Azure Data Factory を使用して Azure Data Lake Storage Gen2 にデータを読み込む
適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
Azure Data Lake Storage Gen2 は、ビッグ データ分析専用の機能セットであり、Azure Blob Storageに組み込まれます。 ファイル システムとオブジェクト ストレージの両方のパラダイムを使用して、データと連携させることができます。
Azure Data Factory (ADF) は、フル マネージドのクラウドベース データ統合サービスです。 このサービスを使用して、オンプレミスとクラウドベースのデータストアの豊富なセットからのデータをレイクに入力し、分析ソリューションをビルドする際の時間を節約できます。 サポートされるコネクタの詳細な一覧については、サポートされるデータ ストアの表をご覧ください。
Azure Data Factory では、スケール アウトしたマネージド データ移動ソリューションを提供しています。 ADF のスケールアウト アーキテクチャにより、高スループットでデータを取り込むことができます。 詳しくは、コピー アクティビティのパフォーマンスに関する記事をご覧ください。
この記事では、Data Factory のデータのコピー ツールを使用して "アマゾン ウェブ サービスの S3 サービス" から Azure Data Lake Storage Gen2 にデータを読み込む方法を示します。 その他の種類のデータ ストアからデータをコピーする場合も、同様の手順で実行できます。
ヒント
Azure Data Lake Storage Gen1 から Gen2 へのデータのコピーについては、こちらのチュートリアルを参照してください。
前提条件
- Azure サブスクリプション:Azure サブスクリプションをお持ちでない場合は、開始する前に 無料アカウント を作成してください。
- Data Lake Storage Gen2 が有効な Azure Storage アカウント:ストレージ アカウントがない場合、作成します。
- データが含まれる S3 バケットを持つ AWS アカウント:この記事では、Amazon S3 からデータをコピーする方法を示します。 同様の手順に従うことによって、その他のデータ ストアも使用できます。
