Azure AI Search でのベクトル ストレージ
Azure AI 検索には、ベクトル検索とハイブリッド検索用のベクトル ストレージと構成が用意されています。 サポートはフィールド レベルで実装されます。つまり、同じ検索コーパスでベクトル フィールドと非ベクトル フィールドを組み合わせることができます。
ベクトルは検索インデックスに格納されます。 Create Index REST API または同等の Azure SDK メソッドを使用して、ベクトル ストアを作成します。
ベクトル ストレージの主な考慮事項は以下のとおりです。
- 目的とするベクトル取得パターンに基づいて、ユース ケースに合うスキーマを設計します。
- インデックス サイズを見積もり、検索サービスの容量を確認します。
- ベクトル ストアを管理する
- ベクトル ストアをセキュリティで保護する
ベクトル取得パターン
Azure AI Search には、検索結果を操作するための 2 つのパターンがあります。
生成検索。 言語モデルは、Azure AI Search のデータを使用して、ユーザーのクエリに対する応答を作成します。 このパターンには、プロンプトを調整し、コンテキストを維持するためのオーケストレーション レイヤーが含まれます。 このパターンでは、検索結果はプロンプト フローにフィードされ、GPT や Text-Davinci などのチャット モデルが受け取ります。 このアプローチは、検索インデックスによってグラウンド データが提供される取得拡張生成 (RAG) アーキテクチャに基づいています。
検索バー、クエリ入力文字列、レンダリングされた結果を使用した従来の検索。 検索エンジンによって、ベクトル クエリが受け入れられて実行され、応答が作成されます。ユーザーはそれらの結果をクライアント アプリにレンダリングします。 Azure AI Search では、結果はフラット化された行セットで返され、検索結果を含めるフィールドを選ぶことができます。 チャット モデルがないため、応答で人間が判読できる非ベクトル コンテンツをベクトル ストア (検索インデックス) に設定することが期待されます。 検索エンジンはベクトルに一致しますが、非ベクトル値を使用して検索結果を設定する必要があります。 ベクトル クエリとハイブリッド クエリは、従来の検索シナリオ用に作成できるクエリ要求の型に対応します。
インデックス スキーマには、主なユース ケースが反映されている必要があります。 次のセクションでは、生成 AI と従来の検索用に構築されるソリューションのフィールド構成の違いに着目します。
ベクトル ストアのスキーマ
ベクトル ストアのインデックス スキーマには、名前、キー フィールド (文字列)、1 つ以上のベクトル フィールド、およびベクトル構成が必要です。 非ベクトル フィールドは、ハイブリッド クエリ、または言語モデルを通過する必要のない、人間が読み取り可能な逐語的なコンテンツを返す場合に推奨されます。 ベクトル構成の手順については、「ベクトル ストアを作成する」を参照してください。
基本的なベクトル フィールドの構成
ベクトル フィールドは、データ型とベクトル固有のプロパティによって区別されます。 フィールド コレクション内のベクトル フィールドの外観を以下に示します。
{
"name": "content_vector",
"type": "Collection(Edm.Single)",
"searchable": true,
"retrievable": true,
"dimensions": 1536,
"vectorSearchProfile": "my-vector-profile"
}
ベクトル フィールドには、特定のデータ型があります。 現在、Collection(Edm.Single) が最も一般的ですが、狭いデータ型を使用するとストレージを節約できます。
ベクトル フィールドは検索可能で取得可能である必要がありますが、フィルター可能、ファセット可能、並べ替え可能にすることはできません。また、アナライザー、ノーマライザー、シノニム マップの割り当てを持つことはできません。
ベクトル フィールドでは、埋め込みモデルによって生成される埋め込みの数に dimensions を設定する必要があります。 たとえば、text-embedding-ada-002 では、テキストのチャンクごとに 1,536 個の埋め込みが生成されます。
ベクトル フィールドには、"ベクトル検索プロファイル" によって示されるアルゴリズムを使用してインデックスが作成されます。このプロファイルはインデックス内の他の場所で定義されているため、例では示されていません。 詳細については、ベクトル検索の構成に関するページを参照してください。
基本的なベクトル ワークロードのフィールド コレクション
ベクトル ストアでは、ベクトル フィールド以外にもさらにフィールドが必要です。 たとえば、キー フィールド (この例では "id") はインデックス要件です。
"name": "example-basic-vector-idx",
"fields": [
{ "name": "id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "key": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": null },
