SharePoint の特定のパフォーマンス要件に合わせてエンタープライズ検索トポロジを再設計する
適用対象: 2016 2019 Subscription Edition
2016 2019 Subscription Edition  SharePoint in Microsoft 365
SharePoint in Microsoft 365
「SharePoint Server 2016 でエンタープライズ検索アーキテクチャを計画する」のガイダンスに従っても検索環境の特定のパフォーマンス要件を満たせなかった場合は、エンタープライズ検索アーキテクチャのトポロジをスケーリングすることが解決策となります。
トポロジの再設計 (この記事)
再設計されたトポロジの実装 (SharePoint Serever で検索トポロジを管理する)
SharePoint Server 2016 の検索システムのコンポーネントと、それらの操作方法についてよく理解していますか? 「SharePoint Server での検索アーキテクチャの概要」と「SharePoint Server 2016 の検索アーキテクチャ (または SharePoint Server2013 の検索アーキテクチャ)」を参照すると、検索アーキテクチャ、検索コンポーネント、検索データベース、および検索トポロジについて理解できるようになります。
この記事では、検索トポロジを再設計して、特定のパフォーマンス要件を満たす方法を順を追って説明します。
これらの手順を実行すると、以下が判明します。
使用するトポロジで必要となる、検索コンポーネントと検索データベースの種類ごとの数。
各検索コンポーネントの展開先となるアプリケーション サーバーとデータベース サーバー。
各アプリケーション サーバーとデータベース サーバーで必要となるハードウェア リソース。
手順 1: 特定のパフォーマンス要件を見極める
特定のパフォーマンス要件の背後にあるビジネス ニーズを確実に理解してさい。 例えば、ニュースや金融の検索ではほぼリアルタイムにインデックス付けされた最新データが必要ですが、訴訟サポート サービスでは一度だけインデックス付けされたデータの一括取り込みが必要です。 以下の 1 つ以上の方法でパフォーマンス要件を表現してください。
インデックス付きのアイテムの数。
検索ソリューションが毎秒クロールする必要のあるアイテム数と、その待機時間。
検索ソリューションが毎秒処理しなければならないクエリ数と、その待機時間。
上記のパフォーマンス要件に加えて、クエリ結果の関連性の要件や検索トポロジの冗長性の要件を持つ環境もあります。 特定のパフォーマンス要件はなくても、パフォーマンスに影響を与え得るボトルネックが検索アーキテクチャに見つかる場合もあります。 これらについても検討します。
手順 2: どの検索コンポーネントをスケーリングする必要があるか
パフォーマンスの向上やボトルネックの除去のために、作業用の検索コンポーネントをさらに追加したり、検索コンポーネントをホストするサーバーにさらにリソースを追加したりすることができます。 より多くの検索コンポーネントを追加することをスケール アウトと言い、サーバーにより多くのリソースを追加することをスケール アップと言います。 どの検索コンポーネントをスケール アウトするか、またはどのサーバーをスケール アップするかは、改善するパフォーマンス メトリックや除去するボトルネックによって異なります。 以下にいくつかの例を示します。
クエリ速度の向上が必要で、インデックス用の CPU リソースがボトルネックになっている環境の場合、インデックスの各パーティションにインデックス レプリカをもう 1 つ追加します。 これにより、検索はより多くのクエリに対して同時にサービスを提供できます。
クロールしたコンテンツを処理する CPU リソースがボトルネックになっている場合、コンテンツを処理するコンポーネントの数をスケール アウトします。 または、より多くの、あるいはより高速な CPU を搭載したサーバーで実行することによって、コンテンツを処理するコンポーネントをスケール アップすることもできます。 どちらの方法のスケーリング処理でも、コンテンツを処理するためにより多くの CPU リソースが必要となります。
分析コンポーネントの分析完了までの速度が不十分な場合は、分析コンポーネントをホストするサーバーのプロセッサ リソース、ディスク IOPS、またはネットワーク帯域をスケール アップします。
検索コンポーネントまたはデータベース数のスケール アウトのサポートには制限があることに注意してください。 「検索の制限」で上限を確認し、それらの制限内に収めることで、検索コンポーネントとデータベースの間の通信が迅速で安定したものとなるようにします。 必要な場合には、検索コンポーネントの数を減らして、検索アーキテクチャのキャパシティを小さくします。
以下のセクションでは、各要件を満たすように検索コンポーネントやデータベースをスケール処理するためのガイドラインを示します。
インデックス内でより多くのアイテムを処理する方法
