Creazione di chiavi primarie e secondarie in una tabella
Nelle tabelle le chiavi sono essenziali perché permettono di rendere univoci i record e di ottimizzare le prestazioni del database quando si cercano o si filtrano i dati delle tabelle.
In AL, una definizione di chiave è una sequenza di uno o più ID di campo da una tabella. È possibile definire le chiavi negli oggetti tabella ed estensione tabella, a seconda del tipo di chiave. Esistono due tipi di chiavi, primaria e secondaria.
Chiavi primarie
Una chiave primaria identifica in modo univoco ciascun record in una tabella. Ogni tabella ha una chiave primaria e in ogni tabella può essere presente una sola chiave primaria. Le chiavi primarie sono definite soltanto sugli oggetti tabella. In SQL, gli oggetti estensione tabella ereditano la chiave primaria dell'oggetto tabella che estendono (l'oggetto tabella di base). Pertanto, qualsiasi chiave definita in un oggetto estensione tabella si considera una chiave secondaria.
Chiavi secondarie
Le chiavi secondarie creano indici in SQL. Sono definite sia negli oggetti tabella che negli oggetti estensione tabella. È possibile definire più chiavi secondarie per un singolo oggetto tabella ed estensione tabella.
Una chiave in un oggetto estensione tabella può includere campi dall'oggetto tabella di base o dall'oggetto estensione tabella.
Ogni tabella in Dynamics 365 Business Central richiede una chiave primaria. Non si possono avere tabelle senza chiavi nell'applicazione. In una tabella si possono avere chiavi primarie e secondarie.
La chiave primaria è sempre la prima dell'elenco, è sempre attiva e consente di rendere univoci i record. Si possono avere fino a 40 chiavi per ogni tabella e ogni chiave può essere composta da un massimo di 20 campi.
La chiave primaria tiene traccia dei dati in una tabella ed è composta da un massimo di 16 campi in un record. La combinazione di valori nei campi della chiave primaria permette di identificare in modo univoco ogni record. In AL, la prima chiave definita in un oggetto tabella è la chiave primaria. La chiave primaria determina l'ordine logico in cui vengono archiviati i record, indipendentemente dalla posizione fisica dei campi nell'oggetto tabella.
Dal punto di vista logico, i record vengono archiviati in sequenza in ordine crescente e ordinati in base alla chiave primaria. Prima di aggiungere un nuovo record a una tabella, SQL Server verifica se le informazioni nei campi della chiave primaria del record sono univoche. Se così è, inserisce il record nella posizione logica corretta. I record vengono ordinati in modo dinamico affinché il database sia sempre strutturalmente corretto. Questo ordinamento consente la manipolazione e il recupero dei dati in tempi brevi.
La chiave primaria è sempre attiva. SQL Server mantiene la tabella ordinata in base all'ordine della chiave primaria e rifiuta i record con valori duplicati nei campi della chiave primaria. Per questo motivo, i valori nella chiave primaria devono essere sempre univoci. Non è il valore in ogni campo della chiave primaria che deve essere univoco. Il criterio di univocità si applica invece alla combinazione di valori in tutti i campi che costituiscono la chiave primaria.
Le chiavi secondarie sono facoltative e possono aiutare a eseguire le azioni di ricerca più velocemente. Potrebbero avere un impatto sulle prestazioni perché sono indici in SQL Server. È quindi consigliabile limitare le chiavi secondarie a un massimo che va da tre a cinque per ogni tabella.
In un oggetto tabella, tutte le chiavi definite dopo la chiave primaria sono denominate chiavi secondarie. Tutte le chiavi definite in un oggetto estensione tabella sono considerate chiavi secondarie.
Una chiave secondaria viene implementata in SQL Server usando una struttura denominata indice. Questa struttura è simile all'indice adottato nei libri di testo. L'indice di un libro di testo elenca in ordine alfabetico i termini importanti alla fine di un libro. Accanto a ciascun termine sono indicati i numeri di pagina. È possibile eseguire una ricerca rapida nell'indice per trovare un elenco di numeri di pagina (indirizzi) e individuare il termine eseguendo una ricerca nelle pagine specificate. L'indice è un indicatore esatto che mostra dove si trova ogni termine nel libro di testo.
