Tip
Microsoft Fabric Data Warehouse は、将来のアーキテクチャ、組み込みの AI、および新機能を備えた、Data Lake 基盤上のエンタープライズ 規模のリレーショナル ウェアハウスです。 データ ウェアハウスを初めて使用する場合は、Fabric Data Warehouseから始めます。 既存の dedicated SQL プール ワークロードは、Fabric にアップグレードして、データ サイエンス、リアルタイム分析、レポートの新機能にアクセスできます。
- Fabric無料試用版を開始します。
- Fabric Data Warehouse 用マイグレーションアシスタント
この記事では、Azure Synapse Analytics の サーバーレス SQL プールを使用して、単一の CSV ファイルに対してクエリを実行する方法について説明します。 CSV ファイルには、次のようなさまざまな形式があります。
- ヘッダー行あり・なし
- コンマ区切りの値およびタブ区切りの値
- Windows スタイルおよび Unix スタイルの行の終わり
- 引用符なしと引用符付きの値、およびエスケープ文字
上記のすべてのバリエーションについては、以下で説明します。
クイック スタートの例
OPENROWSET 関数を使用すると、ファイルの URL を指定することによって、CSV ファイルの内容を読み取ることができます。
csv ファイルの読み取り
CSV ファイルの内容を確認する最も簡単な方法は、OPENROWSET 関数にファイルの URL を指定し、csv FORMAT および 2.0 PARSER_VERSION を指定することです。 ファイルが一般公開されている場合、または Microsoft Entra ID でこのファイルにアクセスできる場合は、次の例に示すようなクエリを使用して、ファイルの内容を表示することができます。
select top 10 *
from openrowset(
bulk 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
format = 'csv',
parser_version = '2.0',
firstrow = 2 ) as rows
オプション firstrow は、この場合のヘッダーを表す CSV ファイルの最初の行をスキップするために使用されます。 このファイルにアクセスできることを確認します。 ファイルが SAS キーまたはカスタム ID で保護されている場合は、 SQL ログイン用にサーバー レベルの資格情報を設定する必要があります。
重要
CSV ファイルに UTF-8 文字が含まれている場合は、UTF-8 データベース照合順序 ( Latin1_General_100_CI_AS_SC_UTF8 など) を使用していることを確認します。
ファイル内のテキスト エンコードと照合順序が一致しないと、予期しない変換エラーが発生する可能性があります。
現在のデータベースの既定の照合順序は、alter database current collate Latin1_General_100_CI_AI_SC_UTF8 という T-SQL ステートメントを使用して容易に変更できます。
データ ソースの使用状況
前の例では、ファイルへの完全なパスを使用しています。 別の方法として、ストレージのルート フォルダーを示す場所を持つ外部データ ソースを作成します。
create external data source covid
with ( location = 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases' );
データ ソースを作成したら、そのデータソースと OPENROWSET 関数のファイルへの相対パスを使用できます。
select top 10 *
from openrowset(
bulk 'latest/ecdc_cases.csv',
data_source = 'covid',
format = 'csv',
parser_version ='2.0',
firstrow = 2
) as rows
データ ソースが SAS キーまたはカスタム ID で保護されている場合は、 データベース スコープの資格情報を使用してデータ ソースを構成できます。
スキーマを明示的に指定する
OPENROWSET を使用すると、WITH 句によってファイルから読み取る列を明示的に指定できます。
select top 10 *
from openrowset(
bulk 'latest/ecdc_cases.csv',
data_source = 'covid',
format = 'csv',
parser_version ='2.0',
firstrow = 2
) with (
date_rep date 1,
cases int 5,
geo_id varchar(6) 8
) as rows
WITH 句のデータ型の後の数値は、CSV ファイル内の列インデックスを表します。
重要