インデックス付きのアイテム量が増加している一方で、インデックス付きのアイテムの変化が以前と同じ割合で生じている場合は、以下の検索コンポーネントとデータベースをスケール アウトして、検索トポロジのキャパシティを拡大します。
| 検索コンポーネントまたはデータベース | ガイドライン |
|---|---|
| インデックス コンポーネント | 2,000 万 1 のインデックス付きアイテムごとに 1 つのインデックス パーティションを使用します。 各パーティションには、1 つまたは複数のパーティションのレプリカが含まれています。 すべてのパーティションには、同じ数のレプリカが必要です。 1 つのインデックス コンポーネントは、1 つのインデックス レプリカを表します。 したがって、インデックスのレプリカを 2 つ作成する場合は、インデックス パーティションの 2 倍の数のインデックス コンポーネントが必要となります。 たとえば、8,000 万 2 のアイテムを含む冗長なインデックスには 4 つのパーティションが必要です。 パーティションごとに 2 つのレプリカを使用する場合、8 個のインデックス コンポーネントは 4 つのパーティションを表します。 |
| クロール データベース | コンテンツ コーパス内の 2,000 万のアイテムごとに 1 つのクロール データベースを使用します。 たとえば、アイテムが 1 億個のインデックスには 5 つのクロール データベースが必要です。 インデックス付きのアイテム数の増加がクロール速度の向上を示している場合は、クロール データベースにサービスを提供するための IOPS リソースもさらに必要となります。 クロール速度が毎秒 1 ドキュメントの場合、クロール データベースには約 10 IOPS が必要です。 |
| リンク データベース | コンテンツ コーパス内の 6,000 万のアイテムごとに 1 つのリンク データベースを使用します。 たとえば、アイテムが 1 億個のインデックスには 2 つのリンク データベースが必要です。 追加コンテンツがクロール速度の向上を示している場合は、リンク データベースにサービスを提供するための IOPS リソースがさらに必要となる可能性があります。 |
| 分析レポート データベース | 分析レポート データベースの必要数は、検索環境が分析を使用する方法とその頻度によって異なります。 一般に、分析のパフォーマンスが低下し始めたら、分析レポート データベースを追加します。 たとえば、毎晩のデータベース更新により多くの時間がかかるようになったときなどです。 これは、データベースの合計サイズが 250 GB または 2,000 万行に達したとき、または 1 日に表示される一意のアイテム数が 500,000 に達したときに生じる可能性があります。 |
SharePointServer 2013 または SharePoint Server 2016 で実行される 1,000 万個のアイテムで、500 GB 未満のストレージ、32 GB の RAM、8 つの CPU コアを使用して実行されます。
SharePointServer 2013、または SharePoint Server 2016 が 500 GB 未満のストレージ、32 GB RAM、8 つの CPU コアを使用して実行されている 4,000 万個のアイテム。
結果の取り込み速度と鮮度を向上させる方法
取り込み速度を高めなければならない状況もあります。 たとえば、環境がきわめて鮮度の高い結果を要求し、コンテンツのボリュームが検索アーキテクチャの上限に近いか、またはコンテンツが頻繁に変更される場合などです。 チーム サイトでファイルをアーカイブしていたユーザーが、作業中にファイルを OneDrive に保存すると、コンテンツが頻繁に変更される可能性があります。 検索により、ユーザーがファイルに加える変更すべてにインデックスが付けられます。
検索がアイテムを取り込む速度に影響を与える要素を理解していると役立ちます。
検索がアイテムをクロールする速度。 これは以下の要素に依存します。
クロール コンポーネントとコンテンツ ソース間の接続の速度。
クロールするアイテムの種類と平均サイズ。
クロール データベースをホストしている SQL サーバーのパフォーマンス。
クロール コンポーネントの CPU およびメモリ リソースの量。
インデックス付けする前に各アイテムで必要となるコンテンツ処理の量。
インデックスにあるパーティションの数。 パーティションが多いほど、検索でのインデックス付けの負荷が分散されます。
以下を行います。
クロールされたアイテムの年齢分布を調べることによって、ファーム内の結果の鮮度を確認します。 SharePoint サーバーの全体管理 Web サイト で、[ クロールの正常性レポート ] に移動して [ クロール更新の確認間隔 ] を選択します。 ファームで許容できる年齢分布は、ビジネス要件によって異なります。 たとえば、[ クロール更新の確認間隔 ] ページにコンテンツの 90% をインデックス付けするために 4 時間かかると示されている場合、要件が 30 分であれば、取り込み速度を増加させてください。
