Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo descrive l'oggetto di sincronizzazione della recinzione GPU che può essere usato per la sincronizzazione da GPU a GPU nella fase 2 di pianificazione hardware GPU. Questa funzionalità è supportata a partire da Windows 11 versione 24H2 (WDDM 3.2). Gli sviluppatori di driver grafici devono avere familiarità con WDDM 2.0 e la fase di pianificazione hardware GPU 1.
Oggetto di sincronizzazione del recinto monitorato di WDDM 2.x
L'oggetto di sincronizzazione del recinto monitorato di WDDM 2.x supporta le operazioni seguenti:
- La CPU attende un valore di recinto monitorato, in base a:
- Polling con un indirizzo virtuale della CPU (VA).
- Accodamento di un'attesa di blocco all'interno di Dxgkrnl che viene segnalato quando la CPU osserva il nuovo valore di recinto monitorato.
- Segnale CPU di un valore monitorato.
- Segnale GPU di un valore monitorato scrivendo nel va va della GPU monitorata e generando un interrupt segnalato monitorato per notificare alla CPU l'aggiornamento del valore.
Ciò che non era supportato era un'attesa nativa nella GPU per un valore di limite monitorato. Il sistema operativo ha invece mantenuto il lavoro della GPU che dipende dal valore in attesa della CPU. Questa operazione è stata rilasciata solo alla GPU quando il valore viene segnalato.
Aggiunta dell'oggetto di sincronizzazione della recinzione nativa GPU
A partire da WDDM 3.2, l'oggetto recinto monitorato è stato esteso per supportare le funzionalità aggiunte seguenti:
- Attesa GPU su un valore di limite monitorato, che consente la sincronizzazione da motore a motore ad alte prestazioni senza richiedere un round trip della CPU.
- Notifica di interrupt condizionale solo per i segnali di isolamento GPU con camerieri CPU. Questa funzionalità consente un notevole risparmio di energia consentendo alla CPU di entrare in uno stato di basso consumo quando tutto il lavoro GPU viene accodato.
- Isolamento dell'archiviazione dei valori nella memoria locale della GPU (anziché nella memoria di sistema).
Progettazione di oggetti di sincronizzazione della recinzione nativa GPU
Il diagramma seguente illustra l'architettura di base di un oggetto recinto nativo gpu, con particolare attenzione allo stato dell'oggetto di sincronizzazione condiviso tra la CPU e la GPU.
: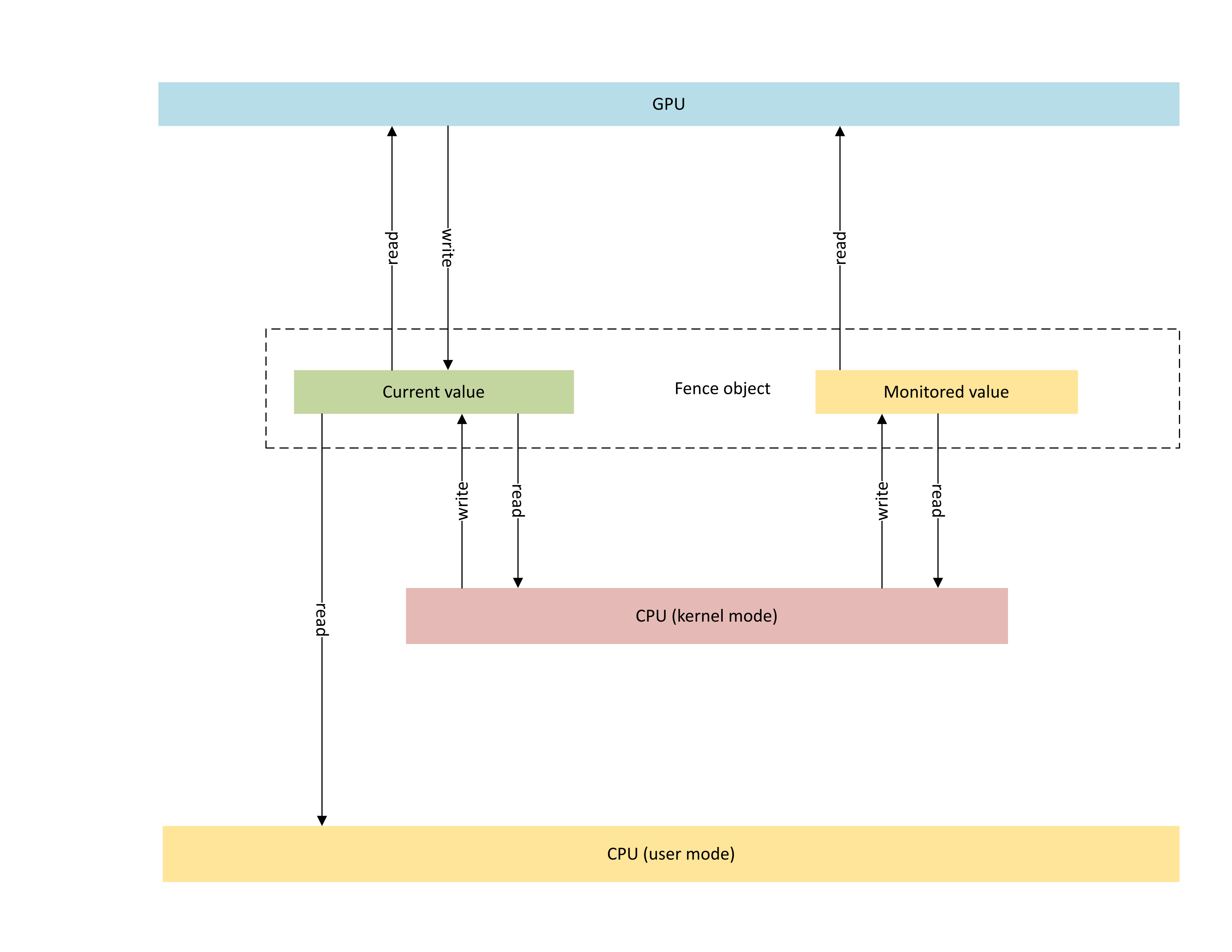
Il diagramma include due componenti principali:
Valore corrente (denominato CurrentValue in questo articolo). Questa posizione di memoria contiene il valore di limite a 64 bit attualmente segnalato. CurrentValue è mappato e accessibile sia alla CPU (scrivibile dalla modalità kernel, leggibile sia dall'utente che dalla modalità kernel) e dalla GPU (leggibile e scrivibile usando l'indirizzo virtuale GPU). CurrentValue richiede che le scritture a 64 bit siano atomice sia dalla CPU che dal punto di vista della GPU. Ovvero, gli aggiornamenti ai 32 bit alti e bassi non possono essere strappati e dovrebbero essere visibili contemporaneamente. Questo concetto è già presente nell'oggetto recinto monitorato esistente.
Valore monitorato (denominato MonitoredValue in questo articolo). Questo percorso di memoria contiene il valore meno attualmente atteso dalla CPU sottratta da uno (1). MonitoredValue è mappato e accessibile sia alla CPU (leggibile e scrivibile dalla modalità kernel, senza accesso in modalità utente) che alla GPU (leggibile tramite GPU VA, senza accesso in scrittura). Il sistema operativo mantiene l'elenco dei camerieri cpu in sospeso per un determinato oggetto di isolamento e aggiorna MonitoredValue man mano che i camerieri vengono aggiunti e rimossi. Quando non sono presenti camerieri in sospeso, il valore viene impostato su UINT64_MAX. Questo concetto è nuovo per l'oggetto di sincronizzazione della recinzione nativa della GPU.
