Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
AI Toolkit for VS Code (AI Toolkit) è un'estensione VS Code che consente di scaricare, testare, ottimizzare e distribuire modelli di intelligenza artificiale con le app o il cloud. Per altre informazioni, vedere panoramica di AI Toolkit.
Nota
La documentazione e le esercitazioni aggiuntive per AI Toolkit for VS Code sono disponibili nella VS Code documentazione: AI Toolkit for Visual Studio Code. Sono disponibili indicazioni su Playground, sull'uso di modelli di intelligenza artificiale, sull'ottimizzazione dei modelli locali e basati sul cloud e altro ancora.
In questo articolo si apprenderà come:
- Configurare un ambiente locale per ottimizzare.
- Eseguire un processo di ottimizzazione.
Prerequisiti
- Completata Introduzione a AI Toolkit per Visual Studio Code.
- Se si usa un computer Windows per la messa a punto, installare Windows Subsystem for Linux(WSL). Vedere Come installare Linux in Windows con WSL per installare WSL e una distribuzione Linux predefinita. È necessario installare la distribuzione di WSL Ubuntu 18.04 o versione successiva e impostare come distribuzione predefinita prima di usare AI Toolkit per VS Code. Informazioni su come modificare la distribuzione predefinita.
- Se si usa un computer Linux , deve essere una distribuzione Ubuntu 18.04 o successiva.
- L'uso del modello in questa esercitazione richiede GPU NVIDIA per l'ottimizzazione. Esistono altri modelli nel catalogo che possono essere caricati nei dispositivi Windows usando CPU o NPU.
Suggerimento
Assicurarsi di avere installato i driver NVIDIA più recenti nel computer. Se si ha la possibilità di scegliere tra Game Ready Driver o Studio Driver, scaricare il driver di Studio.
È necessario conoscere il modello della GPU per scaricare i driver corretti. Per scoprire la GPU disponibile, vedere Come controllare la GPU e perché è importante.
Configurazione dell'ambiente
Per verificare se sono presenti tutti i prerequisiti necessari per eseguire processi di ottimizzazione nel dispositivo locale o nella macchina virtuale cloud, aprire il riquadro comandi (MAIUSC+CONTROLLO+P) e cercare AI Toolkit: Validate Environment prerequisites (Prerequisiti dell'ambiente di convalida).
Se il dispositivo locale supera i controlli di convalida, il pulsante Configura ambiente WSL verrà abilitato per la selezione. Verranno installate tutte le dipendenze necessarie per eseguire processi di ottimizzazione.
Macchina virtuale cloud
Se il computer locale non dispone di un dispositivo GPU Nvidia, è possibile ottimizzare in una macchina virtuale cloud, sia Windows che Linux, con una GPU Nvidia (se è disponibile una quota). In Azure è possibile ottimizzare la serie di macchine virtuali seguente:
- Serie NCasT4_v3
- Serie NC A100 v4
- Serie ND A100 v4
- Serie NCads H100 v5
- Serie NCv3
- Serie NVadsA10 v5
Suggerimento
VS Code consente di accedere in remoto alla macchina virtuale cloud. Se non hai familiarità con questa funzionalità, leggi l'esercitazione sullo sviluppo remoto tramite SSH
Ottimizzare un modello
AI Toolkit usa un metodo denominato QLoRA, che combina la quantizzazione e l'adattamento a bassa classificazione (LoRA) per ottimizzare i modelli con i propri dati. Per ulteriori informazioni su QLoRA, vedere QLoRA: Efficient Finetuning of Quantized LLMs.
Passaggio 1: Configurare il progetto
Per avviare una nuova sessione di ottimizzazione con QLoRA, selezionare l'elemento Ottimizzazione nella sezione Strumenti nel pannello sinistro di AI Toolkit.
Per iniziare, immettere un nome di progetto univoco e un percorso di progetto. Verrà creata una nuova cartella con il nome del progetto specificato nel percorso selezionato per archiviare i file di progetto.