[クロール更新の確認間隔] ページ で、結果の鮮度が不足しているのは 1 日のどの期間かを識別します。
ガイドラインに従って、その期間の取り込み速度を向上させます。
| ガイドライン |
|---|
| 特定のコンテンツ ソースの鮮度を向上させる |
| クロールの処理リソースを増やす |
| クロール データベースの処理リソースを増やす |
| コンテンツ処理の処理リソースとメモリ リソースを増やす |
| インデックス パーティションの数を増やす |
特定のコンテンツ ソースの鮮度を向上させる
クロールのスケジュールを確認し、鮮度が低い時間帯に検索がクロールしているコンテンツ ソースを特定してください。 特定のコンテンツ ソースの鮮度が低い場合には、次の点を考慮します。
クロール コンポーネントをホストするサーバーと、そのコンテンツ ソースとの間の接続速度を上げます。 クロール コンポーネントのネットワークで帯域幅の必要性を大きくしているのは、クロール速度、コンテンツ ソースからアイテムをダウンロードすること、およびコンテンツ処理コンポーネントにアイテムを渡すことです。
コンテンツ ソースが SharePoint の場合、そのファームにはより多くの専用のクロール ターゲットが必要となる可能性があります。 クロール ターゲットについて詳しくは、「クロールの負荷を管理する (SharePoint Server 2010)」を参照してください。
コンテンツ データベースのパフォーマンスを向上させます。 その方法については、「SharePoint Server 2016 ファーム内の SQL Server のベスト プラクティス」を参照してください。
クロールの処理リソースを増やす
クロール コンポーネントがプロセッサ リソースを 100% 使用することが頻繁に生じる場合、クロール コンポーネントをもう 1 つ追加することや、クロール コンポーネントをホストしているサーバーにより多くのプロセッサ リソースを追加することを検討してください。 プロセッサ リソースの必要性を大きくしているのは、クロール速度、リンクの発見、およびクロールの管理です。 Microsoft がテストした小型や中型のサンプル検索アーキテクチャ (SharePoint Server 2016 でエンタープライズ検索アーキテクチャを計画する) のような検索アーキテクチャでは、通常、2 つのクロール コンポーネントを使用すればクロール処理は十分に速くなります。 大型や巨大なサンプルのような検索アーキテクチャでは、3 つ以上のクロール コンポーネントが必要な場合があります。
クロール データベースの処理リソースを増やす
クロール データベースをホストしている SQL サーバーに十分なリソースがあるかどうかを確認します。 その方法については、「SharePoint Server 2016 ファーム内の SQL Server のベスト プラクティス」を参照してください。
すべてのクロール データベースが多くのプロセッサ リソースを使用する場合、データベースをホストしている SQL サーバーにより多くのプロセッサ リソースを追加すること、または既存の SQL サーバーが持つのと同じ数のクロール データベースを持つ SQL サーバーをもう 1 つ追加することを検討してください。 たとえば、それぞれ 3 つのクロール データベースを持つ 2 つの SQL サーバーがある場合、3 つのクロール データベースを持つ SQL サーバーをもう 1 つ追加します。
1 つまたは少数のクロール データベースだけが多くのプロセッサ リソースを使用する場合は、クロール データベース間での負荷が不均衡です。 すべてのクロール データベース間でコンテンツのバランスを再調整することを検討してください。 再調整中、検索はクロール処理を停止するので、再調整中の結果の鮮度は、クロール処理が停止中の変更に追いつくまで低下することに注意してください。 再調整は、[ データベース ] ページの [ バランス ] ボタンで起動します。 [検索管理] で [クロール ログ] に移動して、[データベース] を選択します。
コンテンツ処理の処理リソースとメモリ リソースを増やす
コンテンツ処理コンポーネントが 100% に近い CPU リソースを使用している場合は、より多くのコンテンツ処理コンポーネントを追加すること、またはコンテンツ処理コンポーネントをホストしているサーバーにより多くの CPU リソースを追加することを検討してください。
メモリの再起動が頻発することに気付いた場合は、コンテンツ処理コンポーネントをホストしているサーバー上のメモリ量を増やすことを検討します。 経験則では、CPU コアあたり 2 GB の作業メモリが適しています。
インデックス パーティションの数を増やす
コンテンツ処理アクティビティを確認します。 これは、[検索管理] に移動して [ クロールの正常性レポート ] を選択してから [ コンテンツ処理アクティビティ ] を選択すると見つかります。 インデックス付けのアクティビティに大半の時間を要する場合、インデックスをより多くのパーティションに分割することを検討してください。 パーティションが多いほど、検索でのインデックス付けの負荷が分散されます。
