Risolvere i problemi di Spazi di archiviazione diretta
Si applica a: Azure Stack HCI, versioni 22H2 e 21H2; Windows Server 2022, Windows Server 2019, Windows Server 2016
Usare le informazioni contenute in questo articolo per risolvere i problemi relativi alla distribuzione Spazi di archiviazione diretta.
In generale, iniziare con questi passaggi:
- Verificare che la creazione e il modello di SSD siano certificati per Windows Server 2016 e Windows Server 2019 usando il catalogo di Windows Server. Verificare con il fornitore che le unità siano supportate per Spazi di archiviazione diretta.
- Esaminare lo spazio di archiviazione per eventuali unità difettose. Usare il software di gestione dell'archiviazione per controllare lo stato delle unità. Se una delle unità è difettosa, rivolgersi al fornitore.
- Aggiornare lo spazio di archiviazione e il firmware dell'unità, se necessario. Assicurarsi che la versione più recente di Windows Aggiornamenti sia installata in tutti i nodi. È possibile ottenere gli aggiornamenti più recenti per Windows Server 2016 dalla cronologia degli aggiornamenti di Windows 10 e Windows Server 2016. Ottenere gli aggiornamenti più recenti per Windows Server 2019 dalla cronologia degli aggiornamenti di Windows 10 e Windows Server 2019.
- Aggiornare i driver e il firmware della scheda di rete.
- Eseguire la convalida del cluster ed esaminare la sezione Archiviazione Space Direct. Assicurarsi che le unità usate per la cache vengano segnalate correttamente e che non siano presenti errori.
Se si verificano ancora problemi, vedere le informazioni sulla risoluzione dei problemi per ognuno dei problemi specifici in questo articolo.
Le risorse del disco virtuale non sono in stato di ridondanza
I nodi di un sistema Spazi di archiviazione diretta si riavviano in modo imprevisto a causa di un arresto anomalo o di un guasto di alimentazione. Quindi, uno o più dischi virtuali potrebbero non essere online e viene visualizzata la descrizione Informazioni sulla ridondanza non sufficienti.
| FriendlyName | ResiliencySettingName | OperationalStatus | HealthStatus | IsManualAttach | Dimensione | PSComputerName |
|---|---|---|---|---|---|---|
| Disk4 | Mirror | OK | Healthy | Vero | 10 TB | Node-01.conto... |
| Disk3 | Mirror | OK | Healthy | Vero | 10 TB | Node-01.contoso. |
| Disk2 | Mirror | Nessuna ridondanza | Unhealthy | Vero | 10 TB | Node-01.contoso. |
| Disk1 | Mirror | {Nessuna ridondanza, InService} | Unhealthy | Vero | 10 TB | Node-01.contoso. |
Inoltre, dopo un tentativo di portare online il disco virtuale, le informazioni seguenti vengono registrate nel log del cluster, ovvero .DiskRecoveryAction
[Verbose] 00002904.00001040::YYYY/MM/DD-12:03:44.891 INFO [RES] Physical Disk <DiskName>: OnlineThread: SuGetSpace returned 0.
[Verbose] 00002904.00001040:: YYYY/MM/DD -12:03:44.891 WARN [RES] Physical Disk < DiskName>: Underlying virtual disk is in 'no redundancy' state; its volume(s) may fail to mount.
[Verbose] 00002904.00001040:: YYYY/MM/DD -12:03:44.891 ERR [RES] Physical Disk <DiskName>: Failing online due to virtual disk in 'no redundancy' state. If you would like to attempt to online the disk anyway, first set this resource's private property 'DiskRecoveryAction' to 1. We will try to bring the disk online for recovery, but even if successful, its volume(s) or CSV may be unavailable.
Lo stato operativo di nessuna ridondanza si verifica se un disco non è riuscito o se il sistema non è in grado di accedere ai dati sul disco virtuale. Questo problema può verificarsi se si verifica un riavvio in un nodo durante la manutenzione nei nodi.
Per risolvere il problema, seguire questa procedura:
Rimuovere i dischi virtuali interessati dal volume condiviso cluster. In questo modo, le inserisce nel gruppo di archiviazione disponibile nel cluster e inizia a essere visualizzate come ResourceType di
Physical Disk.Remove-ClusterSharedVolume -Name "CSV Name"Nel nodo proprietario del gruppo Available Archiviazione eseguire il comando seguente in ogni disco senza ridondanza. Per identificare il nodo in cui si trova il gruppo Archiviazione disponibile, è possibile eseguire questo comando:
Get-ClusterGroupImpostare l'azione di ripristino del disco e quindi avviare i dischi.
