適用対象:![]() SQL Server on Linux
SQL Server on Linux
このチュートリアルでは、SQL Server on Linux 用の可用性グループ (AG) を作成して構成する方法について説明します。 WINDOWS 上の SQL Server 2016 (13.x) 以前のバージョンとは異なり、基になる Pacemaker クラスターを最初に作成するか、または作成せずに AG を有効にすることができます。 必要に応じて、クラスターとの統合は後で行われます。
チュートリアルには次のタスクが含まれます。
- 可用性グループを有効にします。
- 可用性グループのエンドポイントと証明書を作成します。
- SQL Server Management Studio (SSMS) または Transact-SQL を使用して可用性グループを作成します。
- Pacemaker の SQL Server ログインとアクセス許可を作成します。
- Pacemaker クラスターに可用性グループのリソースを作成します (外部タイプのみ)。
前提条件
Pacemaker 高可用性クラスターを「SQL Server on Linux の Pacemaker クラスターをデプロイする」の説明に従ってデプロイします。
可用性グループ機能を有効にする
Windows とは異なり、PowerShell または SQL Server Configuration Manager を使用して可用性グループ (AG) 機能を有効にすることはできません。 Linux では、 mssql-conf ユーティリティを使用するか、 mssql.conf ファイルを手動で編集する 2 つの方法で可用性グループ機能を有効にすることができます。
重要
SQL Server Express でも、構成のみのレプリカに対して AG 機能を有効にする必要があります。
mssql-conf ユーティリティを使用する
プロンプトで、次のコマンドを実行します。
sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1
mssql.conf ファイルを編集する
mssql.conf フォルダーの下にある/var/opt/mssql ファイルを変更することもできます。 次の行を追加します。
[hadr]
hadr.hadrenabled = 1
SQL Server を再起動する
可用性グループを有効にした後、SQL Server を再起動する必要があります。 次のコマンドを使用します。
sudo systemctl restart mssql-server
可用性グループのエンドポイントと証明書を作成する
可用性グループは通信に TCP エンドポイントを使用します。 Linux では、認証に証明書を使用する場合にのみ、SQL Server で AG のエンドポイントがサポートされます。 同じ AG のレプリカとして参加している他のすべてのインスタンス上の 1 つのインスタンスから証明書を復元する必要があります。 構成専用レプリカの場合でも、証明書プロセスが必要です。
エンドポイントを作成し、Transact-SQL を使用して証明書を復元することのみが可能です。 SQL Server で生成されていない証明書を使用することもできます。 また、証明書を管理したり有効期限が切れた証明書を置き換えるプロセスも必要です。
重要
SQL Server Management Studio ウィザードを使用して AG を作成する予定の場合でも、Linux で Transact-SQL を使用して証明書を作成および復元する必要があります。
さまざまなコマンド (セキュリティを含む) で使用できるオプションの完全な構文については、次を参照してください。
注
可用性グループを作成する場合でも、エンドポイントの種類として FOR DATABASE_MIRRORING を使用します。特徴の一部が、現在非推奨となっているこの機能と共通しているためです。
この例では、3 ノード構成の証明書を作成します。 インスタンス名は、LinAGN1、LinAGN2、および LinAGN3 です。
LinAGN1で次のスクリプトを実行して、マスター キー、証明書、およびエンドポイントを作成し、証明書をバックアップします。 この例では、標準の TCP ポート 5022 がエンドポイントに使用されています。CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>'; GO CREATE CERTIFICATE LinAGN1_Cert WITH SUBJECT = 'LinAGN1 AG Certificate'; GO BACKUP CERTIFICATE LinAGN1_Cert TO FILE = '/var/opt/mssql/data/LinAGN1_Cert.cer'; GO CREATE ENDPOINT AGEP STATE = STARTED AS TCP ( LISTENER_PORT = 5022, LISTENER_IP = ALL ) FOR DATABASE_MIRRORING ( AUTHENTICATION = CERTIFICATE LinAGN1_Cert, ROLE = ALL ); GOLinAGN2で同じ操作を行います。CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>'; GO CREATE CERTIFICATE LinAGN2_Cert WITH SUBJECT = 'LinAGN2 AG Certificate'; GO BACKUP CERTIFICATE LinAGN2_Cert TO FILE = '/var/opt/mssql/data/LinAGN2_Cert.cer'; GO CREATE ENDPOINT AGEP STATE = STARTED AS TCP ( LISTENER_PORT = 5022, LISTENER_IP = ALL ) FOR DATABASE_MIRRORING ( AUTHENTICATION = CERTIFICATE LinAGN2_Cert, ROLE = ALL ); GO最後に、
LinAGN3で同じ手順を実行します。CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>'; GO CREATE CERTIFICATE LinAGN3_Cert WITH SUBJECT = 'LinAGN3 AG Certificate'; GO BACKUP CERTIFICATE LinAGN3_Cert TO FILE = '/var/opt/mssql/data/LinAGN3_Cert.cer'; GO CREATE ENDPOINT AGEP STATE = STARTED AS TCP ( LISTENER_PORT = 5022, LISTENER_IP = ALL ) FOR DATABASE_MIRRORING ( AUTHENTICATION = CERTIFICATE LinAGN3_Cert, ROLE = ALL ); GOscpまたは別のユーティリティを使用して、AG の一部にする各ノードに証明書のバックアップをコピーします。この例の場合は次のとおりです。
-
LinAGN1_Cert.cerをLinAGN2とLinAGN3にコピーします。 -
LinAGN2_Cert.cerをLinAGN1とLinAGN3にコピーします。 -
LinAGN3_Cert.cerをLinAGN1とLinAGN2にコピーします。
-
所有権と、コピーした証明書ファイルに関連付けられているグループを
mssqlに変更します。sudo chown mssql:mssql <CertFileName>LinAGN2とLinAGN3に関連付けられたインスタンスレベルのログインとユーザーをLinAGN1上に作成します。CREATE LOGIN LinAGN2_Login WITH PASSWORD = '<password>'; CREATE USER LinAGN2_User FOR LOGIN LinAGN2_Login; GO CREATE LOGIN LinAGN3_Login WITH PASSWORD = '<password>'; CREATE USER LinAGN3_User FOR LOGIN LinAGN3_Login; GO注意事項
パスワードは SQL Server の既定のパスワード ポリシーに従う必要があります。 既定では、パスワードの長さは少なくとも 8 文字で、大文字、小文字、10 進数の数字、記号の 4 種類のうち 3 種類を含んでいる必要があります。 パスワードには最大 128 文字まで使用できます。 パスワードはできるだけ長く、複雑にします。
LinAGN1にLinAGN2_CertとLinAGN3_Certを復元します。 他のレプリカの証明書があることが、AG の通信とセキュリティの重要な側面です。CREATE CERTIFICATE LinAGN2_Cert AUTHORIZATION LinAGN2_User FROM FILE = '/var/opt/mssql/data/LinAGN2_Cert.cer'; GO CREATE CERTIFICATE LinAGN3_Cert AUTHORIZATION LinAGN3_User FROM FILE = '/var/opt/mssql/data/LinAGN3_Cert.cer'; GOLinAGN2とLinAGN3に関連付けられたログインに、LinAGN1のエンドポイントに接続するアクセス許可を付与します。GRANT CONNECT ON ENDPOINT::AGEP TO LinAGN2_Login; GRANT CONNECT ON ENDPOINT::AGEP TO LinAGN3_Login;LinAGN1とLinAGN3に関連付けられたインスタンスレベルのログインとユーザーをLinAGN2上に作成します。