実行中のインストール環境により多くのパーティションを追加すると、インデックスは自動的に再パーティション化されます。 インデックスの再パーティション化には、数時間または数日かかることがあります。 必要な期間は、再パーティション化が開始するときのファームの状態によって異なります。
クエリの待機時間を少なくしてクエリのスループットを向上させる方法
毎秒処理できるクエリ検索の数をクエリ スループットと言います。 クエリ スループットは、検索がクエリの処理に使用する時間、および処理中のリソースが使用できないことによるクエリの待ち時間に依存します。 処理時間と待ち時間の合計を、クエリの待機時間と言います。 クエリの待機時間を短縮すると、クエリのスループットが向上します。 クエリの待機時間を短縮するには、以下のいずれかまたは両方の次のガイドラインに従います。
| ガイドライン |
|---|
| クエリの処理時間を短縮する |
| クエリの待ち時間を短縮する |
クエリの処理時間を短縮する
インデックスにさらに多くのパーティションを追加することを検討してください。 パーティションを多くすると、各パーティションのアイテム数は少なくなります。 アイテム数が少なくなると、各パーティションはクエリに対してより速く応答します。 パーティションが多すぎることも良くありません。 クエリ処理コンポーネントは各パーティションからの応答をマージしてクエリに対する回答を生成する必要があるので、インデックスのパーティション数が多くなるとマージにかかる時間が長くなります。 すべてのパーティションには、同じ数のレプリカが必要です。
実行中のインストール環境にさらに多くのパーティションを追加すると、インデックスは自動的に再パーティション化されます。 インデックスの再パーティション化には、数時間または数日かかることがあります。 必要な時間は、再パーティション化が開始するときのファームの状態によって異なります。
クエリの待ち時間を短縮する
以下の操作を検討してください。
インデックスのレプリカをより多く追加します。 より多くのレプリカを追加すると、検索はそれらのレプリカにクエリを分散し、それらの上で並行して実行されます。 1 つのインデックス コンポーネントは、1 つのインデックス レプリカを表します。 すべてのパーティションでレプリカの数が同じでなければならないので、インデックスのパーティションごとに 1 つのインデックス コンポーネントを追加してください。 実行中のインストール環境にある既存のパーティションにインデックス コンポーネントをレプリカとして追加すると、検索はインデックス パーティションからのデータによって新しいレプリカをシードします。 新しいレプリカが運用可能になるまで数時間かかります。
インデックス コンポーネントをホストしているサーバーに、より多くのメモリを追加します。
インデックス コンポーネントをホストしているサーバーで、ソリッド ステート ドライブ (SSD) など、インデックス用のより高速なストレージに切り替えます。
インデックスのコンポーネントをホストしているサーバーに、より多くのプロセッサ リソースを追加します。 すると、コンポーネントで 1 秒ごとに処理されるクエリ数が増加します。 たとえば、サーバーに 2 GHz の CPU がある場合、1 つのコアで以下を処理できます。
インデックスに 100 万のアイテムがある場合、毎秒 5 つのクエリ。
インデックスに 500 万のアイテムがある場合、毎秒 2 つのクエリ。
インデックスに 1,000 万のアイテムがある場合、毎秒 1 つのクエリ。
クエリ処理コンポーネントをホストしているサーバーに、より多くのプロセッサ リソースを追加します。 すると、クエリがまれで複雑な場合には特に、コンポーネントによって毎秒処理されるクエリ数が増えます。 クエリ処理コンポーネントでプロセッサ リソースの必要性を大きくしているのは、クエリ速度およびクエリ変換数です。 クエリ処理コンポーネントでは、通常は毎秒 4 つのクエリごとに 1 つの CPU コアが必要です。
分析処理の時間を短縮する方法
分析処理は毎晩行われます。 分析処理コンポーネントは、コンポーネントをホストしているサーバーに中間データを保管して、分析の結果を分析レポート データベースに保管します。 障害が分析処理の妨げになる場合でも、ドキュメントのクロールまたはクエリへの応答は影響を受けません。 しかし、クエリ結果の関連性は最良ではなくなります。
以下の操作を検討してください。
クエリ結果の関連性が最良でなければならない環境において、この条件を満たすために分析処理が十分高速でない場合、より多くのディスク (スピンドル)、またはより高速なディスクを追加します。
分析処理に通常よりも時間がかかるようになり始めたら、分析レポート データベースを追加します。 そのような時間の増加は、データベースの合計サイズが 250 GB または 2,000 万行に達したとき、または 1 日に表示される一意のアイテム数が 500,000 に達したときに生じる可能性があります。
