Azure Monitor ログを使用したイベントの分析と視覚化
Azure Monitor ログでは、クラウド内でホストされているアプリケーションとサービスからテレメトリが収集および分析され、それらの可用性とパフォーマンスを最大限に高めるために役立つ分析ツールが提供されます。 この記事では、Azure Monitor ログでクエリを実行して分析情報を取得し、クラスター内の処理をトラブルシューティングする方法について説明します。 次のような一般的な質問に対応します。
- 正常性イベントをどのようにトラブルシューティングすればいいか。
- ノードがダウンするタイミングを知るにはどうすればいいか。
- 自分のアプリケーションのサービスが起動または停止されたかを知るにはどうすればいいか。
注意
この記事は最近、Log Analytics ではなく Azure Monitor ログという用語を使うように更新されました。 ログ データは引き続き Log Analytics ワークスペースに格納され、同じ Log Analytics サービスによって収集されて分析されます。 Azure Monitor のログの役割をより適切に反映させるために、用語を更新しています。 詳しくは、Azure Monitor の用語の変更に関するページをご覧ください。
Log Analytics ワークスペースの概要
Note
クラスター作成時に診断ストレージが既定で有効になっている場合は、Log Analytics ワークスペースを診断ストレージから読み取るように設定する必要があります。
Azure Monitor ログでは、Azure ストレージ テーブルやエージェントなどの管理対象リソースからデータを収集し、中央レポジトリで管理します。 それらのデータは分析、アラート、および視覚化、さらにエクスポートに使用できます。 Azure Monitor ログでは、イベント、パフォーマンス データ、またはその他のカスタム データがサポートされます。 診断の拡張機能を設定してイベントを集計する手順および Log Analytics ワークスペースを作成してストレージ内のイベントから読み取りを行う手順を確認して、データが確実に Azure Monitor ログに送信されるようにしてください。
Azure Monitor ログによってデータが受信されたら、Azure に用意されている管理ソリューション (パッケージ済みのソリューションまたは運用ダッシュボード) を使用して、さまざまなシナリオに合わせて受信データを監視します。 Service Fabric Analytics ソリューションとコンテナー ソリューションが含まれており、これらは Service Fabric クラスターを使用する際の診断と監視に最も関連性の高いソリューションです。 この記事では、ワークスペースを使って作成される、Service Fabric Analytics ソリューションを使用する方法について説明します。
Service Fabric Analytics ソリューションへのアクセス