Selezionare quindi un modello, ad esempio Phi-3-mini-4k-instruct , dal Catalogo modelli e quindi selezionare Configura progetto:
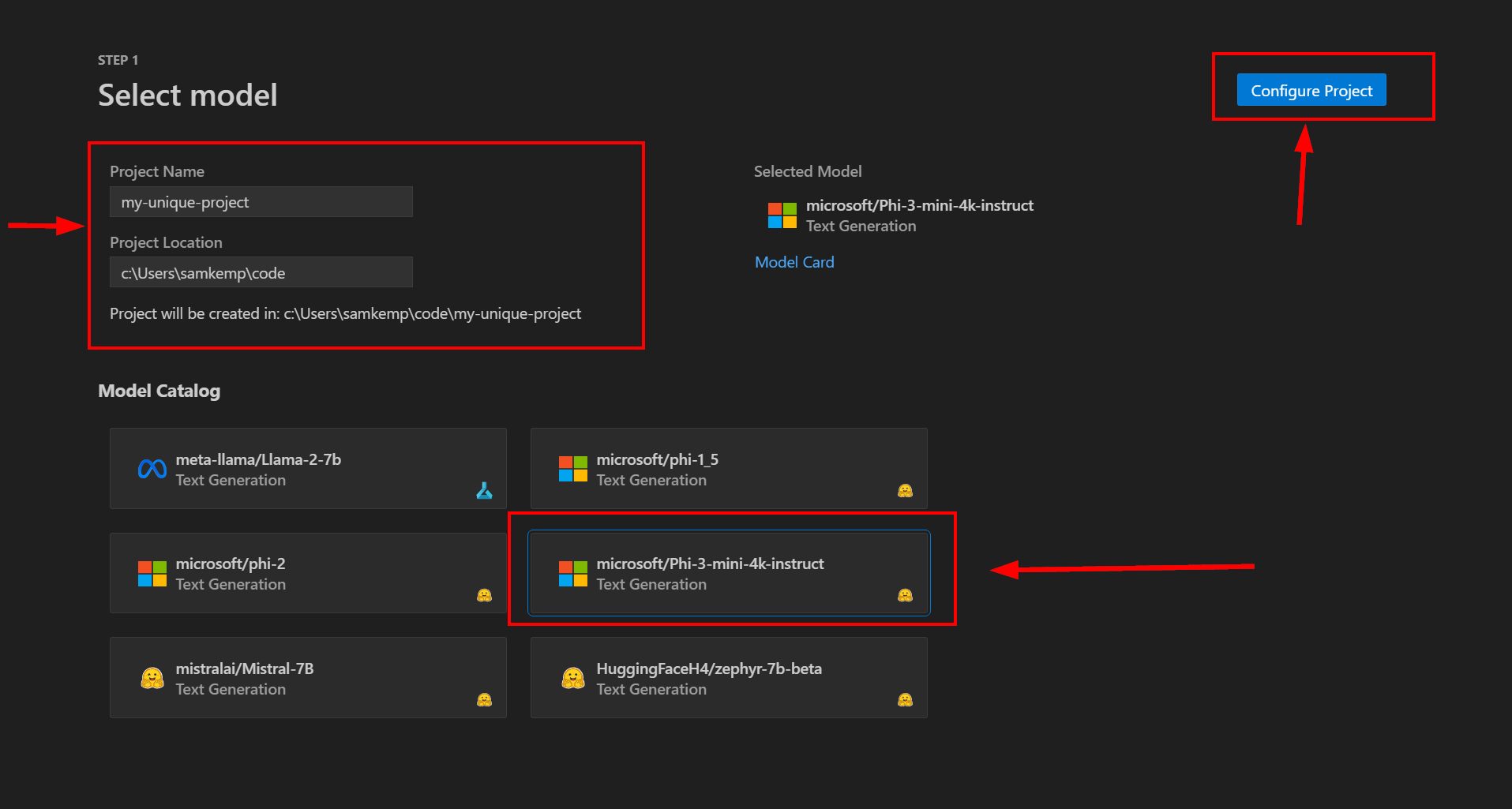
Verrà quindi richiesto di configurare le impostazioni del progetto di ottimizzazione. Verificare che la casella di controllo Ottimizza localmente sia selezionata (in futuro l'estensione consentirà di eseguire l'offload VS Code dell'ottimizzazione nel cloud):
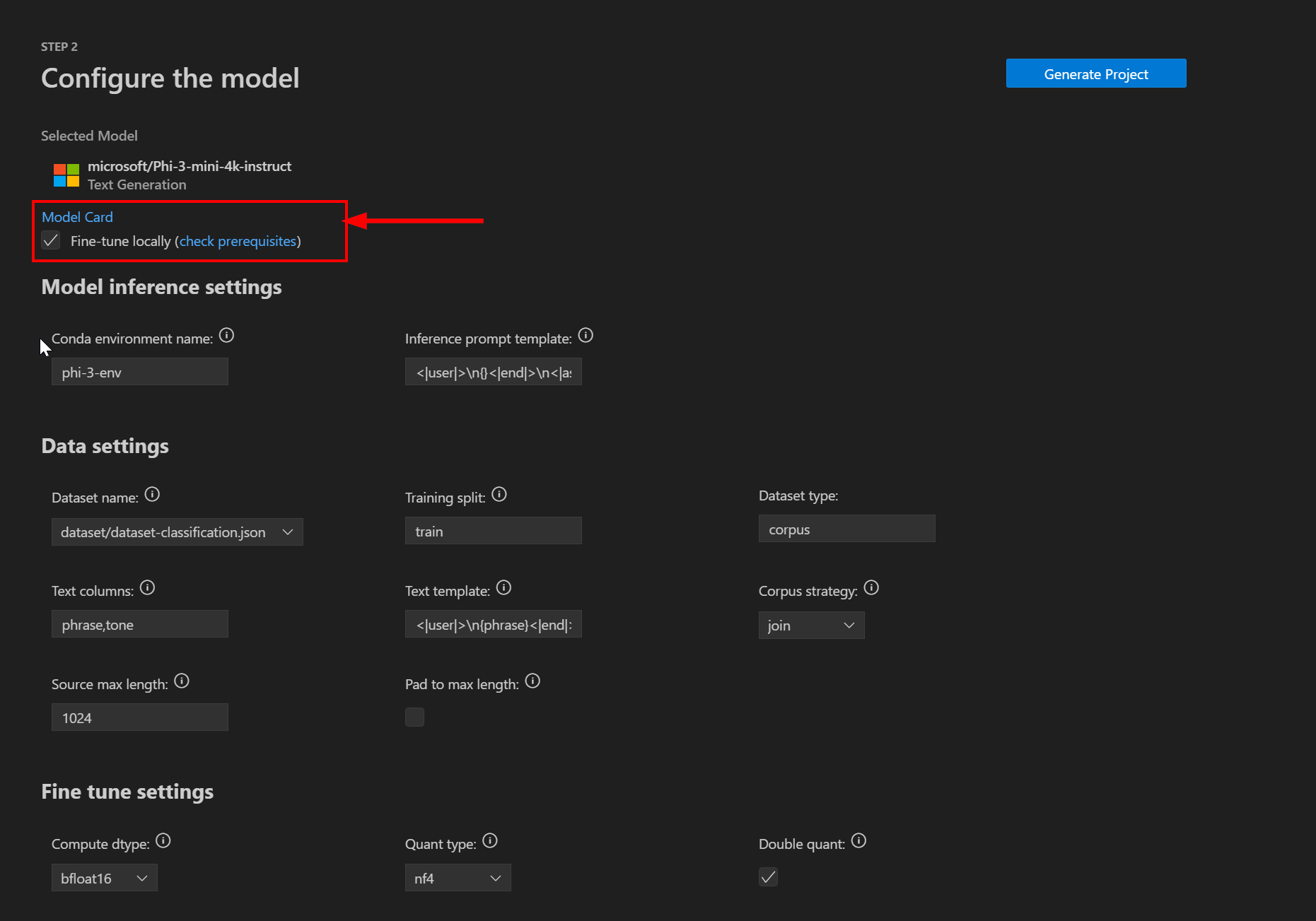
Impostazioni di inferenza del modello
Nella sezione Inferenza del modello sono disponibili due impostazioni:
| Impostazione | Descrizione |
|---|---|
| Nome dell'ambiente Conda | Nome dell'ambiente conda da attivare e utilizzare per il processo di ottimizzazione. Questo nome deve essere univoco nell'installazione di conda. |
| Modello di richiesta di inferenza | Modello di richiesta da usare in fase di inferenza. Assicurarsi che corrisponda alla versione ottimizzata. |
Impostazioni dati
Nella sezione Dati sono disponibili le impostazioni seguenti per configurare le informazioni sul set di dati:
| Impostazione | Descrizione |
|---|---|
| Nome set di dati | Nome del set di dati da usare per ottimizzare il modello. |
| Suddivisione della formazione | Nome della divisione del training per il set di dati. |
| Tipo di set di dati | Tipo di set di dati da usare. |
| Colonne di testo | Nomi delle colonne nel set di dati per popolare il prompt di training. |