24 時間を超えても分析処理が完了しない場合は、より多くの分析処理コンポーネントを追加するか、または分析処理コンポーネントをホストしているサーバーにより多くのプロセッサ リソースを追加します。 プロセッサ リソースの必要性を大きくしているのは、インデックス内のアイテムの数およびサイト上のアクティビティです。
分析処理がいつまでも完了しない場合や、分析コンポーネントをホストしているサーバーのディスクに対して正常性通知が出された場合は、より多くのディスク スペースをサーバーに追加します。 分析コンポーネントがより多量の中間データをより高速に処理するためには、より多くの分析コンポーネントを追加すること、または分析コンポーネントをホストしているサーバーにより多くのプロセッサ ソースを追加することを検討してください。
検索コンポーネントとデータベースを冗長化する方法
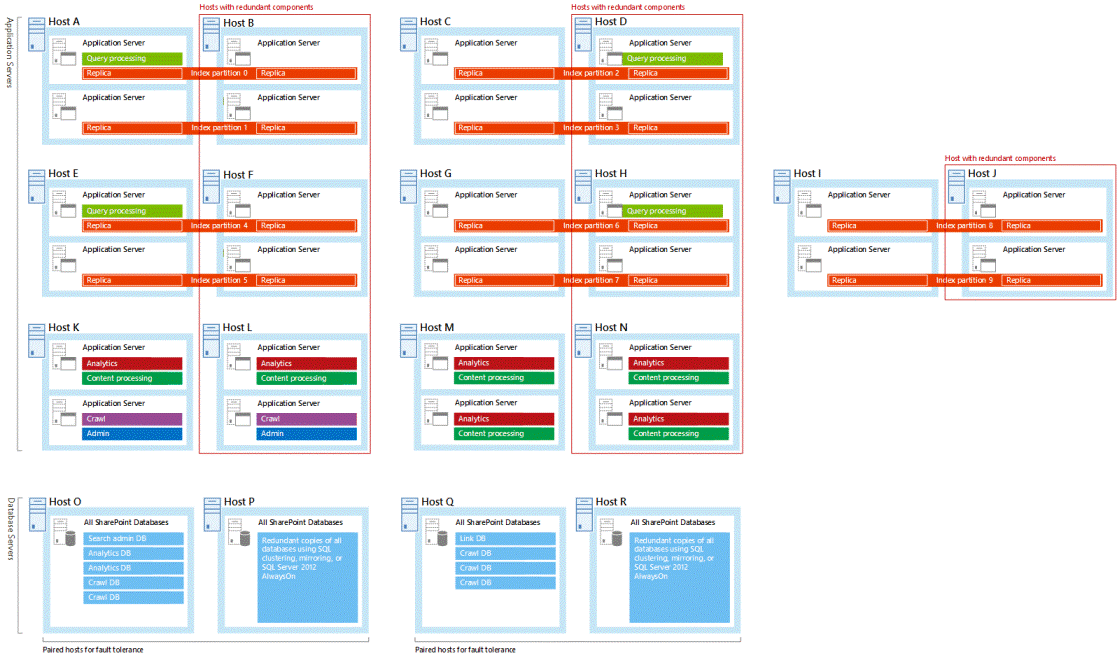
冗長検索コンポーネントおよびデータベースを別々の障害ドメインでホストする場合には、検索アーキテクチャで高可用性がサポートされます。 冗長な検索データベースとコンポーネントを使用して検索トポロジを設計することをお勧めします。 Microsoft がテストしたすべてのサンプル検索アーキテクチャには、冗長な検索コンポーネントとデータベースがあり、独自のトポロジで作業するときにこれらのサンプルを調べるのに役立つ場合があります ( 「SharePoint 2016 のエンタープライズ検索アーキテクチャ」を参照してください)。
次のガイドラインに従います。
| ガイドライン |
|---|
| インデックスを冗長化する |
| クロール、コンテンツ処理、クエリ処理、分析処理、および検索管理を冗長化する |
| 検索データベースを冗長化する |
インデックスを冗長化する
インデックスのパーティションごとに 2 つ以上のインデックス レプリカがある場合、インデックスは冗長化されています。 インデックス レプリカをホストするサーバーに障害が生じた場合、パフォーマンスは低下する可能性がありますが、検索は引き続きクエリやインデックス アイテムを処理できます。 しかし、常に同じパフォーマンスが要求される環境の検索には、より多くの冗長インデックス コンポーネントが必要です。 たとえば、クエリの待ち時間を短縮するためにパーティションごとに 2 つのレプリカを備える検索トポロジを設計したとします。 この環境で、常に短いクエリの待ち時間が求められる場合、パーティションごとのインデックス レプリカの数を増やします。
すべてのパーティションには、同じ数のレプリカが必要です。 1 つのインデックス コンポーネントは、1 つのインデックス レプリカを表します。 したがって、インデックスのレプリカを 2 つ作成する場合は、インデックス パーティションの 2 倍の数のインデックス コンポーネントが必要となります。 たとえば、SharePoint Server 2016 の場合、8,000 万のアイテムを含む冗長なインデックスには 4 つのパーティションが必要です。 パーティションごとに 2 つのレプリカを使用する場合、8 個のインデックス コンポーネントは 4 つのパーティションを表します。
実行中のインストール環境にある既存のパーティションにインデックス コンポーネントをレプリカとして追加すると、検索はインデックス パーティションからのデータによって新しいレプリカをシードします。 新しいレプリカが運用可能になるまで数時間かかります。
クロール、コンテンツ処理、クエリ処理、分析処理、および検索管理を冗長化する
例として、クロール コンポーネントを取り上げます。 クロール コンポーネントをホストしているサーバーの 1 つをメンテナンスのために停止する必要がある場合、結果の鮮度は低下しますが、検索は引き続きすべてのコンテンツをクロールできます。 しかし、常に同等の結果の鮮度が要求されている環境の検索では、より多くの冗長なクロール コンポーネントが必要となります。 たとえば、3 つのクロール コンポーネントを持つ検索トポロジを設計したとします。 2 つのクロール コンポーネント サーバーに障害が生じた場合でも結果の鮮度を同じに保つには、さらに 2 つのクロール コンポーネントを追加します。
検索管理コンポーネントはこの原則の例外です。 1 つの検索管理コンポーネントで、あらゆるサイズの検索トポロジに対応する十分のキャパシティがあります。 したがって、2 つの検索管理コンポーネントがあれば、十分な冗長性が得られます。
コンテンツ処理コンポーネントは互い同士で負荷のバランスを取るため、コンテンツ処理コンポーネントを冗長化すると、アイテムを処理するキャパシティが強化されます。
検索データベースを冗長化する
検索データベースを冗長にするには、SQL Server が提供する高可用性の代替方式を使用します (「SharePoint Server の高可用性のアーキテクチャと戦略を作成する」を参照してください)。