CSV ファイルに UTF-8 文字が含まれている場合は、Latin1_General_100_CI_AS_SC_UTF8句のすべての列に対して一部の UTF-8 照合順序 (WITH など) を明示的に指定しているか、データベース レベルで UTF-8 照合順序を設定していることを確認してください。
ファイル内のテキスト エンコードと照合順序が一致しないと、予期しない変換エラーが発生する可能性があります。
現在のデータベースの既定の照合順序は、 という T-SQL ステートメントを使用して容易に変更できます。
alter database current collate Latin1_General_100_CI_AI_SC_UTF8
geo_id varchar(6) collate Latin1_General_100_CI_AI_SC_UTF8 8という定義を使用して、列の型に照合順序を簡単に設定できます。
次のセクションでは、さまざまな種類の CSV ファイルに対してクエリを実行する方法について説明します。
前提条件
最初の手順として、テーブルが作成されるデータベースを作成します。 次に、そのデータベースでセットアップ スクリプトを実行して、オブジェクトを初期化します。 このセットアップ スクリプトにより、データ ソース、データベース スコープの資格情報、これらのサンプルで使用される外部ファイル形式が作成されます。
Windows スタイルの改行
次のクエリは、CSV ファイル (ヘッダー行がなく、Windows スタイルの改行およびコンマ区切りの列を含む) を読み取る方法を示しています。
ファイル プレビュー:
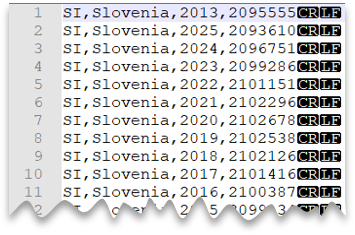
SELECT *
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
Unix スタイルの改行
次のクエリは、CSV ファイル (ヘッダー行がなく、Unix スタイルの改行およびコンマ区切りの列を含む) を読み取る方法を示しています。 他の例と比較して、ファイルの場所が異なることに注意してください。
ファイル プレビュー:
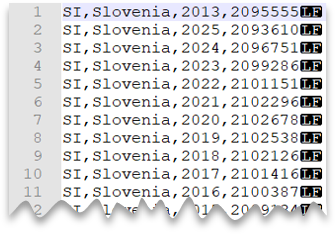
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
ヘッダー行
次のクエリは、CSV ファイル (ヘッダー行があり、Unix スタイルの改行およびコンマ区切りの列を含む) を読み取る方法を示しています。 他の例と比較して、ファイルの場所が異なることに注意してください。
ファイル プレビュー:
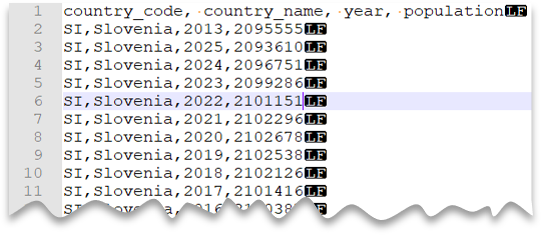
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
HEADER_ROW = TRUE
) AS [r]
オプション HEADER_ROW = TRUE を指定すると、ファイル内のヘッダー行から列名が読み取られます。 ファイル コンテンツに慣れていない場合は、探索目的に最適です。 最適なパフォーマンスについては、「 ベスト プラクティス」の「適切なデータ型を使用する」セクションを参照してください。 さらに、こちらで OPENROWSET 構文に関する詳細も参照できます。
カスタム引用符文字
次のクエリは、ファイル (ヘッダー行があり、Unix スタイルの改行、コンマ区切りの列、および引用符で囲まれた値を含む) を読み取る方法を示しています。 他の例と比較して、ファイルの場所が異なることに注意してください。
ファイル プレビュー:
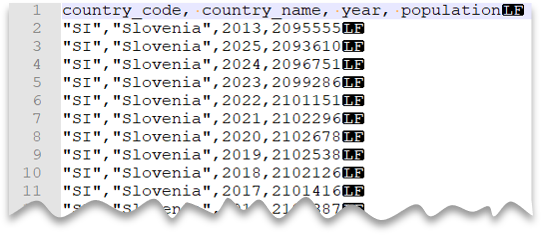
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-quoted/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2,
FIELDQUOTE = '"'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
注意
FIELDQUOTE の既定値は二重引用符であるため、このクエリでは、FIELDQUOTE パラメーターを省略した場合と同じ結果が返されます。
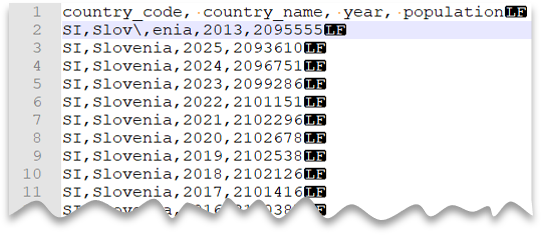
エスケープ文字
次のクエリは、ファイル (ヘッダー行があり、Unix スタイルの改行、コンマ区切りの列、および値内のフィールド区切り記号 (コンマ) に使用されるエスケープ文字を含む) を読み取る方法を示しています。 他の例と比較して、ファイルの場所が異なることに注意してください。
ファイル プレビュー:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-escape/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2,
ESCAPECHAR = '\\'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Slovenia';
注意