Get-ClusterResource "Physical Disk Resource Name" | Set-ClusterParameter -Name DiskRecoveryAction -Value 1 Start-ClusterResource -Name "Physical Disk Resource Name"Verrà avviato automaticamente un ripristino. Attendere il completamento della riparazione. Potrebbe entrare in uno stato sospeso e ricominciare. Per monitorare lo stato di avanzamento:
- Eseguire
Get-StorageJobper monitorare lo stato del ripristino e verificare quando viene completato. - Eseguire
Get-VirtualDiske verificare che Space restituisca uno Stato integro.
- Eseguire
Al termine della riparazione e i dischi virtuali sono integri, modificare nuovamente i parametri del disco virtuale.
Get-ClusterResource "Physical Disk Resource Name" | Set-ClusterParameter -Name DiskRecoveryAction -Value 0Portare offline i dischi e quindi di nuovo online per rendere effettivo:
DiskRecoveryActionStop-ClusterResource "Physical Disk Resource Name" Start-ClusterResource "Physical Disk Resource Name"Aggiungere nuovamente i dischi virtuali interessati al volume condiviso cluster.
Add-ClusterSharedVolume -Name "Physical Disk Resource Name"
DiskRecoveryAction è un'opzione di override che consente di collegare il volume Spazio in modalità di lettura/scrittura senza alcun controllo. La proprietà consente di diagnosticare il motivo per cui un volume non è in arrivo online. È simile alla modalità di manutenzione, ma è possibile richiamarla su una risorsa in uno stato di errore. Consente anche di accedere ai dati in modo da poterli copiare. Questo accesso è utile in situazioni di assenza di ridondanza. La DiskRecoveryAction proprietà è stata aggiunta nel 22 febbraio 2018 nell'aggiornamento kb 4077525.
Stato scollegato in un cluster
Quando si esegue il Get-VirtualDisk cmdlet, per OperationalStatus uno o più dischi virtuali Spazi di archiviazione diretta viene scollegato. Tuttavia, HealthStatus segnalato dal Get-PhysicalDisk cmdlet indica che tutti i dischi fisici sono in uno stato Integro.
Questo esempio mostra l'output del Get-VirtualDisk cmdlet .
| FriendlyName | ResiliencySettingName | OperationalStatus | HealthStatus | IsManualAttach | Dimensione | PSComputerName |
|---|---|---|---|---|---|---|
| Disk4 | Mirror | OK | Healthy | Vero | 10 TB | Node-01.contoso. |
| Disk3 | Mirror | OK | Healthy | Vero | 10 TB | Node-01.contoso. |
| Disk2 | Mirror | Detached | Sconosciuto | Vero | 10 TB | Node-01.contoso. |
| Disk1 | Mirror | Detached | Sconosciuto | Vero | 10 TB | Node-01.contoso. |
Inoltre, gli eventi seguenti potrebbero essere registrati nei nodi:
Log Name: Microsoft-Windows-StorageSpaces-Driver/Operational
Source: Microsoft-Windows-StorageSpaces-Driver
Event ID: 311
Level: Error
User: SYSTEM
Computer: Node#.contoso.local
Description: Virtual disk {GUID} requires a data integrity scan.
Data on the disk is out-of-sync and a data integrity scan is required.
To start the scan, run this command:
Get-ScheduledTask -TaskName "Data Integrity Scan for Crash Recovery" | Start-ScheduledTask
Once you have resolved that condition, you can online the disk by using these commands in PowerShell:
Get-VirtualDisk | ?{ $_.ObjectId -Match "{GUID}" } | Get-Disk | Set-Disk -IsReadOnly $false
Get-VirtualDisk | ?{ $_.ObjectId -Match "{GUID}" } | Get-Disk | Set-Disk -IsOffline $false
------------------------------------------------------------
Log Name: System
Source: Microsoft-Windows-ReFS
Event ID: 134
Level: Error
User: SYSTEM
Computer: Node#.contoso.local
Description: The file system was unable to write metadata to the media backing volume <VolumeId>. A write failed with status "A device which does not exist was specified." ReFS will take the volume offline. It might be mounted again automatically.
------------------------------------------------------------
Log Name: Microsoft-Windows-ReFS/Operational
Source: Microsoft-Windows-ReFS
Event ID: 5
Level: Error
User: SYSTEM
Computer: Node#.contoso.local
Description: ReFS failed to mount the volume.
Context: 0xffffbb89f53f4180
Error: A device which does not exist was specified.
