Descrivere Apache Spark in Azure Synapse Analytics
Apache Spark è un sistema distribuito open source che viene usato per l'elaborazione dei carichi di lavoro di Big Data. I carichi di lavoro di Big Data sono definiti come carichi di lavoro per gestire dati di dimensioni troppo grandi o troppo complessi per i sistemi di database tradizionali. Apache Spark elabora grandi quantità di dati in memoria, migliorando in modo più efficace le prestazioni di analisi dei Big Data. Questa funzionalità è disponibile all'interno di Azure Synapse Analytics ed è chiamata pool di Spark.
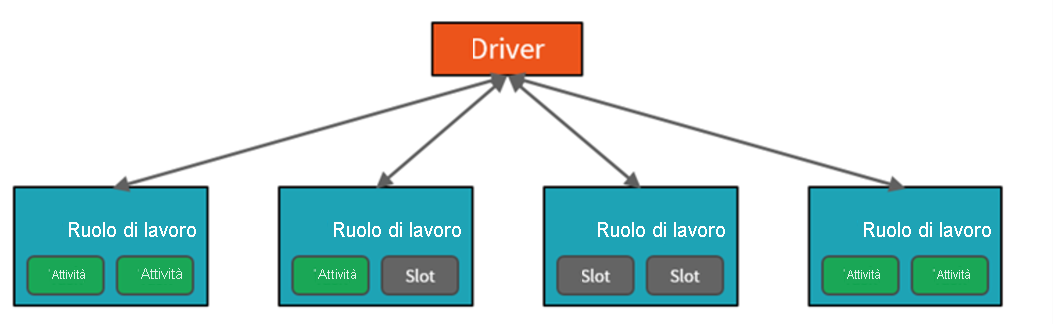
Per ottenere questa funzionalità, i cluster di pool di Spark sono gruppi di computer trattati come un singolo computer e gestiscono l'esecuzione di comandi eseguiti dai notebook. I cluster consentono l'elaborazione dei dati in parallelo in molti computer per migliorare la scalabilità e le prestazioni. La funzionalità prevede un nodo del driver Spark e nodi di lavoro. Il nodo del driver invia il lavoro ai nodi di lavoro e indica di eseguire il pull dei dati da un'origine dati specificata. Inoltre, è possibile configurare il numero di nodi necessari per eseguire l'attività.
I pool di Spark in Azure Synapse Analytics offrono un servizio Spark completamente gestito. Di seguito sono elencati i vantaggi della creazione di un pool di Spark in Synapse Analytics.
Velocità ed efficienza
Le istanze di Spark vengono avviate in circa 2 minuti in presenza di meno di 60 nodi e in circa 5 minuti in presenza di più di 60 nodi. Per impostazione predefinita, l'istanza viene arrestata 5 minuti dopo l'esecuzione dell'ultimo processo, a meno che non venga mantenuta attiva da una connessione del notebook.
Facilità di creazione
È possibile creare un nuovo pool di Spark in Azure Synapse in pochi minuti usando il portale di Azure, Azure PowerShell o Synapse Analytics .NET SDK.
Semplicità di utilizzo
Synapse Analytics include un notebook personalizzato derivato da Nteract. È possibile usare questi notebook per la visualizzazione e l'elaborazione interattiva di dati.
Scalabilità
Nei pool di Apache Spark in Azure Synapse può essere abilitata la scalabilità automatica, in modo da dimensionare i pool aggiungendo o rimuovendo i nodi secondo le necessità. È anche possibile arrestare i pool di Spark senza alcuna perdita di dati, in quanto tutti i dati sono archiviati in Archiviazione di Azure o Data Lake Storage.
Supporto per Azure Data Lake Storage Gen2
I pool di Spark in Azure Synapse possono usare sia Azure Data Lake Storage Gen2 sia l'archiviazione BLOB.
Nel caso d'uso principale per Apache Spark per Azure Synapse Analytics vengono elaborati i carichi di lavoro di Big Data che non possono essere gestiti da Azure Synapse SQL e in cui non è presente un'implementazione di Apache Spark esistente.
Probabilmente è necessario eseguire un calcolo complesso su grandi volumi di dati. La gestione di questo requisito nei pool di Spark sarà molto più efficiente rispetto alla gestione in Synapse SQL. È possibile passare i dati al cluster Spark per eseguire il calcolo, quindi passare di nuovo i dati elaborati nel data warehouse o nel data lake.
Se è già presente un'implementazione di Spark, Azure Synapse Analytics può anche essere integrato con altre implementazioni di Spark, ad esempio Azure Databricks. Per questa ragione, non è necessario usare la funzionalità in Azure Synapse Analytics se è già presente un'installazione di Spark.
Infine, i pool di Spark in Azure Synapse Analytics includono librerie Anaconda preinstallate. Anaconda offre circa 200 librerie che consentono di usare il pool di Spark per il Machine Learning, l'analisi dei dati e la visualizzazione dei dati. Ciò può consentire ai data scientist e agli analisti di dati di interagire con i dati anche usando il pool di Spark.