要件 の確認後、ドキュメント処理モデルの作成を開始できます。
ウィザードを使用してモデルを作成する
ドキュメント処理モデルは、カスタム モデルの作成ウィザードを使用して作成できます。 ウィザードは、ドキュメントから情報を抽出するモデルを作成するプロセスをガイドします。
Power Apps または Power Automate にサイン インします。
左のペインで ... その他>AI ハブ を選択します。
(オプション) AI モデルをメニューに常時表示し、簡単にアクセスできるようにするには、AI ハブの横にあるピン アイコンを選択します。
AI 機能の検出 で AI モデル を選択します。
ドキュメントからカスタム情報を抽出するを選択します。
カスタム モデルの作成 を選択します。
ステップ バイ ステップのウィザードは、ドキュメントから抽出するすべてのデータを一覧表示するように求めることで、プロセスを説明します。
詳細については、この記事のドキュメントの種類の選択セクションを参照してください。
独自のドキュメントを使用してモデルを作成する場合は、同じレイアウトを使用するサンプルが 5 つ以上あることを確認してください。 それ以外の場合は、サンプル データを使用して モデルを作成できます。
トレーニングを選択します。
クイック テストを選択してモデルをテストします。
ドキュメントの種類を選択します
ドキュメントの種類を選択の手順で、データ抽出を自動化するために AI モデルを構築するドキュメントの種類を選択します。 固定テンプレート ドキュメント、一般ドキュメント、請求書の 3 つのオプションがあります。
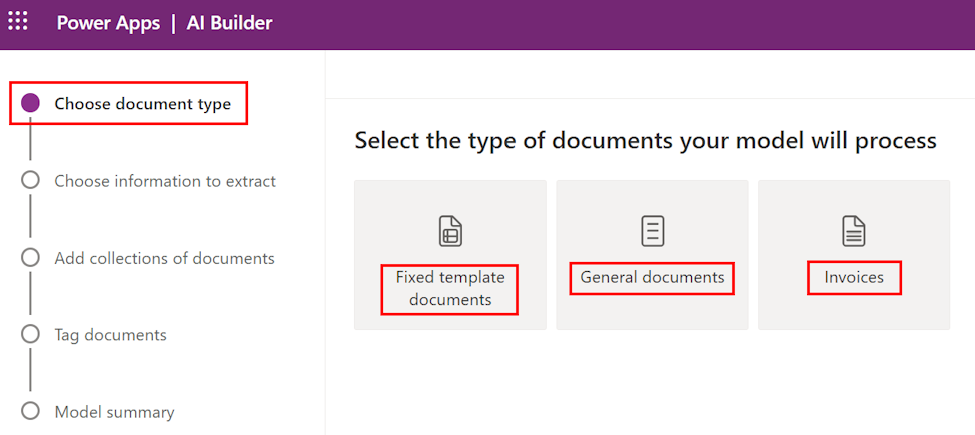
- 固定テンプレート ドキュメント: 以前は構造化と呼ばれていたこのオプションです。特定のレイアウトで、フィールド、テーブル、チェックボックス、署名、およびその他の項目が同様の場所にある場合に最適です。 このモデルに、さまざまなレイアウトの構造化ドキュメントからデータを抽出するように教えることができます。 このモデルはトレーニング時間が短いです。