Volume GUID:{00000000-0000-0000-0000-000000000000}
DeviceName:
Volume Name:
Si Detached Operational Status verifica se il log di rilevamento dell'area dirty (DRT) è pieno. Archiviazione Spazi usa il rilevamento dell'area dirty (DRT) per gli spazi con mirroring per assicurarsi che, quando si verifica un errore di alimentazione, vengono registrati eventuali aggiornamenti in anteprima dei metadati. Gli aggiornamenti registrati assicurano che lo spazio di archiviazione possa ripetere o annullare le operazioni. Restituiscono lo spazio di archiviazione a uno stato flessibile e coerente dopo il ripristino dell'alimentazione e il sistema torna indietro. Se il log DRT è pieno, il disco virtuale non può essere portato online finché i metadati DRT non vengono sincronizzati e scaricati. Questo processo richiede l'esecuzione di un'analisi completa, che può richiedere diverse ore per terminare.
Per risolvere il problema, seguire questa procedura:
Rimuovere i dischi virtuali interessati dal volume condiviso cluster.
Remove-ClusterSharedVolume -Name "CSV Name"Eseguire questi comandi su ogni disco che non è disponibile online.
Get-ClusterResource -Name "Physical Disk Resource Name" | Set-ClusterParameter DiskRunChkDsk 7 Start-ClusterResource -Name "Physical Disk Resource Name"Eseguire il comando seguente in ogni nodo in cui il volume scollegato è online.
Get-ScheduledTask -TaskName "Data Integrity Scan for Crash Recovery" | Start-ScheduledTaskAvviare questa attività in tutti i nodi in cui il volume scollegato è online. Verrà avviato automaticamente un ripristino. Attendere il completamento della riparazione. Potrebbe entrare in uno stato sospeso e ricominciare. Per monitorare lo stato di avanzamento:
- Eseguire
Get-StorageJobper monitorare lo stato del ripristino e verificare quando viene completato. - Eseguire
Get-VirtualDiske verificare che space restituisca uno stato di integrità integro.Analisi dell'integrità dei dati per il ripristino di arresto anomalo del sistema è un'attività che non viene visualizzata come processo di archiviazione e non è presente alcun indicatore di stato. Se l'attività viene visualizzata come in esecuzione, è in esecuzione. Al termine, viene visualizzato il completamento.
È anche possibile visualizzare lo stato di un'attività di pianificazione in esecuzione usando questo cmdlet:
Get-ScheduledTask | ? State -eq running
- Eseguire
Al termine dell'analisi dell'integrità dei dati per il ripristino di arresto anomalo del sistema, il ripristino viene completato e i dischi virtuali sono integri. Modificare di nuovo i parametri del disco virtuale.
Get-ClusterResource -Name "Physical Disk Resource Name" | Set-ClusterParameter DiskRunChkDsk 0Portare offline i dischi e quindi di nuovo online per rendere effettivo:
DiskRecoveryActionStop-ClusterResource "Physical Disk Resource Name" Start-ClusterResource "Physical Disk Resource Name"Aggiungere nuovamente i dischi virtuali interessati al volume condiviso cluster.
Add-ClusterSharedVolume -Name "Physical Disk Resource Name"Usare
DiskRunChkdsk value 7per collegare il volume Spazio e impostare la partizione sulla modalità di sola lettura. Questa azione consente a Spaces di individuare automaticamente e auto-correggere attivando una riparazione. Il ripristino viene eseguito automaticamente una volta montato. Consente anche di accedere ai dati per copiarli. Per alcune condizioni di errore, ad esempio un log DRT completo, è necessario eseguire l'attività pianificata Analisi dell'integrità dei dati per il ripristino di arresto anomalo del sistema.
Usare l'attività Analisi dell'integrità dei dati per il ripristino di arresto anomalo del sistema per sincronizzare e cancellare un log DRT (Dirty Region Tracking) completo. Il completamento di questa attività può richiedere diverse ore. Analisi dell'integrità dei dati per il ripristino di arresto anomalo del sistema è un'attività che non viene visualizzata come processo di archiviazione e non è presente alcun indicatore di stato. Se l'attività viene visualizzata come in esecuzione, è in esecuzione. Al termine, viene visualizzato come completato. Se si annulla l'attività o si riavvia un nodo durante l'esecuzione dell'attività, l'attività deve ricominciare dall'inizio.
Per altre informazioni, vedere Risolvere i problemi relativi all'integrità e agli stati operativi Spazi di archiviazione diretta.
Evento 5120 con STATUS_IO_TIMEOUT c00000b5
Importante
Per Windows Server 2016: per ridurre la probabilità di riscontrare questi sintomi durante l'applicazione dell'aggiornamento con la correzione, è consigliabile usare la procedura di manutenzione dell'archiviazione per installare l'aggiornamento cumulativo del 18 ottobre 2018 per Windows Server 2016 o una versione successiva quando i nodi hanno attualmente installato un aggiornamento cumulativo di Windows Server 2016 rilasciato dall'8 maggio 2016 Dal 9 ottobre 2018 al 2018.