CREATE LOGIN LinAGN1_Login WITH PASSWORD = '<password>'; CREATE USER LinAGN1_User FOR LOGIN LinAGN1_Login; GO CREATE LOGIN LinAGN3_Login WITH PASSWORD = '<password>'; CREATE USER LinAGN3_User FOR LOGIN LinAGN3_Login; GOLinAGN2にLinAGN1_CertとLinAGN3_Certを復元します。CREATE CERTIFICATE LinAGN1_Cert AUTHORIZATION LinAGN1_User FROM FILE = '/var/opt/mssql/data/LinAGN1_Cert.cer'; GO CREATE CERTIFICATE LinAGN3_Cert AUTHORIZATION LinAGN3_User FROM FILE = '/var/opt/mssql/data/LinAGN3_Cert.cer'; GOLinAGN1とLinAGN3に関連付けられたログインに、LinAGN2のエンドポイントに接続するアクセス許可を付与します。GRANT CONNECT ON ENDPOINT::AGEP TO LinAGN1_Login; GRANT CONNECT ON ENDPOINT::AGEP TO LinAGN3_Login; GOLinAGN1とLinAGN2に関連付けられたインスタンスレベルのログインとユーザーをLinAGN3上に作成します。CREATE LOGIN LinAGN1_Login WITH PASSWORD = '<password>'; CREATE USER LinAGN1_User FOR LOGIN LinAGN1_Login; GO CREATE LOGIN LinAGN2_Login WITH PASSWORD = '<password>'; CREATE USER LinAGN2_User FOR LOGIN LinAGN2_Login; GOLinAGN3にLinAGN1_CertとLinAGN2_Certを復元します。CREATE CERTIFICATE LinAGN1_Cert AUTHORIZATION LinAGN1_User FROM FILE = '/var/opt/mssql/data/LinAGN1_Cert.cer'; GO CREATE CERTIFICATE LinAGN2_Cert AUTHORIZATION LinAGN2_User FROM FILE = '/var/opt/mssql/data/LinAGN2_Cert.cer'; GOLinAG1とLinAGN2に関連付けられたログインに、LinAGN3のエンドポイントに接続するアクセス許可を付与します。GRANT CONNECT ON ENDPOINT::AGEP TO LinAGN1_Login; GRANT CONNECT ON ENDPOINT::AGEP TO LinAGN2_Login; GO
可用性グループを作成する
このセクションでは、SQL Server Management Studio (SSMS) または Transact-SQL を使用して SQL Server の可用性グループを作成する方法について説明します。
SQL Server Management Studio を使用します
このセクションでは、新しい可用性グループ ウィザードを使用して、SSMS を使用する外部タイプのクラスターの AG を作成する方法を説明します。
SSMS で、[Always On 高可用性] を展開し、[可用性グループ] を右クリックし、[新しい可用性グループ ウィザード] を選びます。
[はじめに] ダイアログで [次へ] を選びます。
[ 可用性グループオプションの指定] ダイアログで、AG の名前を入力し、ドロップダウン リストでクラスターの種類の
EXTERNALまたはNONEを選択します。 Pacemaker をデプロイするときにEXTERNALを使用します。NONEは、読み取りスケールアウトなどの特殊なシナリオに使用します。データベース レベルの正常性検出のオプションの選択は省略可能です。 このオプションの詳細については、「 可用性グループ データベース レベルの正常性検出フェールオーバー オプション」を参照してください。 [次へ] を選択します。![クラスターの種類を示す [可用性グループの作成] のスクリーンショット。](media/sql-server-linux-create-availability-group/image3.png?view=sql-server-ver15)
[データベースの選択] ダイアログで、AG に参加させるデータベースを選択します。 AG に追加するには、各データベースに完全バックアップが必要です。 [次へ] を選択します。
[レプリカの指定] ダイアログで [レプリカの追加] を選びます。
[サーバーに接続] ダイアログで、セカンダリ レプリカにする SQL Server の Linux インスタンスの名前と、接続するための資格情報を入力します。 [接続] を選択します。
前の 2 つの手順を、構成専用レプリカまたは別のセカンダリ レプリカを格納するインスタンスに対して繰り返します。