"Slov,enia" のコンマは国/地域名の一部ではなくフィールド区切り記号として扱われるので、ESCAPECHAR が指定されていない場合、このクエリは失敗します。 "Slov,enia" は 2 つの列として扱われます。 そのため、特定の行には、他の行よりも列が 1 つ多く存在し、WITH 句で定義した列数より 1 つ多くなります。
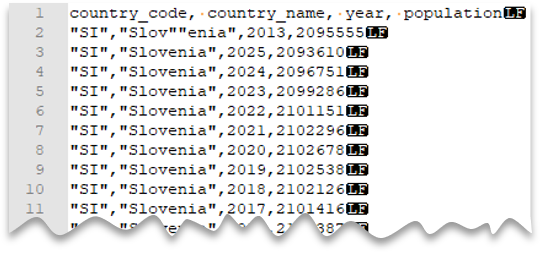
引用符文字のエスケープ
次のクエリは、ファイル (ヘッダー行があり、Unix スタイルの改行、コンマ区切りの列、および値内のエスケープされた二重引用符文字を含む) を読み取る方法を示しています。 他の例と比較して、ファイルの場所が異なることに注意してください。
ファイル プレビュー:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-escape-quoted/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Slovenia';
注意
引用文字は、別の引用文字でエスケープする必要があります。 引用文字は、値が引用文字で囲まれている場合にのみ、列の値の中で使用できます。
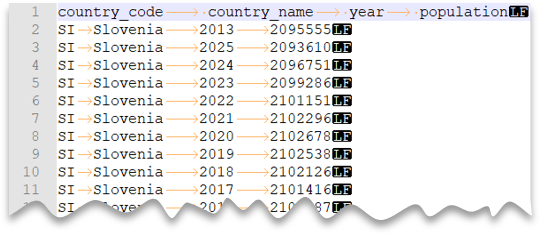
タブ区切りファイル
次のクエリは、ファイル (ヘッダー行があり、Unix スタイルの改行およびタブ区切りの列を含む) を読み取る方法を示しています。 他の例と比較して、ファイルの場所が異なることに注意してください。
ファイル プレビュー:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-tsv/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR ='\t',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017
列のサブセットを返す
ここまで、WITH を使用し、すべての列をリストして CSV ファイル スキーマを指定してきました。 クエリにおいて実際に必要な列だけを指定するには、必要な各列に対して序数を使用します。 また、関心のない列も省略します。
次のクエリでは、ファイル内の異なる国/地域名の数が返されます。これにより必要な列のみを指定できます。
注意
次のクエリ内の WITH 句を見てください。 [country_name] 列を定義した行の末尾に "2" (引用符はなし) があることがわかります。 これは、 [country_name] 列がファイル内の 2 番目の列であることを意味します。 このクエリでは、2 番目の列を除く、ファイル内のすべての列が無視されます。
SELECT
COUNT(DISTINCT country_name) AS countries
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
--[country_code] VARCHAR (5),
[country_name] VARCHAR (100) 2
--[year] smallint,
--[population] bigint
) AS [r]
追加可能なファイルに対するクエリの実行
クエリの実行中は、クエリで使用される CSV ファイルを変更しないでください。 長時間実行されるクエリでは、SQL プールによって読み取りが再試行されたり、ファイルの一部が読み取られたり、ファイルが複数回読み取られたりする場合もあります。 ファイル コンテンツを変更すると、結果が不正確になる可能性があります。 そのため、クエリの実行中にファイルの変更時刻が変更されていることが検出されると、SQL プールはクエリに失敗します。
場合によっては、継続的な追加が行われているファイルを読み取ることが必要になることがあります。 継続的な追加が行われているファイルが原因でクエリが失敗しないようにするために、OPENROWSET 関数で、ROWSET_OPTIONS の設定を使用して、不整合な可能性のある読み取りを無視することができます。
select top 10 *
from openrowset(
bulk 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
format = 'csv',
parser_version = '2.0',
firstrow = 2,
ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}') as rows
ALLOW_INCONSISTENT_READS 読み取りオプションを指定すると、クエリ ライフサイクルでのファイルの変更時刻のチェックが無効になり、ファイルから読み取り可能なものをすべて読み取ります。 追加可能なファイルでは、既存のコンテンツは更新されず、新しい行のみが追加されます。 そのため、更新可能なファイルと比較して、結果が不正確になる可能性が最小限に抑えられます。 このオプションを使用すると、頻繁に追加されるファイルを、エラーを処理せずに読み取ることができる可能性があります。 ほとんどのシナリオにおいて、SQL プールでは、クエリの実行中にファイルに追加される一部の行が単に無視されます。
関連するコンテンツ
次の記事では、次の方法について説明します。