Microsoft Syntexの説明の種類
適用対象: ✓ 非構造化ドキュメント処理
説明は、Microsoft Syntexの非構造化ドキュメント処理モデルでラベル付けおよび抽出する情報を定義するのに役立ちます。 説明を作成するときに、説明の種類を選択する必要があります。 この記事では、さまざまな種類の説明とその使用方法の詳細について説明します。
![3 つの説明の種類を示す [説明の作成] パネルのスクリーンショット。](../media/content-understanding/explanation-types.png)
説明の種類には、次のものがあります。
語句リスト: 抽出する文書または情報で使用できる単語、語句、数字、その他の文字の一覧です。 たとえば、委託医師の文字列は、指定したすべての医療紹介文書に存在します。 または、識別しているすべての医療紹介文書から、委託医師の電話番号を抽出できます。
正規表現: パターン マッチングの表記を使用して、特定の文字パターンを検索します。 たとえば、正規表現を使用して、一連のドキュメント内のメール アドレス パターンのすべてのインスタンスを検索できます。
類似性: 説明が他の説明とどの程度相互に近いかについて説明します。 たとえば、 番地の語句 リストは 番地名 フレーズ リストのすぐ前に表示され、間にトークンはありません (この記事の後半でトークンについて学習します)。 近接型を使用するには、モデルに少なくとも 2 つの説明が必要です。そうでない場合、オプションは無効になります。
語句リスト
通常、語句リストの説明の種類は、モデルを介してドキュメントを識別して分類するために使用されます。 委託医師のラベルの例に記載されているように、指定した文書に常に含まれる単語、語句、数字、または文字の文字列です。
必須ではありませんが、キャプチャしている語句が文書内の一貫した場所にある場合は、説明をうまく行うことができます。 たとえば、委託医師のラベルは、文書の最初の段落に常に保存されている場合があります。 また、[ドキュメント内の語句の位置を構成する] 詳細設定を使用して、特にドキュメント内の複数の場所に語句がある可能性がある場合、語句を配置する特定のエリアを選択することができます。
ラベルを特定する際に大文字と小文字が区別される必要がある場合は、語句リストの種類を使用して、[文字の 大文字のみ を選択する] チェックボックスをオンにして、テキストの種類を指定します。

語句の種類は、日付、電話番号、クレジットカード番号など、さまざまな形式の情報を特定して抽出する説明を作成する場合に特に有効です。 たとえば、日付をさまざまな形式で表示できます (1/1/2020、1-1-2020、01/01/20、01/01/2020、Jan 1、2020 など)。 語句一覧を定義すると、指定して抽出するデータのバリエーションをキャプチャして、説明をより効率的にすることができます。
電話番号の例では、モデルが識別するすべての医療紹介文書から、委託する各医師の電話番号を抽出します。 説明を作成する場合は、電話番号が表示されるさまざまな形式を文書に入力し、可能なバリエーションをキャプチャできるようにします。
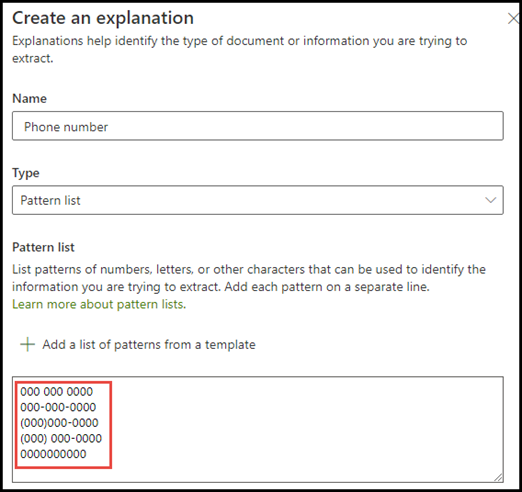
この例では、詳細設定 で [0〜9 の任意の数字] チェックボックスを選択して、語句一覧で使用されている各 "0" の値が 0〜9 の任意の数字であることを認識します。

同様に、テキスト文字を含む語句一覧を作成する場合は、[a-zから任意の文字] チェックボックスを選択して、語句一覧で使用される各 "a" 文字が "a" から "z" までの任意の文字であることを認識します。
たとえば、 日付 の語句一覧を作成した場合、 2020年1月1日などの日付形式が認識されるようにするには、次の操作を行う必要があります。
- aaa 0, 0000aaa 00, 0000 を語句一覧に追加します。
- a-z の の任意の文字 が選択されていることを確認します。

語句一覧に大文字と小文字の区別をする要件がある場合は、[大文字のみを区別する] チェックボックスをオンにできます。 日付の例では、月の最初の文字を大文字にする必要がある場合、次の操作を行う必要があります。
- Aaa 0, 0000および Aaa 00, 0000 を語句一覧に追加します。
- すべて大文字のみが選択されていることを確認してください。