Data Factory の作成
データ ファクトリをまだ作成していない場合は、「クイック スタート: Azure portal と Azure Data Factory Studio を使用してデータ ファクトリを作成する」の手順に従って作成してください。 作成した後、Azure portal 内のデータ ファクトリに移動します。
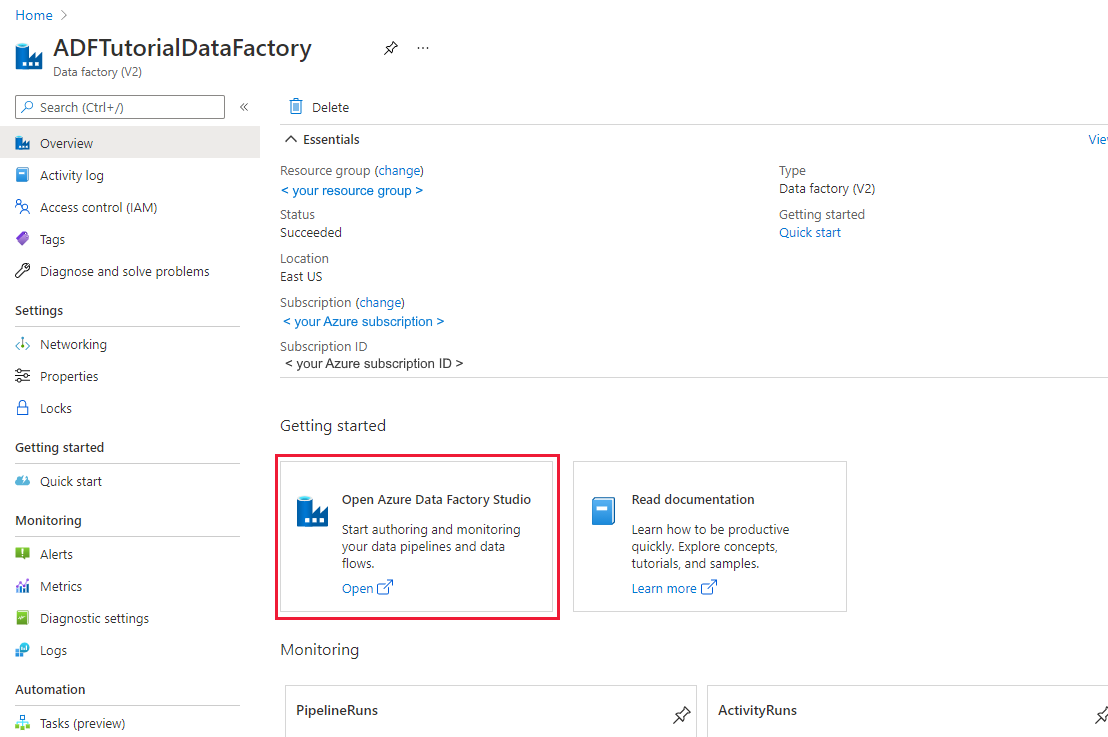
[Open Azure Data Factory Studio](Azure Data Factory Studio を開く) タイルで [開く] を選択して、別のタブでデータ統合アプリケーションを起動します。
Azure Data Lake Storage Gen2 にデータを読み込む
Azure Data Factory のホーム ページで、 [取り込み] タイルを選択し、データのコピー ツールを起動します。