| Modello di testo | Modello di richiesta da usare per ottimizzare il modello. Vengono utilizzati token di sostituzione dalle colonne di testo. |
| Strategia del corpus | Indica se si desidera unire gli esempi o elaborarli riga per riga. |
| Lunghezza massima della fonte | Numero massimo di token per campione di training. |
| Tastiera fino alla lunghezza massima | Aggiungere un token PAD all'esempio di training fino al numero massimo di token. |
Ottimizzare le impostazioni
Le impostazioni seguenti sono disponibili nella sezione Ottimizzazione per configurare ulteriormente il processo di ottimizzazione:
| Impostazione | Tipo di dati | Valore predefinito | Descrizione |
|---|---|---|---|
| Calcolo Dtype | Stringa | bfloat16 | Tipo di dati per pesi del modello e pesi dell'adattatore. Per un modello quantizzato a 4 bit, è anche il tipo di dati di calcolo per i moduli quantizzati. Valori validi: bfloat16, float16 o float32. |
| Tipo quanti | Stringa | nf4 | Tipo di dati di quantizzazione da utilizzare. Valori validi: fp4 o nf4. |
| Quanti doppio | Booleano | Sì | Indica se utilizzare la quantizzazione nidificata in cui le costanti di quantizzazione della prima quantizzazione vengono quantizzate di nuovo. |
| Lora r | Intero | 64 | Dimensione di attenzione di Lora. |
| Lora alfa | Galleggiare | 16 | Parametro alfa per il ridimensionamento di Lora. |
| Rilascio di Lora | Galleggiare | 0,1 | Probabilità di rilascio per i livelli Lora. |
