モデルのパフォーマンスが意図したとおりではない場合 (たとえば、悪い結果が得られたり、信頼度スコアが低いなど) は、いくつかのことを試してみてください。
モデルの精度スコアの解釈
精度スコアを解釈して、モデルが抽出に苦労しているものを特定します。 モデルの評価には、スコアを上げるための推奨事項が含まれます。
Power Apps または Power Automate にサイン インします。
左のペインで ... その他>AI ハブ を選択します。
AI 機能の検出 で AI モデル を選択します。
(オプション) AI モデル をメニュー上に常時表示してアクセスしやすくするには、ピン アイコンを選択します。
調査するドキュメント処理モデルを開きます。 精度スコアが表示されます。
Note
次の場合、ドキュメント処理モデルの精度スコアは取得されません。
- モデルがドキュメントの種類として [全般ドキュメント] を選択してトレーニングされた場合。 現在、精度スコアは、"固定テンプレート ドキュメント" 型のモデルに対してのみ返されます。
- モデルが別の環境からインポートされました。
- モデルが 2022 年 1 月 1 日より前にトレーニングされた場合。 この場合、再トレーニングできます。
モデルの詳細ページで、一般的な精度スコアを取得する必要があります。
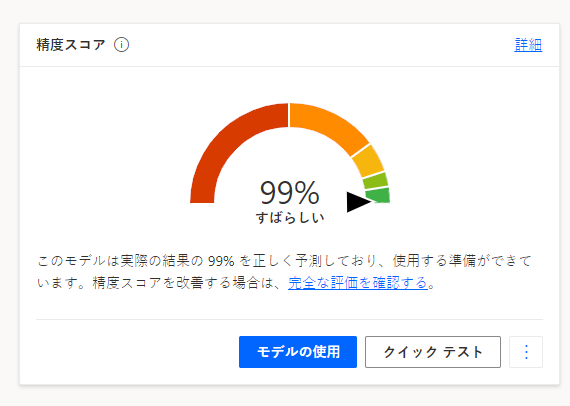
詳細を取得するには、完全な評価を確認するを選択します。
![[モデル評価] 画面の [概要] タブのスクリーンショット。](media/improve-the-performance-of-your-form-processing-model/model-evaluation.png)
このパネルでは、さまざまなタブ間を移動して、モデルが抽出に苦労しているものを特定できます。 コレクション、フィル度、テーブル、チェックボックスタブを参照し、正しく処理されていないものを見つけることができます。
フィールド タブの情報の例を次に示します。
![[モデル評価] 画面の [フィールド] タブのスクリーンショット。](media/improve-the-performance-of-your-form-processing-model/field-evaluation.png)
この例では、ベンダー 情報の精度を向上させる必要があります。
![[フィールド] タブの精度スコアが低いスクリーンショット。](media/improve-the-performance-of-your-form-processing-model/field-evaluation-poor.png)
精度スコアの低い項目の上にマウス ポインターを置くことで、モデルの表示を改善するためにできることに関する提案。 たとえば、トレーニング用の サンプル ドキュメントをさらに提供 する推奨事項が表示される場合があります。
よく寄せられる質問
フィールド、テーブル、またはチェックボックスの精度スコアが低い場合はどうすればよいですか?
- すべてのドキュメントでフィールド、テーブル、またはチェックボックスが正しくタグ付けされていることを確認します。
- フィールド、テーブル、またはチェックボックスが存在するトレーニングにサンプル ドキュメントをさらに提供します。
- ベスト プラクティスを確認します。
コレクションの精度スコアが低い場合はどうすればよいですか?