È possibile ottenere l'evento 5120 con STATUS_IO_TIMEOUT c00000b5 dopo il riavvio di un nodo in Windows Server 2016 con aggiornamento cumulativo rilasciato dall'8 maggio 2018 KB 4103723 al 9 ottobre 2018 KB 4462917 installato.
Quando si riavvia il nodo, l'evento 5120 viene registrato nel registro eventi di sistema e include uno dei codici di errore seguenti:
Event Source: Microsoft-Windows-FailoverClustering
Event ID: 5120
Description: Cluster Shared Volume 'CSVName' ('Cluster Virtual Disk (CSVName)') has entered a paused state because of 'STATUS_IO_TIMEOUT(c00000b5)'. All I/O will temporarily be queued until a path to the volume is reestablished.
Cluster Shared Volume 'CSVName' ('Cluster Virtual Disk (CSVName)') has entered a paused state because of 'STATUS_CONNECTION_DISCONNECTED(c000020c)'. All I/O will temporarily be queued until a path to the volume is reestablished.
Quando viene registrato un evento 5120, viene generato un dump live per raccogliere informazioni di debug che possono causare altri sintomi o influire sulle prestazioni. Quando il dump attivo viene generato, causa una breve pausa. La pausa consente a uno snapshot della memoria di scrivere il file di dump. I sistemi con una grande quantità di memoria e sotto stress potrebbero causare l'eliminazione dei nodi dall'appartenenza al cluster e causare la registrazione dell'evento 1135 seguente.
Event source: Microsoft-Windows-FailoverClustering
Event ID: 1135
Description: Cluster node 'NODENAME'was removed from the active failover cluster membership. The Cluster service on this node might have stopped. This could also be due to the node having lost communication with other active nodes in the failover cluster. Run the Validate a Configuration wizard to check your network configuration. If the condition persists, check for hardware or software errors related to the network adapters on this node. Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges.
Una modifica introdotta nell'8 maggio 2018 a Windows Server 2016 è un aggiornamento cumulativo per aggiungere handle resilienti SMB per le sessioni di rete SMB Spazi di archiviazione diretta all'interno del cluster. Questo aggiornamento è stato apportato per migliorare la resilienza agli errori di rete temporanei e migliorare il modo in cui RoCE gestisce la congestione della rete. Questi miglioramenti aumentano anche inavvertitamente i timeout quando le connessioni SMB tentano di riconnettersi e attende il timeout quando un nodo viene riavviato. Questi problemi possono influire su un sistema sotto stress. Durante il tempo di inattività non pianificato, sono state osservate anche pause di I/O fino a 60 secondi mentre il sistema attende il timeout delle connessioni. Per risolvere questo problema, installare l'aggiornamento cumulativo del 18 ottobre 2018 per Windows Server 2016 o versione successiva.
Nota
Questo aggiornamento allinea i timeout csv ai timeout della connessione SMB per risolvere il problema. Non implementa le modifiche per disabilitare la generazione di dump in tempo reale menzionata nella sezione Soluzione alternativa.
Flusso del processo di arresto
Eseguire il cmdlet Get-VirtualDisk e assicurarsi che il valore HealthStatus sia Integro.
Svuotare il nodo eseguendo questo cmdlet:
Suspend-ClusterNode -DrainInserire i dischi in tale nodo in modalità di manutenzione dell'archiviazione eseguendo questo cmdlet:
Get-StorageFaultDomain -Type StorageScaleUnit | Where-Object {$_.FriendlyName -eq "<NodeName>"} | Enable-StorageMaintenanceModeEseguire il
Get-PhysicalDiskcmdlet e assicurarsi che ilOperationalStatusvalore siaIn Maintenancein modalità.Eseguire il
Restart-Computercmdlet per riavviare il nodo.Dopo il riavvio del nodo, rimuovere i dischi in tale nodo dalla modalità di manutenzione dell'archiviazione eseguendo questo cmdlet:
Get-StorageFaultDomain -Type StorageScaleUnit | Where-Object {$_.FriendlyName -eq "<NodeName>"} | Disable-StorageMaintenanceModeRiprendere il nodo eseguendo questo cmdlet:
Resume-ClusterNodeControllare lo stato dei processi di risincronizzazione eseguendo questo cmdlet:
Get-StorageJob
Disabilitazione dei dump in tempo reale
Per attenuare gli effetti della generazione di dump in tempo reale nei sistemi con una grande quantità di memoria e sotto stress, è possibile disabilitare la generazione di dump in tempo reale. Sono disponibili tre opzioni seguenti:
Attenzione
Questa procedura può impedire la raccolta di informazioni di diagnostica che supporto tecnico Microsoft potrebbe dover analizzare questo problema. Un agente di supporto potrebbe chiedere di riabilitare la generazione di dump in tempo reale in base a scenari di risoluzione dei problemi specifici.