Azure Portal で、Service Fabric Analytics ソリューションを作成したリソース グループに移動します。
リソースの [ServiceFabric<nameOfOMSWorkspace> ] を選択します。
Summary に、有効なソリューションごとのグラフ形式のタイルが表示されます (Service Fabric のタイルも含まれています)。 [Service Fabric] グラフをクリックして、Service Fabric Analytics ソリューションを継続します。
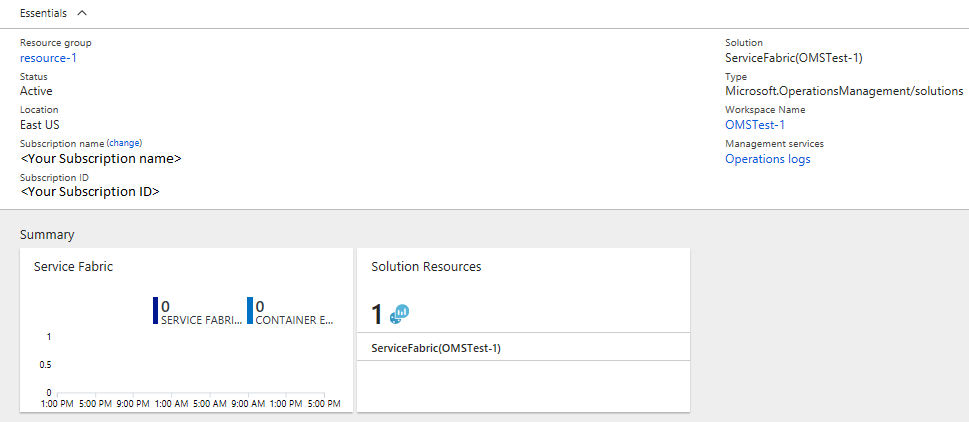
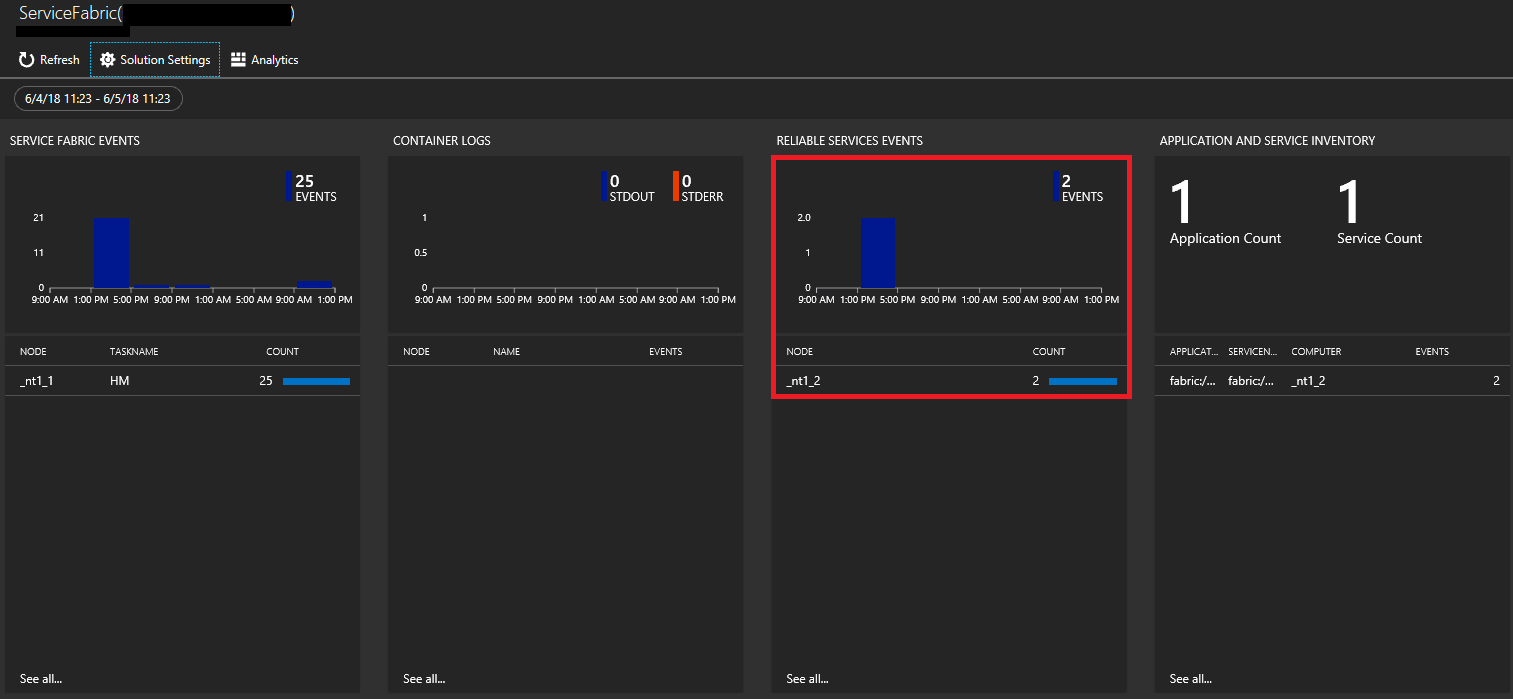
次の画像には、Service Fabric Analytics ソリューションのホーム ページが示されています。 このホーム ページでは、クラスター内で行われている処理のスナップショット ビューが提供されます。
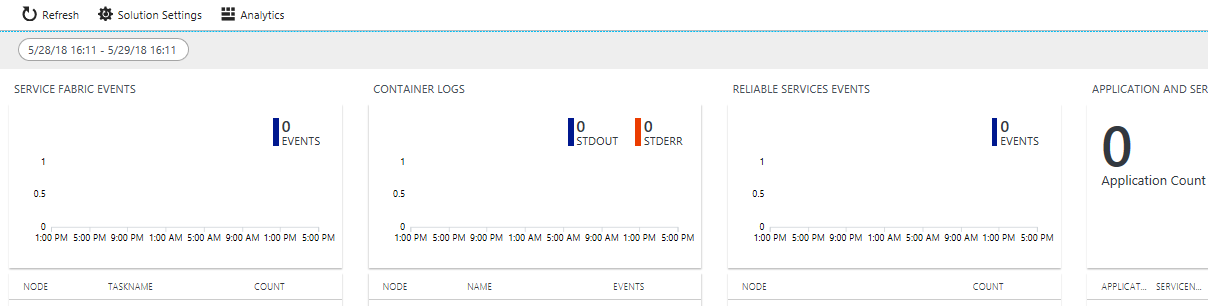
クラスター作成時に診断を有効にした場合は、以下に対するイベントが表示されます。
Note
診断の拡張機能の構成を更新することで、すぐに利用できる Service Fabric イベントだけでなく、より詳細なシステム イベントが収集できます。
ノードに対する操作を含む Service Fabric イベントを表示する
Service Fabric Analytics ページで、Service Fabric Events グラフをクリックします。
