注意
2025 年 5 月以降、アクションのドキュメントから情報を抽出はドキュメントを処理に名称が変わります。
Power Automate でドキュメント処理モデルを使用するには、次の手順に従います。
Power Automate にサインインします。
+作成>インスタント クラウド フロー を選択します。
手動でフローを起動する>作成を選択します。
手動でフローをトリガーするを選択し、左側ペインの +入力の追加>ファイルを選択します。
デザイナーで、+ の後にフローを手動でトリガーするを選択し、アクションの一覧でドキュメントを処理するを選択します。
使用するドキュメント処理モデルを選択し、ドキュメントの種類を選択します。
フォーム フィールドで、トリガーから
File Contentを追加します。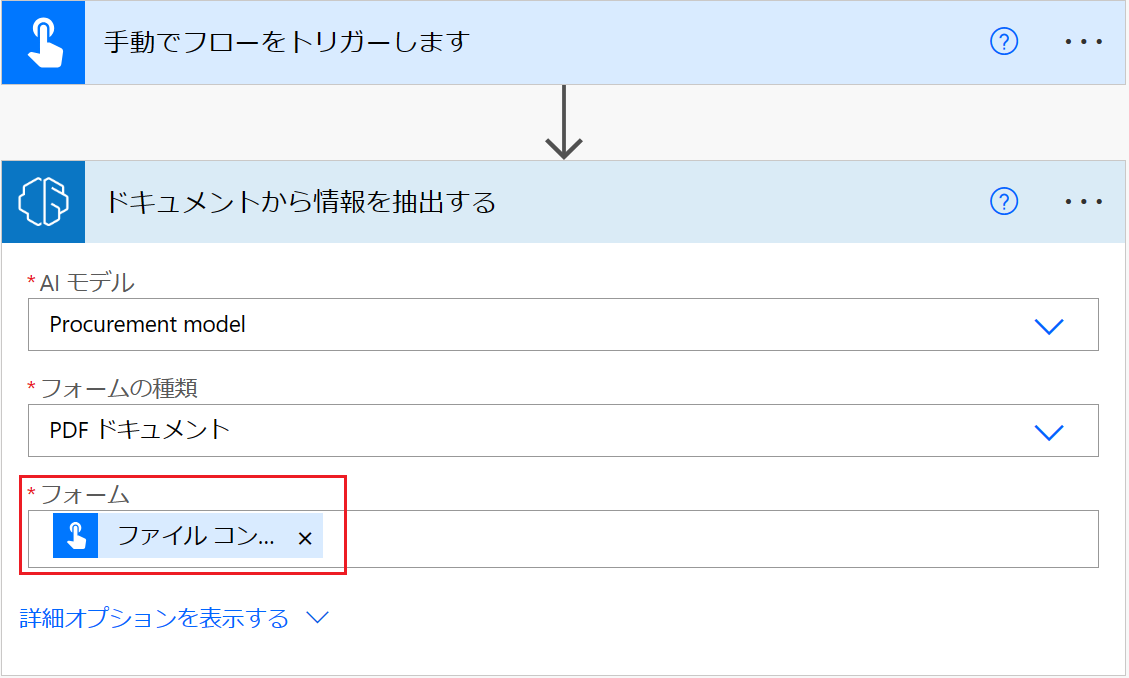
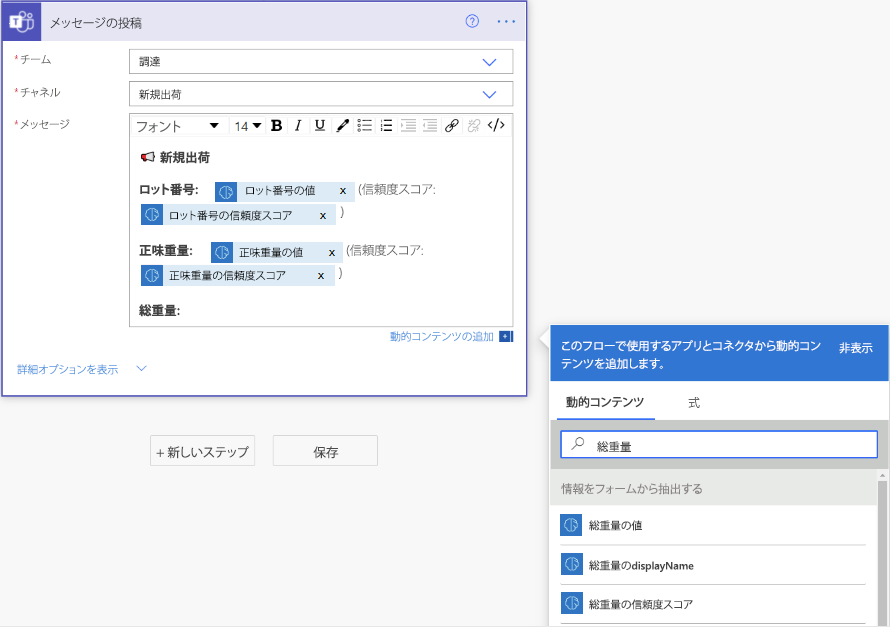
後続のアクションでは、AI Builder モデルによって抽出されたいずれかのフィールドとテーブルを使用できます。 たとえば、モデルが