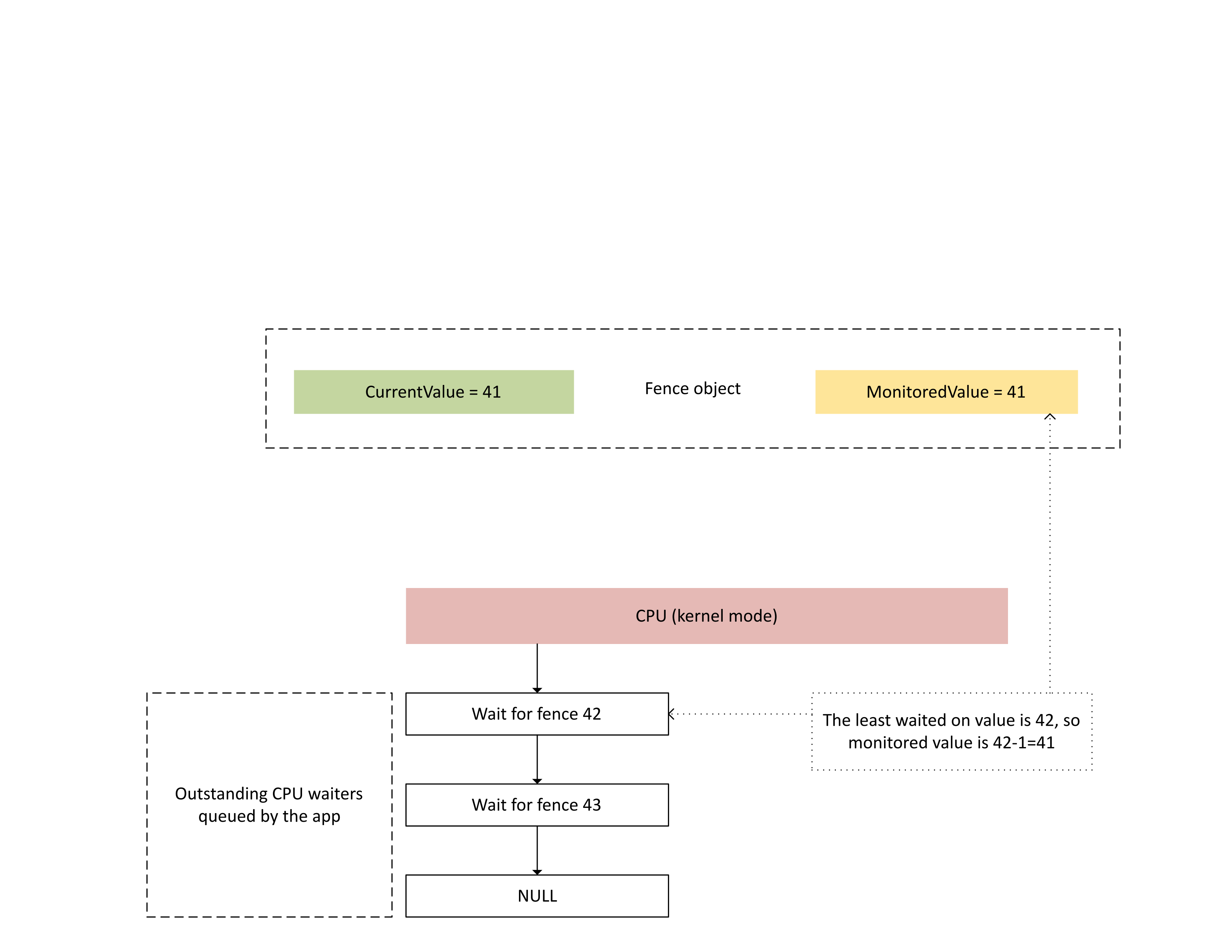
Il diagramma successivo illustra in che modo Dxgkrnl tiene traccia dei camerieri CPU in sospeso su un valore di recinto monitorato specifico. Mostra anche il valore di recinto monitorato impostato in un determinato momento. CurrentValue e MonitoredValue sono entrambi 41, il che significa che:
- La GPU ha completato tutte le attività fino al valore di recinto 41.
- La CPU non è in attesa di alcun valore di recinto minore o uguale a 41.
:
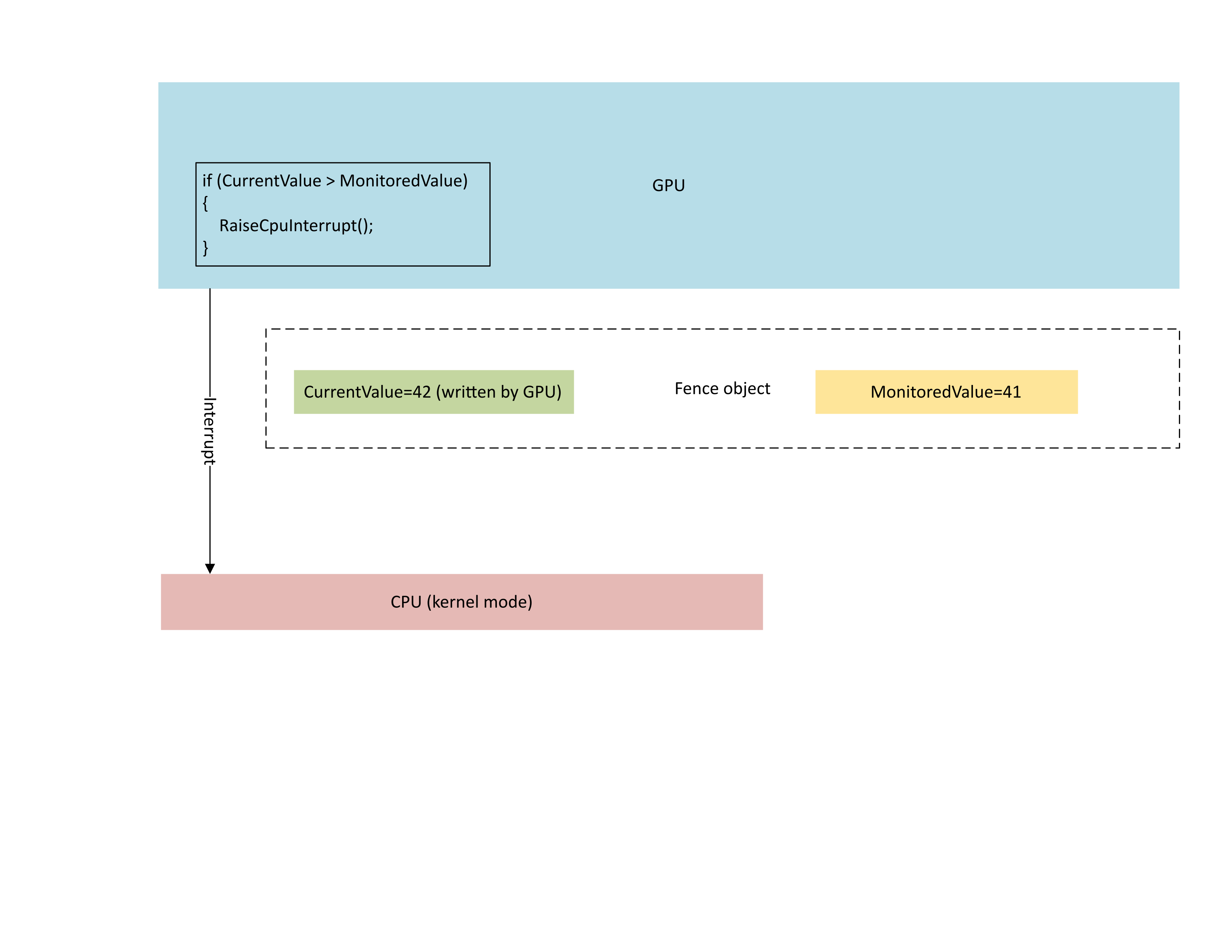
Il diagramma seguente illustra che il processore di gestione del contesto della GPU genera in modo condizionale un interrupt della CPU solo se il nuovo valore di limite è maggiore del valore monitorato. Un interrupt di questo tipo indica che ci sono camerieri CPU in sospeso che possono essere soddisfatti del valore appena scritto.
:
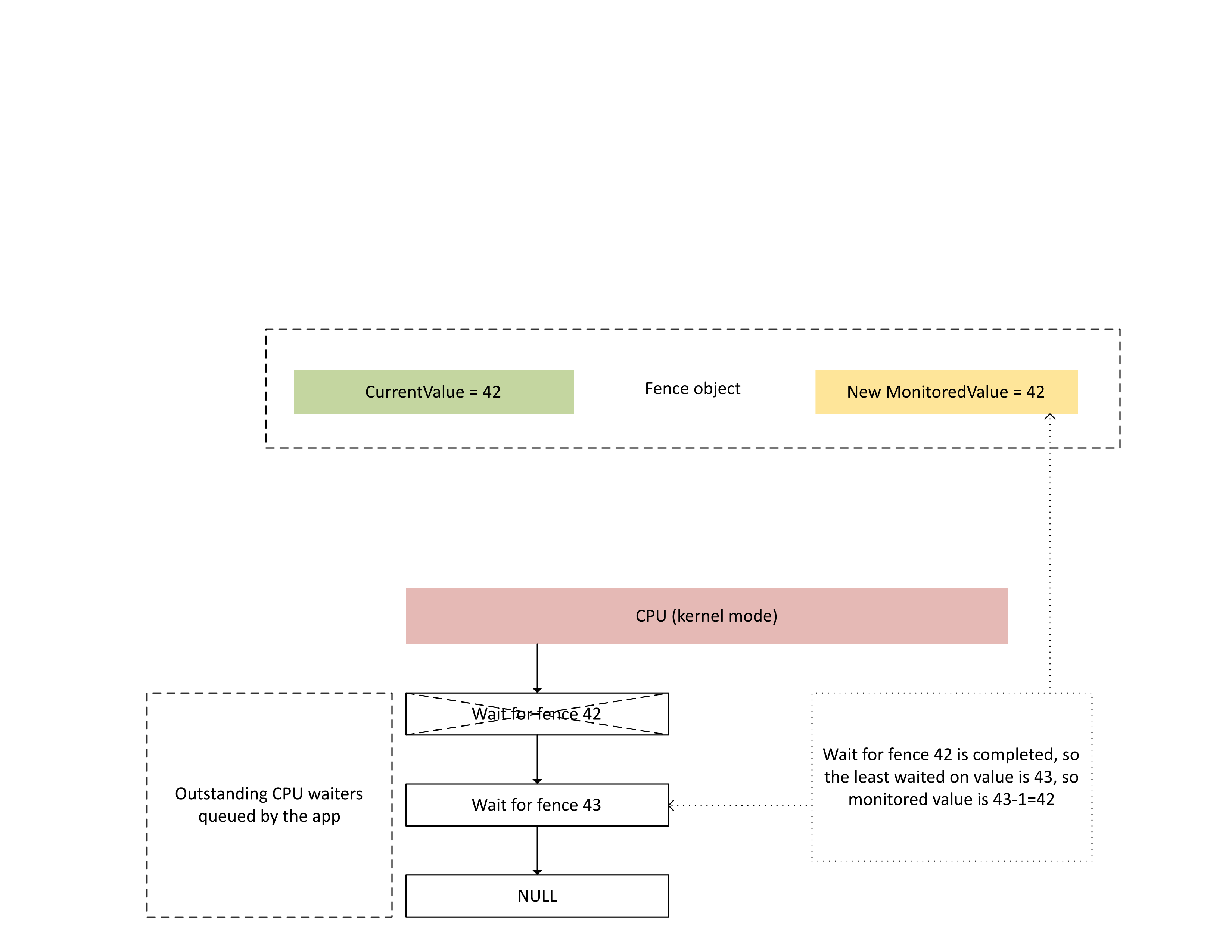
Quando la CPU elabora questo interrupt, Dxgkrnl esegue le azioni seguenti, come illustrato nel diagramma seguente:
- Sblocca i camerieri della CPU soddisfatti della nuova recinzione scritta.