Quando si definisce una chiave secondaria e la si contrassegna come abilitata, in SQL Server viene gestito automaticamente un indice. L'indice riflette l'ordinamento definito dalla chiave. Possono essere attive più chiavi secondarie contemporaneamente.
Una chiave secondaria può essere disabilitata in modo che non occupi spazio nel database o usi il tempo durante gli aggiornamenti per gestire il proprio indice. Le chiavi disabilitate possono essere nuovamente abilitate, anche se questa operazione può richiedere molto tempo poiché SQL Server deve eseguire la scansione dell'intera tabella per ricostruire l'indice.
I campi che compongono le chiavi secondarie non sempre contengono dati univoci. SQL Server non rifiuta i record con dati duplicati nei campi della chiave secondaria. Pertanto, se due o più record contengono informazioni identiche nella chiave secondaria, SQL Server usa la chiave primaria della tabella per risolvere questo conflitto.
Se si osservano le tabelle master, come Cliente, Fornitore o Articolo, si può notare che la chiave primaria è la stessa per ogni tabella. Tutte le tabelle master usano il campo N. come chiave primaria. Questo campo è implementato con un tipo di dati Codice, il che significa che i valori della chiave primaria sono sempre in maiuscolo e la lunghezza è impostata su 20.
Una chiave primaria può anche essere costituita da più di un campo. Ad esempio, la tabella Testate vendita usa una combinazione di campi Tipo di documento e N. Nella tabella Testate vendita si mantengono preventivi, fatture, ordini e così via. Il tipo di documento è memorizzato nel campo Tipo di documento. Poiché si può avere lo stesso N. per una fattura e per un ordine, è necessaria una chiave primaria che contenga entrambi i campi.
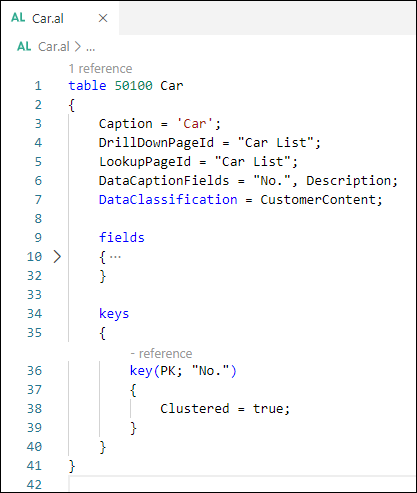
Chiavi secondarie univoche
Una definizione di chiave include la proprietà Unique che è possibile usare per creare un vincolo univoco sulla tabella in SQL Server. Una chiave univoca garantisce che i record in una tabella non abbiano valori di campo identici. Con una chiave univoca, quando la tabella viene convalidata, viene verificata l'univocità del valore della chiave. Se la tabella include record con valori duplicati, la convalida ha esito negativo. Un altro vantaggio degli indici univoci è il fatto che fornisce a Query Optimizer informazioni che facilitano la creazione di piani di esecuzione più efficienti.
È possibile creare chiavi secondarie univoche composte da più campi, come avviene con le chiavi primarie. In questo caso, è la combinazione di valori nella chiave secondaria che deve essere univoca. Si prenda ad esempio la tabella Cliente. Si supponga di voler essere certi che non vi siano clienti con la stessa combinazione di valori per i campi Nome, Indirizzo e Città. È possibile creare una chiave univoca per questi campi.
A differenza delle chiavi primarie, è possibile definire più chiavi secondarie univoche su una tabella.
C'è sempre una chiave secondaria univoca nel campo SystemId.
Chiavi secondarie con campi inclusi
Con le chiavi secondarie non cluster, è possibile usare la proprietà IncludedFields per aggiungere campi che non fanno parte della chiave stessa. In SQL Server, questi campi non chiave corrispondono a ciò che viene chiamato colonne incluse. L'uso dei campi inclusi permette di creare indici che coprono più query e di ignorare il numero massimo di campi in una chiave.