InvoiceIDとTotalの値を抽出するようにトレーニングされているとします。 また、AI Builder がドキュメントからそれらを抽出した後 Microsoft Teams チャネルへ投稿するとします。 チャットまたはチャネルにメッセージを投稿する アクションを追加してから、AI Builder モデルからの出力フィールドを追加する必要があります。注意
- フィールドの値を取得するには、<field_name> の値 を選択します。
- 抽出した項目の信頼度スコアを取得するには、<field_name> 信頼度スコア を選択します。
ご報告: AI Builder のドキュメント処理モデルを使用するフローを作成できました。 右上にある保存を選択し、テストを選択してフローを試します。
ページ範囲
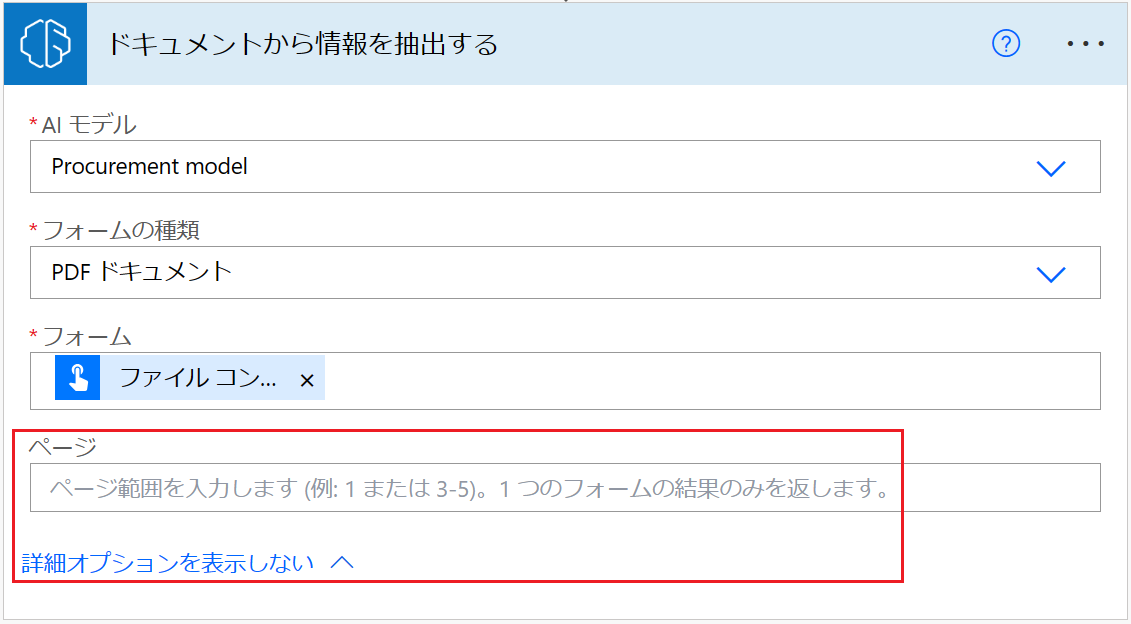
複数のページが含まれるドキュメントの場合、処理するページ範囲を指定できます。
プロセス ドキュメント カードで、詳細パラメーターを選択し、次に ページを選択します。
ページ パラメーターに、ページ値またはページ範囲を入力できます。 例: 1 または 3-5。
注意
フォームが 1 つしかない大きなドキュメントがある場合は、ページ パラメータを使用します。 これを行うと、モデル予測のコストを削減でき、パフォーマンスを向上させることができます。 ただし、正しいデータを返すアクションの一意のフォームがページ範囲に含まれる場合です。