| Dimensioni set di dati Eval | Galleggiare | 1024 | Dimensioni del set di dati di convalida. |
| Seme | Intero | 0 | Valore di inizializzazione casuale. |
| Valore di inizializzazione dei dati | Intero | 42 | Valore di inizializzazione casuale da usare con i campionatori di dati. |
| Dimensioni batch per training del dispositivo | Intero | 1 | Dimensioni batch per GPU per il training. |
| Dimensioni batch per dispositivo eval | Intero | 1 | Dimensioni batch per GPU per valutazione. |
| Passaggi di accumulo sfumatura | Intero | 4 | Numero di passaggi di aggiornamento per cui accumulare le sfumature, prima di eseguire un passaggio indietro/aggiornamento. |
| Abilitare il checkpoint sfumatura | Booleano | Sì | Usare il checkpoint sfumato. È consigliabile risparmiare memoria. |
| Velocità di apprendimento | Galleggiare | 0,0002 | Tasso di apprendimento iniziale per AdamW. |
| Numero massimo di passaggi | Intero | -1 | Se impostato su un numero positivo, il numero totale di passaggi di training da eseguire. Questa operazione esegue l'override di num_train_epochs. Se si usa un set di dati iterabile finito, il training può interrompersi prima di raggiungere il numero di passaggi impostato quando tutti i dati vengono esauriti. |
Passaggio 2: Generare un progetto
Dopo aver impostato tutti i parametri, fare clic su Genera progetto. Verranno eseguite le azioni seguenti:
- Avviare il download del modello.