- Fa avanzare il valore monitorato in modo che corrisponda al valore meno in sospeso sottratto da 1.
:
Archiviazione della memoria fisica per i valori limite correnti e monitorati
Per un determinato oggetto di isolamento, CurrentValue e MonitoredValue vengono archiviati in posizioni separate.
Gli oggetti recinto che non sono condivisibili hanno spazio di archiviazione dei valori di isolamento per oggetti recinto diversi all'interno dello stesso processo compresso nella stessa pagina di memoria. I valori vengono compressi in base ai valori stride specificati nei limiti di recinto kmD nativi descritti più avanti in questo articolo.
Gli oggetti recinto condivisibili hanno i valori correnti e monitorati inseriti nelle pagine di memoria che non sono condivise con altri oggetti recinto.
Valore corrente
Il valore corrente può risiedere nella memoria di sistema o nella memoria locale della GPU, a seconda del tipo di limite specificato da D3DDDI_NATIVEFENCE_TYPE.
Il valore corrente per le recinzioni tra adattatori è sempre in memoria di sistema.
Quando il valore corrente viene archiviato nella memoria di sistema, l'archiviazione viene allocata dal pool di memoria di sistema interno.
Quando il valore corrente viene archiviato nella memoria locale, l'archiviazione viene allocata dai segmenti di memoria specificati nel driver in D3DKMDT_FENCESTORAGESURFACEDATA.
Valore monitorato
Il valore monitorato può risiedere anche nella memoria locale del sistema o della GPU, a seconda di D3DDDI_NATIVEFENCE_TYPE.
Quando il valore monitorato viene archiviato nella memoria di sistema, il sistema operativo alloca l'archiviazione dal pool di memoria di sistema interno.
Quando il valore monitorato viene archiviato nella memoria locale, il sistema operativo alloca l'archiviazione dai segmenti di memoria specificati nel driver specificato in D3DKMDT_FENCESTORAGESURFACEDATA.
Quando le condizioni di attesa della CPU del sistema operativo cambiano, chiama il callback DxgkDdiUpdateMonitoredValues di KMD per indicare al KMD di aggiornare il valore monitorato a un valore specificato.
Errori di sincronizzazione
Il meccanismo descritto in precedenza ha una race condition intrinseca tra le letture della CPU e la GPU e le scritture del valore corrente e del valore monitorato. Se non viene eseguita particolare attenzione, potrebbero verificarsi i problemi seguenti:
- La GPU potrebbe leggere un oggetto MonitoredValue non aggiornato e non generare un interrupt come previsto dalla CPU.
- Un motore GPU potrebbe scrivere un currentValue più recente mentre il CMP è al centro della decisione della condizione di interrupt. Questo currentValue più recente potrebbe non generare l'interrupt come previsto o potrebbe non essere visibile alla CPU durante il recupero del valore corrente.
Sincronizzazione all'interno della GPU tra il motore e CMP
Per un'efficienza, molte GPU discrete implementano la semantica del segnale di isolamento monitorato usando lo stato shadow che risiede nella memoria locale della GPU tra:
Il motore GPU che esegue il flusso del buffer dei comandi e genera in modo condizionale un segnale hardware al CMP.
CMP GPU che decide se deve essere generato un interrupt della CPU.
In questo caso, il CMP deve sincronizzare l'accesso alla memoria con il motore GPU che esegue la scrittura di memoria nel valore di isolamento. In particolare, l'operazione di aggiornamento di un oggetto Shadow MonitoredValue deve essere ordinata dal punto di vista CMP:
- Scrivere un nuovo oggetto MonitoredValue (archiviazione GPU shadow).
- Eseguire una barriera di memoria per sincronizzare l'accesso alla memoria con il motore GPU.
- Read CurrentValue:
- Se CurrentValue MonitoredValue>, generare un interrupt della CPU.
- Se CurrentValue<= MonitoredValue, non generare l'interrupt della CPU.
Per risolvere correttamente questa race condition, è fondamentale che la barriera di memoria nel passaggio 2 funzioni correttamente. Non deve essere presente un'operazione di scrittura di memoria in sospeso in CurrentValue nel passaggio 3 che ha avuto origine da un comando che non ha visto l'aggiornamento MonitoredValue nel passaggio 1. Questa situazione genera un interrupt se la recinzione scritta nel passaggio 3 è maggiore del valore aggiornato nel passaggio 1.
Sincronizzazione tra GPU e CPU
La CPU deve eseguire gli aggiornamenti di MonitoredValue e le letture di CurrentValue in modo da non perdere la notifica di interrupt per i segnali in anteprima.
- Il sistema operativo deve modificare MonitoredValue quando viene aggiunto un nuovo waiter CPU al sistema o se un cameriere CPU esistente viene ritirato.
- Il sistema operativo chiama DxgkDdiUpdateMonitoredValues per notificare alla GPU un nuovo valore monitorato.
- DxgkDdiUpdateMonitoredValue viene eseguito a livello di interrupt del dispositivo ed è quindi sincronizzato con la routine del servizio di interruzione segnalata monitorata (ISR).
- DxgkDdiUpdateMonitoredValue deve garantire che, dopo la restituzione, currentValueletto da qualsiasi core del processore sia stato scritto dal CMP GPU dopo aver osservato il nuovo MonitoredValue.
- Al ritorno da DxgkDdiUpdateMonitoredValue, il sistema operativo ricampiona CurrentValue e soddisfa tutti i camerieri sbloccati dal nuovo CurrentValue.
È perfettamente accettabile che la CPU osservi un CurrentValue più recente di quello usato dalla GPU per decidere se generare l'interrupt. Questa situazione comporta occasionalmente una notifica di interruzione che non sblocca alcun cameriere. Ciò che non è accettabile è che la CPU non riceva una notifica di interruzione per l'aggiornamento CurrentValue più recente monitorato (>
Abilitazione della funzionalità di isolamento nativo per l'esecuzione di query nel sistema operativo
I driver devono verificare se la funzionalità di isolamento nativo è abilitata nel sistema operativo durante l'inizializzazione del driver. A partire da WDDM 3.2, il sistema operativo usa l'interfaccia IsFeatureEnabled aggiunta per controllare se alcune funzionalità sono abilitate, inclusa la funzionalità di isolamento nativo.
Di conseguenza, kmd deve implementare l'interfaccia IsFeatureEnabled . L'implementazione del kmD deve eseguire una query per verificare se il sistema operativo ha abilitato la funzionalità di DXGK_FEATURE_NATIVE_FENCE prima del supporto per la recinzione nativa della pubblicità in DXGK_VIDSCHCAPS. L'inizializzazione dell'adattatore non riesce se kmd annuncia il supporto nativo per il recinto quando il sistema operativo non ha abilitato la funzionalità.
Per altre informazioni sull'interfaccia di abilitazione delle funzionalità, vedere Esecuzione di query sul supporto e l'abilitazione delle funzionalità WDDM.
Query DDIs per l'abilitazione della funzione di fence nativa.
