Azure AI Search での AI エンリッチメント
Azure AI Search では、"AI エンリッチメント" は、生の形式で検索できないコンテンツを処理するために Azure AI サービスと統合することを指します。 エンリッチメントにより、分析と推論を使用して、以前は存在しなかった検索可能なコンテンツや構造を作成します。
Azure AI Search はテキストおよびベクトル検索ソリューションであるため、AI エンリッチメントの目的は、検索関連のシナリオでコンテンツの有用性を向上することです。 ソース コンテンツはテキストである必要があります (ベクトルをエンリッチすることはできません) が、エンリッチメント パイプラインによって作成されるコンテンツは、チャンク用の Text Split スキルや、エンコード用の AzureOpenAIEmbedding スキルなどのスキルを使用してベクトル化し、ベクトル インデックス内でインデックスを付けることができます。
AI エンリッチメントは、"スキル" に基づきます。
組み込みスキルは、Azure AI サービスに関連付けられます。 組み込みのスキルにより、生のコンテンツに次の変換と処理が適用されます。
- 多言語検索の場合の翻訳と言語検出
- テキストの大きなチャンクからユーザー名、場所、その他のエンティティを抽出するエンティティ認識
- 重要な用語を識別して出力するキー フレーズ抽出
- バイナリ ファイル内の印刷されたテキストと手書きのテキストを認識する光学式文字認識 (OCR)
- 画像の内容を説明し、説明を検索可能なテキスト フィールドとして出力する画像分析
カスタム スキルは、外部コードを実行します。 カスタム スキルは、パイプラインに含めるカスタム処理に使用できます。
AI エンリッチメントは、Azure データ ソースに接続するインデクサー パイプラインの拡張機能です。 エンリッチメント パイプラインには、インデクサー パイプラインのすべてのコンポーネント (インデクサー、データ ソース、インデックス) に加えて、アトミック エンリッチメント ステップを指定するスキルセットが含まれます。
次の図に、AI エンリッチメントの進行を示します。
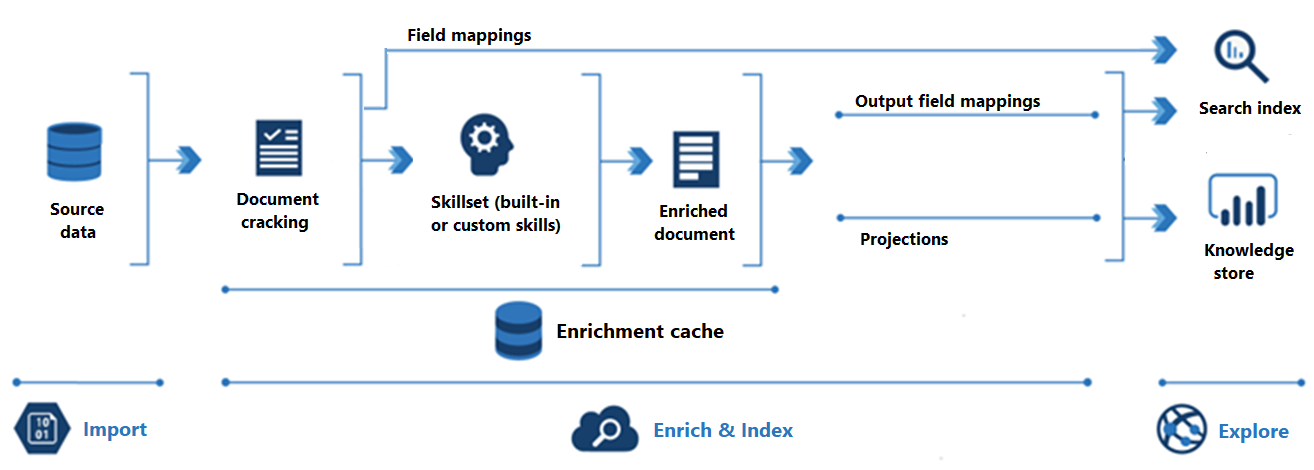
インポートは最初の手順です。 ここで、インデクサーがデータ ソースに接続し、コンテンツ (ドキュメント) を検索サービスにプルします。 AI エンリッチメント シナリオで使用される最も一般的なリソースは Azure Blob Storage ですが、サポートされている任意のデータ ソースがコンテンツを提供できます。
[エンリッチとインデックス]では、ほとんどの AI エンリッチメント パイプラインが対象となります。
エンリッチメントは、インデクサーが "ドキュメントを解読" し、画像とテキストを抽出したときに開始されます。 次に発生する処理の種類は、データと、スキルセットに追加したスキルによって異なります。 画像がある場合は、画像処理を実行するスキルに転送できます。 テキスト コンテンツは、テキストと自然言語の処理のためにキューに入れられます。 内部的には、スキルによって、変換が発生したときにそれを収集する "エンリッチされたドキュメント" が作成されます。
エンリッチ済みコンテンツは、スキルセットの実行の間に生成され、ユーザーが保存しない限り一時的なものです。 後でスキルセットを実行するときに再利用するため、エンリッチメント キャッシュで解読されたドキュメントとスキル出力を保持できます。
検索インデックスにコンテンツを取り込むため、インデクサーはエンリッチされたコンテンツをターゲット フィールドに送信するためのマッピング情報を保持している必要があります。 フィールド マッピング (明示的または暗黙的) は、ソース データから検索インデックスへのデータ パスを設定します。 出力フィールド マッピングは、エンリッチされたドキュメントからインデックスへのデータ パスを設定します。
インデックス作成は、生のコンテンツとエンリッチされたコンテンツが検索インデックス (そのファイルとフォルダー) の物理データ構造に取り込まれるプロセスです。 このステップで、字句解析とトークン化が行われます。
探索は最後の手順です。 出力は常に、クライアント アプリからクエリを実行できる検索インデックスです。 必要に応じて出力を、データ探索ツールまたはダウンストリーム プロセスを介してアクセスされる Azure Storage 内の BLOB とテーブルで構成されるナレッジ ストアにすることができます。 ナレッジ ストアを作成している場合は、エンリッチされたコンテンツのデータ パスがプロジェクションによって決定されます。 インデックスとナレッジ ストアの両方に、同じエンリッチされたコンテンツを含めることができます。