- Installare tutti i prerequisiti e le dipendenze.
- Creare un'area VS Code di lavoro.
Quando il modello viene scaricato e l'ambiente è pronto, è possibile avviare il progetto da AI Toolkit selezionando Finestra di riavvio nell'area di lavoro nella pagina Passaggio 3 - Generazione del progetto . Verrà avviata una nuova istanza di VS Code connessa all'ambiente.
Nota
Potrebbe essere richiesto di installare estensioni aggiuntive, ad esempio Prompt Flow per VS Code. Per un'esperienza di ottimizzazione ottimale, installarle per procedere.
La finestra riavviata avrà nell'area di lavoro le cartelle seguenti:
| Nome cartella | Descrizione |
|---|---|
| set di dati | Questa cartella contiene il set di dati per il modello (dataset-classification.json - un file di righe JSON contenente frasi e toni). Se si imposta il progetto per l'uso di un file locale o di un set di dati Hugging Face, è possibile ignorare questa cartella. |
| Ottimizzazione della regolazione | File di configurazione Olive per eseguire il processo di ottimizzazione. Olive è uno strumento di ottimizzazione dei modelli compatibile con hardware facile da usare che compone tecniche leader del settore per la compressione del modello, l'ottimizzazione e la compilazione. Dato un modello e un hardware di destinazione, Olive compone le tecniche di ottimizzazione più adatte per restituire i modelli più efficienti per l'inferenza su cloud o edge, prendendo in considerazione un set di vincoli, ad esempio accuratezza e latenza. |
| inferenza | Esempi di codice per l'inferenza con un modello ottimizzato. |
| infra | Per ottimizzare e inferenza usando azure Container servizio app (presto disponibile). Questa cartella contiene i file di configurazione e Bicep per effettuare il provisioning dell'servizio app di Azure Container. |
| installazione | File usati per configurare l'ambiente conda. Ad esempio, i requisiti pip. |
Passaggio 3: Eseguire un processo di ottimizzazione
È ora possibile ottimizzare il modello usando:
# replace {conda-env-name} with the name of the environment you set
conda activate {conda-env-name}
python finetuning/invoke_olive.py
Importante
Il tempo necessario per ottimizzare dipenderà dal tipo di GPU, dal numero di GPU, dal numero di passaggi e dal numero di periodi. Questo può richiedere molto tempo( ad esempio, può richiedere diverse ore).
Se si vuole eseguire un test rapido, è consigliabile ridurre il numero massimo di passaggi nel olive-config.json file. Il checkpoint viene usato e quindi l'esecuzione successiva di ottimizzazione continuerà dall'ultimo checkpoint.
I checkpoint e il modello finale verranno salvati nella models cartella del progetto.
Passaggio 4: Integrare un modello ottimizzato nell'app
Eseguire quindi l'inferenza con il modello ottimizzato tramite chat in un consoleweb browser oggetto o prompt flow.
cd inference
# Console interface.
python console_chat.py
# Web browser interface allows to adjust a few parameters like max new token length, temperature and so on.
# User has to manually open the link (e.g. http://127.0.0.1:7860) in a browser after gradio initiates the connections.
python gradio_chat.py
Suggerimento
Le istruzioni sono disponibili anche nella README.md pagina, disponibile nella cartella del progetto.