Visualizza i dati
Uno dei modi più intuitivi per analizzare i risultati delle query sui dati consiste nel visualizzarli come grafici. I notebook in Azure Databricks offrono funzionalità per i grafici nell'interfaccia utente e, quando tali funzionalità non soddisfano le esigenze specifiche, è possibile usare una delle numerose librerie di grafica di Python per creare e mostrare visualizzazioni dei dati nel notebook.
Uso di grafici di notebook predefiniti
Quando si visualizza un dataframe o si esegue una query SQL in un notebook Spark in Azure Databricks, i risultati vengono visualizzati sotto la cella di codice. Per impostazione predefinita, viene eseguito il rendering dei risultati come tabella, ma è anche possibile mostrare i risultati come visualizzazione e personalizzare la modalità di rappresentazione dei dati nel grafico, come illustrato di seguito:
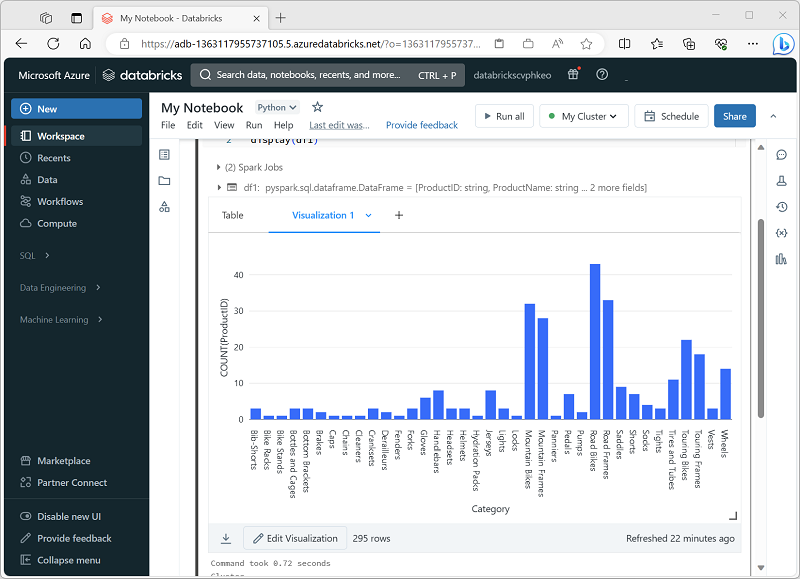
Tipi di visualizzazione
Si tratta dei diversi tipi di visualizzazioni che è possibile creare in Databricks, ognuna valida per determinati tipi di informazioni dettagliate sui dati. Punti chiave:
Grafici a barre/Grafici a linee/Grafici ad area: per visualizzare le tendenze nel tempo, confronti categorici o entrambi. Utile per vedere l'evoluzione delle metriche.
Grafici a torta: buoni per visualizzare parti proporzionali di un intero (ma non per le serie temporali).
Istogramma: per visualizzare la distribuzione dei dati numerici (come vengono distribuiti i valori, raggruppati).
Mappa termica: utile per la visualizzazione di due assi categorici e la colorazione in base a un valore numerico, consente di visualizzare i modelli tra i gruppi.
Grafici a dispersione/bolle: mostra la relazione tra due (o più) variabili numeriche; le bolle consentono di utilizzare dimensioni o colore come terza dimensione.
Box plot: per confrontare le distribuzioni (dispersione, quartili, valori anomali) attraverso le categorie.
Grafico combinato: combinazione di linee e barre nello stesso grafico, utile in cui confrontare metriche diverse con scale diverse.
Tabella pivot: consente di modellare e aggregare i dati in formato tabella (ad esempio SQL PIVOT/GROUP BY), utile per le analisi a schede incrociate.
Tipi speciali: analisi della coorte (gruppi di rilevamento nel tempo), visualizzazione del contatore (evidenziando una singola metrica di riepilogo, forse rispetto alla destinazione), imbuto, visualizzazioni mappa (coropletica, marcatore), nuvola di parole e così via. Sono più specializzati.