どのような場合に AI エンリッチメントを使用するか
生コンテンツが、非構造化テキスト、画像コンテンツ、または言語検出と翻訳を必要とするコンテンツの場合は、エンリッチメントが有用です。 "組み込みのコグニティブ スキル" を通じて AI を適用すると、フルテキスト検索とデータ サイエンス アプリケーションに対してこのコンテンツのロックが解除されます。
カスタム スキルを作成して、外部処理を提供することもできます。 オープンソース、サードパーティ、またはファーストパーティのコードは、カスタム スキルとしてパイプラインに統合できます。 さまざまなドキュメントの種類の顕著な特徴を識別する分類モデルはこのカテゴリに分類されますが、コンテンツの価値を高める任意の外部パッケージを使用できます。
組み込みスキルのユース ケース
組み込みのスキルは、Azure AI Computer Vision と Language Service などのAzure AI サービス API に基づいています。 コンテンツの入力が少ない場合を除いて、より大きなワークロードを実行するために、課金対象の Azure AI サービス リソースをアタッチする必要があります。
組み込みのスキルを使用して作られたスキルセットは、次のアプリケーション シナリオに適しています。
画像処理スキルには、光学式文字認識 (OCR) と、視覚的特徴の識別が含まれます。後者は、顔検出、画像の解釈、画像の認識 (有名な人物やランドマーク)、画像の向きのような属性などの識別です。 これらのスキルにより、Azure AI Search でフルテキスト検索用の画像コンテンツのテキスト表現が作成されます。
機械翻訳 は、多くの場合、多言語ソリューション用の 言語検出 と組み合わせて、テキスト翻訳 スキルによって提供されます。
自然言語処理では、テキストのチャンクが分析されます。 このカテゴリのスキルには、エンティティ認識、センチメント検出 (オピニオン マイニングを含む)、個人を特定できる情報の検出などがあります。 これらのスキルによって、構造化されていないテキストが、インデックスで検索可能およびフィルター可能なフィールドとしてマップされます。
カスタム スキルのユース ケース
カスタム スキルは、指定した外部コードを実行し、カスタム スキル Web インターフェイスでラップします。 カスタム スキルのいくつかの例は、azure-search-power-skills の GitHub リポジトリにあります。
カスタム スキルは常に複雑とは限りません。 たとえば、パターン マッチングまたはドキュメント分類モデルを提供する既存のパッケージがある場合は、カスタム スキルで完成させることができます。
出力を格納する
Azure AI Search では、インデクサーによって作成された出力が保存されます。 1 回のインデクサー実行で、エンリッチされてインデックス付けされた出力を含む最大 3 つのデータ構造を作成できます。
| データ ストア | 必須 | 場所 | 説明 |
|---|---|---|---|
| 検索可能なインデックス | 必須 | 検索サービス | フルテキスト検索やその他のクエリ フォームに使用されます。 インデックスの指定はインデクサーの要件です。 インデックスの内容は、スキルの出力に加えて、インデックス内のフィールドに直接マップされるすべてのソース フィールドから設定されます。 |
| ナレッジ ストア | オプション | Azure Storage | ナレッジ マイニングやデータ サイエンスなどのダウンストリーム アプリに使用されます。 ナレッジ ストアは、スキルセット内で定義されています。 その定義により、エンリッチされたドキュメントが Azure Storage でテーブルとオブジェクト (ファイルと BLOB) のどちらとして投影されるかが決まります。 |
| エンリッチメント キャッシュ: | オプション | Azure Storage | 後続のスキルセットの実行で再利用するためのエンリッチメントのキャッシュに使用されます。 キャッシュには、インポートされた未処理のコンテンツ (解読されたドキュメント) が格納されます。 スキルセットの実行中に作成されたエンリッチされたドキュメントも格納されます。 キャッシュは、画像解析または OCR を使用していて、画像ファイルの再処理にかかる時間と費用を回避したい場合に役立ちます。 |