手順 3: サーバーを物理的に実行するか仮想的に実行するかを選択する
最初に検索アーキテクチャを計画した時、物理サーバーを使用するか、仮想マシンを使用するか、それとも両者を組み合わせるかを決定しました。 そのときの決定がまだ有効かどうかを検討してください。 現在はずっと多くの検索コンポーネントがある場合、仮想マシンを使用してアーキテクチャの管理を容易にすることもできます。 たとえば、障害が発生した場合、仮想マシンは物理マシンよりも交換が簡単です。 仮想環境は管理が簡単ですが、パフォーマンス レベルが物理環境のものよりも少し低くなることがある点にも注意してください。 物理サーバーは仮想サーバーよりも、同じサーバー上でより多くの検索コンポーネントをホストできます。 「Overview of farm virtualization and architectures for SharePoint 2013」に役立つガイダンスがあります。
手順 4: どの検索コンポーネントまたはデータベースをどのサーバーでホストするか
検索トポロジの再設計が完了したので、次のステップでは、検索とデータベースのコンポーネントを物理サーバーまたは仮想サーバーに割り当てます。 検索コンポーネントを物理サーバーまたは仮想マシンに割り当てる単一の最適な方法はありませんが、以下にガイドラインを示します。
サーバーごとに 1 つの検索コンポーネント
各物理サーバーや仮想マシンは、それぞれのタイプの検索コンポーネントを 1 つだけホストできます。 インデックス コンポーネントは例外です。 物理サーバーや仮想マシンは、4 つまでのインデックス コンポーネントをホストできます。 これらの制限については、「ソフトウェアの境界と制限 (SharePoint Server 2016)」を参照してください。
一括処理とリアルタイムのコンポーネントを互いに分離する
一括処理とリアルタイム処理の検索コンポーネントが同じ物理サーバーまたは仮想マシンで混在しないようにします。 クロール、コンテンツ処理、および分析処理のコンポーネントは一括処理を実行します。 インデックスとクエリの処理コンポーネントはリアルタイム処理を実行します。
競合する検索コンポーネントを混在させない
検索コンポーネント同士が同じリソースを求めて競合する場合には、物理サーバーまたはマシン上にコンポーネントを混在させないようにします。 次の表は、各コンポーネントに必要なリソースの相対的な量を示しています。
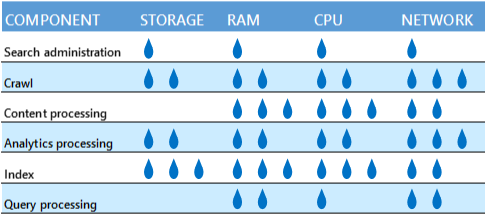
たとえば、クロールと分析処理のコンポーネントはどちらも多くのネットワーク帯域幅を使用するので、両者を同じサーバーに配置することは適切でないことがあります。 ただし、物理サーバーまたは仮想マシンに十分のネットワーク容量がある場合、それらのコンポーネントは競合しません。
別の例には、Microsoft が推定した巨大な検索アーキテクチャのサンプルがあります。 ここでは、クロールと検索の管理コンポーネントを別々の仮想マシンに配置しました。 そうしない場合、2 つのコンポーネントがプロセッサ リソースをめぐって競合する可能性があるため、これはクロールの速度に適しています。
障害ドメインを使用する
冗長検索コンポーネントを、さまざまな障害ドメインのホストに割り当てるようにします。
手順 5: 認識しておくべきハードウェア要件は何か
次のステップでは、必要なハードウェアを計画します。
ホスト サーバーのハードウェア リソースの量を選択する
各検索コンポーネントと検索データベースが良好に機能するには、ホスト サーバーからの最小限のハードウェア リソースが必要です。 しかし、ハードウェア リソースは多ければ多いほど、検索アーキテクチャのパフォーマンスが向上します。 そのため、最小限のハードウェア リソースよりも多くのハードウェア リソースを用意することをお勧めします。 各検索コンポーネントで必要なリソースはワークロードによって異なり、大部分はクロール速度、クエリ速度、およびインデックス付けされたアイテムの数によって決まります。
たとえば、仮想マシンを Windows Server 2008 R2 Service Pack 1 (SP1) でホストする場合、仮想マシン 1 台につき最大で 4 個の CPU コアしか使用できません。 Windows Server 2012 以降では、仮想マシンごとに 8 個以上の CPU コアを使用します。 したがって、より多くの仮想マシンを使用してスケール アップする代わりに、仮想マシンごとにより多くの CPU コアを使用してスケール アウトできます。 同じ検索コンポーネントをホストし、同じハードウェア リソースを持つサーバーまたは仮想マシンをセットアップします。 例としてインデックス コンポーネントを取り上げます。 仮想マシンでインデックス パーティションをホストする場合、最低のパフォーマンスの仮想マシンによって検索アーキテクチャ全体のパフォーマンスが決まります。
汎用ストレージ