{ "name": "content", "type": "Edm.String", "searchable": true, "retrievable": true, "analyzer": null },
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": true, "facetable": true }
]
"content" フィールドなどの他のフィールドでは、人間が判読できる "content_vector" フィールドと同等のものが提供されます。 応答の作成専用の言語モデルを使用している場合は、非ベクトル コンテンツ フィールドを省略できますが、クライアント アプリに検索結果を直接プッシュするソリューションには非ベクトル コンテンツが必要です。
メタデータ フィールドは、特にメタデータにソース ドキュメントに関する配信元情報が含まれている場合に、フィルターに役立ちます。 ベクトル フィールド上で直接フィルター処理を行うことはできませんが、ベクトル クエリの実行前または実行後にフィルター処理を行うプリフィルター モードまたはポストフィルター モードを設定することができます。
データのインポートとベクトル化ウィザードによって生成されるスキーマ
評価と概念実証のテストには、データのインポートとベクトル化ウィザードをお勧めします。 ウィザードによって、このセクションのスキーマ例が生成されます。
このスキーマの偏りは、検索ドキュメントがデータ チャンクを中心に構築されていることです。 RAG アプリで一般的なように、言語モデルが応答を作成する場合は、データ チャンクを中心に設計されたスキーマが必要です。
データ チャンクは、言語モデルの入力制限内を維持するために必要ですが、複数の親ドキュメントからプルされたコンテンツの小さなチャンクに対してクエリを照合できる場合の類似性検索の精度も向上します。 最後に、セマンティック ランカーを使用している場合、セマンティック ランカーにはトークン制限もあります。これは、データ チャンクがアプローチの一部である場合に、より簡単に満たされます。
次の例では、検索ドキュメントごとに 1 つのチャンク ID、チャンク、タイトル、ベクトル フィールドがあります。 blob メタデータ (パス) の base 64 エンコードを使用して、chunkID と親 ID がウィザードによって設定されます。 チャンクとタイトルは、BLOB コンテンツと BLOB 名から派生します。 ベクトル フィールドのみが完全に生成されます。 これは、ベクトル化されたバージョンのチャンク フィールドです。 埋め込みは、指定した Azure OpenAI 埋め込みモデルを呼び出すことによって生成されます。
"name": "example-index-from-import-wizard",
"fields": [
{"name": "chunk_id", "type": "Edm.String", "key": true, "searchable": true, "filterable": true, "retrievable": true, "sortable": true, "facetable": true, "analyzer": "keyword"},
{ "name": "parent_id", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": true},
{ "name": "chunk", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true, "sortable": false},
{ "name": "title", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": false},
{ "name": "vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "vector-1707768500058-profile"}
]
RAG アプリとチャットスタイル アプリのスキーマ
生成検索用のストレージを設計する場合は、インデックスを作成してベクトル化した静的コンテンツに対して個別のインデックスを作成し、プロンプト フローで使用できる会話用に 2 つ目のインデックスを作成できます。 以下のインデックスは、chat-with-your-data-solution-accelerator アクセラレータから作成されます。

生成検索エクスペリエンスをサポートするチャット インデックスのフィールド:
"name": "example-index-from-accelerator",
"fields": [
{ "name": "id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "my-vector-profile"},
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "title", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "facetable": true },