例: ドキュメントには、2 ページに最初のフォームが含まれ、3 ページと 4 ページにまたがって 2 番目のフォームが含まれています。
- ページ範囲 2 を入力すると、最初のフォームのデータが返されます。
- ページ範囲 3-4 を入力すると、2 番目のフォームのデータのみが返されます。
- ページ範囲 2-4 を入力すると、最初と 2 番目のフォームの部分的なデータが返されます (これは避ける必要があります)。
入力パラメーター
| 件名 | Required | タイプ | プロパティ | Values |
|---|---|---|---|---|
| AI モデル | はい | モデル | 分析に使用するドキュメント処理モデル | トレーニングおよび発行されたドキュメント処理モデル |
| ドキュメントの種類 | はい | リスト | 分析するフォームのファイルの種類 | PDF ドキュメント (.pdf)、JPEG 画像 (.jpeg)、PNG 画像 (.png) |
| フォーム | 有効 | file | 処理するフォーム | |
| ページ | いいえ | string | 処理するページ範囲 |
出力パラメーター
| 件名 | タイプ | プロパティ | Values |
|---|---|---|---|
| {field} 値 | string | AI モデルにより抽出された値 | |
| {field} 信頼度スコア | 浮動小数 | モデルが予測にどの程度信頼されているかを示す | 0 から 1 の範囲の値。 1 に近い値は、抽出された値が正確であるという、より高い信頼度を示します |
| {table}{column} 値 | string | テーブル内のセルの AI モデルによって抽出された値 | |
| {table}{column} 信頼度スコア | 浮動小数 | モデルが予測にどの程度信頼されているかを示す | 0 から 1 の範囲の値。 1 に近い値は、抽出されたセル値が正確であるという、より高い信頼度を示します |
注意
フィールド座標、ポリゴン、バウンディング ボックス、ページ番号など、より多くの出力パラメータを提案できます。 これらは、主に高度な使用を目的としているため、意図的にリストされていません。
座標は、左上隅からのドキュメントの高さと幅のパーセンテージとして表されます。 たとえば、座標 X = 0.10 および Y = 0.20 が指定された場合、これは、X 軸に沿ってドキュメントの幅の 10%、Y 軸に沿って高さの 20% の位置を意味します (どちらも左上から測定) コーナー。
一般的なユース ケース
Power Automate で出力されたドキュメント処理テーブルを繰り返す