[プロパティ] ページで、 [タスクの種類] の [Built-in copy task](組み込みコピー タスク) を選択して、 [Task cadence or task schedule](タスクの周期またはタスクのスケジュール) の [Run once now](今すぐ 1 度だけ実行する) を選択し、 [次へ] を選択します。
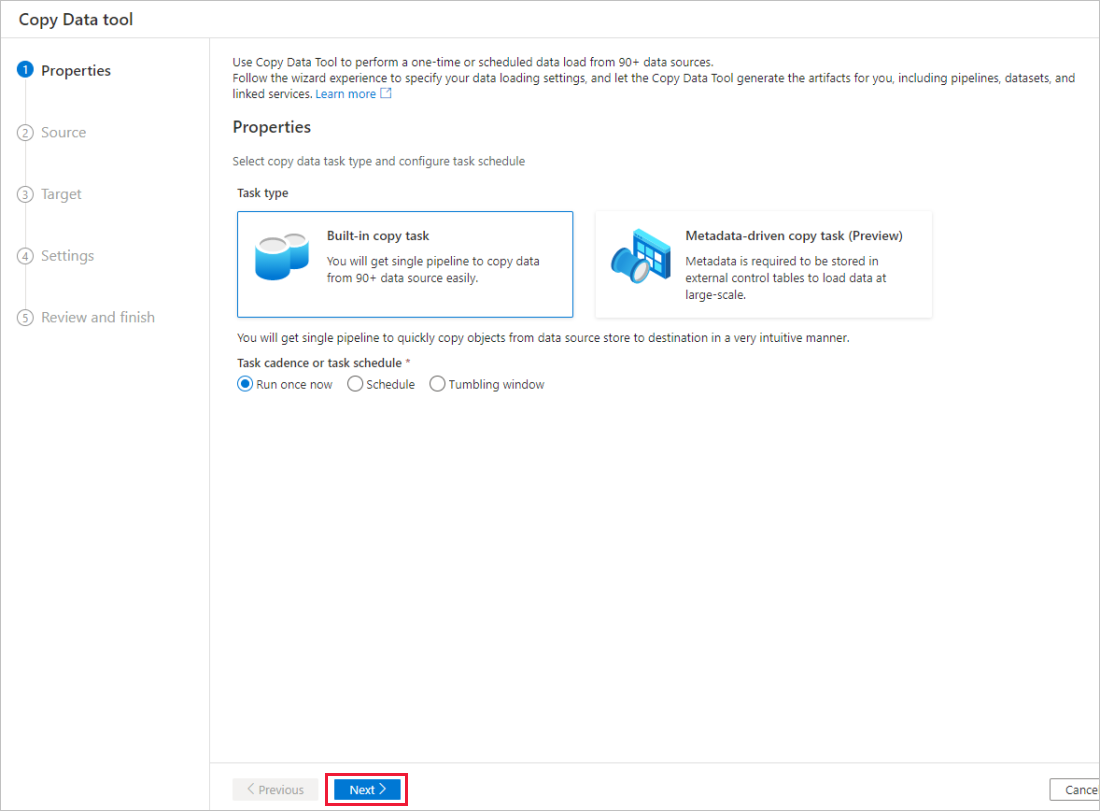
[ソース データ ストア] ページで、次の手順を実行します。
[+ 新しい接続] を選択します。 コネクタ ギャラリーから [Amazon S3] を選択し、 [続行] を選択します。

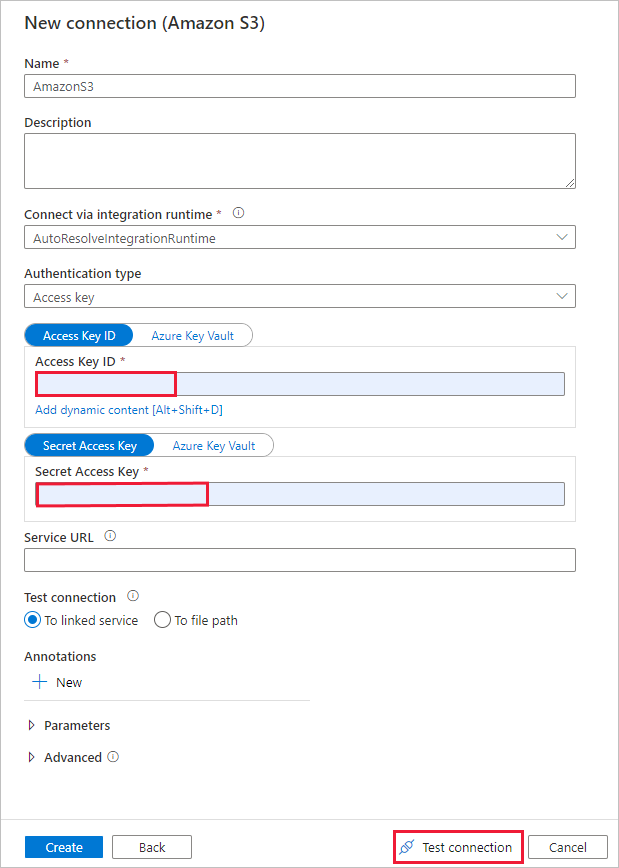
[New connection (Amazon S3)](新しい接続 (Amazon S3)) ページで、次の手順のようにします。
- [アクセス キー ID] の値を指定します。
- [シークレット アクセス キー] の値を指定します。
- [テスト接続] を選択して設定を検証し、 [作成] を選択します。
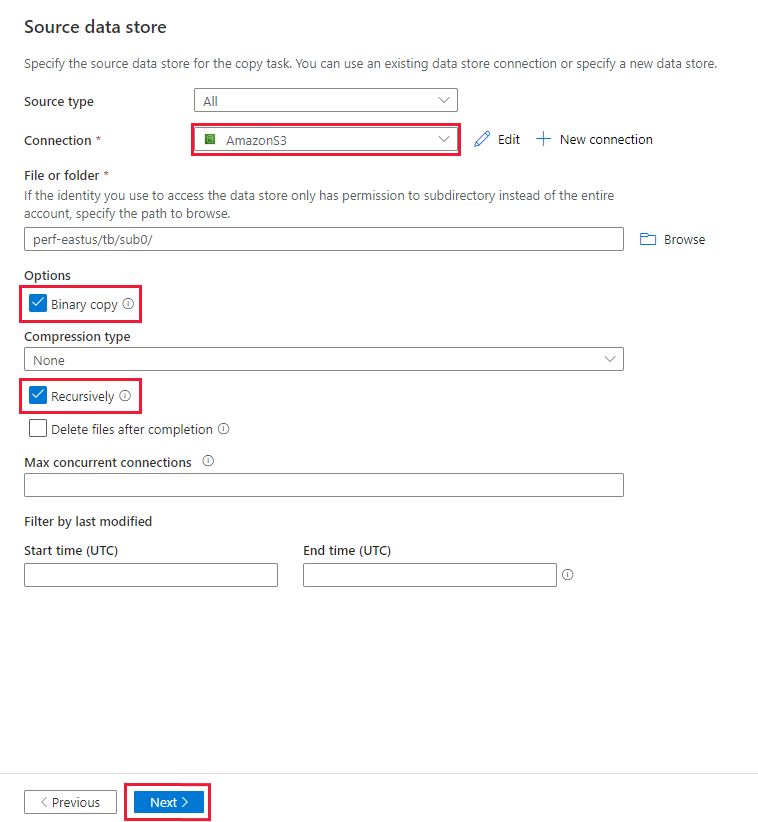