La funzionalità di visualizzazione predefinita nei notebook è utile quando si vogliono riepilogare rapidamente i dati visivamente. Quando si vuole avere un maggiore controllo sulla formattazione dei dati o sulla visualizzazione dei valori già aggregati in una query, è consigliabile usare un pacchetto grafico per creare visualizzazioni personalizzate.
Uso di pacchetti grafici nel codice
Sono disponibili molti pacchetti grafici che è possibile usare per creare visualizzazioni dei dati nel codice. In particolare, Python supporta una vasta selezione di pacchetti; la maggior parte di essi si basa sulla libreria Matplotlib di base. È possibile eseguire il rendering dell'output di una libreria grafica in un notebook, semplificando la combinazione di codice per inserire e modificare i dati con visualizzazioni dei dati inline e celle Markdown per fornire commenti.
È ad esempio possibile usare il codice PySpark seguente per aggregare i dati dei prodotti ipotetici esaminati in precedenza in questo modulo e usare Matplotlib per creare un grafico dai dati aggregati.
from matplotlib import pyplot as plt
# Get the data as a Pandas dataframe
data = spark.sql("SELECT Category, COUNT(ProductID) AS ProductCount \
FROM products \
GROUP BY Category \
ORDER BY Category").toPandas()
# Clear the plot area
plt.clf()
# Create a Figure
fig = plt.figure(figsize=(12,8))
# Create a bar plot of product counts by category
plt.bar(x=data['Category'], height=data['ProductCount'], color='orange')
# Customize the chart
plt.title('Product Counts by Category')
plt.xlabel('Category')
plt.ylabel('Products')
plt.grid(color='#95a5a6', linestyle='--', linewidth=2, axis='y', alpha=0.7)
plt.xticks(rotation=70)
# Show the plot area
plt.show()
La libreria Matplotlib richiede che i dati si trovano in un dataframe Pandas anziché in un dataframe Spark, quindi il metodo toPandas viene usato per convertirli. Il codice crea quindi una figura con una dimensione specificata e traccia un grafico a barre con una configurazione di proprietà personalizzata prima di visualizzare il tracciato risultante.
Il grafico prodotto dal codice sarà simile all'immagine seguente:
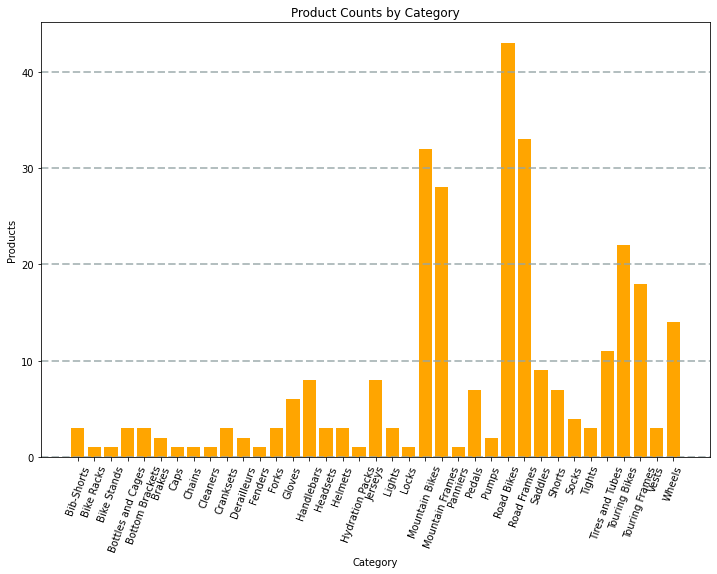
È possibile usare la libreria Matplotlib per creare molti tipi di grafico; oppure, se preferito, è possibile usare altre librerie come Seaborn per creare grafici altamente personalizzati.
Nota
Le librerie Matplotlib e Seaborn possono essere già installate nei cluster di Databricks, a seconda del Databricks Runtime per il cluster. In caso contrario, oppure se si vuole usare una libreria diversa che non è già installata, è possibile aggiungerla al cluster. Per informazioni dettagliate, vedere Librerie di cluster nella documentazione di Azure Databricks.