- 汎用ドキュメント: 以前は非構造化と呼ばれていましたが、このオプションは、特に構造が設定されていない場合や形式が複雑な場合など、あらゆる種類のドキュメントに適しています。 このモデルに、さまざまなレイアウトの構造化または非構造化ドキュメントからデータを抽出するように教えることができます。 このモデルは強力ですが、トレーニング時間が長くなります。
- 請求書: デフォルト のフィールドに加え、抽出する新しいフィールドや、適切に抽出されなかったドキュメントのサンプルを追加して、事前構築済みの請求書処理の動作を拡張します。
ドキュメント インテリジェンスのバージョンについて
ドキュメント インテリジェンス モデルには、v4.0 と v3.1 の 2 つのバージョンがあります。 モデルのバージョンは、モデルを最後に編集した日時によって異なります。
Document Intelligence v4.0 - 一般提供 (GA)
この記事に記載されている機能に加えて、v4.0 では v3.1 のすべての機能が保持されています。
- 重複するフィールド: v4.0 では、カスタムモデルのオーバーラップ フィールドがサポートされ、複雑なレイアウトのドキュメントからより効果的に情報を抽出できます。
- 署名検出: v4.0 は、ドキュメント内の署名を検出します。これは、契約書、合意書、その他の署名されたフォームに特に役立ちます。
- テーブルの信頼度スコア: v4.0 では、テーブルとそのセルの信頼度スコアが提供されます。
- OCR エンジンの機能強化: v4.0 では、光学式文字認識 (OCR) エンジンが改良され、テキスト認識精度が向上し、より多くのドキュメント タイプと形式をサポートします。
Document Intelligence v3.1 の一般提供 (GA)
- v3.1は、一意のテキストフィールドや構造など、特定のデータパターンを認識するようにトレーニングされたカスタムモデルをサポートしています。
- v3.1 には、ユーザーがドキュメントのレイアウトと構造に基づいてテンプレートを作成できるカスタム テンプレート モデルが含まれています。
モデルのバージョンを確認する
モデルのトレーニングと公開に使用されたバージョンを確認できます。 これを行うには、設定>発行済みモデル バージョン>最後にトレーニングされたモデル バージョンを選択します。