[ソース データ ストア] ページで、新しく作成した Amazon S3 接続が、 [接続] ブロックで選択されていることを確認します。
[ファイルまたはフォルダー] セクションで、コピーするフォルダーとファイルを参照します。 フォルダーまたはファイルを選択して、 [OK] を選択します。
[再帰的] オプションと [バイナリ コピー] オプションをオンにすることで、コピーの動作を指定します。 [次へ] を選択します。
[Destination data store](コピー先データ ストア) ページで、次の手順のようにします。
[+ 新しい接続] を選択し、 [Azure Data Lake Storage Gen2] を選択して、 [続行] を選択します。
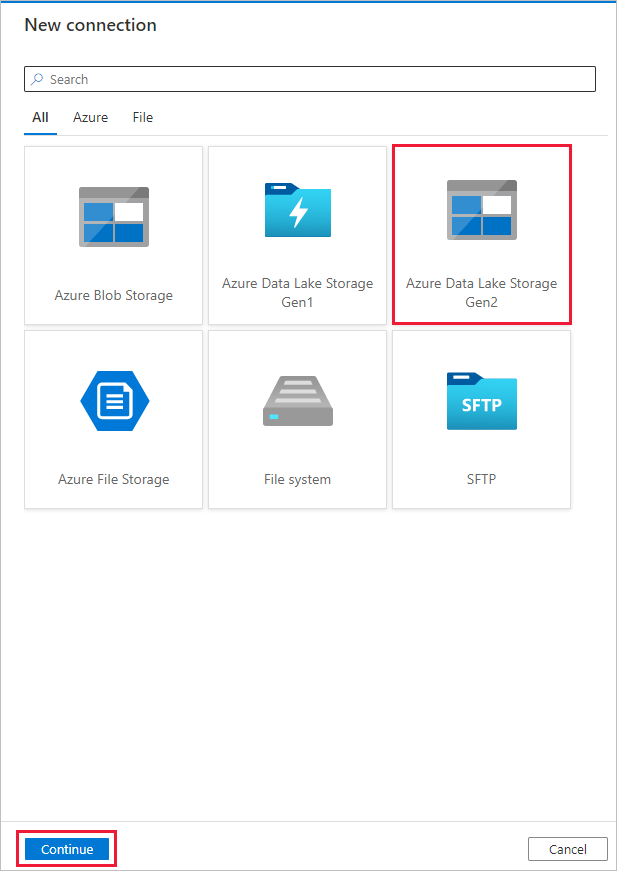
[新しい接続 (Azure Data Lake Storage Gen2)] ページで、[ストレージ アカウント名] ドロップダウンの一覧から Data Lake Storage Gen2 対応のアカウントを選択し、 [作成] を選択して接続を作成します。
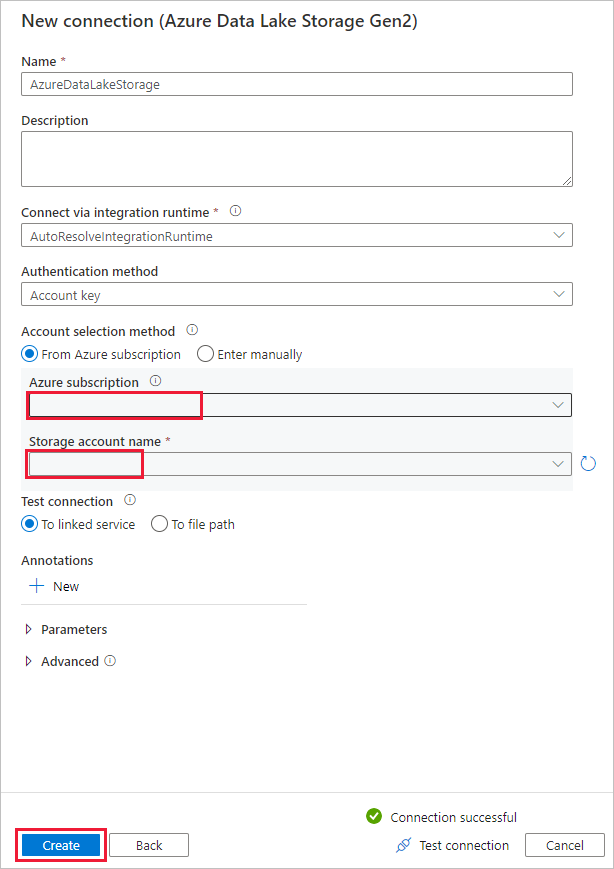