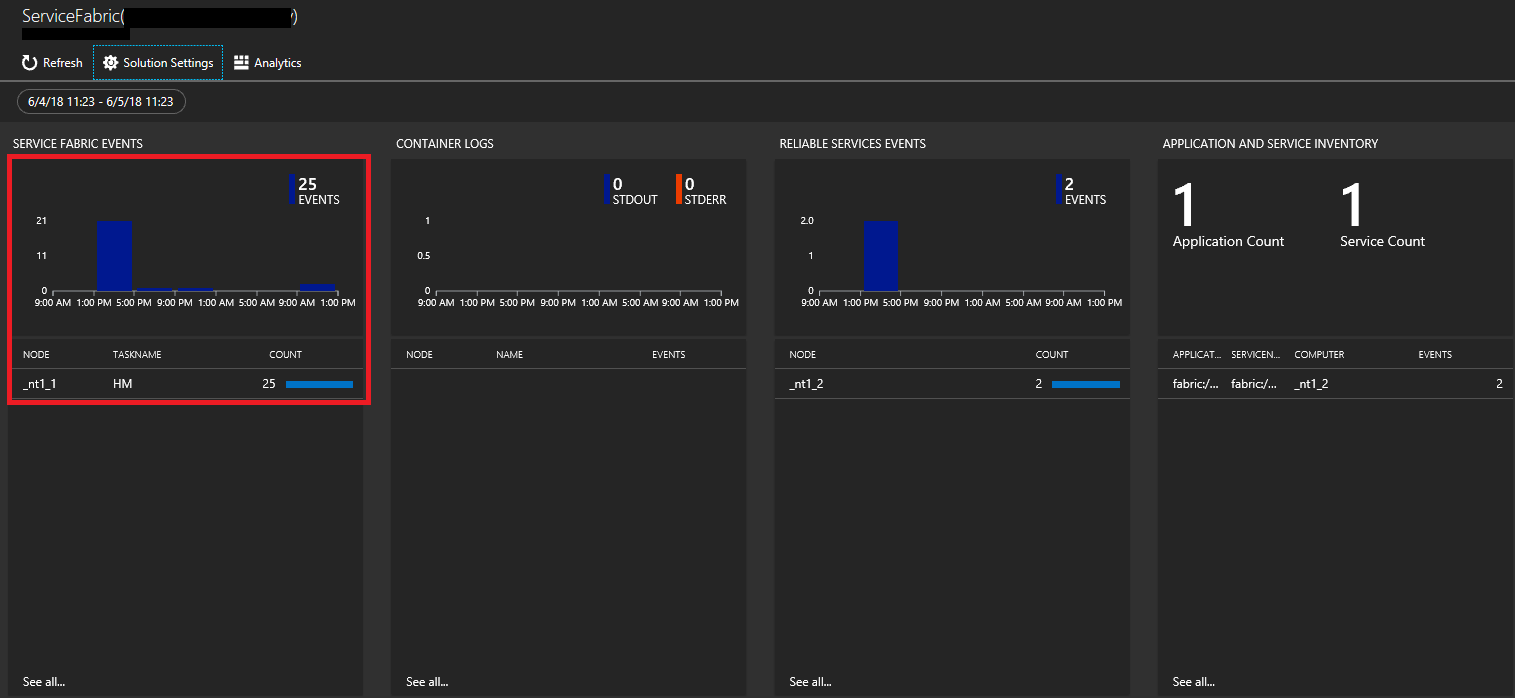
一覧内のイベントを表示するには、 [一覧] をクリックします。 ここで、収集済みのすべてのシステム イベントが表示されます。 参考までに、これらは Azure Storage アカウント内の WADServiceFabricSystemEventsTable に由来し、次に確認する Reliable Services イベントや Reliable Actors イベントも同様に、それぞれのテーブルに由来します。
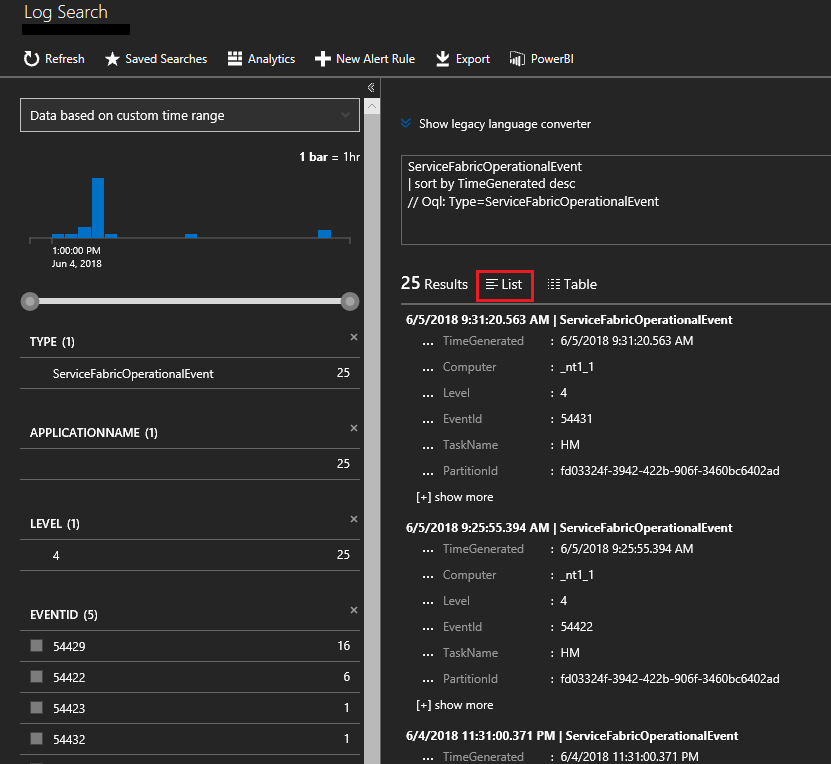
または、左側にある虫眼鏡をクリックし、Kusto クエリ言語を使って検索対象を見つけることもできます。 たとえば、クラスター内のノードに対して行われたすべての操作を検索するは、次のクエリを使用できます。 使用されているイベント ID は、操作チャネルのイベント リファレンスで確認できます。
ServiceFabricOperationalEvent
| where EventId < 25627 and EventId > 25619
特定のノード (Computer) やシステム サービス (TaskName) など、より多くのフィールドに対してクエリを実行できます。
Service Fabric Reliable Service および Actor イベントの表示