Le interfacce seguenti vengono introdotte per un kmD per eseguire una query se il sistema operativo ha abilitato la funzionalità di isolamento nativo:
- DXGKCB_FEATURE_NATIVEFENCE_CAPS_1
- DXGKARGCB_FEATURE_NATIVEFENCE_CAPS_1
- DXGKCBINT_FEATURE_NATIVEFENCE_1
Il sistema operativo implementa la tabella dell'interfaccia DXGKCB_FEATURE_NATIVEFENCE_CAPS_1 aggiunta dedicata alla versione 1 di DXGK_FEATURE_NATIVE_FENCE. Il KmD deve eseguire una query su questa tabella dell'interfaccia delle funzionalità per determinare le funzionalità del sistema operativo. Nelle versioni future del sistema operativo, il sistema operativo potrebbe introdurre versioni future di questa tabella di interfaccia, con il supporto dettagliato per le nuove funzionalità.
Codice del driver di esempio per l'esecuzione di query sul supporto
Il codice di esempio seguente illustra in che modo i driver devono usare la funzionalità DXGK_FEATURE_NATIVE_FENCE nell'interfaccia DXGK_FEATURE_INTERFACE per il supporto delle query.
DXGK_FEATURE_INTERFACE FeatureInterface;
struct FEATURE_RESULT
{
bool Enabled;
DXGK_FEATURE_VERSION Version;
};
// Driver internal cache for state & version of queried features
struct FEATURE_STATE
{
struct
{
UINT NativeFenceEnabled : 1;
};
DXGK_FEATURE_VERSION NativeFenceVersion = 0;
// Interfaces
DXGKCBINT_FEATURE_NATIVEFENCE_1 NativeFenceInterface = {};
// Interface queried values
DXGKARGCB_FEATURE_NATIVEFENCE_CAPS_1 NativeFenceOSCaps1 = {};
};
// Helper function to query OS's feature enabled interface
FEATURE_RESULT IsFeatureEnabled(
DXGK_FEATURE_ID FeatureId
)
{
FEATURE_RESULT Result = {};
//
// If the feature interface functionality is available (e.g. supported by the OS)
//
DXGKARGCB_ISFEATUREENABLED2 Args = {};
Args.FeatureId = FeatureId;
if(NT_SUCCESS(FeatureInterface.IsFeatureEnabled(DxgkInterface.DeviceHandle, &Args)))
{
Result.Enabled = Args.Result.Enabled;
Result.Version = Args.Result.Version;
}
return Result;
}
// Actual code to query whether OS has enabled Native Fence support and corresponding OS caps
FEATURE_RESULT FeatureResult = IsFeatureEnabled(DXGK_FEATURE_NATIVE_FENCE);
FEATURE_STATE FeatureState = {};
FeatureState.NativeFenceEnabled = !!FeatureResult.Enabled;
if (FeatureResult.Enabled)
{
// Query OS caps for native fence feature, using the feature interface
DXGKARGCB_QUERYFEATUREINTERFACE QFIArgs = {};
QFIArgs.FeatureId = DXGK_FEATURE_NATIVE_FENCE;
QFIArgs.Interface = &FeatureState.NativeFenceInterface;
QFIArgs.InterfaceSize = sizeof(FeatureState.NativeFenceInterface);
QFIArgs.Version = FeatureResult.Version;
Status = FeatureInterface.QueryFeatureInterface(DxgkInterface.DeviceHandle, &QFIArgs);
if(NT_SUCCESS(Status))
{
FeatureState.NativeFenceVersion = FeatureResult.Version;
Status = FeatureState.NativeFenceInterface.GetOSCaps(&FeatureState.NativeFenceOSCaps1);
NT_ASSERT(NT_SUCCESS(Status));
}
else
{
// We should always succeed getting an interface from a successfully
// negotiated feature + version.
NT_ASSERT(FALSE);
}
}
Funzionalità di isolamento nativo
Le interfacce seguenti vengono aggiornate o introdotte per eseguire query sui limiti di isolamento nativi:
Il campo NativeGpuFence viene aggiunto a DXGK_VIDSCHCAPS. Se il sistema operativo ha abilitato la funzionalità di DXGK_FEATURE_NATIVE_FENCE, il driver può dichiarare il supporto per la funzionalità di isolamento GPU nativa durante l'inizializzazione dell'adattatore impostando il bit DXGK_VIDSCHCAPS::NativeGpuFence su 1.
DXGKQAITYPE_NATIVE_FENCE_CAPS viene aggiunto a DXGK_QUERYADAPTERINFOTYPE.
Dxgkrnl espone questa funzionalità alla modalità utente tramite l'aggiunta della struttura/bit corrispondente D3DKMT_WDDM_3_1_CAPS::NativeGpuFenceSupported .
KMTQAITYPE_WDDM_3_1_CAPS viene aggiunto a KMTQUERYADAPTERINFOTYPE.
Le entità seguenti vengono aggiunte per un kmD per indicare le funzionalità di supporto per la funzionalità di isolamento GPU nativa.
La struttura DXGK_NATIVE_FENCE_CAPS descrive le funzionalità di isolamento nativo della GPU. Quando kmd imposta il bit MapToGpuSystemProcess di questa struttura, indica al sistema operativo di riservare uno spazio di indirizzi virtuale GPU del processo di sistema per l'uso CMP e di creare mapping di VA GPU in tale spazio di indirizzi per il limite nativo CurrentValue e MonitoredValue. Queste VA GPU vengono successivamente passate al callback di creazione del recinto kmD come DXGKARG_CREATENATIVEFENCE::CurrentValueSystemProcessGpuVa e MonitoredValueSystemProcessGpuVa.
KMD restituisce la struttura DXGK_NATIVE_FENCE_CAPS popolata quando viene chiamata la funzione DxgkDdiQueryAdapterInfo con il tipo di informazioni dell'adattatore query aggiunto DXGKQAITYPE_NATIVE_FENCE_CAPS.
DDD kmd per creare, aprire, chiudere e distruggere un oggetto di isolamento nativo
Vengono introdotte le DDI implementate dal KMD per creare, aprire, chiudere ed eliminare un oggetto di isolamento nativo. Dxgkrnl chiama queste DDI per conto dei componenti in modalità utente. Dxgkrnl li chiama solo se il sistema operativo ha abilitato la funzionalità di DXGK_FEATURE_NATIVE_FENCE .
- DxgkDdiCreateNativeFence/DXGKARG_CREATENATIVEFENCE
- DxgkDdiOpenNativeFence/DXGKARG_OPENNATIVEFENCE
- DxgkDdiCloseNativeFence/DXGKARG_CLOSENATIVEFENCE
- DxgkDdiDestroyNativeFence/DXGKARG_DESTROYNATIVEFENCE
Le DDI seguenti sono state aggiornate per supportare oggetti di isolamento nativi:
I membri seguenti sono stati aggiunti a DRIVER_INITIALIZATION_DATA. I driver che supportano oggetti di isolamento GPU nativi devono implementare le funzioni e fornire a Dxgkrnl puntatori tramite questa struttura.
- PDXGKDDI_CREATENATIVEFENCE DxgkDdiCreateNativeFence (aggiunta in WDDM 3.1)
- PDXGKDDI_DESTROYNATIVEFENCE DxgkDdiDestroyNativeFence (aggiunta in WDDM 3.1)
- PDXGKDDI_OPENNATIVEFENCE DxgkDdiCreateNativeFence (aggiunta in WDDM 3.2)
- PDXGKDDI_CLOSENATIVEFENCE DxgkDdiCloseNativeFence (aggiunta in WDDM 3.2)
- PDXGKDDI_SETNATIVEFENCELOGBUFFER DxgkDdiSetNativeFenceLogBuffer (aggiunta in WDDM 3.2)
- PDXGKDDI_UPDATENATIVEFENCELOGS DxgkDdiUpdateNativeFenceLogs (aggiunta in WDDM 3.2)
Handle globali e locali per recinzioni condivise
Si supponga che il processo A crei un recinto nativo condiviso e che il processo B in un secondo momento apre questa recinzione.
Quando il processo A crea la recinzione nativa condivisa, Dxgkrnl chiama DxgkDdiCreateNativeFence con l'handle del driver dell'adattatore su cui viene creato questo recinto. L'handle di recinzione creato e restituito in hGlobalNativeFence è l'handle di isolamento globale.
Dxgkrnl segue successivamente una chiamata a DxgkDdiOpenNativeFence per aprire un handle locale specifico di A (hLocalNativeFenceA).
Quando il processo B apre la stessa recinzione nativa condivisa, Dxgkrnl chiama DxgkDdiOpenNativeFence per aprire un handle locale specifico del processo B (hLocalNativeFenceB).
Se il processo A distrugge l'istanza di recinto nativo condiviso, Dxgkrnl rileva che esiste ancora un riferimento in sospeso a questa recinzione globale, quindi chiama solo DxgkDdiCloseNativeFence(hLocalNativeFenceA) per il driver per pulire le strutture specifiche di A. L'handle hGlobalNativeFence esiste ancora.
Quando il processo B distrugge l'istanza di recinto, Dxgkrnl chiama DxgkDdiCloseNativeFence(hLocalNativeFenceB) e poi DxgkDdiDestroyNativeFence(hGlobalNativeFence) per consentire al KMD di distruggere i dati di isolamento globale.
