Descrivere come eseguire Slurm con Azure CycleCloud
Attenzione
Questo contenuto fa riferimento a CentOS, una distribuzione Linux con stato End Of Life (EOL). Valutare le proprie esigenze e pianificare di conseguenza. Per ulteriori informazioni, consultare la Guida alla fine del ciclo di vita di CentOS.
Dopo aver completato questa unità, si sarà in grado di usare Slurm in Azure CycleCloud.
Abilitazione di Slurm in CycleCloud
È possibile distribuire un cluster High Performance Computing (HPC) tramite Azure CycleCloud eseguendo i passaggi seguenti:
Connettersi a un'istanza distribuita di Azure CycleCloud ed eseguire l'autenticazione.
Nella pagina Create a New Cluster (Crea un nuovo cluster) esaminare le opzioni disponibili e nella sezione Schedulers (Utilità di pianificazione) selezionare Slurm.

Nella scheda About della pagina New Slurm Cluster, nella casella di testo Cluster Name, specificare un nome per il cluster Slurm.
Nella scheda Required Settings della pagina New Slurm Cluster, nella casella di testo Cluster Name, configurare le impostazioni seguenti (lasciare i valori predefiniti per le altre impostazioni):
- Area. Definisce quale data center ospiterà i nodi del cluster.
- Scheduler VM Type. Consente di specificare lo SKU della macchina virtuale che ospiterà il pianificatore di processi.
- HPC VM Type. Consente di specificare lo SKU della macchina virtuale che ospiterà i carichi di lavoro delle partizioni HPC dell'host.
- HTC VM Type. Consente di specificare lo SKU della macchina virtuale che ospiterà i carichi di lavoro delle partizioni HTC dell'host.
- Abilitare la scalabilità automatica. Consente di abilitare o disabilitare l'avvio e l'arresto delle istanze di macchine virtuali che ospitano nodi delle partizioni quando sono necessarie o non lo sono più.
- Max HPC Cores. Il numero massimo di core di CPU che possono essere allocati alle partizioni HPC quando è abilitata la scalabilità automatica.
- Max HTC Cores. Il numero massimo di core di CPU che possono essere allocati alle partizioni HTC quando è abilitata la scalabilità automatica.
- Max VMs per Scaleset. Il numero massimo di macchine virtuali che è possibile usare per i carichi di lavoro delle partizioni dell'host.
- Use Spot Instances. Indica se si vuole consentire l'uso di istanze spot di Azure. Anche se le istanze spot sono notevolmente meno costose da eseguire, possono essere rimosse senza alcun avviso, il che può influire sull'esecuzione dei processi.
- Subnet ID. La subnet della rete virtuale di Azure che ospiterà le macchine virtuali dei nodi dell'host.

Nella pagina Network Attached Storage configurare se usare le opzioni Builtin o External NFS per il montaggio NAS. Se si seleziona Builtin, il nodo del pianificatore verrà configurato come server NFS che funge da punto di montaggio per gli altri nodi. Se si specifica External NFS, è possibile specificare i dettagli di un dispositivo NAS come Azure NetApp Files, Cache HPC o una macchina virtuale appositamente configurata che esegue un server NFS.