各ホスト サーバーには、Windows Server オペレーティング システムの基本インストールと、SharePoint Server 2016 プログラム ファイルのための十分なディスク領域を確保してください。 また、ホスト サーバーでは、ログ記録、デバッグ、メモリ ダンプの作成などの診断用、日々の操作用、およびページ ファイル用の空きハードディスク領域も必要です。 通常、Windows Server オペレーティング システムおよびSharePoint Server 2016 プログラム ファイルには、80 GB のディスク領域があれば十分です。
データベース サーバーごとに SQL ログ スペース用のストレージを追加します。 データベースを頻繁にバックアップするようにデーベース サーバーを設定していない場合は、SQL ログ スペースに大量のストレージが使用されます。 SQL データベースを計画する方法の詳細については、「ストレージおよび SQL Server の容量計画と構成 (SharePoint Server)」を参照してください。
分析レポート データベースが必要とする最低限のストレージは、異なる場合があります。 これは、必要とされるストレージの量はユーザーが SharePoint Server 2016 を操作する方法によって決まるためです。 ユーザーが頻繁に操作すると、通常は保存されるイベントが多くなります。 現在の検索アーキテクチャがデータベースの分析に使用しているストレージの量を確認し、再設計するトポロジにこの量以上を割り当ててください。
インデックス コンポーネントのための最小限のリソース
以下は、サーバーまたは仮想マシンが 1 つのインデックス コンポーネントをホストするため、または 1 つのインデックスコンポーネントと 1 つのクエリ処理コンポーネントをホストするために必要な最小限のリソースです。
| ストレージ | メモリ | プロセッサ | ネットワークの帯域幅 |
| インデックス用に 500 GB1 | 32 GB1 | 64 ビット、8 コア (最小)1、2。 | 2 Gbps |
1SharePoint Server 2013 では、リソースの最小量は 500 GB ストレージ、16 GB RAM、および 4 つの CPU コアです。
2SharePoint Server 2016 では 16 GB の RAM と 4 つの CPU コアを使用することができますが、各インデックス コンポーネントが保持できるアイテムは最大で 1,000 万個です (2,000 万個ではありません)。
分析処理コンポーネントのための最小限のリソース
以下は、サーバーまたは仮想マシンが 1 つの分析処理コンポーネントをホストするために必要な最小限のリソースです。
| ストレージ | メモリ | プロセッサ | ネットワークの帯域幅 |
| 分析のローカル処理のために 300 GB | 8 GB | 64 ビット、4 コア (最小)、8 コア (推奨)。 | 2 Gbps |
サーバーが 1 つの分析処理コンポーネントと 1 つ以上の一括処理コンポーネントをホストしている場合は、メモリを 16GB に増やします。
クロール、コンテンツ処理、クエリ処理、および検索管理コンポーネントのための最小限のリソース
以下は、サーバーまたは仮想マシンがこれらのコンポーネントのうち 1 つをホストするために必要な最小限のリソースです。
| ストレージ | メモリ | プロセッサ | ネットワークの帯域幅 |
| 省略可 | 8 GB | 64 ビット、4 コア (最小)、8 コア (推奨)。 | 2 Gbps |
サーバーがこれらのコンポーネントを 2 つ以上ホストしている場合は、メモリを 16GB に増やします。
クエリ処理コンポーネントには、適切なネットワーク帯域幅が必要です。 このネットワーク帯域幅の必要性を大きくしているのは、インデックス パーティションの数、およびクエリと結果のサイズです。 たとえば、クエリ処理コンポーネントごとに毎秒 20 のクエリ (20 QPS/QPC) があり、インデックスに 20 のインデックス パーティションがある場合、クエリ処理コンポーネントをホストしているサーバーまたは仮想マシンの受信トラフィックは 200 Mbps、送信トラフィックは 100 Mbps になります。
検索データベースのための最小限のリソース
以下は、サーバーまたは仮想マシンが 1 つ以上の検索データベースをホストするために必要な最小限のリソースです。
| ストレージ | メモリ | プロセッサ | ネットワークの帯域幅 |
| 分析レポート データベースに必要なストレージは、検索環境が分析を使用する方法とその頻度によって異なります。 現在の分析レポート データベースのストレージ量をガイドラインとして使用してください。 | 小規模展開の場合は 8 GB。 中規模展開の場合は 16 GB。 |
64 ビット、4 コア | 2 Gbps |
ストレージ パフォーマンスの計画
ストレージの速度は検索のパフォーマンスに影響します。 ご使用のストレージが、検索コンポーネントおよびデータベースからのトラフィックを処理するのに十分な速度であることを確認してください。 ディスク速度は、IOPS (1 秒あたりの I/O 操作数) で測定されます。