[Destination data store](コピー先データ ストア) ページの [接続] ブロックで、新しく作成した接続を選択します。 [フォルダー パス] で、出力フォルダー名として「copyfroms3」と入力し、 [次へ] を選択します。 対応する ADLS Gen2 ファイル システムとサブ フォルダーが存在しない場合は、コピー中に ADF によって作成されます。
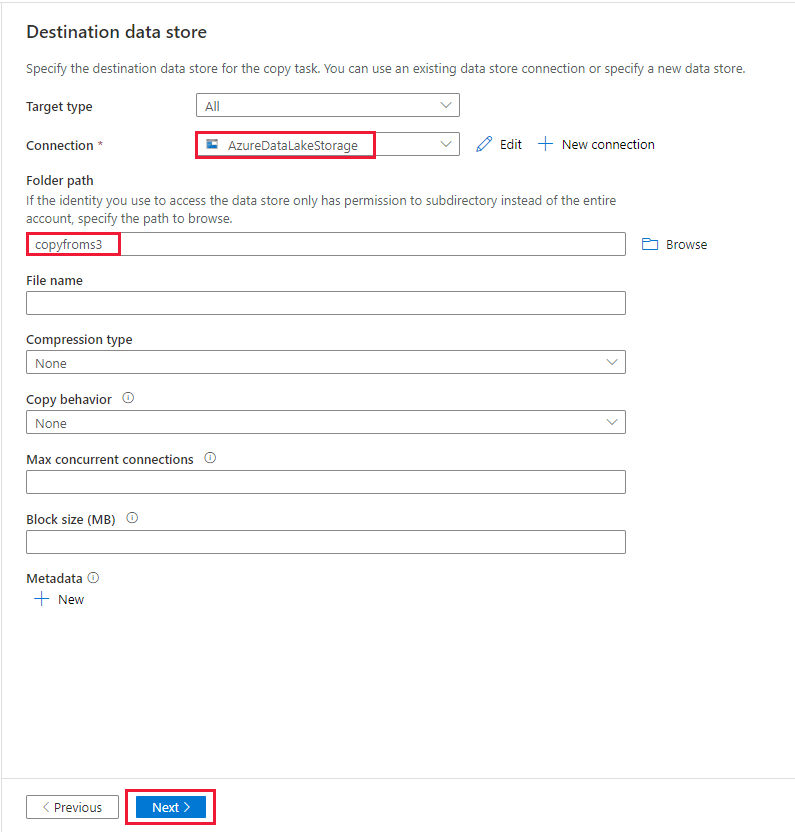
[設定] ページで、 [タスク名] フィールドに「CopyFromAmazonS3ToADLS」と指定し、 [次へ] を選択して既定の設定を使用します。
[サマリー] ページで設定を確認し、 [次へ] を選択します。
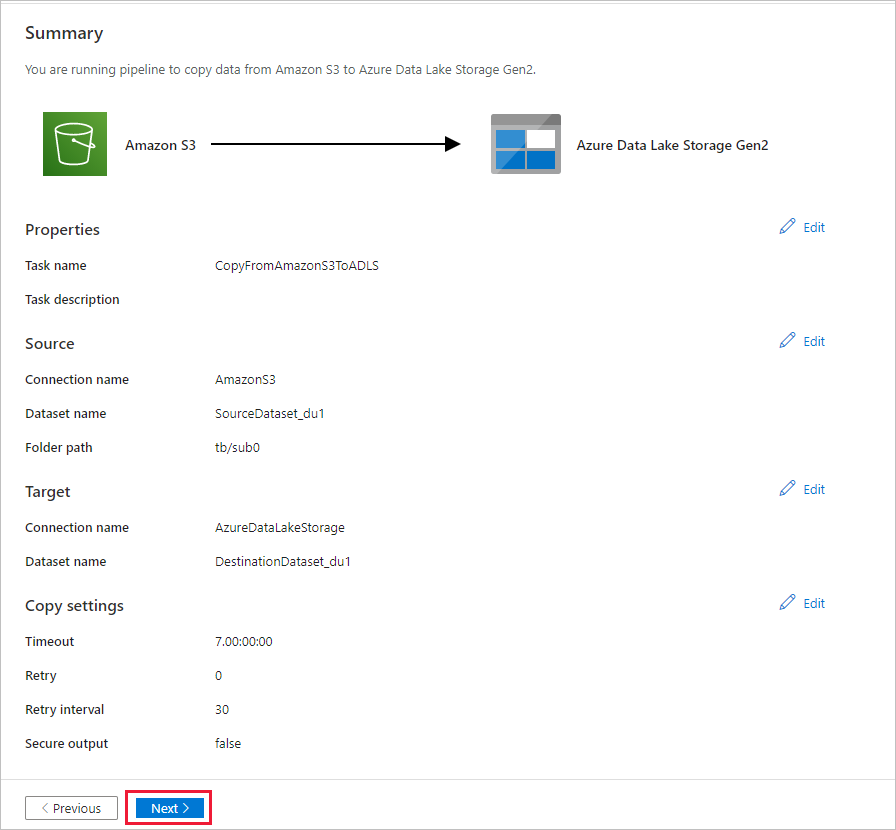
[Deployment](デプロイ) ページで [監視] を選択してパイプライン (タスク) を監視します。
パイプラインの実行が正常に完了すると、手動トリガーによってトリガーされたパイプラインの実行が表示されます。 [パイプライン名] 列のリンクを使用して、アクティビティの詳細を表示したりパイプラインを再実行したりできます。