Una chiave secondaria con campi inclusi può migliorare le prestazioni delle query SQL, soprattutto quando l'indice SQL contiene tutte le colonne della query, come colonne chiave o come colonne incluse. Il miglioramento delle prestazioni è dovuto al fatto che Query Optimizer è in grado di individuare tutti i valori di colonna all'interno dell'indice. Inoltre, non accede ai dati della tabella o dell'indice cluster, il che si traduce in un minor numero di operazioni di I/O del disco. Per ulteriori informazioni sulle colonne incluse in SQL, vedere Creazione di indici con colonne incluse.
Chiavi columnstore non cluster
Le tabelle supportano gli indici columnstore non cluster (a volte indicati come NCCI).
Con la proprietà ColumnStoreIndex si crea un indice columnstore non cluster nella tabella in SQL Server. L'uso di una chiave columnstore non cluster può migliorare le prestazioni delle query quando si eseguono analisi su tabelle di grandi dimensioni. Questo tipo di indice usa l'archiviazione dei dati basata su colonne e l'elaborazione delle query per ottenere prestazioni fino a 10 volte superiori nelle query analitiche rispetto alla tradizionale archiviazione orientata alle righe. È anche possibile ottenere un livello di compressione dei dati fino a 10 volte superiore rispetto alla dimensione dei dati non compressi nelle tabelle normali.
È possibile usare un indice columnstore non cluster per eseguire in modo efficiente analisi operative in tempo reale sul database di Business Central senza la necessità di definire gli indici SIFT in anticipo (e senza i problemi di blocco che gli indici SIFT a volte impongono al sistema). In ogni occasione in cui normalmente si aggiungerebbe una chiave SIFT sui campi per eseguire operazioni di somma/conteggio, usare invece una chiave columnstore non cluster per aggiungere tutti i campi all'indice.
Per meglio chiarire questo concetto, ecco un semplice esempio di sostituzione di due chiavi SIFT con un singolo indice columnstore non cluster. Si supponga di avere già implementato due chiavi SIFT:
Chiave1: "WareHouseId, Color" SumField: "OnStock"
Chiave2: "WareHouseId, ItemId, Size" SumField: "OnStock"
Con un indice columnstore non cluster, si potrebbe avere un solo indice definito come: ColumnStoreIndex = WareHouseId,Color,ItemId,Size,OnStock
Chiavi cluster e non cluster
Una definizione di chiave include la proprietà Clustered usata per creare un indice cluster. Un indice cluster determina l'ordine fisico in cui i record vengono archiviati nella tabella. In base al valore della chiave, i record vengono disposti in ordine crescente. L'uso di una chiave cluster può accelerare il recupero dei record.
Può essere presente un solo indice cluster per tabella. Per impostazione predefinita, la chiave primaria è configurata come chiave cluster.
In che modo le chiavi influiscono sulle prestazioni
La ricerca di dati specifici è più semplice se si definiscono e gestiscono più chiavi per la tabella che contiene i dati desiderati. Gli indici per ciascuna chiave forniscono viste specifiche che permettono ricerche rapide e flessibili. L'uso di un numero elevato di chiavi porta con sé vantaggi e svantaggi.
Decidere quante chiavi usare, se molte o poche, non è facile. Le chiavi appropriate e il numero di chiavi attive da usare sono un compromesso tra la massimizzazione della velocità di recupero dei dati e gli aggiornamenti dei dati (operazioni di inserimento, eliminazione o modifica dei dati). In generale, può essere utile disattivare le chiavi complesse se vengono usate raramente.
La velocità complessiva dipende dai seguenti fattori:
Dimensioni del database.
Numero di chiavi attive.
Complessità delle chiavi.
Numero di record nelle tabelle.
Velocità del computer e del disco rigido.
Gli indici sono una funzionalità efficace nei database relazionali, come SQL, per accelerare il processo di ricerca dei dati. L'indicizzazione dei dati necessari frequentemente consente di ottimizzare le prestazioni generali dell'applicazione. Ad esempio, se è necessario visualizzare alcune informazioni nell'applicazione, per completare la richiesta viene eseguita in background una query di database che cerca in ogni record finché non trova le informazioni richieste. Questo processo di ricerca delle informazioni richiede molto tempo e rallenta le prestazioni dell'applicazione. Viceversa, se si indicizzano i dati, ad esempio le colonne a cui si fa riferimento più spesso, il database andrà direttamente a tali colonne anziché cercare in tutti i record della tabella. Ciò aumenterà in modo significativo l'efficienza e le prestazioni generali dell'applicazione.