Mapping di va GPU nello spazio indirizzi del processo di paging per l'uso CMP
Il KMD imposta il limite DXGK_NATIVE_FENCE_CAPS::MapToGpuSystemProcess sull'hardware che richiede il mapping delle VA GPU native allo spazio indirizzi del processo di paging GPU. Un bit MapToGpuSystemProcess impostato indica al sistema operativo di creare mapping di va GPU nello spazio di indirizzi del processo di paging per currentValue e MonitoredValue del recinto nativo per l'uso da parte del CMP. Queste VA GPU vengono successivamente passate a DxgkDdiCreateNativeFence come DXGKARG_CREATENATIVEFENCE::CurrentValueSystemProcessGpuVa e MonitoredValueSystemProcessGpuVa.
API del kernel D3DKMT per creare, aprire ed eliminare barriere native
Vengono introdotte le API D3DKMT in modalità kernel seguenti per creare e aprire un oggetto di isolamento nativo.
- D3DKMTCreateNativeFence / D3DKMT_CREATENATIVEFENCE
- D3DKMTOpenNativeFenceFromNTHandle / D3DKMT_OPENNATIVEFENCEFROMNTHANDLE
Dxgkrnl chiama la funzione D3DKMTDestroySynchronizationObject esistente per chiudere e distruggere (libero) un oggetto recinto nativo esistente.
Le strutture di supporto e le enumerazioni introdotte o aggiornate includono:
- D3DDDI_NATIVEFENCEINFO
- D3DDDI_NATIVEFENCE_TYPE
- D3DDDI_SYNCHRONIZATIONOBJECT_FLAGS
- D3DDDI_NATIVEFENCE_MAPPING
DDI per supportare il posizionamento dei valori di recinto nativo nella memoria locale
Le DDI seguenti sono state aggiunte o modificate per supportare il posizionamento dei valori di recinto nativo nella memoria locale:
Viene aggiunta la struttura D3DKMDT_FENCESTORAGESURFACEDATA.
La recinzione nativa MonitoredValue e CurrentValue del tipo di recinto nativo D3DDDI_NATIVEFENCE_TYPE_INTRA_GPU possono essere posizionati nella memoria del dispositivo locale. A tale scopo, il sistema operativo chiederà al driver di specificare i segmenti di memoria in cui deve essere posizionata l'archiviazione di isolamento. DxgkDdiGetStandardAllocation viene esteso per fornire tali informazioni.
D3DKMDT_STANDARDALLOCATION_FENCESTORAGE viene aggiunto a DXGKARG_GETSTANDARDALLOCATIONDRIVERDATA.
Indica un limite di avanzamento nativo per le code hardware
L'aggiornamento seguente viene introdotto per indicare un oggetto limite di stato della coda hardware nativo:
Viene aggiunto un flag NativeProgressFence per le chiamate a DxgkDdiCreateHwQueue.
- Nei sistemi supportati, il sistema operativo aggiorna lo stato di avanzamento della coda hardware in un recinto nativo. Quando il sistema operativo imposta NativeProgressFence, indica al KMD che l'handle DXGKARG_CREATEHWQUEUE::hHwQueueProgressFence punta all'handle driver di un oggetto di recinto GPU nativo creato in precedenza usando DxgkDdiCreateNativeFence.
Interruzione segnalata del recinto nativo
Le modifiche seguenti vengono apportate al meccanismo di interrupt per supportare un interrupt segnalato da un recinto nativo:
L'enumerazione DXGK_INTERRUPT_TYPE viene aggiornata in modo da avere un tipo di interrupt DXGK_INTERRUPT_NATIVE_FENCE_SIGNALED .
La struttura DXGKARGCB_NOTIFY_INTERRUPT_DATA viene aggiornata per includere una struttura NativeFenceSignaled per indicare un interrupt segnalato da un recinto nativo
NativeFenceSignaled viene usato per informare il sistema operativo che un set di oggetti GPU di isolamento nativi monitorati dalla CPU è stato segnalato su un motore GPU. Se la GPU è in grado di determinare il sottoinsieme esatto di oggetti con camerieri CPU attivi, passa questo subset tramite pSignaledNativeFenceArray. Gli handle in questa matrice devono essere handle hGlobalNativeFence validi passati a KMD in DxgkDdiCreateNativeFence. Il passaggio di un handle a un oggetto di isolamento nativo distrutto causa un controllo di bug.
La struttura DXGKCB_NOTIFY_INTERRUPT_DATA_FLAGS viene aggiornata per includere un membro EvaluateLegacyMonitoredFences .
La GPU può passare un valore NULL pSignaledNativeFenceArray nelle condizioni seguenti:
- La GPU non è in grado di determinare il sottoinsieme esatto di oggetti con camerieri della CPU attivi.
- Più interrupt di segnale vengono compressi insieme rendendo difficile determinare il set segnalato con i camerieri attivi.
Un valore NULL indica al sistema operativo di analizzare tutti i camerieri di oggetti di isolamento GPU nativi in sospeso.
Il contratto tra il sistema operativo e il driver è: se il sistema operativo ha un cameriere CPU attivo (come espresso da MonitoredValue) e il motore GPU ha segnalato l'oggetto al valore che richiede un interrupt della CPU, la GPU deve eseguire una delle azioni seguenti:
- Includere questo handle di isolamento nativo in pSignaledNativeFenceArray.
- Generare un interrupt NativeFenceSignaled con un valore NULL pSignaledNativeFenceArray.
Per impostazione predefinita, quando kmd genera questo interrupt con un valore NULL pSignaledNativeFenceArray, Dxgkrnl analizza solo tutti i camerieri di recinzione nativi in sospeso e non analizza i camerieri di recinzione monitorati legacy. Nell'hardware che non riesce a distinguere tra DXGK_INTERRUPT_MONITORED_FENCE_SIGNALED legacy e DXGK_INTERRUPT_NATIVE_FENCE_SIGNALED, il KMD può sempre generare solo l'interrupt DXGK_INTERRUPT_NATIVE_FENCE_SIGNALED introdotto con pSignaledNativeFenceArray = NULL e EvaluateLegacyMonitoredFences = 1, che indica al sistema operativo di analizzare tutti i camerieri (camerieri di isolamento monitorati legacy e camerieri di recinzione nativi).
Indica al KmD di aggiornare i batch di valori
Vengono introdotte le interfacce seguenti per indicare al KmD di aggiornare un batch di valori correnti o monitorati:
DxgkDdiUpdateCurrentValuesFromCpu / DXGKARG_UPDATECURRENTVALUESFROMCPU
DxgkDdiUpdateMonitoredValues / DXGKARG_UPDATEMONITOREDVALUES
Recinzioni native tra adattatori
Il sistema operativo deve supportare la creazione di recinzioni native tra schede perché le app DX12 esistenti creano e usano recinzioni monitorate tra schede. Se le code e la pianificazione sottostanti per queste app passano all'invio in modalità utente, i recinti monitorati devono anche essere passati a recinzioni native (le code in modalità utente non possono supportare recinzioni monitorate).
È necessario creare un recinto incrociato con tipo D3DDDI_NATIVEFENCE_TYPE_DEFAULT. In caso contrario, D3DKMTCreateNativeFence ha esito negativo.
Tutte le GPU condividono la stessa copia dell'archiviazione CurrentValue, che viene sempre allocata nella memoria di sistema. Quando il runtime crea un recinto nativo tra schede in GPU1 e lo apre in GPU2, i mapping della GPU va su entrambe le GPU puntano alla stessa risorsa di archiviazione fisica CurrentValue .
Ogni GPU ottiene la propria copia di MonitoredValue. Di conseguenza, l'archiviazione MonitoredValue può essere allocata nella memoria di sistema o nella memoria locale.
I recinti nativi tra schede devono risolvere la condizione in cui GPU1 è in attesa di un recinto nativo segnalato da GPU2. Oggi non esiste alcun concetto di segnali GPU-GPU; di conseguenza, il sistema operativo risolve in modo esplicito questa condizione segnalando GPU1 dalla CPU. Questa segnalazione viene eseguita impostando MonitoredValue per il limite di adattatori incrociati su 0 per la sua durata. Quindi, quando GPU2 segnala il limite nativo, genera anche un interrupt della CPU, consentendo a Dxgkrnl di aggiornare CurrentValue in GPU1 (usando DxgkDdiUpdateCurrentValuesFromCpu con il flag NotificationOnly impostato TRUE) e sbloccare eventuali camerieri CPU/GPU in sospeso di tale GPU.
Anche se MonitoredValue è sempre 0 per le barriere native tra schede, l'attesa e i segnali inviati sulla stessa GPU traggono comunque vantaggio da una sincronizzazione GPU più veloce. Tuttavia, il vantaggio di potenza delle interruzioni della CPU ridotte viene perso perché gli interrupt della CPU verranno generati in modo incondizionato, anche se non c'erano camerieri CPU o camerieri sull'altra GPU. Questo compromesso è fatto per mantenere semplice il costo di progettazione e implementazione del recinto nativo tra schede.