Disabilitare tutti i dump
Per disabilitare completamente tutti i dump, inclusi i dump live a livello di sistema, seguire questa procedura. Usare questa procedura per questo scenario:
- Creare la chiave del Registro di sistema seguente: HKLM\System\CurrentControlSet\Control\CrashControl\ForceDumpsDisabled
- Nella nuova chiave ForceDumpsDisabled creare una proprietà REG_DWORD come GuardedHost e quindi impostarne il valore su 0x10000000.
- Applicare la nuova chiave del Registro di sistema a ogni nodo del cluster.
Nota
Per rendere effettiva la modifica di nregistry, è necessario riavviare il computer.
Dopo aver impostato questa chiave del Registro di sistema, la creazione del dump in tempo reale avrà esito negativo e genererà un errore di STATUS_NOT_SUPPORTED .
Consenti un solo LiveDump
Per impostazione predefinita, Segnalazione errori Windows consente un solo LiveDump per tipo di report per sette giorni e un solo LiveDump per computer per cinque giorni. È possibile modificarlo impostando le chiavi del Registro di sistema seguenti per consentire un solo LiveDump nel computer per sempre.
reg add "HKLM\Software\Microsoft\Windows\Windows Error Reporting\FullLiveKernelReports" /v SystemThrottleThreshold /t REG_DWORD /d 0xFFFFFFFF /f
reg add "HKLM\Software\Microsoft\Windows\Windows Error Reporting\FullLiveKernelReports" /v ComponentThrottleThreshold /t REG_DWORD /d 0xFFFFFFFF /f
Nota
Per rendere effettiva la modifica, è necessario riavviare il computer.
Disabilitare la generazione del cluster
Per disabilitare la generazione di cluster di dump in tempo reale (ad esempio quando viene registrato un evento 5120), eseguire questo cmdlet:
(Get-Cluster).DumpPolicy = ((Get-Cluster).DumpPolicy -Band 0xFFFFFFFFFFFFFFFE)
Questo cmdlet ha un effetto immediato su tutti i nodi del cluster senza un riavvio del computer.
Prestazioni di I/O lente
Se si riscontrano prestazioni di I/O lente, verificare se la cache è abilitata nella configurazione Spazi di archiviazione diretta.
Esistono due modi per verificare:
Usare il log del cluster. Aprire il log del cluster con un editor di testo di propria scelta e cercare "[=== Dischi SBL ===]". Viene visualizzato un elenco del disco nel nodo in cui è stato generato il log.
Esempio di dischi abilitati per la cache: si noti che lo stato è
CacheDiskStateInitializedAndBounde che è presente un GUID qui.[=== SBL Disks ===] {26e2e40f-a243-1196-49e3-8522f987df76},3,false,true,1,48,{1ff348f1-d10d-7a1a-d781-4734f4440481},CacheDiskStateInitializedAndBound,1,8087,54,false,false,HGST,HUH721010AL4200,7PG3N2ER,A21D,{d5e27a3b-42fb-410a-81c6-9d8cc12da20c},[R/M 0 R/U 0 R/T 0 W/M 0 W/U 0 W/T 0],Cache non abilitata: qui è possibile vedere che non è presente alcun GUID e che lo stato è
CacheDiskStateNonHybrid.[=== SBL Disks ===] {426f7f04-e975-fc9d-28fd-72a32f811b7d},12,false,true,1,24,{00000000-0000-0000-0000-000000000000},CacheDiskStateNonHybrid,0,0,0,false,false,HGST,HUH721010AL4200,7PGXXG6C,A21D,{d5e27a3b-42fb-410a-81c6-9d8cc12da20c},[R/M 0 R/U 0 R/T 0 W/M 0 W/U 0 W/T 0],Cache non abilitata: quando tutti i dischi sono dello stesso tipo, il case non è abilitato per impostazione predefinita. Qui è possibile vedere che non è presente alcun GUID e lo stato è
CacheDiskStateIneligibleDataPartition.{d543f90c-798b-d2fe-7f0a-cb226c77eeed},10,false,false,1,20,{00000000-0000-0000-0000-000000000000},CacheDiskStateIneligibleDataPartition,0,0,0,false,false,NVMe,INTEL SSDPE7KX02,PHLF7330004V2P0LGN,0170,{79b4d631-976f-4c94-a783-df950389fd38},[R/M 0 R/U 0 R/T 0 W/M 0 W/U 0 W/T 0],Usare Get-PhysicalDisk.xml da SDDCDiagnosticInfo.