注:
語句一覧の説明を手動で作成する代わりに、説明ライブラリを使用して、共通語句一覧に語句一覧テンプレート (日付、 電話番号、クレジット カード番号など) を使用します。
正規表現
正規表現の説明の種類を使用すると、ドキュメント内の特定の文字列を見つけて識別するのに役立つパターンを作成できます。 正規表現を使用すると、大量のテキストをすばやく解析して次のことができます。
- 特定の文字パターンを見つけます。
- テキストを検証して、事前定義されたパターン (メール アドレスなど) と一致することを確認します。
- 部分文字列を抽出、編集、置換、または削除します。
正規表現の種類は、メール アドレス、銀行口座番号、URL など、同様の形式の情報を特定して抽出する説明を作成する場合に特に有効です。 たとえば、 megan@contoso.comなどのメール アドレスは特定のパターンで表示されます ("megan" は最初の部分、"com" は最後の部分)。
メール アドレスの正規表現は、[A-Za-z0-9._%-]+@[A-Za-z0-9.-]+.[A-Za-z]{2,6} です。
この式は、次の順序の 5 つの部分から構成されます。
次の任意の長さの文字:
a. a から z までの文字
b. 0 から 9 までの番号
c. ピリオド、アンダースコア、パーセント、ダッシュ
@ 記号
任意の長さのメール アドレスの最初の部分と同じ文字
ピリオド 1 つ
2 文字から 6 文字
正規表現の説明を追加するには、次のように入力します。
[説明の作成] パネルの [説明の種類] で [正規表現] を選択します。
![[正規表現] が選択された [説明の作成] パネルを示すスクリーンショット。](../media/content-understanding/create-regular-expression.png)
[正規表現] テキスト ボックスに式を入力するか、[テンプレートから正規表現を追加] を選択できます。
テンプレートを使用して正規表現を追加すると、名前と正規表現がテキスト ボックスに自動的に追加されます。 たとえば、Email アドレス テンプレートを選択すると、[説明の作成] パネルが表示されます。
![[メール アドレス] テンプレートが適用された [説明の作成] パネルを示すスクリーンショット。](../media/content-understanding/create-regular-expression-email.png)
制限事項
次の表は、正規表現パターンで現在使用できないインライン文字オプションを示しています。
| オプション | 状態 | 最新機能 |
|---|---|---|
| 大文字と小文字の区別 | 現時点ではサポートされていません。 | 実行されるすべての一致では、大文字と小文字が区別されません。 |
| ライン アンカー | 現時点ではサポートされていません。 | 一致する必要がある文字列内の特定の位置を指定できません。 |
類似性
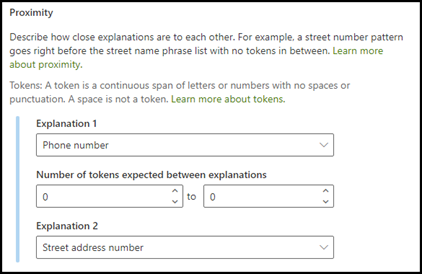
類似性の説明タイプは、モデルが他のデータがどの程度自分と似ているかを定義することで、データを特定するのに役立ちます。 たとえば、モデルでは、顧客にラベルを付けるために、番地と電話番号の 2 つの説明を定義しました。
お客様の電話番号は番地の前に常に表示されることに注意してください。
Alex Wilburn
555-555-5555
One Microsoft Way
Redmond, WA 98034
[類似性の説明を使用して、ドキュメント中の住所の番地をうまく特定するには、電話番号の説明はあまりに類似性が低いことを定義します。
注:
現在、近接通信の説明の種類では正規表現を使用できません。
トークンとは?
類似性の説明の種類を使用するには、トークンが何かを理解する必要があります。 トークンの数は、ある説明から別の説明への距離を、類似性の説明がどのように測定しているかを表しています。 トークンは、文字と数字を連続しているスパン (スペースや句読点を含まない) です。
次の表は、語句の中のトークン数を決定する方法の例を示しています。
| 語句 | トークン数 | 説明 |
|---|---|---|
Dog |
1 | 句読点やスペースを含まない1つの単語。 |
RMT33W |
1 | レコードロケーター番号。 数字と文字が含まれる場合がありますが、区切り記号はありません。 |
425-555-5555 |
5 | 電話番号 句読点はそれぞれ1つのトークンなので、425-555-5555 は、5 トークンとなります。425-555-5555 |
https://luis.ai |
7 | https://luis.ai |
類似性の説明の種類を構成する
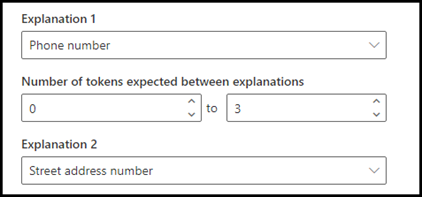
この例では、[類似性] 設定を構成して、番地の説明から電話番号の説明のトークン数の範囲を定義します。 電話番号と住所の番地の間にトークンがないため、最小範囲が "0" であることがわかります。
ただし、サンプルドキュメントの一部の電話番号には、接頭語 (mobile) が追加されています。
Nestor Wilke
111-111-1111 (モバイル)
One Microsoft Way
Redmond, WA 98034
(モバイル)には次の3つのトークンがあります。
| 語句 | トークン数 |
|---|---|
| ( | 1 |
| モバイル | 2 |
| ) | 3 |
0から3までの範囲を設定するには、[類似性] 設定を構成します。
ドキュメント内の語句の位置を構成する
説明を作成すると、既定でドキュメント全体から抽出しようとしている語句が検索されます。 ただし、[これらの語句が表示される場所] の詳細設定を使用すると、語句が表示されるドキュメント内の特定の場所を特定するのに役立ちます。 この設定は、ドキュメント内の別の場所に語句の類似のインスタンスが表示される可能性があり、正しいインスタンスが選択されていることを確認する場合に役立ちます。
医療紹介文書の例を参照すると、委託医師は常にドキュメントの第 1 段落に記載されています。 この例では、[これらの語句が表示される場所] の設定を使用して、このラベルをドキュメントの先頭部分、またはラベルが表示される可能性のあるその他の場所だけで検索するように説明を構成できます。
![[これらの語句が表示される場所] の設定。](../media/content-understanding/phrase-location.png)
この設定では、次のオプションを選択できます。
ファイル内の任意の場所: ドキュメント全体で語句が検索されます。
ファイルの先頭: 文書は、最初から語句の場所まで検索されます。
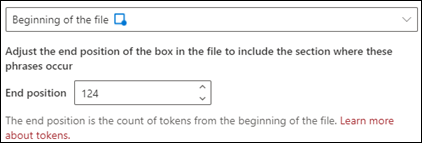
ビューアでは、フェーズが表示される場所を含めるように選択ボックスを手動で調整できます。 [終了位置] の値が更新され、選択した領域に含まれるトークンの数が表示されます。 [終了位置] の値を更新して、選択した領域を調整することもできます。
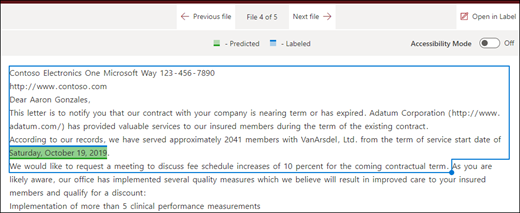
ファイルの末尾: ドキュメントの末尾から語句の場所まで検索されます。
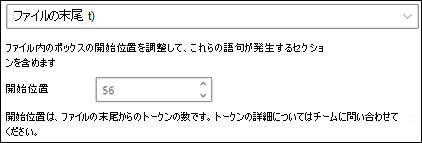
ビューアでは、フェーズが表示される場所を含めるように選択ボックスを手動で調整できます。 [開始位置] の値が更新され、選択した領域に含まれるトークンの数が表示されます。 [開始位置] の値を更新して、選択した領域を調整することもできます。