Il sistema operativo supporta lo scenario in cui viene creato un oggetto di isolamento nativo in GPU1 e aperto in GPU2, in cui GPU1 supporta la funzionalità e GPU2 non lo supporta. L'oggetto recinto viene aperto come normale MonitoredFence su GPU2.
Il sistema operativo supporta lo scenario in cui viene creato un normale oggetto recinto monitorato in GPU1 e aperto come recinto nativo in GPU2, che supporta la funzionalità. L'oggetto recinto viene aperto come recinto nativo in GPU2.
Combinazioni di attesa/segnale tra adattatori
Le tabelle nelle sottosezioni seguenti accettano un esempio di sistema iGPU e dGPU ed elencano le varie configurazioni possibili per l'attesa/segnale di isolamento nativo dalla CPU/GPU. Vengono presi in considerazione i due casi seguenti:
- Entrambe le GPU supportano recinzioni native.
- L'iGPU non supporta le recinzioni native, ma la dGPU supporta le recinzioni native.
Il secondo scenario è simile anche al caso in cui entrambe le GPU supportano i recinto nativi, ma l'attesa/segnale di isolamento nativo viene inviato a una coda in modalità kernel nell'iGPU.
Le tabelle devono essere lette selezionando una coppia di attese e segnali dalle colonne, ad esempio WaitFromGPU - SignalFromGPU o WaitFromGPU - SignalFromCPU, e così via.
Scenario 1
Nello scenario 1, sia dGPU che iGPU supportano recinzioni native.
| iGPU WaitFromGPU (hFence, 10) | iGPU WaitFromCPU (hFence, 10) | dGPU SignalFromGpu (hFence, 10) | dGPU SignalFromCpu(hFence, 10) |
|---|---|---|---|
| UMD inserisce un'attesa per il valore CurrentValue per l'hfence == 10 istruzioni nel buffer dei comandi | Chiamate di runtime D3DKMTWaitForSynchronizationObjectFromCpu | ||
| VidSch tiene traccia di questo oggetto di sincronizzazione nell'elenco dei camerieri CPU di isolamento nativo | |||
| UMD inserisce un valore CurrentValue di scrittura = 10 istruzioni di segnale nel buffer dei comandi | Il runtime chiama D3DKMTSignalSynchronizationObjectFromCpu | ||
| VidSch riceve un ISR segnalato in modo nativo quando CurrentValue viene scritto (perché MonitoredValue == 0 sempre) | VidSch chiama DxgkDdiUpdateCurrentValuesFromCpu(hFence, 10) | ||
| VidSch propaga il segnale (hFence, 10) all'iGPU | VidSch propaga il segnale (hFence, 10) a iGPU | ||
| VidSch riceve il segnale propagato e chiama DxgkDdiUpdateCurrentValuesFromCpu(hFence, NotificationOnly=TRUE) | VidSch riceve il segnale propagato e chiama DxgkDdiUpdateCurrentValuesFromCpu(hFence, NotificationOnly=TRUE) | ||
| KmD analizza nuovamente l'elenco di esecuzioni per sbloccare il canale HW in attesa su hFence | VidSch sblocca la condizione di attesa della CPU segnalando kevent |
Scenario 2a
Nello scenario 2a, l'iGPU non supporta le recinzioni native, ma la dGPU lo fa. Viene inviata un'attesa sull'iGPU e viene inviato un segnale sulla dGPU.
| iGPU WaitFromGPU (hFence, 10) | iGPU WaitFromCPU (hFence, 10) | dGPU SignalFromGpu (hFence, 10) | dGPU SignalFromCpu(hFence, 10) |
|---|---|---|---|
| Runtime chiama D3DKMTWaitForSynchronizationObjectFromGpu | Chiamate di runtime D3DKMTWaitForSynchronizationObjectFromCpu | ||
| VidSch tiene traccia di questo oggetto di sincronizzazione nell'elenco di attesa del recinto monitorato | VidSch tiene traccia di questo oggetto di sincronizzazione nella testa dell'elenco dei camerieri CPU monitorati | ||
| UMD inserisce un valore CurrentValue di scrittura = 10 istruzioni di segnale nel buffer dei comandi | Il runtime chiama D3DKMTSignalSynchronizationObjectFromCpu | ||
| VidSch riceve NativeFenceSignaledISR quando CurrentValue viene scritto (perché MV == 0 sempre) | VidSch chiama DxgkDdiUpdateCurrentValuesFromCpu(hFence, 10) | ||
| VidSch propaga il segnale (hFence, 10) a iGPU | VidSch propaga il segnale (hFence, 10) a iGPU | ||
| VidSch riceve il segnale propagato e osserva il nuovo valore di recinzione | VidSch riceve il segnale propagato e osserva il nuovo valore di recinzione | ||
| VidSch analizza la lista di attesa del recinto monitorato e sblocca i contesti software | VidSch analizza la testa dell'elenco dei camerieri DELLA CPU monitorati e sblocca l'attesa della CPU segnalando il KEVENT |
Scenario 2b
Nello scenario 2b il supporto per la recinzione nativa rimane invariato (iGPU non supporta dGPU). Questa volta, viene inviato un segnale sull'iGPU e viene inviata un'attesa sulla dGPU.
| iGPU SegnaleDaGPU (hFence, 10) | iGPU SignalFromCPU (hFence, 10) | dGPU WaitFromGpu (hFence, 10) | dGPU WaitFromCpu(hFence, 10) |
|---|---|---|---|
| UMD inserisce un'attesa per il valore CurrentValue dell'hfence == 10 istruzioni nel buffer dei comandi | Chiamate di runtime D3DKMTWaitForSynchronizationObjectFromCpu | ||
| VidSch tiene traccia di questo oggetto di sincronizzazione nell'elenco dei camerieri CPU di isolamento nativo | |||
| UMD chiama D3DKMTSignalSynchronizationObjectFromGpu | UMD chiama D3DKMTSignalSynchronizationObjectFromCpu | ||
| Quando il pacchetto si trova all'inizio del contesto software, VidSch aggiorna il valore di isolamento direttamente dalla CPU | VidSch aggiorna il valore di isolamento direttamente dalla CPU | ||
| VidSch propaga il segnale (hFence, 10) a dGPU | VidSch propaga il segnale (hFence, 10) a dGPU | ||
| VidSch riceve il segnale propagato e chiama DxgkDdiUpdateCurrentValuesFromCpu(hFence, NotificationOnly=TRUE) | VidSch riceve il segnale propagato e chiama DxgkDdiUpdateCurrentValuesFromCpu(hFence, NotificationOnly=TRUE) | ||
| KmD analizza nuovamente l'elenco di esecuzioni per sbloccare il canale HW in attesa su hFence | VidSch sblocca la condizione di attesa della CPU segnalando kevent |
Segnale futuro da GPU a GPU a scheda incrociata
Come descritto in Problemi di sincronizzazione, per le recinzioni native tra schede, si perde il risparmio di energia perché un interrupt della CPU viene generato in modo incondizionato.
In una versione futura, il sistema operativo svilupperà un'infrastruttura per consentire a un segnale GPU su una GPU di interrompere altre GPU scrivendo in una memoria a campanella comune, consentendo ad altre GPU di riattivarsi, elaborare il proprio elenco di esecuzioni e sbloccare le code HW pronte.
La sfida per questo lavoro consiste nel progettare:
- Memoria comune del campanello.
- Payload intelligente o handle che una GPU può scrivere nel campanello che consente ad altre GPU di determinare quale limite è stato segnalato in modo da poter analizzare solo un subset di HWQueues.
Con un segnale di questo tipo di adattatore incrociato, potrebbe anche essere possibile che le GPU convidano la stessa copia dell'archiviazione di isolamento nativo (un'allocazione tra adattatori in formato lineare, simile alle allocazioni di analisi tra schede) da cui tutte le GPU leggono e scrivono.
Progettazione del buffer di log di isolamento nativo
Con recinzioni native e invio in modalità utente, Dxgkrnl non ha visibilità quando la GPU nativa attende e i segnali accodati da UMD vengono sbloccati sulla GPU per un determinato HWQueue. Con recinzioni native, un'interruzione segnalata monitorata potrebbe essere soppressa per una determinata recinzione.
:
È necessario un modo per ricreare le operazioni di isolamento, come illustrato in questa immagine GPUView . Le caselle rosa scure sono segnali e scatole rosa chiaro sono attese. Ogni casella inizia quando l'operazione è stata inviata sulla CPU a Dxgkrnl e termina quando Dxgkrnl completa l'operazione sulla CPU. In questo modo siamo in grado di studiare l'intera durata di un comando.
