Azure AI Custom Translator を使用すると、ビジネス、業界、ドメインに固有の用語やスタイルを反映した翻訳システムを構築することができます。 カスタム システムのトレーニングとデプロイは簡単で、プログラミング スキルを必要としません。 カスタマイズされた翻訳システムは、既存のアプリケーション、ワークフロー、Web サイトにシームレスに統合され、毎日何十億もの翻訳を行うのと同じクラウドベースの Microsoft Text 翻訳 API サービスを通じて Azure で利用できます。
このプラットフォームを使用すると、ユーザーは英語との間のカスタム翻訳システムを構築して公開できます。 カスタム翻訳ツールでは、60 を超える言語がサポートされ、ニューラル機械翻訳 (NMT) で利用可能な言語に直接マップされています。 詳細な一覧については、「翻訳ツールの言語サポート」を "参照してください"。
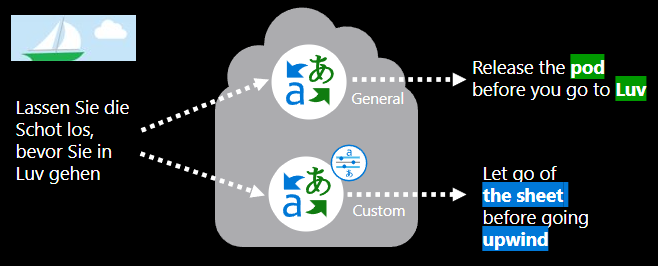
カスタム翻訳モデルが適切なケース
適切にトレーニングされたカスタム翻訳モデルは、以前に翻訳されたドメイン内のドキュメントを利用して優先される翻訳を学習するため、より正確なドメイン固有の翻訳を提供します。 Translator は、コンテキストに依存する文法を尊重しながら、これらの用語と語句をコンテキストで使用して、ターゲット言語で流暢な翻訳を生成します。
完全なカスタム翻訳モデルをトレーニングするには、大量のデータが必要です。 以前にトレーニング済みのドキュメントの文が少なくとも 10,000 件ない場合は、フル言語翻訳モデルをトレーニングできません。 ただし、辞書のみのモデルをトレーニングすることも、テキスト翻訳 API で使用できる高品質のすぐに使用できる翻訳を使用することもできます。
カスタム翻訳モデルのトレーニングに関連する要素
カスタム翻訳モデルを構築するには、次のことが必要です。
目的のユース ケースの理解。
ドメイン内の翻訳済みデータ (人間による翻訳が望ましい) の取得。
翻訳品質またはターゲット言語の翻訳を評価する。
目的のユース ケースを評価する方法
目的のユース ケースと何をもって成功とするかを明確化することは、精度の高いトレーニング データをソース化するための最初のステップです。 いくつかの考慮事項があります。
目的の結果は指定されているか、どのように測定するか。
ビジネス ドメインは特定されているか。
用語とスタイルが似ているドメイン内の文がありますか?
目的のユース ケースに複数のドメインが含まれますか? 含まれるなら、1 つの翻訳システムを構築するか、複数のシステムを構築する必要がありますか?
保存中と転送中の地域的データ所在地に影響を与える要件がありますか?
ターゲット ユーザーは 1 つのリージョンに存在しますか、複数のリージョンに存在しますか?
データをソース化する方法
ドメイン内の品質データの検索は、多くの場合、ユーザーの分類によって異なる困難なタスクです。 使用可能なデータを評価する場合に、次の点を検討できます。
会社に、使用可能な過去の翻訳データがありますか? 企業は多くの場合、長年にわたって人間の翻訳で蓄積された豊富な翻訳データを持っています。
膨大な量のモノリンガル データがありますか? モノリンガル データは、1 つの言語だけからなるデータです。 その場合、このデータの翻訳を入手できますか?
オンライン ポータルをクロールしてソース文を収集し、ターゲット文を合成できますか?