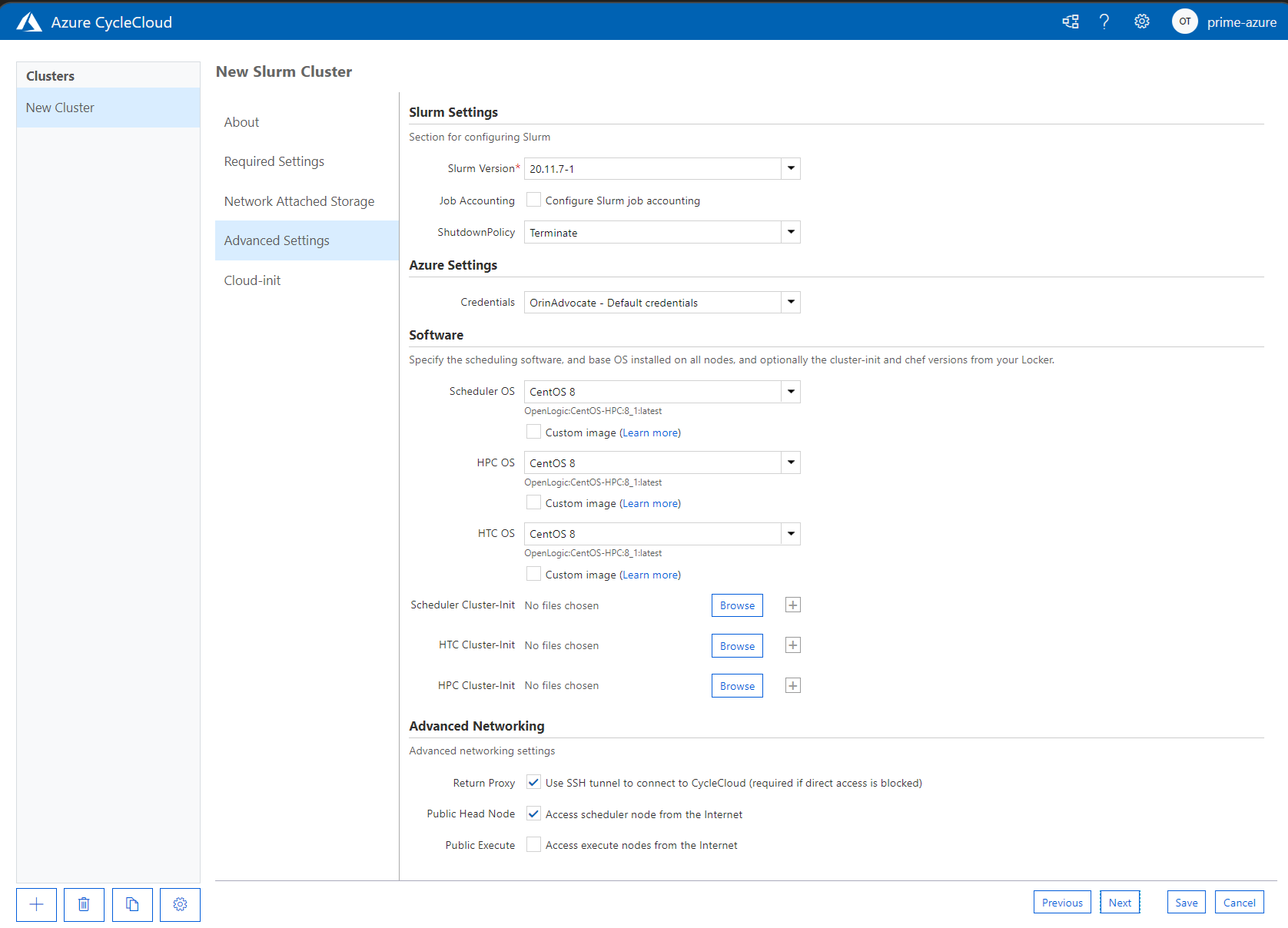
Nella pagina Advanced Settings è possibile specificare le impostazioni seguenti:
- Slurm Version. La versione di Slurm che verrà usata con il cluster.
- Job Accounting. Consente di specificare se abilitare l'accounting dei processi o meno e di configurare le impostazioni per l'archiviazione dei dati di accounting.
- Shutdown Policy. È possibile scegliere se terminare o deallocare l'istanza.
- Credenziali. Le credenziali usate per connettersi alla sottoscrizione di Azure associata.
- Scheduler OS. Consente di specificare il sistema operativo da usare per ospitare il pianificatore. Il valore predefinito è CentOS 8, ma è possibile scegliere un'immagine personalizzata.
- HPC OS. Consente di specificare il sistema operativo da usare per ospitare il pianificatore. Il valore predefinito è CentOS 8, ma è possibile scegliere un'immagine personalizzata.