この手順を説明するために、ドキュメント処理モデルを学習させて、項目と名付けた 3 列のテーブルを抽出した次の例を使用します: 量、説明、合計。 テーブルの各ラインアイテムを Excel ファイルに保存したいと思います。

テーブルのセルに書き込むフィールドを選択します。 動的コンテンツ パネルが開き、ドキュメント処理モデルが抽出する方法を知るすべてのものが表示されます。 {テーブル名} {列名} 値を検索します。
Items Quantity valueを使用する例。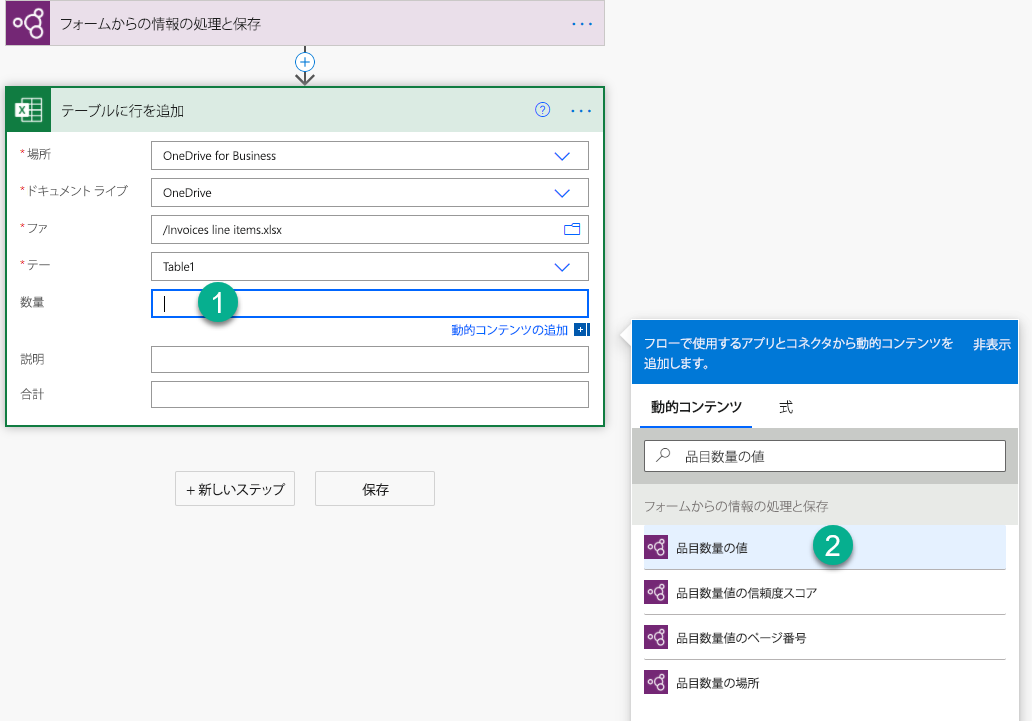
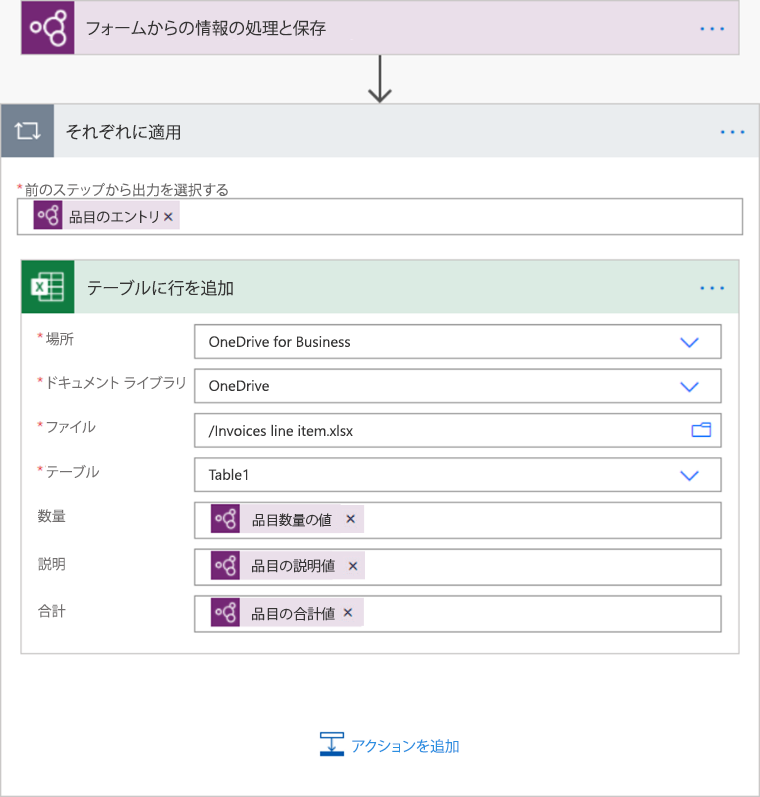
この値を追加すると、追加したアクションが自動的に Apply to each コントロールに挿入されます。 このように、フローの実行時にテーブルのすべての行が処理されます。
繰り返したい列を追加し続けます。
Power Automate のチェックボックスの出力処理
チェックボックスの値はブール値で、true はそのチェックボックスがドキュメントで選択済みとマークされていることを意味し、false は選択されていないことを意味します。
