[flake8]
ignore =
W504,
C901,
E41
max-line-length = 79
exclude =
.git,
.cache,
per-file-ignores =
code/__init__.py:D104
max-complexity = 10
import-order-style = pep8
Suggerimento
Per una panoramica dei codici di errore a cui è possibile fare riferimento, vedere l'elenco degli errori Flake8
Dopo aver configurato Visual Studio Code per eseguire il linting del codice, è possibile aprire qualsiasi file di codice per esaminare i risultati del processo. Eventuali avvisi o errori vengono sottolineati. È possibile selezionare Visualizza problema per esaminare il problema al fine di comprendere l'errore.

Linting con Azure Pipelines o GitHub Actions
È anche possibile eseguire automaticamente il linter con Azure Pipelines o GitHub Actions. L'agente fornito da entrambe le piattaforme esegue il linter quando l'utente esegue una delle operazioni seguenti:
- Creare un file di configurazione
.flake8e archiviarlo nel repository. - Definizione della pipeline di integrazione continua o del flusso di lavoro in YAML.
- Come attività o passaggio, installare Flake8 con
python -m pip install flake8. - Come attività o passaggio, eseguire il comando
flake8per eseguire il linting del codice.
Unit test
Nei punti in cui il processo di linting verifica il modo in cui è stato scritto il codice, gli unit test controllano il funzionamento del codice. Le unità fanno riferimento al codice creato. Gli unit test sono quindi noti anche come test del codice.
Come procedura consigliata, il codice deve esistere principalmente all'esterno delle funzioni. Ciò deve accadere indipendentemente dal fatto che siano state create funzioni per preparare i dati o per eseguire il training di un modello. È possibile applicare unit tes a diversi controlli, ad esempio:
- Verifica della correttezza dei nomi di colonna.
- Verifica del livello di stima del modello nei nuovi set di dati.
- Verifica della distribuzione dei livelli di stima.
In Python è possibile usare Pytest e Numpy (che si basa sul framework Pytest) per testare il codice. Per altre informazioni sull'uso di Pytest, vedere come scrivere test con Pytest.
Suggerimento
Esaminare una procedura dettagliata del test Python in Visual Studio Code.
Si immagini di aver creato una script di training train.py che contiene la funzione seguente:
# Train the model, return the model
def train_model(data, ridge_args):
reg_model = Ridge(**ridge_args)
reg_model.fit(data["train"]["X"], data["train"]["y"])
return reg_model
Si supponga di aver archiviato lo script di training nella directory src/model/train.py nel repository. Per testare la funzione train_model, è necessario importarla da src.model.train.
Il file test_train.py viene creato nella cartella tests. Un modo per testare il codice Python consiste nell'usare numpy. Numpy offre diverse funzioni assert per confrontare matrici, stringhe, oggetti oppure elementi.
Suggerimento
Altre informazioni sulle linee guida per i test quando si usano test Numpy e sul supporto per i test Numpy.
Per testare la funzione train_model, ad esempio, è possibile usare un set di dati di training di piccole dimensioni e usare assert per verificare se le stime sono quasi uguali alle metriche delle prestazioni predefinite.
import numpy as np
from src.model.train import train_model
def test_train_model():
X_train = np.array([1, 2, 3, 4, 5, 6]).reshape(-1, 1)
y_train = np.array([10, 9, 8, 8, 6, 5])
data = {"train": {"X": X_train, "y": y_train}}
reg_model = train_model(data, {"alpha": 1.2})
preds = reg_model.predict([[1], [2]])
np.testing.assert_almost_equal(preds, [9.93939393939394, 9.03030303030303])
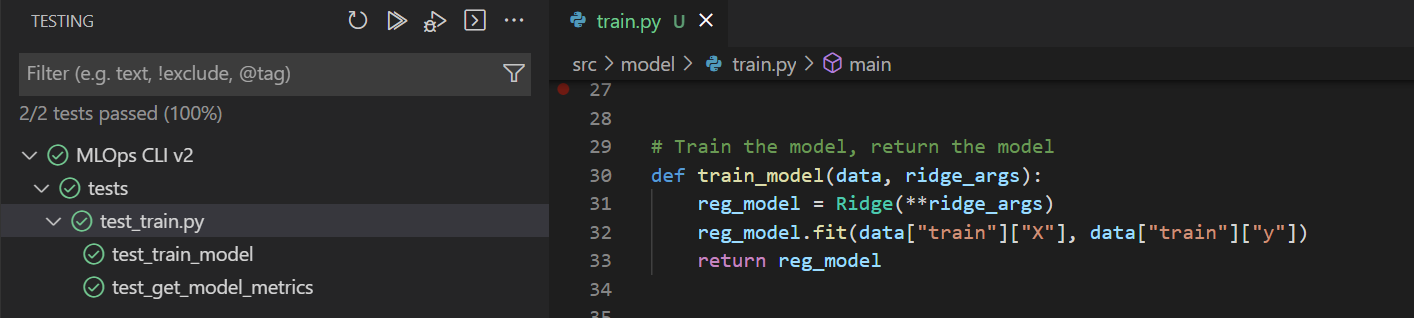
Per testare il codice in Visual Studio Code tramite l'interfaccia utente:
- Installare tutte le librerie necessarie per eseguire lo script di training.
- Verificare che
pytestsia installato e abilitato in Visual Studio Code. - Installare l'estensione Python per Visual Studio Code.
- Selezionare lo script
train.pydi cui eseguire il test. - Selezionare la scheda Test nel menu a sinistra.
- Configurare i test Python selezionando pytest e impostando la directory di test sulla cartella
tests/. - Eseguire tutti i test selezionando il pulsante di riproduzione ed esaminare i risultati.
Per eseguire il test in una pipeline di Azure DevOps o in GitHub Actions:
- Verificare che tutte le librerie necessarie siano installate per eseguire lo script di training. Idealmente, usare un oggetto
requirements.txtper elencare tutte le librerie conpip install -r requirements.txt - Installare
pytestconpip install pytest - Eseguire i test con
pytest tests/
I risultati dei test vengono visualizzati nell'output della pipeline o del flusso di lavoro eseguito.
Nota
Se durante l'esecuzione del processo di linting o del testing unità viene restituito un errore, la pipeline di integrazione continua potrebbe non riuscire. È quindi preferibile verificare il codice in locale prima di attivare la pipeline di integrazione continua.