検索コンポーネントおよびストレージのオペレーティング システムからデータをどのように分散するかによって、検索パフォーマンスに影響が出ます。 以下のようにすることをお勧めします。
Windows Server オペレーティング システム ファイル、SharePoint Server 2016 プログラム ファイル、および診断ログを、通常のパフォーマンスの 3 つの別個のストレージ ボリュームまたはパーティションに分割します。
検索コンポーネントのデータを別個のストレージ ボリュームまたはパーティションに保存します。 インデックス コンポーネントの場合、このストレージには高いパフォーマンスも必要となります。
注:
SharePoint Server 2016 をホストにインストールするとき、検索コンポーネント データ用にカスタムの場所を設定できます。 ホスト上の検索コンポーネントは、データを保存する必要がある場合、この場所に保存します。 この場所を後で変更する場合は、SharePoint Server 2016 を再インストールする必要があります。
ストレージの種類を選択する
ストレージのアーキテクチャおよびディスクの種類についての概要は、「ストレージおよび SQL Server の容量計画と構成 (SharePoint Server 2016)」をご覧ください。 インデックス コンポーネント、分析処理コンポーネント、および検索管理コンポーネント、または検索データベースをホストするサーバーでは、十分な IOPS (1 秒あたりの I/O 操作数) を確保しながら短い待機時間を維持できるストレージが必要とされます。 以下の表は、これらの検索コンポーネントおよびデータベースの各々で必要とされる IOPS 数を示しています。
SAN/NAS などの共有ストレージを展開する場合、通常 1 つの検索コンポーネントのピーク ディスク負荷が別の検索コンポーネントのピーク ディスク負荷と同時に発生します。 共有ストレージから検索が必要とする IOPS 数を取得するには、これらのコンポーネントそれぞれの IOPS 要件をまとめる必要があります。
検索コンポーネントの IOPS 要件
| コンポーネント名 | コンポーネントの詳細 | IOPS 要件 | 別々のストレージ ボリューム/パーティションの使用 |
|---|---|---|---|
| インデックス コンポーネント | インデックスの結合時およびクエリの処理および応答時にストレージを使用します。 | 64 KB のランダム読み取りに 300 IOPS。 256 KB のランダム書き込みに 100 IOPS。 順次読み取りに 200 MB/s。 順次書き込みに 200 MB/s。 |
はい |
| 分析コンポーネント | データをローカルで一括処理で分析します。 | いいえ | はい |
| クロール コンポーネント | ダウンロードされたコンテンツをコンテンツ処理コンポーネントに送信する前にローカルに保存します。 ストレージはネットワーク帯域幅に制限されます。 | いいえ | はい |
検索データベースの IOPS 要件
| データベース名 | IOPS 要件 | I/O サブシステムでの一般的な負荷。 |
|---|---|---|
| クロール データベース | 中~高レベルの IOPS | 1 DPS (1 秒あたりのドキュメント) クロール レートあたり 10 IOPS |
| リンク データベース | 中速度の IOPS | 検索インデックスにおいて 100 万アイテムにつき 10 IOPS。 |
| 検索管理データベース | 低速度の IOPS | なし。 |
| 分析レポート データベース | 中速度の IOPS | なし。 |
検索アーキテクチャがどのように高可用性をサポートするかを選択する
高可用性の戦略について理解できていない場合には、はじめに「SharePoint Server の高可用性のアーキテクチャと戦略を作成する」の記事をお読みください。 冗長検索コンポーネントとデータベースを別々の障害ドメインでホストしている場合、ファームの一部で機能が停止しても、サービス全体が使用不可になることはありません。 ただし、検索コンポーネントが負荷を共有できなくなるために、検索のパフォーマンスは低下します。 1 台のサーバーを失う可能性を減らすためには、ローカルの冗長性を向上させることを推奨します。 検索アーキテクチャ内のホスト サーバーごとに、以下を行ってください。
各サーバー上で RAID ストレージを使用する。
各サーバー上に複数の冗長ネットワーク接続をインストールする。
専用配線を持つ複数の冗長電源装置をインストールするか、各サーバーに無停電電源装置 (UPS) をインストールする。
すべてのサンプルの検索アーキテクチャは、個別のサーバー上で冗長検索コンポーネントをホストしています。 サンプルの検索アーキテクチャでは、各ホスト ペアの右側のホストが冗長です。 次の図は、冗長ホストの概要が示された大規模な検索アーキテクチャです。