コレクション内のドキュメントがすべて同じレイアウトになっていることを確認してください。 コレクションの詳細については、コレクションごとにドキュメントをグループ化する にアクセスしてください。
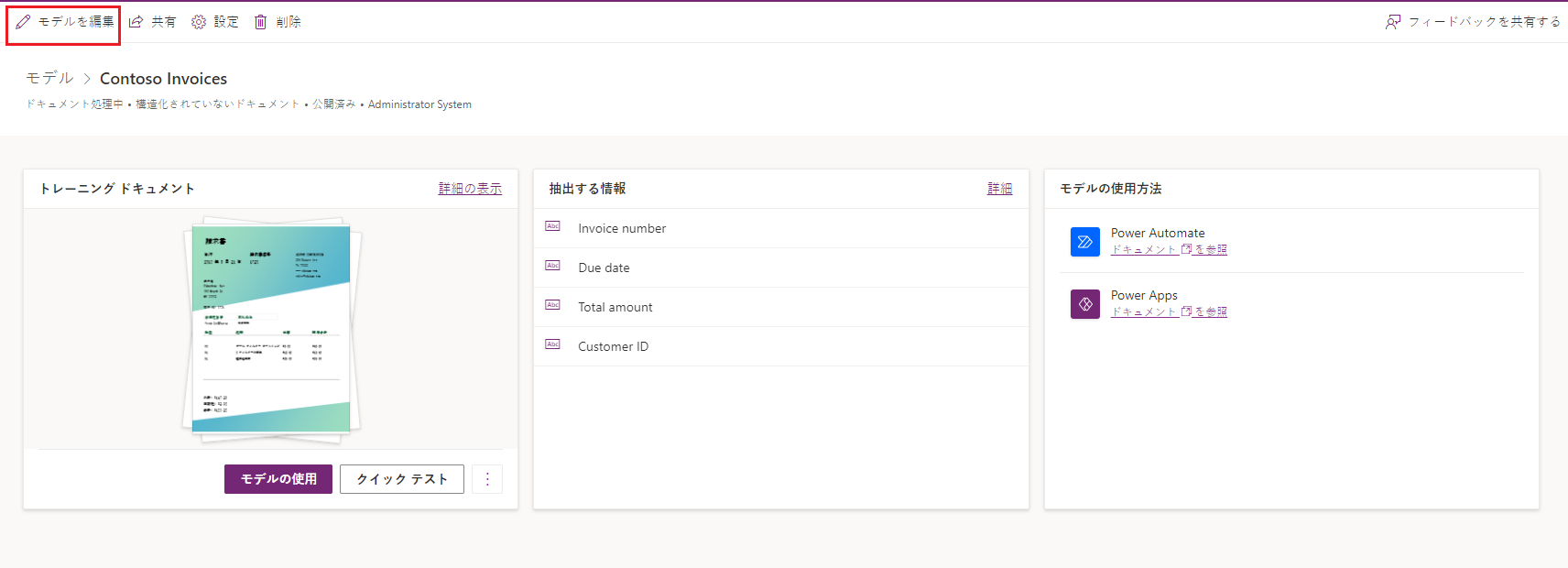
トレーニング データにさらにドキュメントを追加する
タグを付けるドキュメントが多いほど、AI Builder はフィールドをよりよく認識する方法を学習します。 さらにドキュメントを追加するには、ドキュメント処理モデルを編集して、ドキュメントをアップロードします。 モデルの詳細ページにモデルを編集するオプションがあります。
その他のヒント
- 記入済みフォームの場合は、すべてのフィールドが記入されている例を使用します。
- 各フィールドで異なる値のフォームを使用します。
- フォーム画像の品質が低い場合は、より大きなデータ セット (たとえば、10-15 枚の画像) を使用します。
- 可能であれば、画像ベースのドキュメントの代わりにテキスト ベースの PDF ドキュメントを使用します。 スキャンした PDF は画像として扱われます。
- 新しいドキュメント処理モデルを作成する場合は、各ドキュメントが個別のインスタンスである同じレイアウトのドキュメントをアップロードします。 たとえば、異なる月からの請求書は、すべて同じドキュメントにあるのではなく、別々のドキュメントにある必要があります。
- トレーニング用のサンプルをアップロードする場合、レイアウトが異なるドキュメントは異なるコレクションに移動します。
- ドキュメント処理モデルが、モデルで抽出するフィールドの隣接するフィールドから値を抽出する場合は、モデルを編集し、誤って取得されている隣接する値を、別のフィールドとしてタグ付けします。 これを行うことにより、モデルは各フィールドの境界をより適切に学習します。