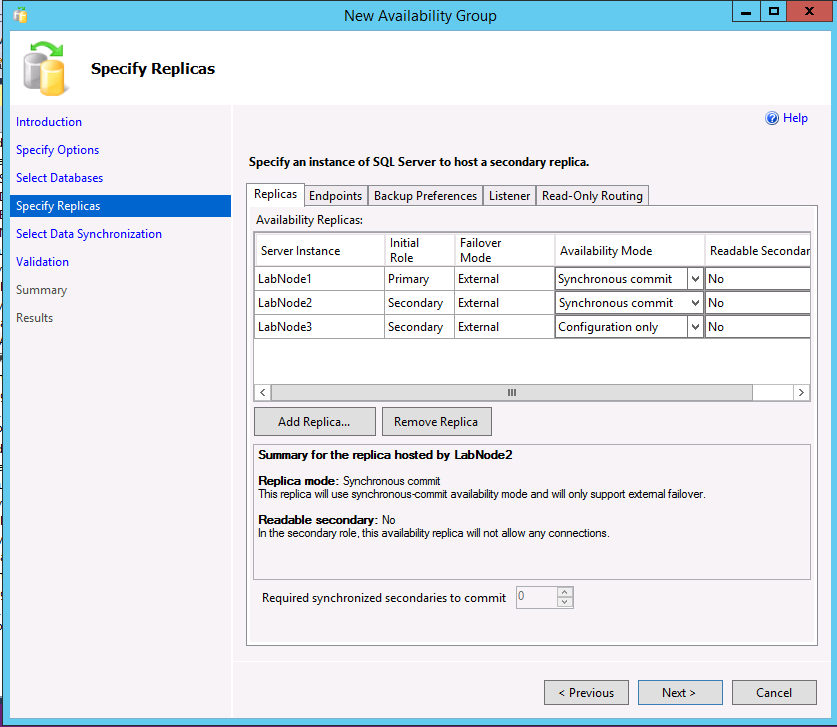
3 つのインスタンスはすべて、[レプリカの指定] ダイアログに表示されます。 クラスターの種類として External を使用する場合は、真のセカンダリであるセカンダリ レプリカに対して、可用性モードがプライマリ レプリカの可用性モードと一致し、フェールオーバー モードが [外部] に設定されていることを確認します。 構成専用レプリカについては、可用性モードとして [構成のみ] を選択します。
次の例に示す AG には、外部クラスタータイプと設定のみのレプリカからなる2つのレプリカが含まれています。
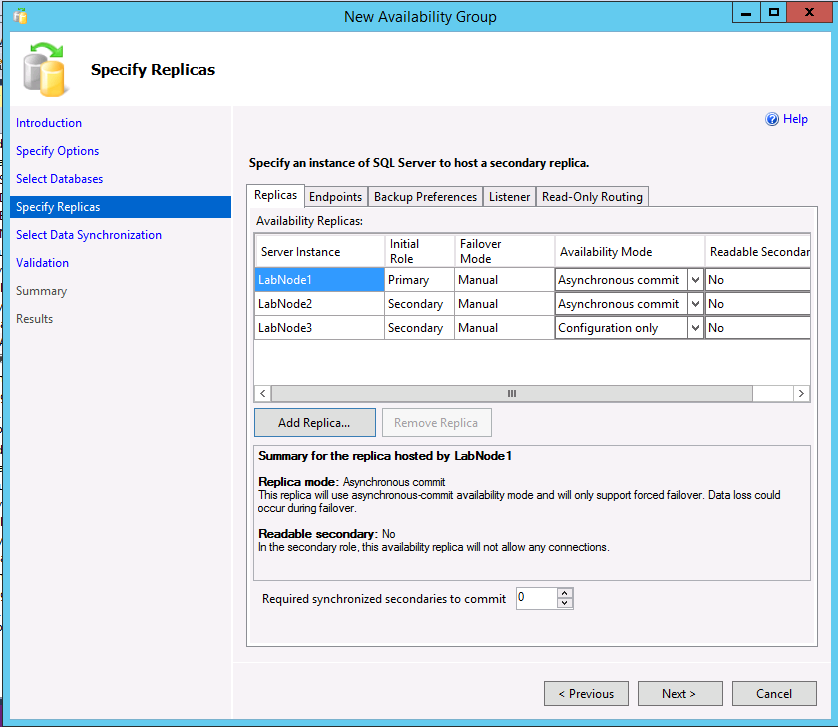
次の例に示す AG には、クラスター タイプ が [なし] のものと構成専用レプリカの 2 つのレプリカが含まれます。
バックアップ設定を変更する場合は、[バックアップ設定] タブを選択します。AG でのバックアップ設定の詳細については、 Always On 可用性グループのセカンダリ レプリカでのバックアップの構成に関するページを参照してください。
読み取り可能なセカンダリを使用する場合、または読み取りスケール用にクラスターの種類が None の AG を作成する場合は、[リスナー] タブを選択して リスナー を作成できます。後でリスナーを追加することもできます。 リスナーを作成するには、[ 可用性グループ リスナーの作成 ] オプションを選択し、名前、TCP/IP ポート、静的または自動的に割り当てられた DHCP IP アドレスのどちらを使用するかを入力します。 クラスターの種類が None の AG の場合、IP は静的で、プライマリの IP アドレスに設定する必要があります。
![リスナー オプションを示す [可用性グループの作成] のスクリーンショット。](media/sql-server-linux-create-availability-group/image6.png?view=sql-server-ver15)
読み取り可能なシナリオのリスナーを作成する場合、SSMS ではウィザードで読み取り専用ルーティングを作成できます。 後で SSMS または Transact-SQL を使用して追加することもできます。 今すぐ読み取り専用ルーティングを追加するには
[読み取り専用ルーティング] タブを選択します。
読み取り専用レプリカの URL を入力します。 これらの URL はエンドポイントに似ていますが、エンドポイントではなくインスタンスのポートを使用する点が異なります。
- 各 URL を選択し、下部で読み取り可能なレプリカを選択します。 複数を選択するには、 Shift キーを押しながらドラッグします。
[次へ] を選択します。
セカンダリ レプリカを初期化する方法を選択します。 既定では、自動シード処理が使用されます。この場合、AG に参加しているすべてのサーバーで同じパスが必要になります。 また、ウィザードでバックアップ、コピー、復元を実行することもできます (2 番目のオプション)。レプリカ上のデータベースを手動でバックアップ、コピー、復元した場合は参加させる (3 番目のオプション)。または後でデータベースを追加します (最後のオプション)。 証明書と同様に、バックアップを手動で作成してコピーする場合は、他のレプリカのバックアップ ファイルに対するアクセス許可を設定します。 [次へ] を選択します。
[検証] ダイアログで、ウィザードがすべてのチェックに対して成功を返さない場合は、さらに詳細に調査してください。 リスナーを作成しない場合など、一部の警告は許容され致命的ではありません。 [次へ] を選択します。
[概要] ダイアログで [完了] を選びます。 これで、AG を作成するプロセスが開始されます。
AG の作成が完了したら、[結果] で [閉じる] を選びます。 これで、動的管理ビューでレプリカに対する AG を表示することも、SSMS の [Always On 高可用性] フォルダーに AG を表示することもできるようになりました。
![クラスターの種類を示す [可用性グループの作成] のスクリーンショット。](media/sql-server-linux-create-availability-group/image3.png?view=sql-server-ver15#lightbox)


![リスナー オプションを示す [可用性グループの作成] のスクリーンショット。](media/sql-server-linux-create-availability-group/image6.png?view=sql-server-ver15#lightbox)
Transact-SQL の使用
このセクションでは、Transact-SQL を使用して AG を作成する例を示します。 AG の作成後に、リスナーと読み取り専用ルーティングを構成できます。
