Descrivere Azure Synapse Analytics SQL
Azure Synapse SQL consente di implementare soluzioni di data warehouse o di eseguire la virtualizzazione dei dati.
Un data warehouse è un componente di base delle soluzioni di Business Intelligence (BI) che offre un repository centrale dei dati archiviati nelle tabelle relazionali. Semplifica le soluzioni per le analisi descrittive. I dati vengono recuperati, puliti e trasformati da diversi sistemi di dati di origine e vengono quindi inviati in un formato relazionale strutturato comunemente definito schema star.
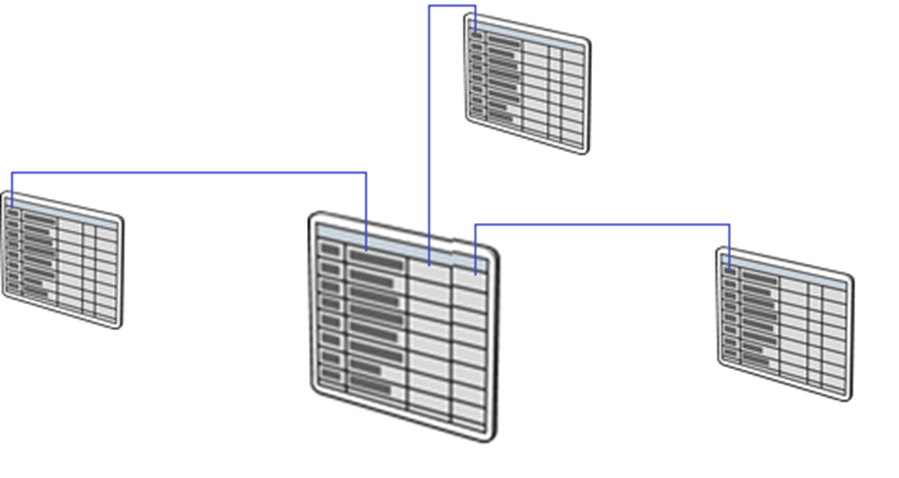
I dati in un data warehouse vengono archiviati in tabelle permanenti popolate tramite un processo di estrazione, trasformazione e caricamento (ETL) da servizi come le pipeline di Azure Synapse o Azure Data Factory. Di conseguenza, è necessario comprendere i dati archiviati nei sistemi di origine, come dovrebbero arrivare all'interno del data warehouse, che a sua volta determina come pulire o trasformare i dati.
La virtualizzazione dei dati consente di interagire con i dati senza conoscere il formato, la struttura o il tipo di dati. Consente di esplorare i dati senza conoscere le specifiche tecniche dei dati di origine, un aspetto molto utile quando si esegue l'analisi diagnostica dove la necessità di accedere ai dati in modo tempestivo per rispondere a una domanda è più importante.
La virtualizzazione dei dati consente anche scenari di preparazione dei dati ad hoc, in cui le organizzazioni vogliono sbloccare le informazioni dettagliate dai propri archivi dati senza eseguire i processi formali di configurazione di un data warehouse. È possibile estrarre dati da un sistema di origine in un formato non elaborato e caricarli in un data lake. Da qui sarà possibile applicare le trasformazioni per presentare i dati in base alle esigenze. Poiché la parte più complessa del processo di estrazione, caricamento e trasformazione (ELT) è alla fine, significa che l'accesso ai dati è molto più rapido.
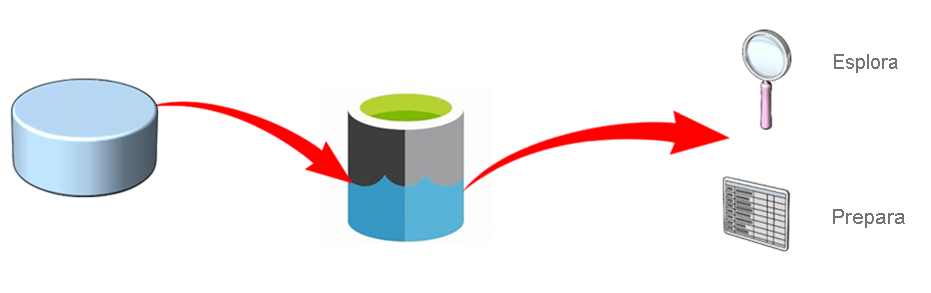
Per distribuire questi tipi di soluzioni, Azure Synapse SQL offre un modello dedicato e un modello serverless del servizio per soddisfare le diverse esigenze di entrambe le soluzioni.
Il modello dedicato è chiamato pool SQL dedicati. Fa riferimento alle funzionalità di data warehousing disponibili a livello generale in Azure Synapse Analytics. I pool SQL dedicato rappresentano una raccolta di risorse analitiche di cui viene effettuato il provisioning durante l'uso di Synapse SQL. Quando è necessario avere prestazioni e costi prevedibili, il miglior approccio consiste nella creazione di pool SQL dedicati per riservare la potenza di elaborazione ai dati archiviati in modo permanente nelle tabelle SQL in un data warehouse.
Il modello serverless è ideale per carichi di lavoro non pianificati o ad hoc generati dall'approccio di analisi diagnostica. Pertanto, se si esegue l'esplorazione dei dati e si preparano i dati per la virtualizzazione dei dati, il modello serverless SQL sarà il modello migliore da usare.