{ "name": "source", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true },
{ "name": "chunk", "type": "Edm.Int32", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "offset", "type": "Edm.Int32", "searchable": false, "filterable": true, "retrievable": true }
]
オーケストレーションとチャット履歴をサポートする会話インデックスのフィールド:
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": false },
{ "name": "conversation_id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "default-profile" },
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "type", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "user_id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "sources", "type": "Collection(Edm.String)", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "created_at", "type": "Edm.DateTimeOffset", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "updated_at", "type": "Edm.DateTimeOffset", "searchable": false, "filterable": true, "retrievable": true }
]
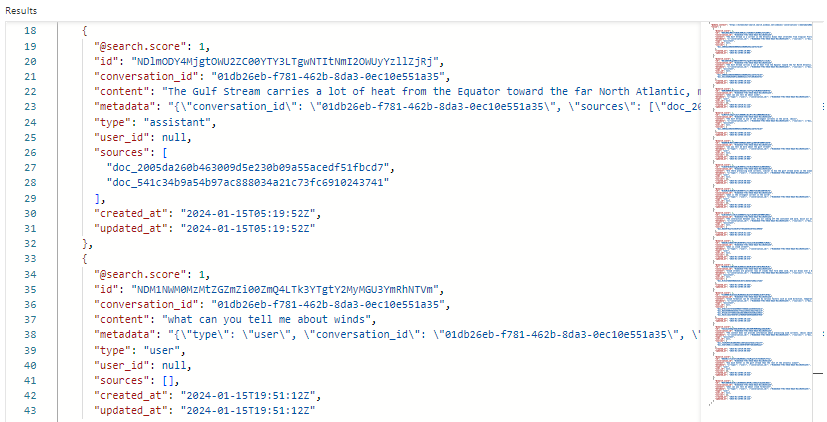
次に示すのは、Search Explorer における会話インデックスの検索結果のスクリーンショットです。 検索に条件がないため、検索スコアは 1.00 となっています。 オーケストレーションとプロンプト フローをサポートするために存在するフィールドに注目してください。 会話 ID は、特定のチャットを特定します。 "type" は、コンテンツがユーザーとアシスタントのどちらからのものであるかを示します。 日付は、古さによって履歴からチャットを削除するために使用されます。
物理的な構造とサイズ
Azure AI Search におけるインデックスの物理的な構造は、主に内部実装です。 そのスキーマへのアクセス、その内容の読み込みとクエリ実行、そのサイズの監視、容量の管理を行うことはできますが、クラスター自体 (転置およびベクトルのインデックス) とその他のファイルとフォルダーは、Microsoft によって内部的に管理されます。
インデックスのサイズと内容は、以下によって決まります。
- ドキュメントの数量と構成
- 個々のフィールドの属性。 たとえば、フィルター処理可能なフィールドにはより多くのストレージが必要です。
- 類似性検索に HNSW と網羅的 KNN のどちらを選択するかに基づくインデックス構成 (内部的なナビゲーション構造がどのように作成されるかを指定するベクトル構成を含む)。
Azure AI 検索はベクトル ストレージに制限を課しており、これは、すべてのワークロードにとってバランスのとれた安定したシステムを維持するのに役立ちます。 利用者が制限の範囲内に留まるのを手助けするために、ベクトルの使用状況は Azure portal においてと、サービスとインデックスの統計情報を使用したプログラム的な方法とで個別に追跡され報告されます。
次に示すのは、1 つのパーティションと 1 つのレプリカで構成された S1 サービスのスクリーンショットです。 この特定のサービスには、平均して 1 つのベクトル フィールドを含む 24 個の小さなインデックスがあり、各フィールドは 1536 個の埋め込みで構成されています。 2 番目のタイルが示しているのは、ベクトル インデックスのクォータと使用状況です。 ベクトル インデックスは、各ベクトル フィールドに対して作成された内部的なデータ構造です。 そのため、ベクトル インデックスのストレージは常に、インデックス全体によって使用されるストレージの一部となります。 残りの部分は、その他の非ベクトル フィールドとデータ構造によって使用されます。

ベクトル インデックスの制限と見積もりについては別の記事でカバーされていますが、前もって強調しておくべき 2 つの点として、ストレージの最大値はサービス レベルによって異なるということと、検索サービスがいつ作成されたかによっても異なるということがあります。 同じレベルでも新しいサービスの方が、かなり多いベクトル インデックスの容量を持ちます。 このため、以下のアクションを行ってください。