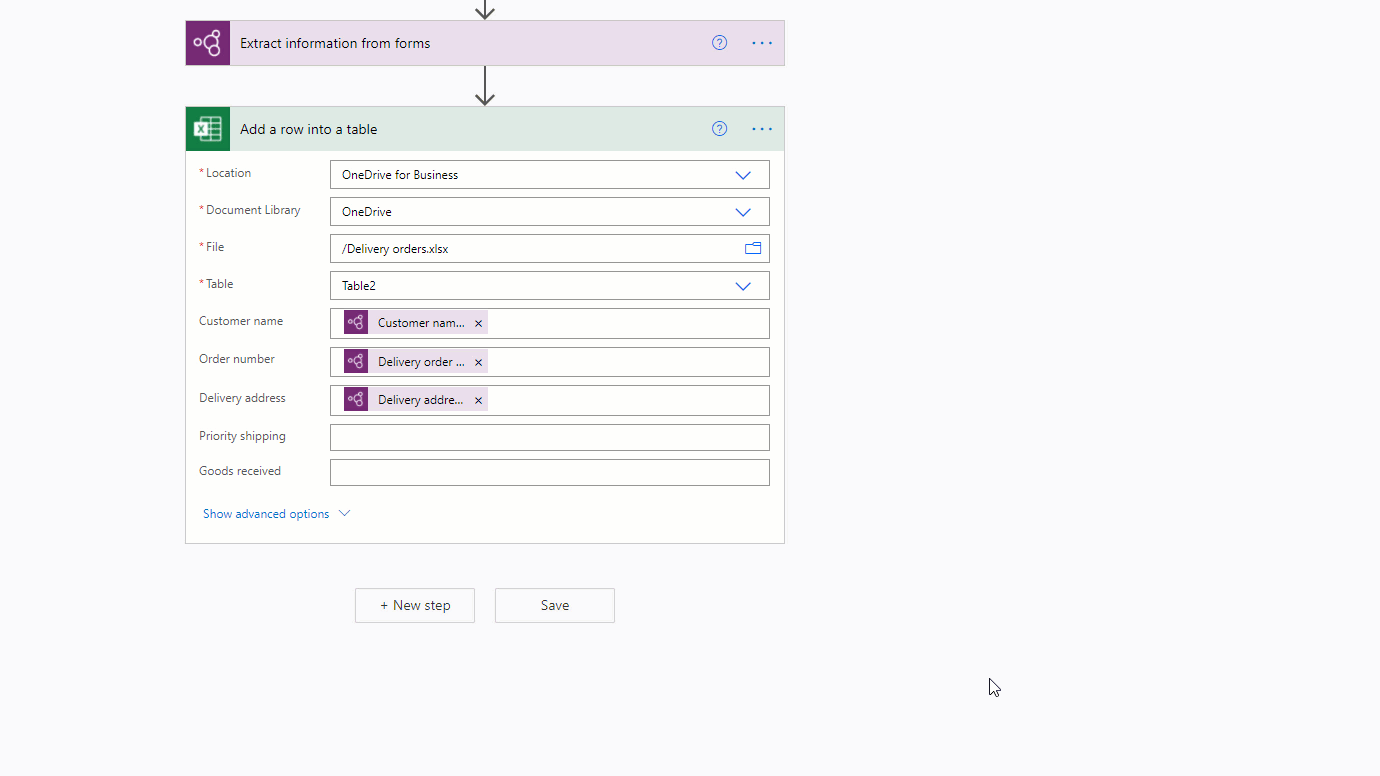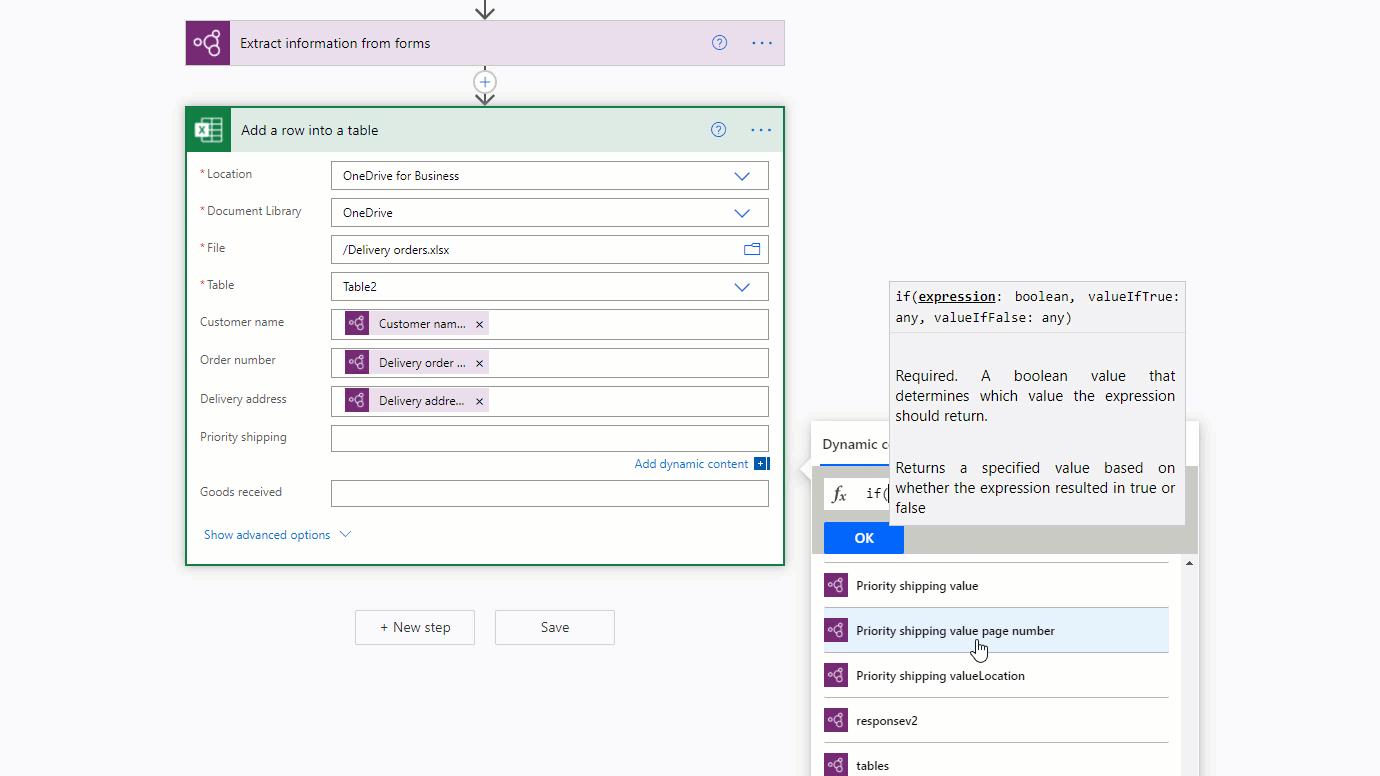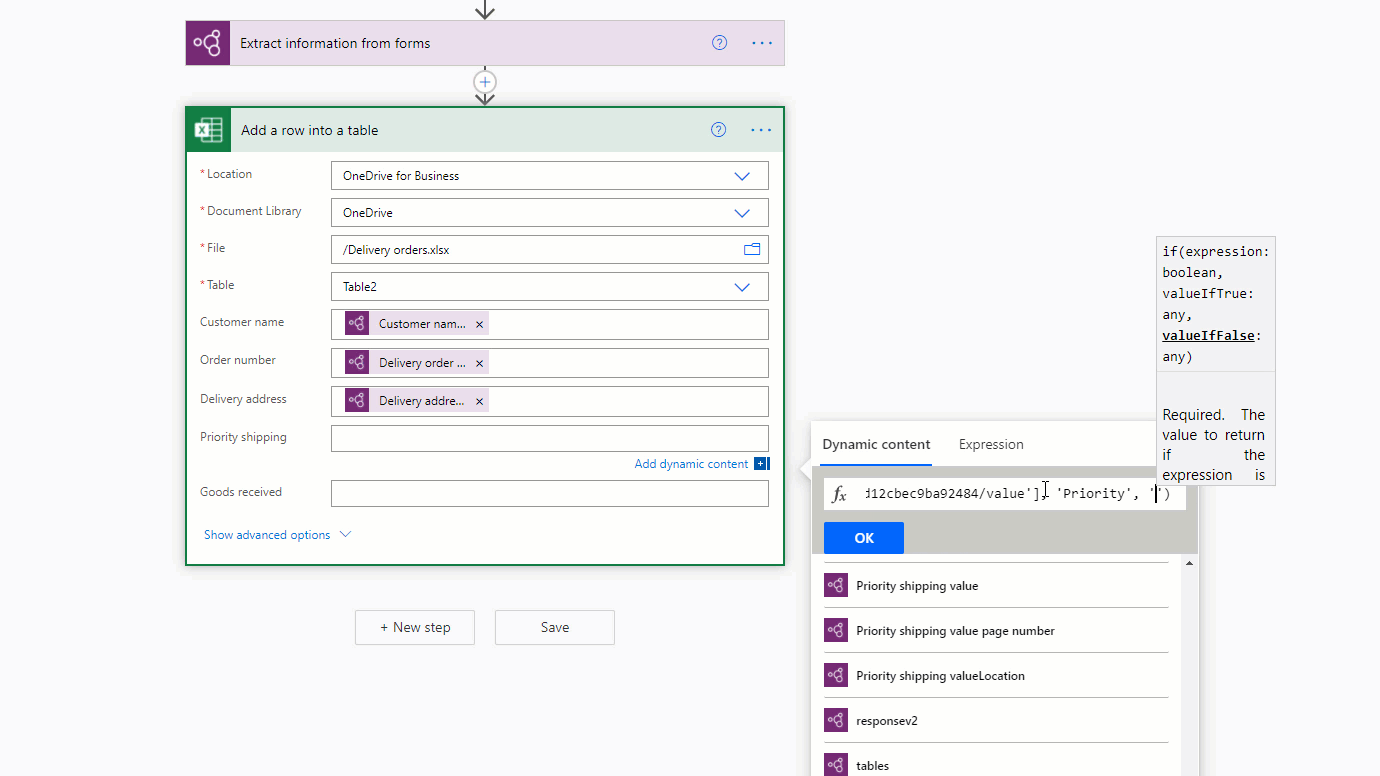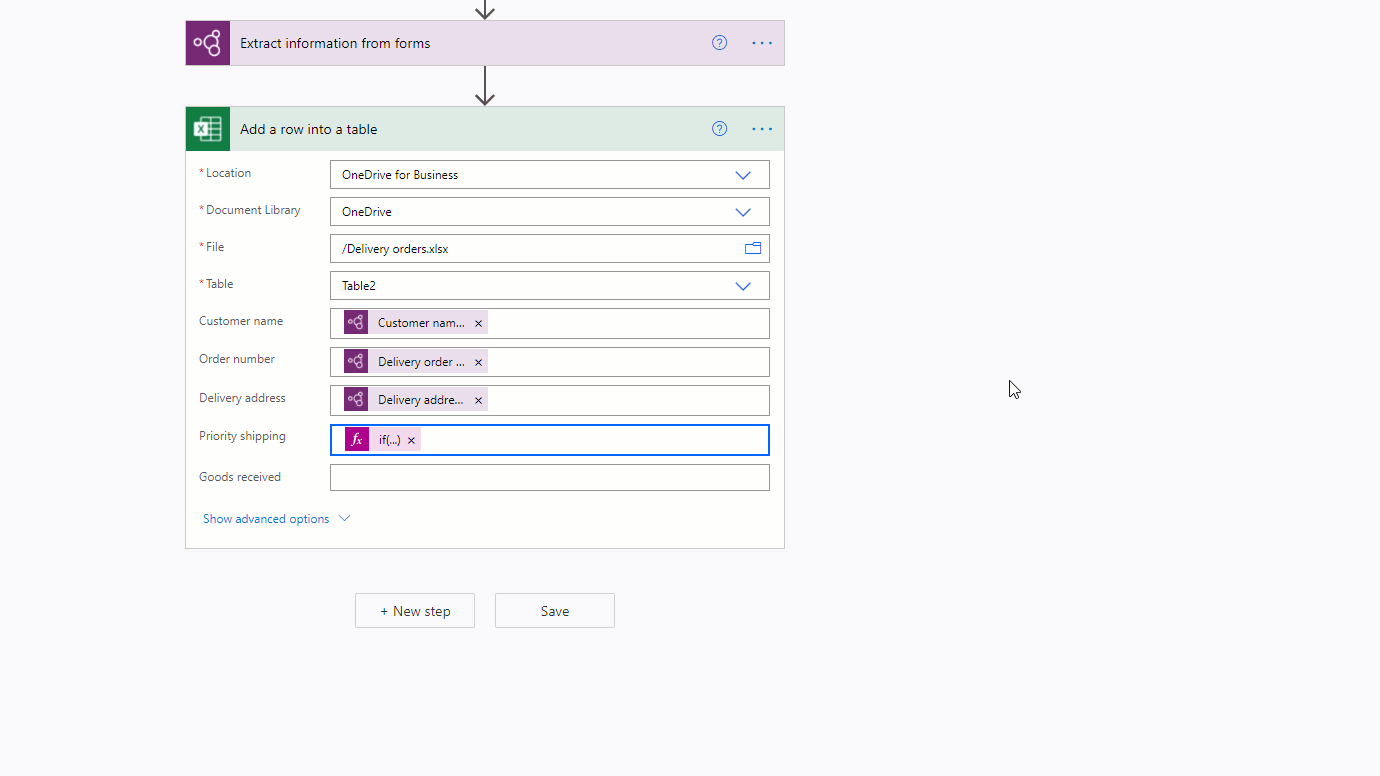
その値を確認する方法のひとつとして、条件 アクションがあります。 チェックボックスの値が true の場合、1 つのアクションを実行します。 値が false の場合は、別のアクションを実行します。 次の図では、例を示しています。
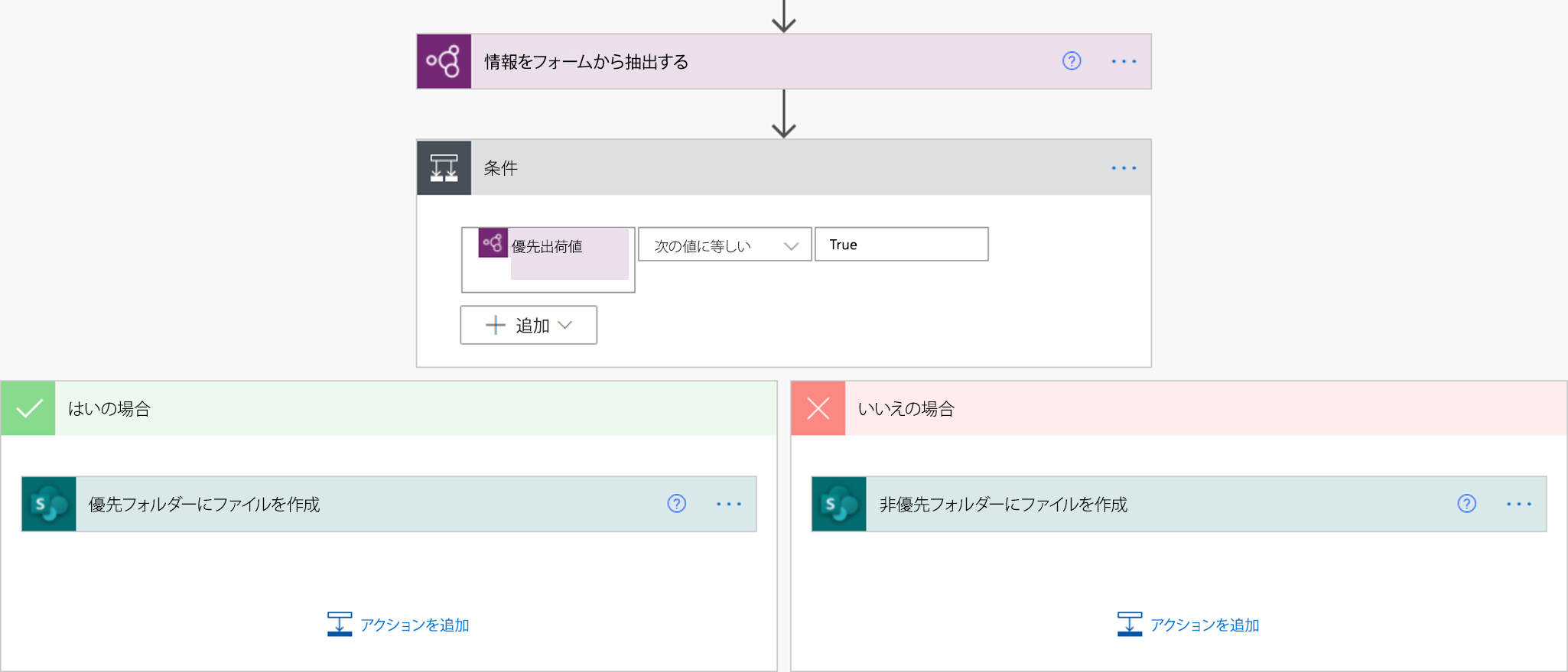
また、if 式を使って、チェックボックスの true/false 出力を他の任意の値にマッピングする方法もあります。 たとえば、Excel ファイルの列で、ドキュメント内のチェックボックスの 1 つが選択されていれば「優先」、選択されていなければ「非優先」と書きたい場合があるとします。 これは、次の式を使って行うことができます: if(<document processing output>, 'Priority', 'Non-priority')。 次のアニメーションで、例を示しています。
Power Automate にあるドキュメント処理出力の通貨記号 (€, $,…) を削除する