- Aprire il file XML usando "$d = Import-Clixml GetPhysicalDisk.XML".
- Eseguire
ipmo storage. - Eseguire
$d. Si noti che l'utilizzo è Selezione automatica, non Journal.
L'output dovrebbe essere simile al seguente:
FriendlyName SerialNumber MediaType CanPool OperationalStatus HealthStatus Utilizzo Dimensione NVMe INTEL SSDPE7KX02 PHLF733000372P0LGN SSD False OK Healthy Selezione automatica 1,82 TB NVMe INTEL SSDPE7KX02 PHLF7504008J2P0LGN SSD False OK Healthy Selezione automatica 1,82 TB NVMe INTEL SSDPE7KX02 PHLF7504005F2P0LGN SSD False OK Healthy Selezione automatica 1,82 TB NVMe INTEL SSDPE7KX02 PHLF7504002A2P0LGN SSD False OK Healthy Selezione automatica 1,82 TB NVMe INTEL SSDPE7KX02 PHLF7504004T2P0LGN SSD False OK Healthy Selezione automatica 1,82 TB NVMe INTEL SSDPE7KX02 PHLF7504002E2P0LGN SSD False OK Healthy Selezione automatica 1,82 TB NVMe INTEL SSDPE7KX02 PHLF7330002Z2P0LGN SSD False OK Healthy Selezione automatica 1,82 TB NVMe INTEL SSDPE7KX02 PHLF733000272P0LGN SSD False OK Healthy Selezione automatica 1,82 TB NVMe INTEL SSDPE7KX02 PHLF7330001J2P0LGN SSD False OK Healthy Selezione automatica 1,82 TB NVMe INTEL SSDPE7KX02 PHLF733000302P0LGN SSD False OK Healthy Selezione automatica 1,82 TB NVMe INTEL SSDPE7KX02 PHLF7330004D2P0LGN SSD False OK Healthy Selezione automatica 1,82 TB
Come eliminare definitivamente un cluster esistente in modo da poter usare di nuovo gli stessi dischi
In un cluster Spazi di archiviazione diretta disabilitare Spazi di archiviazione diretta e usare il processo di pulizia descritto in Pulire le unità. Il pool di archiviazione cluster rimane ancora in uno stato Offline e il Servizio integrità viene rimosso dal cluster.
Il passaggio successivo consiste nel rimuovere il pool di archiviazione fantasma:
Get-ClusterResource -Name "Cluster Pool 1" | Remove-ClusterResource
Ora, se si esegue Get-PhysicalDisk in uno dei nodi, vengono visualizzati tutti i dischi presenti nel pool. Ad esempio, in un lab con un cluster a 4 nodi con 4 dischi SAS, 100 GB ciascuno presentato a ogni nodo. In tal caso, dopo Archiviazione Space Direct è disabilitato, che rimuove sBL (Archiviazione livello bus) ma lascia il filtro, se si esegue Get-PhysicalDisk, dovrebbe segnalare 4 dischi esclusi il disco del sistema operativo locale. Ha invece segnalato 16. Questo comportamento è lo stesso per tutti i nodi del cluster. Quando si esegue un comando Get-Disk , i dischi collegati localmente sono numerati come 0, 1, 2 e così via, come illustrato in questo output di esempio:
| Numero | Soprannome | Numero di serie | HealthStatus | OperationalStatus | Dimensioni totali | Stile partizione |
|---|---|---|---|---|---|---|
| 0 | Msft Virtual | Healthy | Online | 127 GB | GPT | |
| Msft Virtual | Healthy | Offline | 100 GB | RAW | ||
| Msft Virtual | Healthy | Offline | 100 GB | RAW | ||
| Msft Virtual | Healthy | Offline | 100 GB | RAW | ||
| Msft Virtual | Healthy | Offline | 100 GB | RAW | ||
| 1 | Msft Virtual | Healthy | Offline | 100 GB | RAW | |
| Msft Virtual | Healthy | Offline | 100 GB | RAW | ||
| 2 | Msft Virtual | Healthy | Offline | 100 GB | RAW | |
| Msft Virtual | Healthy | Offline | 100 GB | RAW | ||