トレーニング資料に使用すべき素材
| ソース | 実行内容 | 従うべきルール |
|---|---|---|
| バイリンガル トレーニング ドキュメント | システムに用語とスタイルを教えます。 | 寛容に。 ドメイン内の人間による翻訳は、機械翻訳より優れています。 BLEU スコアの向上を試みながら、ドキュメントを追加または削除します。 |
| ドキュメントのチューニング | ニューラル機械翻訳パラメーターをトレーニングします。 | 厳密に。 今後翻訳する予定の内容を最適に表すように編成します。 |
| テスト ドキュメント | BLEU スコアを計算します。 | 厳密に。 今後翻訳する予定の文章を適切に代表するようにテスト ドキュメントを編成します。 |
| 句辞書 | 常に特定の訳語の使用を強制します。 | 限定的に。 句辞書では大文字と小文字が区別され、リストされている単語やフレーズが指定された方法で翻訳されます。 多くの場合、句辞書を使用せずに、システムに学習させることをお勧めします。 |
| 文辞書 | 常に特定の訳語の使用を強制します。 | 厳密に。 文辞書は、大文字と小文字が区別されず、ドメイン内でよく見られる短い文章に適しています。 文辞書との一致が成立するには、送信された文全体がソース辞書の項目と一致する必要があります。 文の一部のみが一致する場合、項目が一致したことにはなりません。 |
BLEU スコアとは
BLEU (Bilingual Evaluation Understudy) は、ある言語から別の言語に機械翻訳されたテキストの精度または正確性を評価するためのアルゴリズムです。 Azure AI Custom Translator では、翻訳精度を確認する 1 つの方法として BLEU メトリックを使用しています。
BLEU スコアは、0 から 100 の数値です。 スコアが 0 の場合、リファレンスと全く一致しない低品質の翻訳を示します。 スコアが 100 の場合、リファレンスと完全に一致する完全な翻訳を示します。 スコアを 100 にする必要はありません。BLEU スコアが 40 から 60 の範囲であれば高品質な翻訳であることを示しています。
チューニング データやテスト データを指定しない場合
チューニング文やテスト文とは、今後翻訳する予定の文章を適切に代表する文のことです。 ユーザーがチューニング データもテスト データも指定しない場合、Azure AI Custom Translator がトレーニング ドキュメントから文を自動的に除外して、チューニング データおよびテスト データとして使用します。
| システム生成 | 手動選択 |
|---|---|
| 便利。 | 将来のニーズに合わせて微調整可能。 |
| トレーニング データが翻訳する予定の文を代表していることがわかっている場合、良好。 | トレーニング データを作成する自由度が高い。 |
| ドメインを拡大または縮小する際に再実行しやすい。 | より多くのデータを使用でき、ドメイン カバレッジも向上可能。 |
| トレーニング実行ごとに変化。 | トレーニング実行を繰り返しても静的に維持。 |
Azure AI Custom Translator によるトレーニング マテリアルの処理のしくみ
トレーニングに備えるために、ドキュメントには一連の処理とフィルタリングが適用されます。 フィルター処理に関する知識は、Azure AI Custom Translator を使用してトレーニングするためのトレーニング ドキュメントの準備に必要な手順だけでなく、表示される文の数を理解するのにも役立ちます。 フィルター処理の手順は次のとおりです。
文の配置
ドキュメントが
XLIFF、XLSX、TMX、またはALIGN形式ではない場合、Azure AI Custom Translator によって、ソース ドキュメントとターゲット ドキュメントの文が、相互に文ごとに配置されます。 カスタム翻訳ツールでは、ドキュメントの配置は実行されません。このツールは、そのドキュメントの名前付け規則に従って、もう一方の言語の一致するドキュメントを検出します。 Azure AI Custom Translator は、ターゲット言語の対応する文の検出をソース テキスト内で試みます。 配置のために、埋め込まれた HTML タグのようなドキュメント マークアップが利用されています。ソース ドキュメントとターゲット ドキュメントに含まれる文の数が大きく異なる場合、ソース ドキュメントの並置や配置を行えない場合があります。 それぞれの側で文の大きな違い (>10%) があるドキュメントのペアでは、並列したドキュメントであることを確認するために 2 回目の見直しが必要です。
チューニングとテスト データの抽出
チューニング データやテスト データは省略可能です。 指定しない場合、システムがトレーニング ドキュメントから適切な割合を削除して、チューニングとテストに使用します。 この削除は、トレーニング プロセスの一部として動的に行われます。 このステップはトレーニングの一環として行われるので、アップロードされたドキュメントには影響しません。 最終的に使用されたデータのカテゴリ (トレーニング、チューニング、テスト、ディクショナリ) ごとの文の数は、トレーニングの終了後に [モデルの詳細] ページで確認できます。
長さフィルター
- どちらかの側の、1 語のみの文を削除します。
- どちらかの側の、100 語を超える文を削除します。 中国語、日本語、韓国語には適用されません。
- 3 文字未満の文を削除します。 中国語、日本語、韓国語には適用されません。
- 中国語、日本語、韓国語の 2,000 文字を超える文を削除します。
- 英数字が 1% 未満の文を削除します。
- 50 語より多くを含む辞書エントリを削除します。
空白
- タブや CR/LF シーケンスを含む空白文字のシーケンスを単一の空白文字に置き換えます。
- 文の先頭または末尾のスペースを削除します。
文末の句点
文末の複数の句読点文字を単一のインスタンスに置き換えます。 日本語の文字の正規化。
全角の文字と数字を半角文字に変換します。
エスケープされていない XML タグ
エスケープされていないタグをエスケープされたタグに変換します。
タグ 変換後 < < > > &;; & 無効な文字
Azure AI Custom Translator では、Unicode 文字 U+FFFD を含む文が削除されます。 文字 U+FFFD は、エンコード変換が失敗したことを示します。
データをアップロードする前に行うべき手順
- エンコードが無効な文を削除します。
- Unicode 制御文字を削除します。
- 可能な場合は、(ソース ターゲット間で) 文を揃えます。
- ソースとターゲットの言語と一致しないソース文とターゲット文を削除します。
- ソース文とターゲット文に言語が混在している場合は、翻訳されていない単語が意図的なもの (組織名や製品名など) であることを確認します。
- 文法と文字体裁が正しいことを確認して、モデルに間違いを教えないようにします。
- 1 つのソース文を 1 つのターゲット文にマップします。 トレーニング プロセスでは、複数の文を含むソース行とターゲット行が処理されますが、1 対 1 のマッピングがベスト プラクティスです。
結果の評価方法
モデルが正常にトレーニングされると、モデルの BLEU スコアとベースライン モデル BLEU スコアをモデルの詳細ページで確認できます。 モデルの BLEU スコアとベースライン モデル BLEU スコアを生成するために使用されるテスト データのセットは同じです。 このデータは、目的のユース ケースに適したモデルについて十分な情報を得たうえでの決定を行うのに役立ちます。