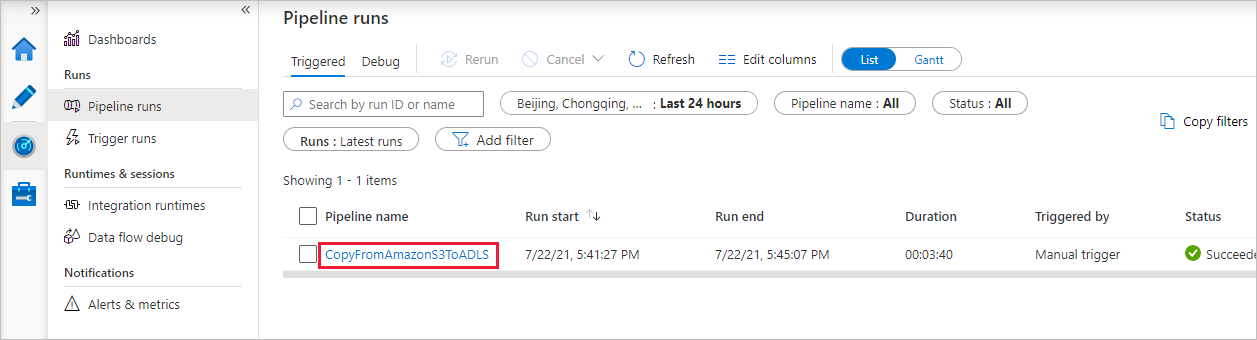
パイプラインの実行に関連付けられているアクティビティの実行を表示するには、 [パイプライン名] 列の CopyFromAmazonS3ToADLS リンクを選択します。 コピー操作の詳細を確認するには、 [アクティビティ名] 列の [詳細] リンク (眼鏡アイコン) を選択します。 ソースからシンクにコピーされるデータのボリューム、データのスループット、実行ステップと対応する期間、使用される構成などの詳細を監視できます。
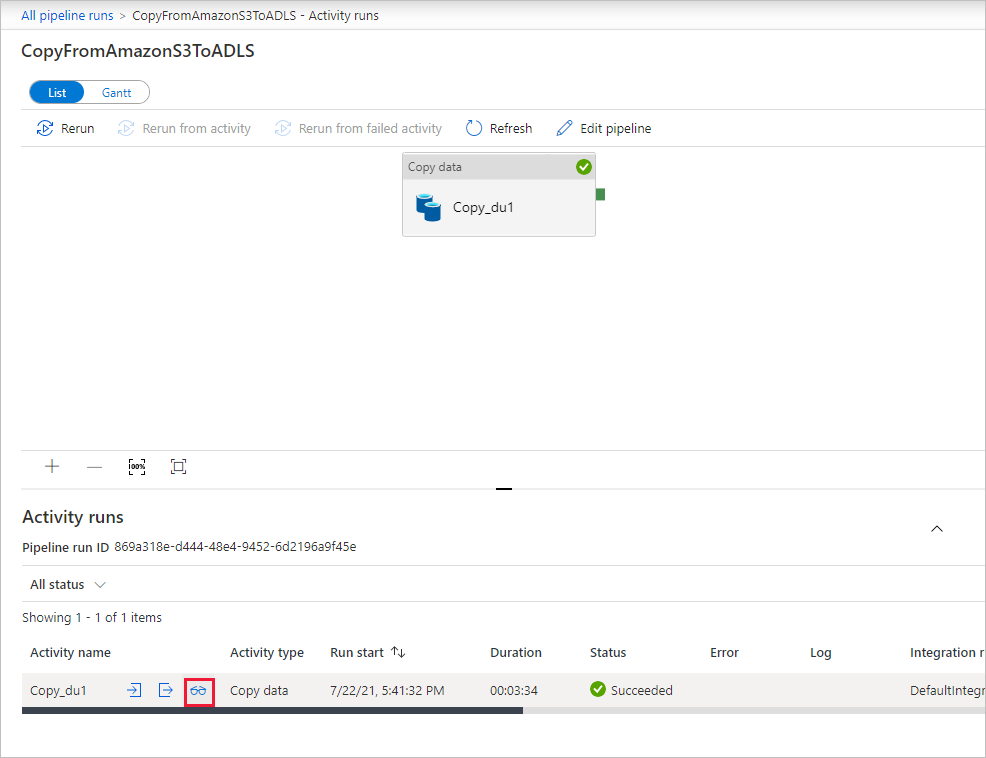
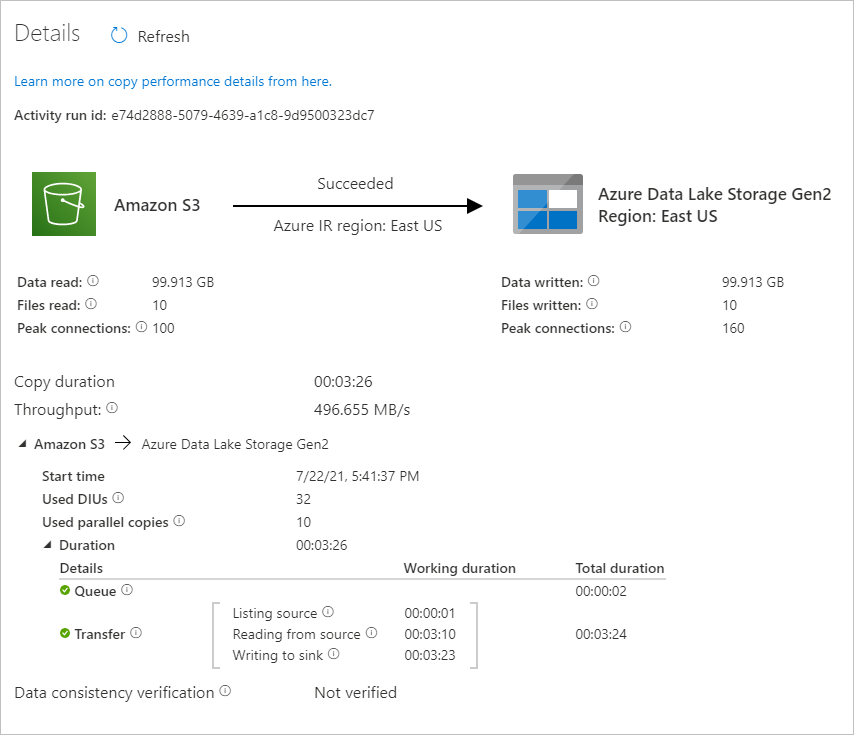
表示を更新するには、 [最新の情報に更新] を選択します。 [パイプラインの実行] ビューに戻るには、一番上にある [すべてのパイプラインの実行] を選択します。
データが Data Lake Storage Gen2 アカウントにコピーされたことを確認します。