| Msft Virtual | Healthy | Offline | 100 GB | RAW | ||
| Msft Virtual | Healthy | Offline | 100 GB | RAW | ||
| Msft Virtual | Healthy | Offline | 100 GB | RAW | ||
| 4 | Msft Virtual | Healthy | Offline | 100 GB | RAW | |
| 3 | Msft Virtual | Healthy | Offline | 100 GB | RAW | |
| Msft Virtual | Healthy | Offline | 100 GB | RAW | ||
| Msft Virtual | Healthy | Offline | 100 GB | RAW | ||
| Msft Virtual | Healthy | Offline | 100 GB | RAW |
Messaggio di errore relativo al tipo di supporto non supportato quando si crea un cluster Spazi di archiviazione diretta tramite Enable-ClusterS2D
È possibile che vengano visualizzati errori simili quando si esegue il cmdlet Enable-ClusterS2D :
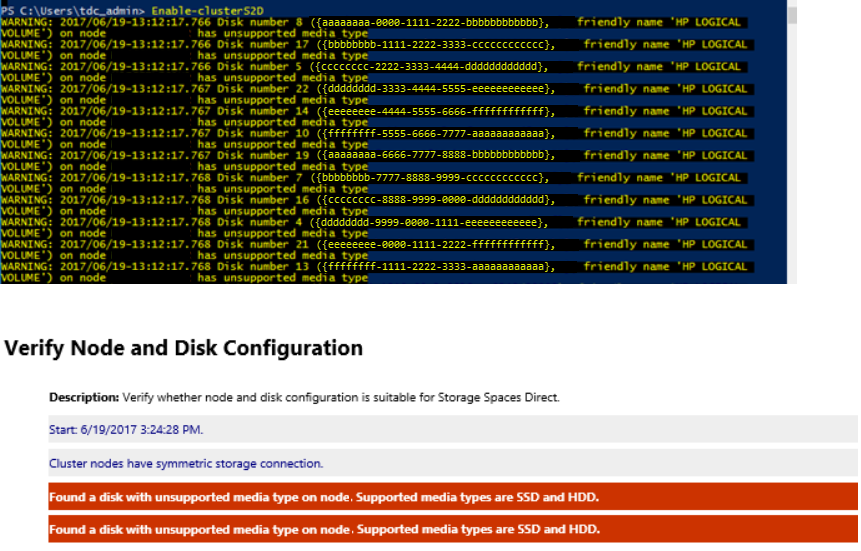
Per risolvere questo problema, verificare che la scheda HBA sia configurata in modalità HBA. Nessun HBA deve essere configurato in modalità RAID.
Enable-Cluster Archiviazione SpacesDirect si blocca a 'Waiting until SBL disks are surfaced' or at 27%
Nel report di convalida sono visualizzate le informazioni seguenti:
Il disco <identifier> connesso al nodo <nodename> ha restituito un'associazione di porte SCSI e non è stato possibile trovare il dispositivo enclosure corrispondente. L'hardware non è compatibile con Spazi di archiviazione diretta (S2D). Contattare il fornitore dell'hardware per verificare il supporto per i servizi enclosure SCSI (edizione Standard S).
Il problema riguarda la scheda di espansione HPE SAS che si trova tra i dischi e la scheda HBA. L'espansore SAS crea un ID duplicato tra la prima unità connessa all'espansore e l'espansore stesso. Questo problema è stato risolto in HPE Smart Array Controllers SAS Expander Firmware: 4.02.
Intel SSD DC P4600 serie ha un NGUID non univoco
Potrebbe essere visualizzato un problema per cui un dispositivo Intel SSD DC P4600 serie sembra segnalare un NGUID di 16 byte simile per più spazi dei nomi, ad esempio 01000000100000000E4D25C000014E214 o 010000001000000E4D25C00000 edizione Enterprise E214 in questo esempio.
| UniqueId | DeviceId | MediaType | BusType | SerialNumber | Dimensione | CanPool | FriendlyName | OperationalStatus |
|---|---|---|---|---|---|---|---|---|
| 5000CCA251D12E30 | 0 | HDD | SAS | 7PKR197G | 10000831348736 | False | HGST | HUH721010AL4200 |
| eui.01000000010000000E4D25C000014E214 | 4 | SSD | NVMe | 0100_0000_0100_0000_E4D2_5C00_0014_E214. | 1600321314816 | Vero | INTEL | SSDPE2KE016T7 |
| eui.01000000010000000E4D25C000014E214 | 5 | SSD | NVMe | 0100_0000_0100_0000_E4D2_5C00_0014_E214. | 1600321314816 | Vero | INTEL | SSDPE2KE016T7 |
| eui.0100000001000000E4D25C00000 edizione Enterprise E214 | 6 | SSD | NVMe | 0100_0000_0100_0000_E4D2_5C00_00edizione Enterprise_E214. | 1600321314816 | Vero | INTEL | SSDPE2KE016T7 |
| eui.0100000001000000E4D25C00000 edizione Enterprise E214 | 7 | SSD | NVMe | 0100_0000_0100_0000_E4D2_5C00_00edizione Enterprise_E214. | 1600321314816 | Vero | INTEL | SSDPE2KE016T7 |
Per risolvere questo problema, aggiornare il firmware nelle unità Intel alla versione più recente. La versione del firmware QDV101B1 di maggio 2018 è nota per risolvere questo problema.