Quando si esegue una query di database, Query Optimizer (un componente importante del database) analizza e sceglie il miglior piano possibile per completare l'istruzione. Contemporaneamente fornisce informazioni supplementari sull'operazione in corso relativamente al possibile miglioramento delle prestazioni in caso di indicizzazione di specifiche colonne. Query Optimizer di SQL Server ottiene queste informazioni da DMV (Dynamic Management View), in questo caso, sys.dm_db_missing_index_details. Restituisce dettagli sugli indici mancanti per consentire di creare gli indici giusti.
Per ottenere informazioni sugli indici mancanti, andare a Indici mancanti nel database in Business Central e consultare i dati nelle colonne seguenti:
Nome tabella: il nome della tabella su cui si basano le colonne suggerite.
ID estensione: l'ID dell'applicazione a cui sono correlati i dati.
Indice con colonne di uguaglianza: i dati in queste colonne si basano sulle query di uguaglianza. Ad esempio,
Select * from customer where id = 021.Indice con colonne di disuguaglianza: i dati in queste colonne provengono dalle query, le quali non si basano su operazioni di uguaglianza. Ad esempio,
Select * from customer where id < 200.Indice con colonne di inclusione: queste colonne contengono una copia dei dati associati per il recupero rapido delle informazioni, basati sulle colonne suggerite in Indice con colonne di uguaglianza e Indice con colonne di disuguaglianza. Le colonne di inclusione non sono colonne indicizzate, ma puntano alle informazioni supplementari collegate alle colonne indicizzate. Ad esempio, includono i campi nella parte Seleziona.

Le informazioni fornite nella pagina Indici mancanti nel database sono suggerimenti e non devono essere considerate come azioni obbligatorie. È necessario considerare quanti indici implementare e dove per ottenere prestazioni ottimali dell'applicazione. Gli indici occupano spazio di archiviazione e possono influire sugli aggiornamenti delle tabelle in cui inserimenti ed eliminazioni sono frequenti, pertanto possono avere un notevole impatto se impiegati eccessivamente.
Limitazioni e restrizioni
Sono presenti alcune limitazioni e restrizioni da tenere presenti in merito alle chiavi.
Chiavi negli oggetti estensione tabella
Negli oggetti estensione tabella è possibile definire più chiavi, proprio come in un oggetto tabella. Tuttavia, si applicano le seguenti limitazioni:
In Business Central 2020 ciclo di rilascio 2 e versioni precedenti, le chiavi negli oggetti estensione tabella possono includere solo i campi dell'oggetto estensione tabella stesso.
In Business Central 2021 ciclo di rilascio 1 e versioni successive, le chiavi negli oggetti estensione tabella possono includere i campi dell'oggetto tabella di base ed estensione tabella. Tuttavia, una singola chiave non può includere campi sia dall'oggetto di tabella di base sia dall'oggetto di estensione di tabella. In altre parole, ogni chiave deve contenere campi dell'oggetto di tabella di base o dell'oggetto di estensione di tabella.
È possibile usare lo stesso nome della chiave nell'estensione della tabella, a meno che la chiave non contenga campi dell'oggetto tabella di base.
Numero totale di chiavi
È possibile associare fino a 40 chiavi a una tabella.
Modifiche delle chiavi
Quando si sviluppa una nuova versione di un'estensione, tenere presente le seguenti restrizioni per evitare errori di sincronizzazione dello schema che impediscono la pubblicazione della nuova versione:
Non eliminare le chiavi primarie.
Non aggiungere o rimuovere i campi della chiave primaria né modificarne l'ordine.
Non modificare le proprietà delle chiavi primarie esistenti.
Non aggiungere più chiavi univoche.
Non aggiungere più chiavi cluster.
Non aggiungere chiavi che sono campi della tabella di base.