Pertanto, a livello generale, le condizioni per HWQueue necessarie per essere registrate sono:
| Condizione | significato |
|---|---|
| FENCE_WAIT_QUEUED | Timestamp CPU di quando UMD inserisce un'istruzione di attesa GPU nella coda dei comandi |
| FENCE_SIGNAL_QUEUED | Timestamp CPU di quando UMD inserisce un'istruzione del segnale GPU nella coda dei comandi |
| FENCE_SIGNAL_EXECUTED | Timestamp GPU di quando viene eseguito un comando di segnale sulla GPU per un HWQueue |
| FENCE_WAIT_UNBLOCKED | Timestamp GPU di quando una condizione di attesa viene soddisfatta nella GPU e HWQueue viene sbloccata |
DDI del buffer di log di isolamento nativo
Sono state introdotte le DDI, le strutture e le enumerazioni seguenti per supportare buffer di log di isolamento nativi:
- DxgkDdiSetNativeFenceLogBuffer / DXGKARG_SETNATIVEFENCELOGBUFFER
- DxgkDdiUpdateNativeFenceLogs / DXGKARG_UPDATENATIVEFENCELOGS
- Buffer di log che contiene un'intestazione e una matrice di voci di log. L'intestazione identifica se le voci sono per un'attesa o un segnale e ogni voce identifica il tipo di operazione (eseguito o sbloccato):
La progettazione del buffer di log è destinata alle code di invio native e in modalità utente in cui il payload del buffer di log viene scritto dal motore GPU/CMP, senza coinvolgimento da Dxgkrnl o KMD. Di conseguenza, UMD inserirà un'istruzione durante la generazione del buffer dei comandi wait/signal, programmando la GPU per scrivere il payload del buffer di log nella voce del buffer di log durante l'esecuzione. Per l'invio in modalità non utente (ovvero le code in modalità kernel), i segnali e l'attesa sono comandi software all'interno di Dxgkrnl, quindi conosciamo già i timestamp e altri dettagli di queste operazioni e non è necessario hardware/KMD per aggiornare il buffer di log. Per queste code in modalità kernel, Dxgkrnl non creerà un buffer di log.
Meccanismo del buffer dei log
Dxgkrnl alloca due buffer di log dedicati da 4 KB per HWQueue.
- Uno per le attese di registrazione.
- Uno per la registrazione dei segnali.
Questi buffer di log hanno mapping per lo spazio di indirizzi della CPU in modalità kernel (LogBufferCpuVa), una GPU VA nello spazio indirizzi del processo (LogBufferGpuVa) e CMP VA (LogBufferSystemProcessGpuVa), in modo che possano essere letti/scritti in KMD, il motore GPU e CMP. Dxgkrnl chiama DxgkDdiSetNativeFenceLogBuffer due volte: una volta per impostare il buffer di log per le attese di registrazione e una volta per impostare il buffer di log per i segnali di registrazione.
Subito dopo che UMD inserisce un'istruzione di attesa o segnale nativa nell'elenco dei comandi, inserisce anche un comando che indica alla GPU di scrivere un payload in una particolare voce nel buffer di log.
Dopo che il motore GPU esegue l'operazione di isolamento, vede l'istruzione UMD per scrivere un payload in una determinata voce nel buffer di log. Inoltre, la GPU scrive anche l'oggetto FenceEndGpuTimestamp corrente in questa voce del buffer di log.
Anche se il UMD non riesce ad accedere al buffer di log accessibile dalla GPU, controlla la progressione del buffer di log. Ovvero, UMD determina la prossima voce gratuita in cui scrivere, se presente, e programma la GPU con queste informazioni. Quando la GPU scrive nel buffer di log, incrementa il valore FirstFreeEntryIndex nell'intestazione del log. Il UMD deve garantire che le scritture nelle voci di log aumentino in modo monotonico.
Prendi in considerazione lo scenario seguente:
- Esistono due HWQueue, HWQueueA e HWQueueB, con buffer di log di isolamento corrispondenti con VA GPU di FenceLogA e FenceLogB. HWQueueA è associato al buffer di log per le attese di registrazione e HWQueueB è associato al buffer di log per i segnali di registrazione.
- Esiste un oggetto di isolamento nativo con un D3DKMT_HANDLE in modalità utente di FenceF.
- Un'attesa GPU su FenceF for Value V1 viene accodata a HWQueueA al momento di CPUT1. Quando UMD compila il buffer dei comandi, inserisce un comando che indica alla GPU di registrare il payload: LOG(FenceF, V1, DXGK_NATIVE_FENCE_LOG_OPERATION_WAIT_UNBLOCKED).
- Un segnale GPU a FenceF con Value V1 viene accodato a HWQueueB al momento della CPUT2. Quando UMD compila il buffer dei comandi, inserisce un comando che indica alla GPU di registrare il payload: LOG(FenceF, V1, DXGK_NATIVE_FENCE_LOG_OPERATION_SIGNAL_EXECUTED).
Dopo che l'utilità di pianificazione GPU esegue il segnale GPU in HWQueueB al momento della GPU GPUT1, legge il payload UMD e registra l'evento nel log di isolamento fornito dal sistema operativo per HWQueueB:
DXGK_NATIVE_FENCE_LOG_ENTRY LogEntry = {};
LogEntry.hNativeFence = FenceF;
LogEntry.FenceValue = V1;
LogEntry.OperationType = DXGK_NATIVE_FENCE_LOG_OPERATION_SIGNAL_EXECUTED;
LogEntry.FenceEndGpuTimestamp = GPUT1; // Time when UMD submits a command to the GPU
Dopo che l'utilità di pianificazione GPU osserva che HWQueueA è sbloccato al momento della GPU GPU GPUT2, legge il payload UMD e registra l'evento nel log di isolamento fornito dal sistema operativo per HWQueueA:
DXGK_NATIVE_FENCE_LOG_ENTRY LogEntry = {};
LogEntry.hNativeFence = FenceF;
LogEntry.FenceValue = V1;
LogEntry.OperationType = DXGK_NATIVE_FENCE_LOG_OPERATION_WAIT_UNBLOCKED;
LogEntry.FenceObservedGpuTimestamp = GPUTo; // Time that GPU acknowledged UMD's submitted command and queued the fence wait on HW
LogEntry.FenceEndGpuTimestamp = GPUT2;
Dxgkrnl può distruggere e ricreare un buffer di log. Ogni volta che lo fa, chiama DxgkDdiSetNativeFenceLogBuffer per informare il KMD della nuova posizione.
Timestamp cpu delle operazioni in coda delimitate
Il log di messaggistica unificata offre pochi vantaggi in base ai timestamp della CPU indicati di seguito:
- Un elenco di comandi può essere registrato alcuni minuti prima dell'esecuzione della GPU di un buffer dei comandi che include l'elenco di comandi.
- Questi minuti possono essere non ordinati con altri oggetti di sincronizzazione che si trovano nello stesso buffer dei comandi.
È previsto un costo per includere i timestamp della CPU nelle istruzioni di UMD nel buffer di log scritto dalla GPU, quindi i timestamp della CPU non sono inclusi nel payload della voce di log.
Il runtime o UMD può invece generare un evento ETW in coda nativo con il timestamp della CPU al momento della registrazione di un elenco di comandi. Gli strumenti possono quindi creare una sequenza temporale di eventi delimitati e completati combinando il timestamp della CPU da questo nuovo evento e il timestamp GPU dalla voce del buffer di log.
Ordine delle operazioni sulla GPU durante la segnalazione o lo sblocco di un recinto
Il UMD deve assicurarsi che mantenga l'ordine seguente quando compila un elenco di comandi che indica alla GPU di segnalare/sbloccare una recinzione:
- Scrivere il nuovo valore di recinto per recinto GPU VA/CMP VA.
- Scrivere il payload del log nel corrispondente buffer di log GPU VA/CMP VA.
- Generare un interrupt segnalato da un recinto nativo, se necessario.
Questo ordine di operazioni garantisce che Dxgkrnl veda le voci di log più recenti quando l'interrupt viene generato nel sistema operativo.
Il sovraccarico del buffer di log è consentito
La GPU può eseguire il sovraccarico del buffer di log sovrascrivendo le voci non ancora visualizzate dal sistema operativo. Lo fa incrementando WraparoundCount.
Quando il sistema operativo legge il log, può rilevare che si è verificato un overrun confrontando il nuovo valore WraparoundCount nell'intestazione del log con il relativo valore memorizzato nella cache. Se si è verificato un sovraccarico, il sistema operativo ha le opzioni di fallback seguenti:
- Per sbloccare le recinzioni quando si verifica un sovraccarico, il sistema operativo analizza tutte le recinzioni e determina quali camerieri sono stati sbloccati.
- Se la traccia è stata abilitata, il sistema operativo può generare un flag nella traccia per notificare a un utente che gli eventi sono andati persi. Inoltre, quando la traccia è abilitata, il sistema operativo aumenta innanzitutto le dimensioni del buffer di log per evitare sovraccarichi al primo posto.
Non è necessario che UMD implementi il supporto per le operazioni di back pressure durante l'avanzamento delle voci del buffer del log.
Timestamp del buffer del log vuoto o ripetuto
In casi comuni, Dxgkrnl prevede che i timestamp nelle voci di log aumentino in modo monotonico. Tuttavia, esistono scenari in cui i timestamp delle voci di log successive sono zero o uguali alle voci di log precedenti.