Service Fabric Analytics ページで、Reliable Services グラフをクリックします。
一覧内のイベントを表示するには、 [一覧] をクリックします。 ここで、Reliable Services のイベントを確認できます。 通常はデプロイおよびアップグレードで行われるサービス runasync の開始時点および完了時点に関する、さまざまなイベントを表示できます。
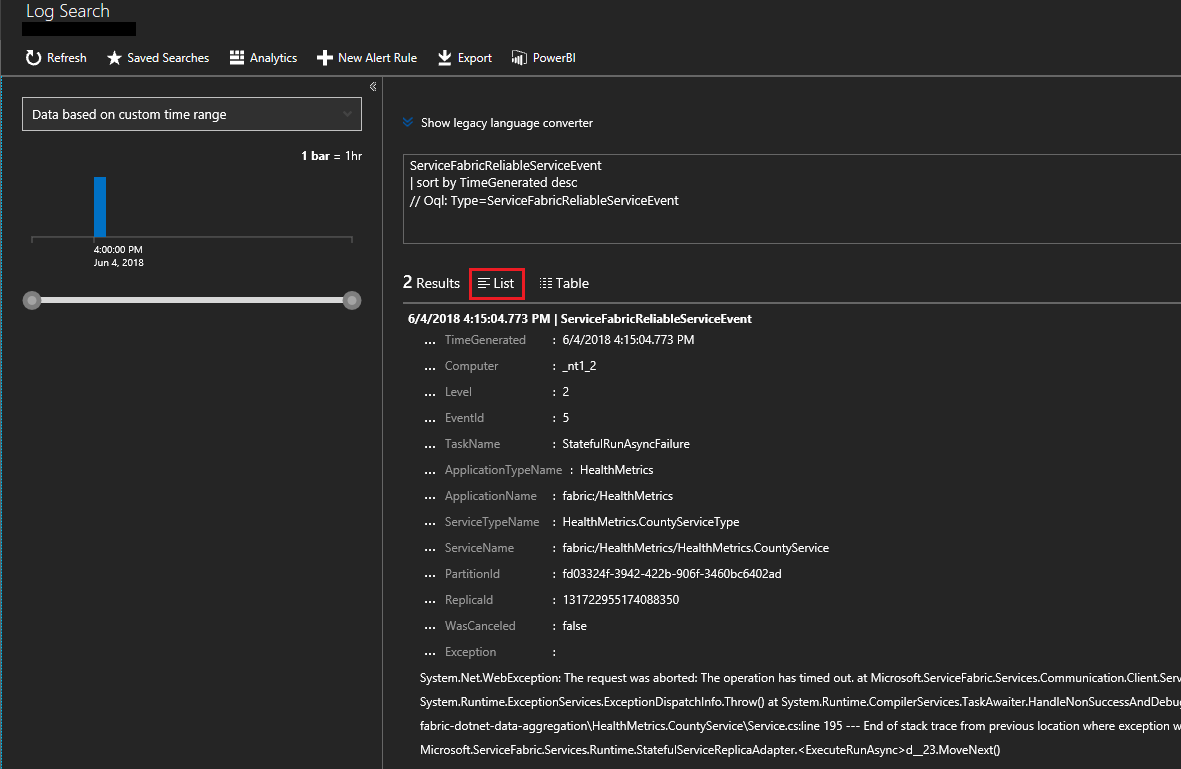
Reliable Actor のイベントも、同様の方式で表示できます。 Reliable Actor により詳細なイベントを設定するには、診断の拡張機能の構成 (以下に示します) で scheduledTransferKeywordFilter を変更する必要があります。 これらの値の詳細については、「Reliable Actors の診断とパフォーマンス監視」を参照してください。
"EtwEventSourceProviderConfiguration": [
{
"provider": "Microsoft-ServiceFabric-Actors",
"scheduledTransferKeywordFilter": "1",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricReliableActorEventTable"
}
},
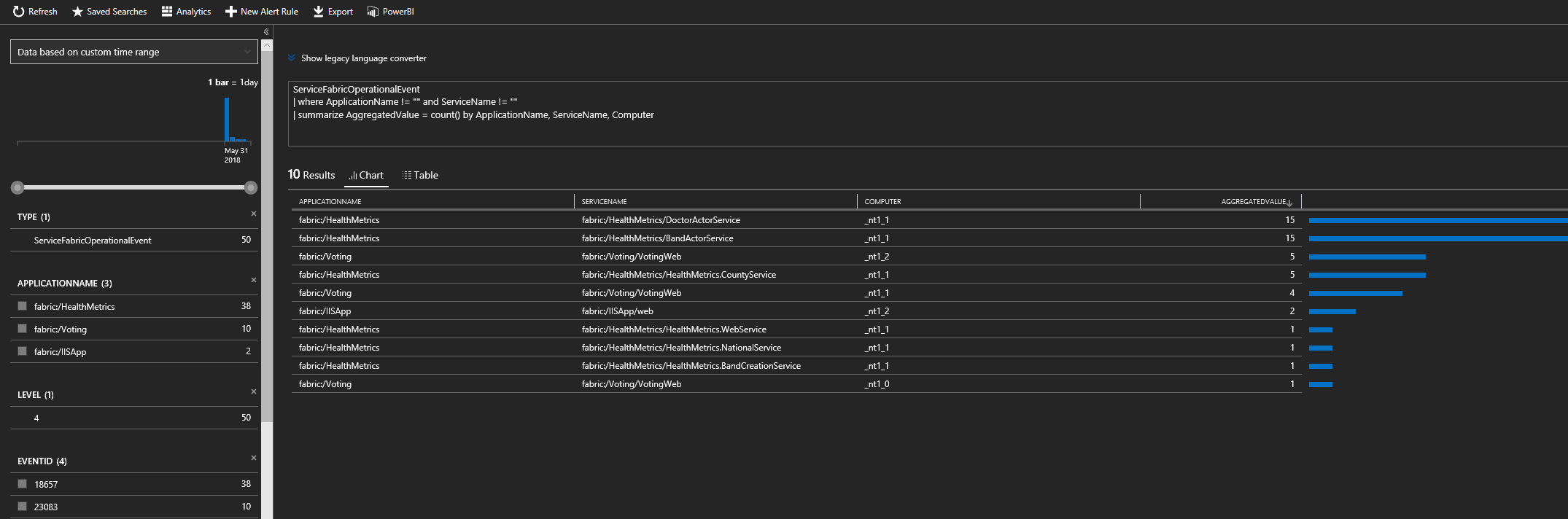
Kusto クエリ言語は優れています。 実行可能なもう 1 つの重要なクエリでは、どのノードで大部分のイベントが生成されているかを検出します。 次のスクリーン ショットのクエリは、特定のサービスとノードで集計された Service Fabric の操作イベントを示しています。
次のステップ
- インフラストラクチャの監視、つまりパフォーマンス カウンターを有効にするために、Log Analytics エージェントの追加に関するページにアクセスしてください。 エージェントによって、パフォーマンス カウンターが収集され、既存のワークスペースに追加されます。
- オンプレミス クラスター向けに、Azure Monitor ログでは、データを Azure Monitor ログに送信するために使用できるゲートウェイ (HTTP 転送プロキシ) を提供されています。 詳細については、「インターネットにアクセスできないコンピューターを Log Analytics ゲートウェイを使って Azure Monitor ログに接続する」を参照してください。
- 検出と診断に役立つ自動アラートを構成します。
- Azure Monitor ログの一部として提供されているログ検索とクエリ機能をよく理解します。
- Azure Monitor ログとそれが提供するサービスの詳しい概要について、Azure Monitor ログとは何かに関するページで確認します。
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示