インデックスとナレッジ ストアは相互に完全に独立しています。 インデクサーの要件を満たすにはインデックスをアタッチする必要がありますが、ナレッジ ストアだけが目的の場合は、作成された後でインデックスを無視してかまいません。
コンテンツを探索する
検索インデックスまたはナレッジ ストアを定義して読み込んだら、そのデータを探索できます。
検索インデックスに対してクエリを実行する
クエリを実行して、パイプラインによって生成されたエンリッチされたコンテンツにアクセスします。 インデックスは、Azure AI Search 用に作成する他のインデックスと同様です。カスタム アナライザーを使用してテキスト解析を補完したり、あいまい検索クエリを呼び出したり、フィルターを追加したり、スコアリング プロファイルを実験して検索の関連性を調整したりできます。
ナレッジ ストアに対してデータ探索ツールを使用する
この Azure Storage ナレッジ ストア では、JSON ドキュメントの BLOB コンテナー、イメージ オブジェクトの BLOB コンテナー、または Table Storage のテーブルの形式を想定できます。 Storage Explorer、Power BI、または Azure Storage に接続する任意のアプリを使用して、コンテンツにアクセスできます。
BLOB コンテナーは、エンリッチされたドキュメント全体をキャプチャします。これは、他のプロセスにフィードを作成する場合に便利です。
テーブルは、エンリッチされたドキュメントのスライスが必要な場合、または出力の特定の部分を含めるか除外する場合に便利です。 Power BI での分析には、表がデータの探索や可視化に推奨されるデータソースです。
可用性と料金
エンリッチメントは、Azure AI サービスが利用できるリージョンで利用できます。 エンリッチメントをご利用いただけるかどうかは、「リージョン別の利用可能な Azure 製品」ページでご確認いただけます。
課金は、従量課金制モデルに従います。 スキルセットで複数リージョンの Azure AI サービス キーが指定されている場合、組み込みスキルを使用するためのコストが転嫁されます。 Azure AI Search によって測定される画像抽出に関連するコストもあります。 ただし、テキスト抽出とユーティリティのスキルは請求されません。 詳細については、「 Azure AI Searchの課金方法」を参照してください。
一般的なワークフローのチェックリスト
エンリッチメント パイプラインは、"スキルセット" を含む "インデクサー" で構成されます。 インデックス作成の後で、インデックスのクエリを実行して結果を検証できます。
サポートされるデータ ソース内のデータのサブセットから始めます。 インデクサーとスキルセットの設計は、反復的なプロセスです。 代表的なデータ セットが小さいと作業が速くなります。
データへの接続が指定されているデータ ソースを作成します。
スキルセットを作成します。 プロジェクトが小さい場合を除き、Azure AI マルチサービス リソースをアタッチする必要があります。 ナレッジ ストアを作成する場合は、スキルセット内でそれを定義します。
検索インデックスを定義するインデックス スキーマを作成します。
インデクサーを作成して実行し、上記のすべてのコンポーネントをまとめます。 この手順では、データの取得、スキルセットの実行、インデックスの読み込みを行います。
インデクサーでは、検索インデックスへのデータ パスを設定するフィールド マッピングと出力フィールド マッピングも指定します。
必要に応じて、インデクサーの構成でエンリッチメント キャッシュを有効にします。 この手順により、後で既存のエンリッチメントを再利用できるようになります。
クエリを実行して結果を評価するか、デバッグ セッションを開始してスキルセットの問題を解決します。
上記の手順を繰り返す場合は、インデクサーを実行する前に リセット します。 または、実行ごとにオブジェクトを削除して再作成します (Free レベルを使用している場合は推奨)。 インデクサーのキャッシュを有効にした場合、ソースでデータが変更されていない場合、およびパイプラインに対する編集によってキャッシュが無効にされない場合は、インデクサーがキャッシュからプルされます。
次のステップ
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示