In uno scenario con adattatori di visualizzazione collegati, ad esempio, uno degli adattatori concatenati nell'LDA può ignorare l'operazione di scrittura del recinto. In questo caso, la voce del buffer di log ha un timestamp zero. Dxgkrnl gestisce un caso di questo tipo. Detto questo, Dxgkrnl non prevede mai che il timestamp di una determinata voce di log sia inferiore a quello della voce di log precedente, ovvero i timestamp non possono mai tornare indietro.
Aggiornamento sincrono del log di isolamento nativo
Le scritture GPU per aggiornare il valore di limite e il buffer di log corrispondente devono assicurarsi che le scritture vengano propagate completamente prima delle letture della CPU. Questo requisito richiede l'uso delle barriere di memoria. Ad esempio:
- Signal Fence(N): scrivere N come nuovo valore corrente
- Scrivere la voce LOG, incluso il timestamp GPU
- MemoryBarrier
- Increment FirstFreeEntryIndex
- MemoryBarrier
- Interrupt di isolamento monitorato (N): leggere Indirizzo "M" e confrontare il valore con N per decidere di recapitare l'interrupt della CPU
È troppo costoso inserire due barriere su ogni segnale GPU, soprattutto quando è probabile che il controllo dell'interrupt condizionale non sia soddisfatto e che non sia necessario interrompere la CPU. Di conseguenza, la progettazione sposta il costo dell'inserimento di una delle barriere di memoria dalla GPU (producer) alla CPU (consumer). Dxgkrnl chiama la funzione DxgkDdiUpdateNativeFenceLogs per fare in modo che kmD scarichi in modo sincrono le scritture di log di recinto nativo in sospeso su richiesta (analogamente a come dxgkddiUpdateflipqueuelog è stato introdotto per lo scaricamento del log della coda di scorrimento HW).
Per le operazioni GPU:
- Signal Fence(N): scrivere N come nuovo valore corrente
- Scrivere la voce LOG, incluso il timestamp gpu
- Increment FirstFreeEntryIndex
- MemoryBarrier => Assicura che FirstFreeEntryIndex sia completamente propagato
- Interrupt di isolamento monitorato (N): leggere Indirizzo "M" e confrontare il valore con N per decidere di recapitare l'interrupt
Per le operazioni della CPU:
Nel gestore di interrupt segnalato da dxgkrnl (DISPATCH_IRQL):
- Per ogni log HWQueue: leggere FirstFreeEntryIndex e determinare se vengono scritte nuove voci.
- Per ogni log HWQueue con nuove voci: Chiamare DxgkDdiUpdateNativeFenceLogs e fornire gli handle del kernel per tali HWQueues. In questo DDI, KMD inserisce una barriera di memoria a ogni HWQueue specificato, che garantisce che venga eseguito il commit di tutte le scritture di voci di log.
- Dxgkrnl legge le voci di log per estrarre il payload del timestamp.
Quindi, purché l'hardware inserisca una barriera di memoria dopo le scritture in FirstFreeEntryIndex, Dxgkrnl chiama sempre DDI del KMD, consentendo al KMD di inserire una barriera di memoria prima che Dxgkrnl legge tutte le voci di log.
Requisiti hardware futuri
La maggior parte dell'hardware di generazione corrente potrebbe supportare solo la scrittura dell'handle del kernel dell'oggetto di recinzione segnalato nell'interrupt segnalato dal recinto nativo. Questa progettazione è descritta in precedenza in Interruzione segnalata del recinto nativo. In questo caso, Dxgkrnl gestisce il payload di interrupt, come indicato di seguito:
- Il sistema operativo esegue una lettura (potenzialmente attraverso PCI) del valore di recinto.
- Sapendo quale recinzione è stata segnalata e il valore di recinzione, il sistema operativo risveglia i camerieri della CPU in attesa di quel recinto/valore.
- Separatamente, per il dispositivo padre di questa recinzione, il sistema operativo analizza i buffer di log di tutti i relativi HWQueue. Il sistema operativo legge quindi le voci dell'ultimo buffer del log scritto per determinare quale HWQueue ha eseguito il segnale ed estrae il payload timestamp corrispondente. Questo approccio potrebbe leggere in modo ridondante alcuni valori di isolamento in PCI.
Nelle piattaforme future, Dxgkrnl preferisce ottenere una matrice di handle HwQueue del kernel nell'interrupt segnalato dal recinto nativo. Questo approccio consente al sistema operativo di:
- Leggere le voci più recenti del buffer di log per tale HwQueue. Il dispositivo utente non è noto al gestore di interrupt; pertanto, questo handle HwQueue deve essere un handle del kernel.
- Analizzare il buffer di log per individuare le voci di log che indicano quali recinzioni sono state segnalate e quali valori. La lettura solo del buffer di log garantisce una sola lettura su PCI invece di dover leggere in modo ridondante i valori di limite e il buffer di log. Questa ottimizzazione ha esito positivo fino a quando il buffer di log non è stato superato (eliminazione di voci mai lette da Dxgkrnl ).
- Se il sistema operativo rileva che il buffer del log è stato sovraccarico, viene eseguito il fallback al percorso non ottimizzato che legge il valore attivo di ogni recinto di proprietà dello stesso dispositivo. Le prestazioni sono proporzionali al numero di recinzioni di proprietà del dispositivo. Se il valore di isolamento è in memoria video, queste letture sono coerenti con la cache in PCI.
- Sapendo quali recinzioni sono state segnalate e i valori di recinzione, il sistema operativo risveglia i camerieri cpu in attesa su tali recinzioni/valori.
Interrupt segnalato con isolamento nativo ottimizzato
Oltre alle modifiche descritte in Interruzione segnalata di isolamento nativo, viene apportata anche la modifica seguente per supportare l'approccio ottimizzato:
- Il limite OptimizedNativeFenceSignaledInterrupt viene aggiunto a DXGK_VIDSCHCAPS.
Se supportato dall'hardware, invece di compilare una matrice di handle di recinzione che sono stati rilevati, la GPU deve menzionare solo l'handle KMD dell'HWQueue in esecuzione quando è stato generato l'interrupt. Dxgkrnl analizza il buffer del log di recinzione per questo HWQueue e legge tutte le operazioni di isolamento completate dalla GPU dall'ultimo aggiornamento e sblocca tutti i camerieri CPU corrispondenti. Se la GPU non è in grado di determinare quale subset di recinzioni sono state segnalate, deve specificare un handle HWQueue NULL. Quando Dxgkrnl vede un handle HWQueue NULL, esegue il fallback per ripetere l'analisi del buffer di log di tutti gli HWQueue su questo motore per determinare quali recinzioni sono state segnalate.
Il supporto per questa ottimizzazione è facoltativo; KmD deve impostare il limite DXGK_VIDSCHCAPS:OptimizedNativeFenceSignaledInterrupt se è supportato dall'hardware. Se il limite OptimizedNativeFenceSignaledInterrupt non è impostato, la GPU/KMD deve seguire il comportamento descritto in Interruzione segnalata del limite nativo.
Esempio di interruzione segnalata del recinto nativo ottimizzato
HWQueueA: segnale GPU per recinto F1, Valore V1 -> Scrivere nella voce del buffer di log E1 -> Nessun interrupt necessario
HWQueueA: segnale GPU per recinto F1, Valore V2 -> Scrittura nella voce del buffer di log E2 -> Nessun interrupt necessario
HWQueueA: segnale GPU per recinto F2, Valore V3 -> Scrittura nella voce del buffer di log E3 -> Nessun interrupt necessario
HWQueueA: segnale GPU per recinto F2, Valore V3 -> Scrittura nella voce del buffer di log E4 -> interrotto generato
DXGKARGCB_NOTIFY_INTERRUPT_DATA FenceSignalISR = {}; FenceSignalISR.NodeOrdinal = 0; FenceSignalISR.EngineOrdinal = 0; FenceSignalISR.hHWQueue = A;Dxgkrnl legge il buffer di log per HWQueueA. Legge le voci del buffer di log E1, E2, E3 ed E4 per osservare le recinzioni segnalate F1 @ Value V1, F1 @ Value V2, F2 @ Value V3 e F2 @ Value V3 e sblocca eventuali camerieri in attesa di tali recinzioni e valori
Registrazione facoltativa e obbligatoria
Il supporto per la registrazione di recinto nativo per DXGK_NATIVE_FENCE_LOG_TYPE_WAITS e DXGK_NATIVE_FENCE_LOG_TYPE_SIGNALS è obbligatorio.
In futuro, altri tipi di registrazione potrebbero essere aggiunti solo quando strumenti come GPUView abilitano la registrazione ETW dettagliata nel sistema operativo. Il sistema operativo deve informare sia UMD che KMD di quando la registrazione dettagliata è abilitata e disabilitata in modo che la registrazione di tali eventi verbose sia abilitata in modo selettivo.