Informazioni su Apache Spark
Apache Spark è un framework di elaborazione dati distribuito che consente l'analisi dei dati su larga scala coordinando il lavoro su più nodi di elaborazione in un cluster.
Funzionamento di Spark
Le applicazioni Apache Spark vengono eseguite in un cluster come un set di processi indipendenti, coordinati dall'oggetto SparkContext nel programma principale (chiamato il programma driver). SparkContext si connette alla gestione cluster, che alloca le risorse tra applicazioni usando un'implementazione di Apache Hadoop YARN. Una volta connesso, Spark acquisisce gli executor nei nodi nel cluster per eseguire il codice dell'applicazione.
SparkContext esegue la funzione principale e le operazioni in parallelo sui nodi del cluster e quindi raccoglie i risultati delle operazioni. I nodi leggono e scrivono dati da e verso il file system e memorizzano nella cache i dati trasformati in memoria come Resilient Distributed Dataset (RDD).
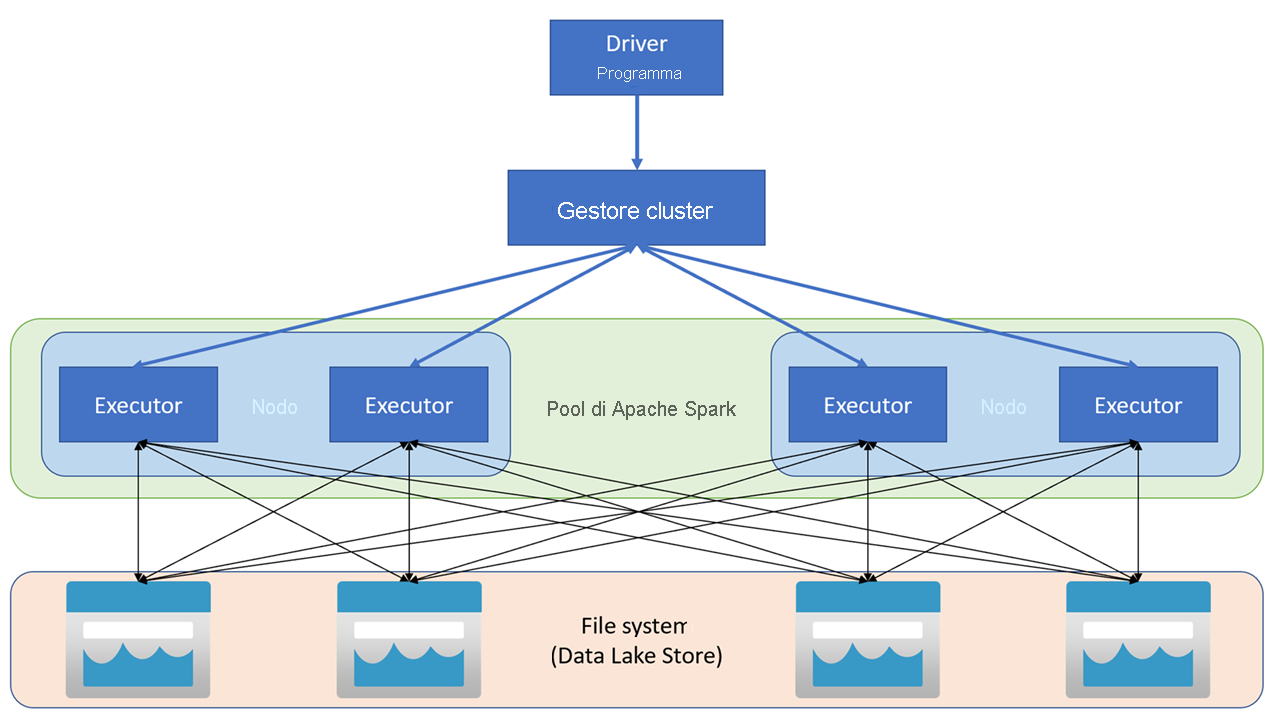
SparkContext è responsabile della conversione di un'applicazione in un grafo aciclico diretto (DAG). Il grafo è costituito da singole attività che vengono eseguite all'interno di un processo executor nei nodi. Ogni applicazione ottiene i propri processi executor, che rimangono attivi per la durata dell'intera applicazione ed eseguono attività in più thread.
Pool di Spark in Azure Synapse Analytics
In Azure Synapse Analytics un cluster viene implementato come pool di Spark, che fornisce un runtime per le operazioni Spark. È possibile creare uno o più pool di Spark in un'area di lavoro Azure Synapse Analytics con il portale di Azure o in Azure Synapse Studio. Quando si definisce un pool di Spark, è possibile specificare le opzioni di configurazione per il pool, tra cui:
- Nome per il pool di Spark.
- Dimensioni della macchina virtuale (VM) usate per i nodi nel pool, inclusa l'opzione per l'uso dei nodi abilitati per GPU con accelerazione hardware.
- Numero di nodi nel pool e se le dimensioni del pool sono fisse oppure se è possibile portare online singoli nodi in modo dinamico per ridimensionare automaticamente il cluster. In questo caso è possibile specificare il numero minimo e massimo di nodi attivi.
- Versione del runtime Spark da usare nel pool, che determina le versioni installate di singoli componenti, ad esempio Python, Java e altri.
Suggerimento
Per altre informazioni sulle opzioni di configurazione del pool di Spark, vedere Configurazioni del pool di Apache Spark in Azure Synapse Analytics nella documentazione di Azure Synapse Analytics.
I pool di Spark in un'area di lavoro Azure Synapse Analytics sono serverless, ovvero vengono avviati su richiesta e arrestati quando sono inattivi.