ユーザー設定の範囲: ドキュメントは指定された範囲内で、語句の場所が検索されます。
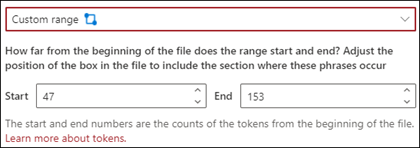
ビューアでは、フェーズが表示される場所を含めるように選択ボックスを手動で調整できます。 この設定では、[開始] と [終了] の位置を選択する必要があります。 これらの値は、ドキュメントの先頭のトークンの数を表します。 これらの値は手動で入力できますが、ビューアーの選択ボックスを手動で調整する方が簡単です。
説明を構成するときの考慮事項
分類子をトレーニングするときは、より予測可能な結果が得られるいくつかの点に留意する必要があります。
トレーニングするドキュメントが多いほど、分類子の精度が高くなります。 可能であれば、5 つ以上の適切なドキュメントを使用し、複数の不適切なドキュメントを使用します。 使用しているライブラリに複数の異なるドキュメントの種類がある場合、各種類のいくつかにより予測可能な結果が得られます。
ドキュメントのラベル付けは、トレーニング プロセスで重要な役割を果たします。 これらは、モデルのトレーニングに説明と共に使用されます。 分類子に多くのコンテンツが含まれていないドキュメントを使用して分類子をトレーニングすると、いくつかの異常が発生することがあります。 説明はドキュメント内の何とも一致しない場合がありますが、"良い" ドキュメントとしてラベルが付けられていたため、トレーニング中に一致している可能性があります。
説明を作成するときに、OR ロジックをラベルと組み合わせて使用して、一致するかどうかを判断します。 AND ロジックを使用する正規表現の方が予測しやすい場合があります。 実際のドキュメントをトレーニングする際に使用する正規表現の例を次に示します。 赤で強調表示されているテキストは、探している語句であることに注意してください。
(?=.*network provider)(?=.*participating providers).*
ラベルと説明は連携し、モデルのトレーニングに使用されます。 これは、結合解除できる一連のルールではなく、構成されている各変数に適用される正確な重みまたは予測です。 トレーニングで使用されるドキュメントのバリエーションが大きいほど、モデルの精度が向上します。