ALTER AVAILABILITY GROUPを使用して AG 自体を変更できますが、SQL Server 2017 (14.x) でクラスターの種類を変更することはできません。 タイプが [外部] のクラスターを含む AG を作成する予定ではなかった場合は、削除して、クラスター タイプ [なし] を含む AG を再作成する必要があります。 詳細およびその他のオプションについては、次のリンクを参照してください。
- 可用性グループの作成 (Transact-SQL)
- 可用性グループを変更する (Transact-SQL)
- Always On 可用性グループの読み取り専用ルーティングの構成
- Always On 可用性グループのリスナーの構成
例 A: 構成のみのレプリカを含む2つのレプリカ(外部クラスタータイプ)
この例では、構成専用レプリカを使用する、2 つのレプリカの AG を作成する方法を示します。
プライマリ レプリカとして機能し、データベースの完全な読み取り/書き込みコピーを含むノードで、次のステートメントを実行します。 この例では自動シード処理を使用します。
CREATE AVAILABILITY GROUP [<AGName>] WITH (CLUSTER_TYPE = EXTERNAL) FOR DATABASE <DBName> REPLICA ON N'LinAGN1' WITH ( ENDPOINT_URL = N' TCP://LinAGN1.FullyQualified.Name:5022', FAILOVER_MODE = EXTERNAL, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT ), N'LinAGN2' WITH ( ENDPOINT_URL = N'TCP://LinAGN2.FullyQualified.Name:5022', FAILOVER_MODE = EXTERNAL, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, SEEDING_MODE = AUTOMATIC ), N'LinAGN3' WITH ( ENDPOINT_URL = N'TCP://LinAGN3.FullyQualified.Name:5022', AVAILABILITY_MODE = CONFIGURATION_ONLY ); GO他のレプリカに接続されているクエリ ウィンドウで、次のステートメントを実行してレプリカを AG に参加させ、プライマリからセカンダリ レプリカへのシード処理を開始します。
ALTER AVAILABILITY GROUP [<AGName>] JOIN WITH (CLUSTER_TYPE = EXTERNAL); GO ALTER AVAILABILITY GROUP [<AGName>] GRANT CREATE ANY DATABASE; GO構成のみのレプリカに接続されているクエリ ウィンドウで、次のステートメントを実行して AG に参加させます。
ALTER AVAILABILITY GROUP [<AGName>] JOIN WITH (CLUSTER_TYPE = EXTERNAL); GO
例 B - 読み取り専用ルーティングの 3 つのレプリカ ([外部] クラスター タイプ)
この例では、3 つの完全なレプリカと、最初の AG 作成の一部として読み取り専用ルーティングを構成する方法を示します。
プライマリ レプリカとして機能し、データベースの完全な読み取り/書き込みコピーを含むノードで、次のステートメントを実行します。 この例では自動シード処理を使用します。
CREATE AVAILABILITY GROUP [<AGName>] WITH (CLUSTER_TYPE = EXTERNAL) FOR DATABASE < DBName > REPLICA ON N'LinAGN1' WITH ( ENDPOINT_URL = N'TCP://LinAGN1.FullyQualified.Name:5022', FAILOVER_MODE = EXTERNAL, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, PRIMARY_ROLE(ALLOW_CONNECTIONS = READ_WRITE, READ_ONLY_ROUTING_LIST = ( ( 'LinAGN2.FullyQualified.Name', 'LinAGN3.FullyQualified.Name' ) )), SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL, READ_ONLY_ROUTING_URL = N'TCP://LinAGN1.FullyQualified.Name:1433') ), N'LinAGN2' WITH ( ENDPOINT_URL = N'TCP://LinAGN2.FullyQualified.Name:5022', FAILOVER_MODE = EXTERNAL, SEEDING_MODE = AUTOMATIC, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, PRIMARY_ROLE(ALLOW_CONNECTIONS = READ_WRITE, READ_ONLY_ROUTING_LIST = ( ( 'LinAGN1.FullyQualified.Name', 'LinAGN3.FullyQualified.Name' ) )), SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL, READ_ONLY_ROUTING_URL = N'TCP://LinAGN2.FullyQualified.Name:1433') ), N'LinAGN3' WITH ( ENDPOINT_URL = N'TCP://LinAGN3.FullyQualified.Name:5022', FAILOVER_MODE = EXTERNAL, SEEDING_MODE = AUTOMATIC, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, PRIMARY_ROLE(ALLOW_CONNECTIONS = READ_WRITE, READ_ONLY_ROUTING_LIST = ( ( 'LinAGN1.FullyQualified.Name', 'LinAGN2.FullyQualified.Name' ) )), SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL, READ_ONLY_ROUTING_URL = N'TCP://LinAGN3.FullyQualified.Name:1433') ) LISTENER '<ListenerName>' ( WITH IP = ('<IPAddress>', '<SubnetMask>'), Port = 1433 ); GOこの構成に関する注意事項:
-
AGNameは AG の名前です。 -
DBNameは、AG で使用するデータベースの名前です。 名前をコンマで区切って指定することもできます。 -
ListenerNameは、基になる任意のサーバーまたはノードとは異なる名前です。IPAddressと共に DNS に登録されます。 -
IPAddressは、ListenerNameに関連付けられている IP アドレスです。 また、一意であり、どのサーバーまたはノードとも同じではありません。 アプリケーションおよびエンド ユーザーは、ListenerNameまたはIPAddressを使用して AG に接続します。-
SubnetMaskは、IPAddressのサブネット マスクです。 SQL Server 2019 (15.x) 以前のバージョンでは、この値は255.255.255.255。 SQL Server 2022 (16.x) 以降のバージョンでは、この値は0.0.0.0。
-
-
他のレプリカに接続されているクエリ ウィンドウで、次のステートメントを実行してレプリカを AG に参加させ、プライマリからセカンダリ レプリカへのシード処理を開始します。
ALTER AVAILABILITY GROUP [<AGName>] JOIN WITH (CLUSTER_TYPE = EXTERNAL); GO ALTER AVAILABILITY GROUP [<AGName>] GRANT CREATE ANY DATABASE; GO3 番目のレプリカに対して手順 2 を繰り返します。
例 C: クラスターなしタイプの読み取り専用ルーティングが可能な2つのレプリカ
この例では、クラスター タイプ [なし] を使用する 2 レプリカ構成を作成しています。 フェールオーバーが想定されない読み取りスケール シナリオでは、この構成を使用します。 この手順では、ラウンド ロビン機能を使用して、実際にはプライマリ レプリカであるリスナーと読み取り専用ルーティングを作成します。
プライマリ レプリカとして機能し、データベースの完全な読み取り/書き込みコピーを含むノードで、次のステートメントを実行します。 この例では自動シード処理を使用します。
CREATE AVAILABILITY GROUP [<AGName>] WITH (CLUSTER_TYPE = NONE) FOR DATABASE <DBName> REPLICA ON N'LinAGN1' WITH ( ENDPOINT_URL = N'TCP://LinAGN1.FullyQualified.Name: <PortOfEndpoint>', FAILOVER_MODE = MANUAL, AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, PRIMARY_ROLE( ALLOW_CONNECTIONS = READ_WRITE, READ_ONLY_ROUTING_LIST = (('LinAGN1.FullyQualified.Name'.'LinAGN2.FullyQualified.Name')) ), SECONDARY_ROLE( ALLOW_CONNECTIONS = ALL, READ_ONLY_ROUTING_URL = N'TCP://LinAGN1.FullyQualified.Name:<PortOfInstance>' ) ), N'LinAGN2' WITH ( ENDPOINT_URL = N'TCP://LinAGN2.FullyQualified.Name:<PortOfEndpoint>', FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC, AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, PRIMARY_ROLE(ALLOW_CONNECTIONS = READ_WRITE, READ_ONLY_ROUTING_LIST = ( ('LinAGN1.FullyQualified.Name', 'LinAGN2.FullyQualified.Name') )), SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL, READ_ONLY_ROUTING_URL = N'TCP://LinAGN2.FullyQualified.Name:<PortOfInstance>') ), LISTENER '<ListenerName>' (WITH IP = ( '<PrimaryReplicaIPAddress>', '<SubnetMask>'), Port = <PortOfListener> ); GOこの例では:
-
AGNameは AG の名前です。 -
DBNameは、AG で使用するデータベースの名前です。 名前をコンマで区切って指定することもできます。 -
PortOfEndpointは、作成するエンドポイントで使用されるポート番号です。-
PortOfInstanceは、SQL Server のインスタンスによって使用されるポート番号です。
-
-
ListenerNameは、基になるレプリカとは異なる名前ですが、実際には使用されません。 -
PrimaryReplicaIPAddressは、プライマリ レプリカの IP アドレスです。-
SubnetMaskは、IPAddressのサブネット マスクです。 SQL Server 2019 (15.x) 以前のバージョンでは、この値は255.255.255.255。 SQL Server 2022 (16.x) 以降のバージョンでは、この値は0.0.0.0。
-
-
セカンダリ レプリカを AG に参加させ、自動シード処理を開始します。
ALTER AVAILABILITY GROUP [<AGName>] JOIN WITH (CLUSTER_TYPE = NONE); GO ALTER AVAILABILITY GROUP [<AGName>] GRANT CREATE ANY DATABASE; GO
Pacemaker の SQL Server ログインおよびアクセス許可を作成する
Linux 上の SQL Server を使用する Pacemaker 高可用性クラスターには、SQL Server インスタンスへのアクセスと AG 自体に対するアクセス許可が必要です。 これらの手順では、ログインと関連するアクセス許可と、Pacemaker に SQL Server に対する認証方法を指示するファイルを作成します。
最初のレプリカに接続しているクエリ ウィンドウで、次のスクリプトを実行します。
CREATE LOGIN PMLogin WITH PASSWORD = '<password>'; GO GRANT VIEW SERVER STATE TO PMLogin; GO GRANT ALTER, CONTROL, VIEW DEFINITION ON AVAILABILITY GROUP::<AGThatWasCreated> TO PMLogin; GOノード 1 で、次のコマンドを入力します。
sudo emacs /var/opt/mssql/secrets/passwdこのコマンドを実行すると、Emacs エディターが開きます。
エディターに次の 2 行を入力します。
PMLogin <password>Ctrlキーを押したまま、Xキー、Cキーの順に押し、ファイルを終了して保存します。次のように実行します。
sudo chmod 400 /var/opt/mssql/secrets/passwdファイルをロック ダウンします。
レプリカとして機能する他のサーバーで手順 1 から 5 を繰り返します。
Pacemaker クラスターに可用性グループのリソースを作成する (外部タイプのみ)
SQL Server で AG を作成した後は、クラスターの種類として External を指定するときに Pacemaker で対応するリソースを作成する必要があります。 AG には、可用性グループ リソースと IP アドレス リソースの 2 つのリソースが必要です。 リスナーを使用していない場合、IP アドレス リソースの構成は省略可能です。 ただし、リスナー機能が必要な場合はお勧めします。