たとえば、ドキュメント処理モデルで抽出された 合計 値には、$54 などの通貨記号が含まれる場合があります。 省略する $ 記号やその他の記号を削除するには、replace 式を使用して削除します。 方法は以下のとおりです。
replace(<document processing output>, '$', '')

ドキュメント処理の出力文字列を、Power Automate の数字に変換する
AI Builder ドキュメント処理では、抽出されたすべての値が文字列として返されます。 AI Builder ドキュメント処理によって抽出された値を保存したいコピー先で数値が必要な場合、int または float 表現を使い値を数値に変換できます。 数値に小数点がない場合は、int を使用します。 数値に小数がある場合は、浮動を使用します。 その方法は次のとおりです。
float('<document processing output>')
Power Automate で出力されたドキュメント処理モデルの空白スペースを削除します
出力値から空白を削除するには、replace 関数を使用します:
replace(<document processing output>, ' ', '')

ドキュメント処理の出力文字列を、Power Automate の日付に変換する
AI Builder ドキュメント処理では、すべて出力が文字列として返されます。 ドキュメント処理によって抽出された値を保存するコピー先が日付形式である必要がある場合は、日付を含む値を日付形式に変換できます。 これを行うには、formatDateTime 式を使用します。 その方法は次のとおりです。
formatDateTime(<document processing output>)

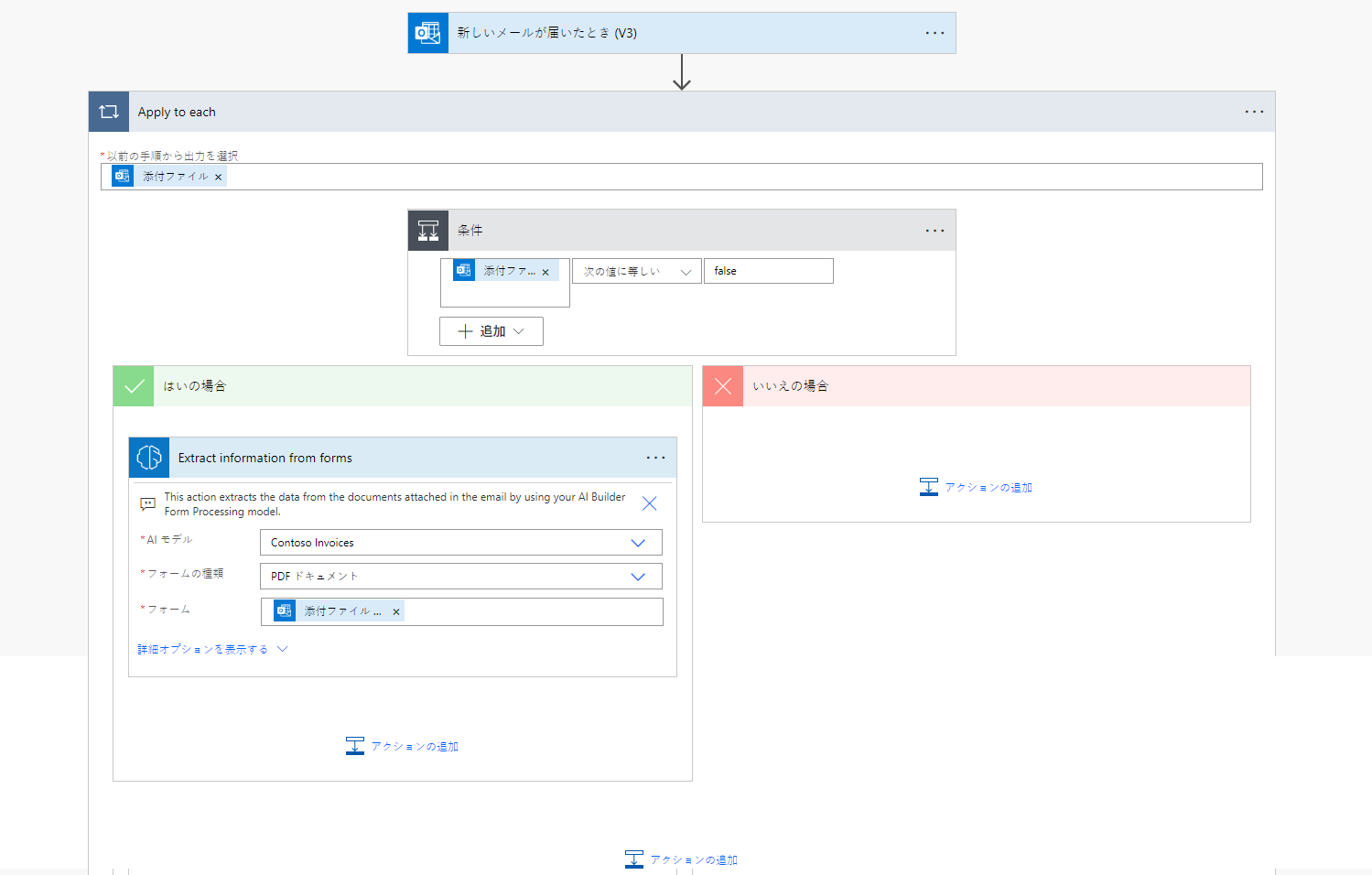
フローからのメール署名をフィルターして、ドキュメント処理モデルで処理されないようにすることができます (Microsoft 365 Outlook)
Microsoft 365 Outlook コネクタからの受信メールの場合、メールの署名は Power Automate によって添付ファイルとして取得されます。 これらがドキュメント処理モデルで処理されないようにするには、添付ファイルはインライン という名前の Microsoft 365 Outlook コネクタからの出力が false に等しいかどうかを確認する条件をフローに追加します。 条件の はいの場合 分岐で、ドキュメント処理アクションを追加します。 これにより、インライン署名ではない、メールの添付ファイルのみが処理されるようになります。