La versione di maggio 2018 dello strumento Intel SSD Data Center include un aggiornamento del firmware, QDV101B1, per la serie Intel SSD DC P4600.
HealthStatus per il disco fisico e OperationalStatus
In un cluster di Windows Server 2016 Spazi di archiviazione diretta, è possibile visualizzare HealthStatus per uno o più dischi fisici come Integro, mentre OperationalStatus sta rimuovendo dal pool, OK.
Lo stato Rimozione dal pool è una finalità impostata quando Remove-PhysicalDisk viene chiamato ma archiviato in Integrità per mantenere lo stato e consentire il ripristino se l'operazione di rimozione non riesce. È possibile modificare manualmente OperationalStatus in Integro con uno di questi metodi:
- Rimuovere il disco fisico dal pool e quindi aggiungerlo di nuovo.
- Import-Module Clear-PhysicalDiskHealthData.ps1.
- Eseguire lo script Clear-PhysicalDiskHealthData.ps1 per cancellare la finalità. Questo script è disponibile per il download come file con estensione txt. È necessario salvarlo come file ps1 prima di poterlo eseguire.
Ecco alcuni esempi che illustrano come eseguire lo script:
Usare il
SerialNumberparametro per specificare il disco che è necessario impostare su Integro. È possibile ottenere il numero di serie daWMI MSFT_PhysicalDiskoGet-PhysicalDisk. In questo esempio vengono usati zeri per il numero di serie.This example uses zeros to stand for the serial number.Clear-PhysicalDiskHealthData -Intent -Policy -SerialNumber 000000000000000 -Verbose -ForceUsare il
UniqueIdparametro per specificare il disco, di nuovo daWMI MSFT_PhysicalDiskoGet-PhysicalDisk.Clear-PhysicalDiskHealthData -Intent -Policy -UniqueId 00000000000000000 -Verbose -Force
La copia dei file è lenta
Si noterà che la copia del file richiede più tempo del previsto quando si usa Esplora file per copiare un disco rigido virtuale di grandi dimensioni nel disco virtuale.
Non è consigliabile usare Esplora file, Robocopy o Xcopy per copiare un disco rigido virtuale di grandi dimensioni nel disco virtuale. Il risultato è più lento rispetto alle prestazioni previste. Il processo di copia non passa attraverso lo stack di Spazi di archiviazione diretta, che si trova più in basso nello stack di archiviazione e agisce invece come un processo di copia locale.
Per testare le prestazioni Spazi di archiviazione diretta, è consigliabile usare VMFleet e Diskspd per caricare e testare lo stress dei server per ottenere una linea di base e impostare le aspettative delle prestazioni Spazi di archiviazione diretta.
Eventi previsti visualizzati nei nodi rimanenti durante il riavvio di un nodo
È possibile ignorare questi eventi:
Event ID 205: Windows lost communication with physical disk {XXXXXXXXXXXXXXXXXXXX}. This can occur if a cable failed or was disconnected, or if the disk itself failed.
Event ID 203: Windows lost communication with physical disk {XXXXXXXXXXXXXXXXXXXX}. This can occur if a cable failed or was disconnected, or if the disk itself failed.
Se si eseguono macchine virtuali di Azure, è possibile ignorare questo evento: ID evento 32: Il driver ha rilevato che nel dispositivo \Device\Harddisk5\DR5 è abilitata la cache di scrittura. Potrebbe verificarsi un danneggiamento dei dati.
Rallentamento delle prestazioni o "Comunicazione persa", "Errore I/O", "Scollegato" o "Nessuna ridondanza" per le distribuzioni che usano dispositivi INTEL P3x00 NVMe
È stato rilevato un problema critico che interessa alcuni utenti Spazi di archiviazione diretta che usano hardware basato sulla famiglia Intel P3x00 di dispositivi NVM Express (NVMe) con versioni del firmware precedenti a "Maintenance Release 8".
Nota
I singoli OEM potrebbero avere dispositivi basati sulla famiglia Intel P3x00 di dispositivi NVMe con stringhe di versione del firmware univoche. Per altre informazioni sulla versione più recente del firmware, contattare l'OEM.
Se si usa l'hardware nella distribuzione in base alla famiglia Intel P3x00 di dispositivi NVMe, è consigliabile applicare immediatamente il firmware disponibile più recente (almeno la versione di manutenzione 8).