- Scheduler Cluster Init. Istruzioni personalizzate da applicare alla macchina virtuale del pianificatore.
- HTC Cluster Init. Istruzioni personalizzate da applicare ai nodi HTC.
- Rete avanzata. Consente di abilitare Return Proxy, nonché di specificare se il nodo head è accessibile da indirizzi Internet e se i nodi di esecuzione sono accessibili da Internet.
Cloud-init consente di passare impostazioni di configurazione personalizzate ai nodi delle macchine virtuali dopo la distribuzione.



Impostazioni di memoria
CycleCloud imposta automaticamente la quantità di memoria disponibile per Slurm da usare a scopo di pianificazione. Poiché la quantità di memoria disponibile può cambiare leggermente in base alle diverse opzioni del kernel Linux e il sistema operativo e la macchina virtuale possono usare una piccola quantità di memoria che altrimenti sarebbe disponibile per i processi, CycleCloud riduce automaticamente la quantità di memoria nella configurazione Slurm. Per impostazione predefinita, CycleCloud mantiene il 5% della memoria disponibile segnalata in una macchina virtuale, ma questo valore può essere sostituito nel modello del cluster impostando slurm.dampen_memory sulla percentuale di memoria da conservare. Ad esempio, per conservare il 20% della memoria di una macchina virtuale:
slurm.dampen_memory=20
Configurazione delle partizioni Slurm
Il modello predefinito fornito con Azure CycleCloud include due partizioni (hpc e htc) ed è possibile definire matrici di nodi personalizzate mappate direttamente alle partizioni Slurm. Ad esempio, per creare una partizione GPU, aggiungere la sezione seguente al modello di cluster:
[[nodearray gpu]]
MachineType = $GPUMachineType
ImageName = $GPUImageName
MaxCoreCount = $MaxGPUExecuteCoreCount
Interruptible = $GPUUseLowPrio
AdditionalClusterInitSpecs = $ExecuteClusterInitSpecs
[[[configuration]]]
slurm.autoscale = true
# Set to true if nodes are used for tightly-coupled multi-node jobs
slurm.hpc = false
[[[cluster-init cyclecloud/slurm:execute:2.0.1]]]
[[[network-interface eth0]]]
AssociatePublicIpAddress = $ExecuteNodesPublic
Modifica di cluster Slurm esistenti
Se si modificano e si applicano modifiche a un cluster Slurm esistente, è necessario ricompilare il file slurm.conf e aggiornare i nodi esistenti nel cluster. A tale scopo, è possibile usare uno script presente nei cluster Slurm distribuiti in Azure cyclecloud usando uno script speciale denominato cyclecloud_slurm.sh che si trova nella directory /opt/cycle/slurm nel nodo del pianificatore di Slurm. Dopo aver apportato modifiche al cluster, eseguire lo script seguente come radice con il parametro apply_changes. Ad esempio:
/opt/cycle/slurm/cyclecloud_slurm.sh apply_changes
Se si apportano modifiche che influiscano su nodi che partecipano a una partizione MPI (Message Passing Interface).
Disabilitazione della scalabilità automatica per nodi o partizioni
È possibile disabilitare la scalabilità automatica per un cluster Slurm in esecuzione modificando direttamente il file slurm.conf. È possibile escludere singoli nodi o intere partizioni dalla scalabilità automatica.
Per escludere uno o più nodi dalla scalabilità automatica, aggiungere SuspendExcNodes=<listofnodes> al file di configurazione di Slurm. Ad esempio, per escludere i nodi 1 e 2 dalla partizione hpc, aggiungere quanto segue a /sched/slurm.conf e quindi riavviare il servizio slurmctld:
SuspendExcNodes=hpc-pg0-[1-2]
Le partizioni vengono escluse anche dal file /sched/slurm.conf. Ad esempio, per escludere la partizione hpc dalla scalabilità automatica, aggiungere la riga seguente a slurm.conf e riavviare il servizio slurmctld.
SuspendExcParts=hpc