検索サービスのデプロイ日を確認する。 2024 年 4 月 3 日より前に作成されている場合は、容量を増やすために新しい検索サービスを作成することを検討してください。
ベクトル ストレージ要件の変動が予想される場合、スケーラブルなレベルを選択する。 Basic レベルは、以前の検索サービスの 1 つのパーティションに固定されています。 柔軟性とパフォーマンスを向上させるには、Standard 1 (S1) 以降を検討するか、より高い制限や多くのパーティションを null 許容レベルで使用する新しい検索サービスを作成します。
基本的な操作と相互作用
このセクションでは、1 つのインデックスへの接続やセキュリティ保護など、ベクトルの実行時操作について紹介します。
Note
インデックスを管理する際、インデックスの移動やコピーに関して、ポータルや API のサポートはないことに注意してください。 代わりに、ユーザーは通常、アプリケーション デプロイ ソリューションを別の検索サービスでポイントする (同じインデックス名を使用している場合) か、名前を変更して現在の検索サービスにコピーを作成してからビルドします。
継続的に使用可能
インデックスは、最初のドキュメントのインデックスが作成されるとすぐにクエリで使用できますが、すべてのドキュメントのインデックスが作成されるまでは完全には機能しません。 内部的には、インデックスは複数のパーティションにわたって分散され、レプリカ上で実行されます。 物理インデックスは内部で管理されます。 論理インデックスはユーザーが管理します。
インデックスは継続的に使用可能であり、一時停止したり、オフラインにしたりすることはできません。 継続的な操作のために設計されているので、コンテンツの更新やインデックス自体への追加はリアルタイムで行われます。 その結果、要求がドキュメントの更新と一致する場合、クエリは一時的に不完全な結果を返す可能性があります。
ドキュメント操作 (更新または削除) や、現在のインデックスの既存の構造と整合性に影響しない変更 (新しいフィールドの追加など) に対しては、クエリの継続性が存在します。 構造上の更新 (既存のフィールドの変更) を行う必要がある場合は、通常、開発環境での削除と再構築のワークフローを使用して、または運用サービスでインデックスの新しいバージョンを作成することによってそれらが管理されます。
インデックスの再構築を避けるため、小規模な変更を行っている一部のお客様は、以前のバージョンと共存する新しいものを作成することによって、フィールドの "バージョン管理" を選択しています。 これは、時間の経過と共に、特にレプリケートに負荷のかかる運用環境のインデックスで、古いフィールドまたは古いカスタム アナライザー定義の形式の、孤立したコンテンツになります。 インデックス ライフサイクル管理の一部として、インデックスの計画更新に関する問題に対処することができます。
エンドポイント接続
ベクトルのインデックス作成とクエリ要求はすべて、インデックスを対象とします。 エンドポイントは、通常、次のいずれかになります。
| エンドポイント | 接続とアクセスの制御 |
|---|---|
<your-service>.search.windows.net/indexes |
インデックスのコレクションを対象とします。 インデックスを作成、一覧表示、または削除するときに使用します。 これらの操作には管理者権限が必要です。管理者 API キーまたは Search 共同作成者ロールを通じて使用できます。 |
<your-service>.search.windows.net/indexes/<your-index>/docs |
1 つのインデックスのドキュメント コレクションを対象とします。 インデックスまたはデータ更新に対してクエリを実行するときに使用します。 クエリには、読み取り権限で十分であり、クエリ API キーまたはデータ閲覧者ロールを通じて使用できます。 データ更新の場合は、管理者権限が必要です。 |
Azure AI 検索への接続方法
アクセス許可または API アクセス キーがあることを確認します。 既存のインデックスに対してクエリを実行する場合を除き、検索サービスのコンテンツを管理および表示するには、管理者権限または共同作成者ロールの割り当てが必要です。
Azure portal から開始します。 検索サービスを作成したユーザーは、[アクセス制御 (IAM)] ページを使用して他のユーザーにアクセスを許可するなど、検索サービスを表示および管理できます。
プログラムによるアクセスのために他のクライアントに移動します。 最初の手順としては、以下のクイックスタートとサンプルをお勧めします。
ベクトル データへのアクセスをセキュリティで保護する
Azure AI 検索では、データ暗号化、インターネットなしのシナリオ用のプライベート接続、Microsoft Entra ID を介した安全なアクセスのためのロールの割り当てが実装されています。 エンタープライズ セキュリティ機能の全容については、「Azure AI 検索のセキュリティ」で説明されています。
ベクトル ストアを管理する
Azure には、診断ログとアラートを含む監視プラットフォームが用意されています。 推奨するベスト プラクティスを次に示します。