作成する AG リソースは、 複製と呼ばれるリソースの種類です。 AG リソースには、各ノードにコピーがあり、 マスターと呼ばれる 1 つの制御リソースがあります。 マスターは、プライマリ レプリカをホストしているサーバーに関連付けられています。 他のリソースはセカンダリ レプリカ (通常または構成のみ) をホストし、フェールオーバーで マスター に昇格できます。
Pacemaker HA エージェント v2 (プレビュー)
累積的な更新プログラム (CU) 3 以降のバージョンの SQL Server 2025 (17.x) では、Red Hat Enterprise Linux (RHEL) と Ubuntu で新しい Pacemaker HA エージェント v2 (mssql-server-ha) を使用できます。
Pacemaker HA エージェント v2 では、次のような、以前のエージェントに対する信頼性とパフォーマンスの向上が導入されています。
フェールオーバーのパフォーマンスを向上させ、計画されたフェールオーバー時間と計画外のフェールオーバー時間の両方を短縮しました。
正常性チェックのタイムアウトと障害状態レベルの構成など、柔軟な自動フェールオーバー ポリシーのサポート。
Pacemaker クラスターと SQL Server 間の通信に対する TLS 1.3 のサポート。
Pacemaker HA エージェント v2 は現在プレビュー段階です。 既存の Pacemaker HA エージェント (v1) は、運用環境のデプロイで引き続き完全にサポートされています。
既存の Pacemaker HA エージェント (v1) を使用して Pacemaker で AG リソースを作成します。
sudo pcs resource create <NameForAGResource> ocf:mssql:ag ag_name=<AGName> meta failure-timeout=30s promotable notify=trueこの例では、
NameForAGResourceは AG のこのクラスター リソースに指定する一意の名前で、AGNameは作成した AG の名前です。Pacemaker HA エージェント v2 を使用するには、
agv2リソース エージェントを使用して AG リソースを作成します。sudo pcs resource create <NameForAGResource> ocf:mssql:agv2 ag_name=<AGName> meta failure-timeout=30s promotable notify=trueSQL Server 2025 (17.x) での新しいデプロイでは、Pacemaker HA エージェント v2 を評価できます。 必要に応じて、既存の運用デプロイをアップグレードする必要があります。
Pacemaker HA エージェント v2 にアップグレードまたはデプロイする場合は、前の
agv2エージェントではなく、agエージェントを使用して新しい AG リソースを作成します。 既存の AG リソースを既に構成している場合は、それを削除し、agv2を使用して新しいリソースを作成します。sudo pcs resource delete <NameForAGResource>この操作は、リソースの再作成中に AG 同期を一時的に停止します。 Pacemaker AG リソースを削除して再作成しても、AG は削除されません。 リソースが再作成されると、Pacemaker は管理と AG 同期を自動的に再開します。
リスナー機能に関連付ける AG の IP アドレス リソースを作成します。
sudo pcs resource create <NameForIPResource> ocf:heartbeat:IPaddr2 ip=<IPAddress> cidr_netmask=<Netmask>この例では、
NameForIPResourceは IP リソースの一意の名前で、IPAddressはリソースに割り当てる静的 IP アドレスです。IP アドレスと AG リソースが同じノードで実行されるようにするには、コロケーション制約を構成します。
sudo pcs constraint colocation add <NameForIPResource> with promoted <NameForAGResource>-clone INFINITYこの例では、
NameForIPResourceは IP リソースの名前、NameForAGResourceは AG リソースの名前です。順序制約を作成して、IP アドレスよりも前に AG リソースが稼働するようにします。 コロケーション制約は順序付け制約を意味しますが、この手順ではこれを適用します。
sudo pcs constraint order promote <NameForAGResource>-clone then start <NameForIPResource>この例では、
NameForIPResourceは IP リソースの名前、NameForAGResourceは AG リソースの名前です。