![最後に公開されたモデル バージョンの GA と最後にトレーニングされたモデル バージョンの GA を取得するための [モデル設定] パネルのスクリーンショット。](media/create-form-processing-model/model_settings1.png)
モデルを v3.1 から v4.0 に移行するには、モデルを編集し、再トレーニングし、公開します。 タグの再設定やその他の特別な変更は必要ありません。 詳細情報については、ドキュメント処理モデルの FAQ を参照してください。
抽出する情報を定義する
抽出する情報の選択画面で、モデルに抽出を学習させるフィールド、テーブル、チェックボックスを定義します。 これらの定義を開始するには、+ 追加ボタンを選択します。
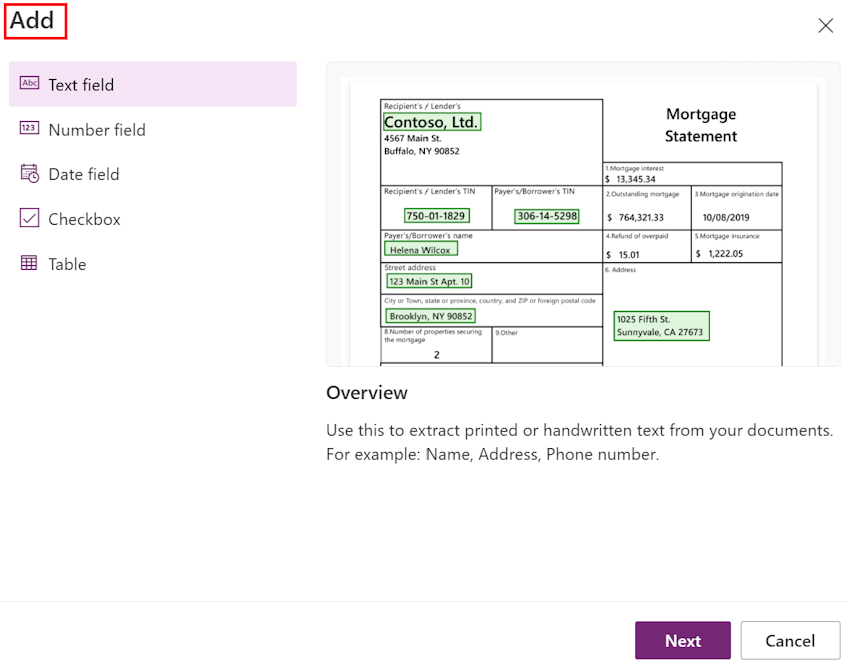
テキスト フィールドごとに、モデルで使用するフィールドの名前を指定します。
数値フィールドごとに、モデルで使用するフィールドの名前を指定します。
書式のドット (.) またはコンマ (,) を小数点として定義します。
日付フィールド ごとに、モデルで使用するフィールドの名前を指定します。
また、(年、月、日) または (月、日、年) または (日、月、年) の形式を定義します。
チェックボックスごとに、モデルで使用するチェックボックスの名前を指定します。
ドキュメント内でチェックできる項目ごとに、個別のチェック ボックスを定義します。
テーブルごとに、テーブルの名前を指定します。
モデルが抽出する必要のあるさまざまな列を定義します。
注意
カスタム請求書モデルには、編集できない既定のフィールドが用意されています。
コレクションごとにドキュメントをグループ化する
コレクション は、同じレイアウトを共有するドキュメントのグループです。 モデルで処理するドキュメント レイアウトと同じ数のコレクションを作成します。 たとえば、2 つの異なるベンダーからの請求書を処理する AI モデルを構築し、それぞれが独自の請求書テンプレートを持っている場合は、2 つのコレクションを作成します。
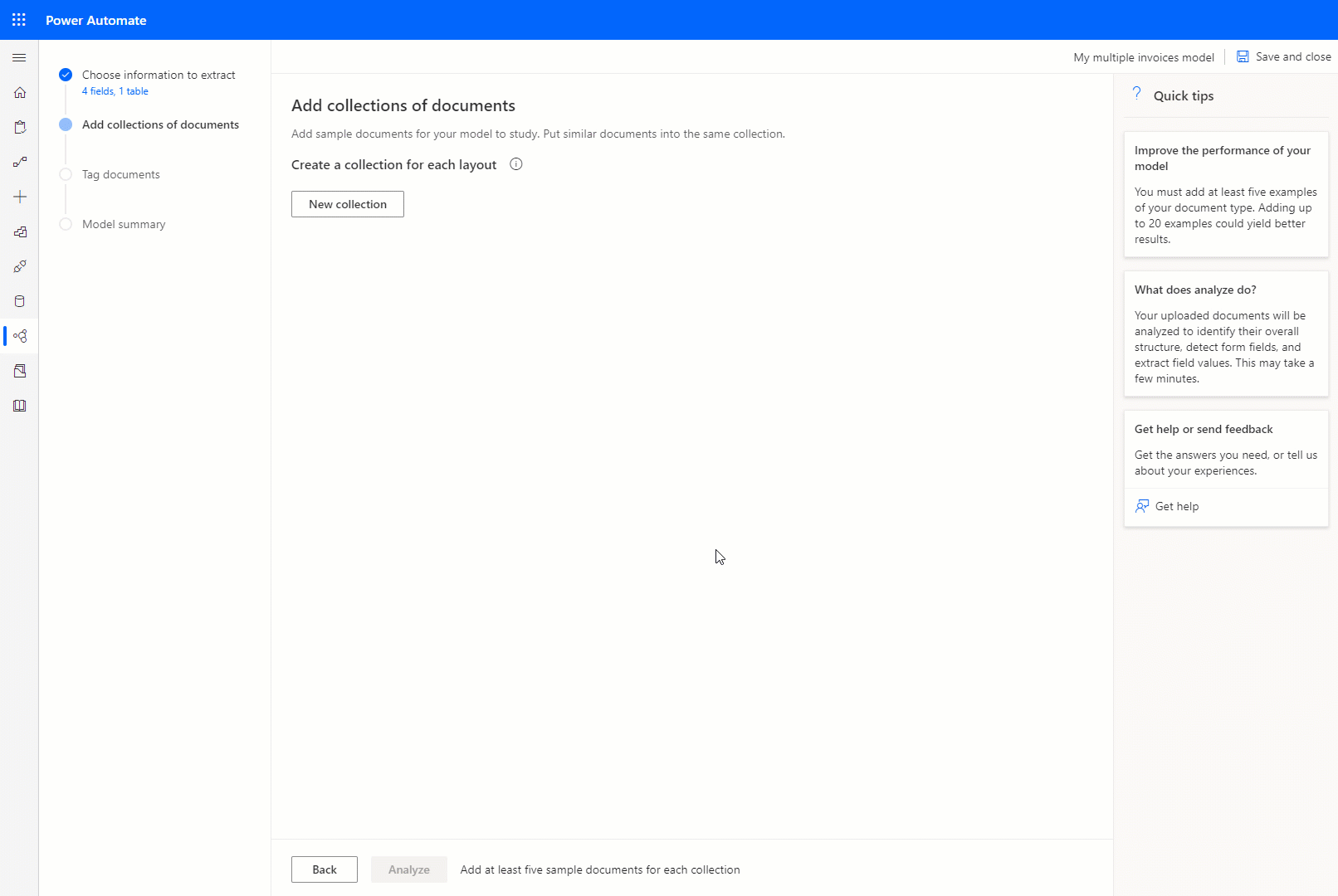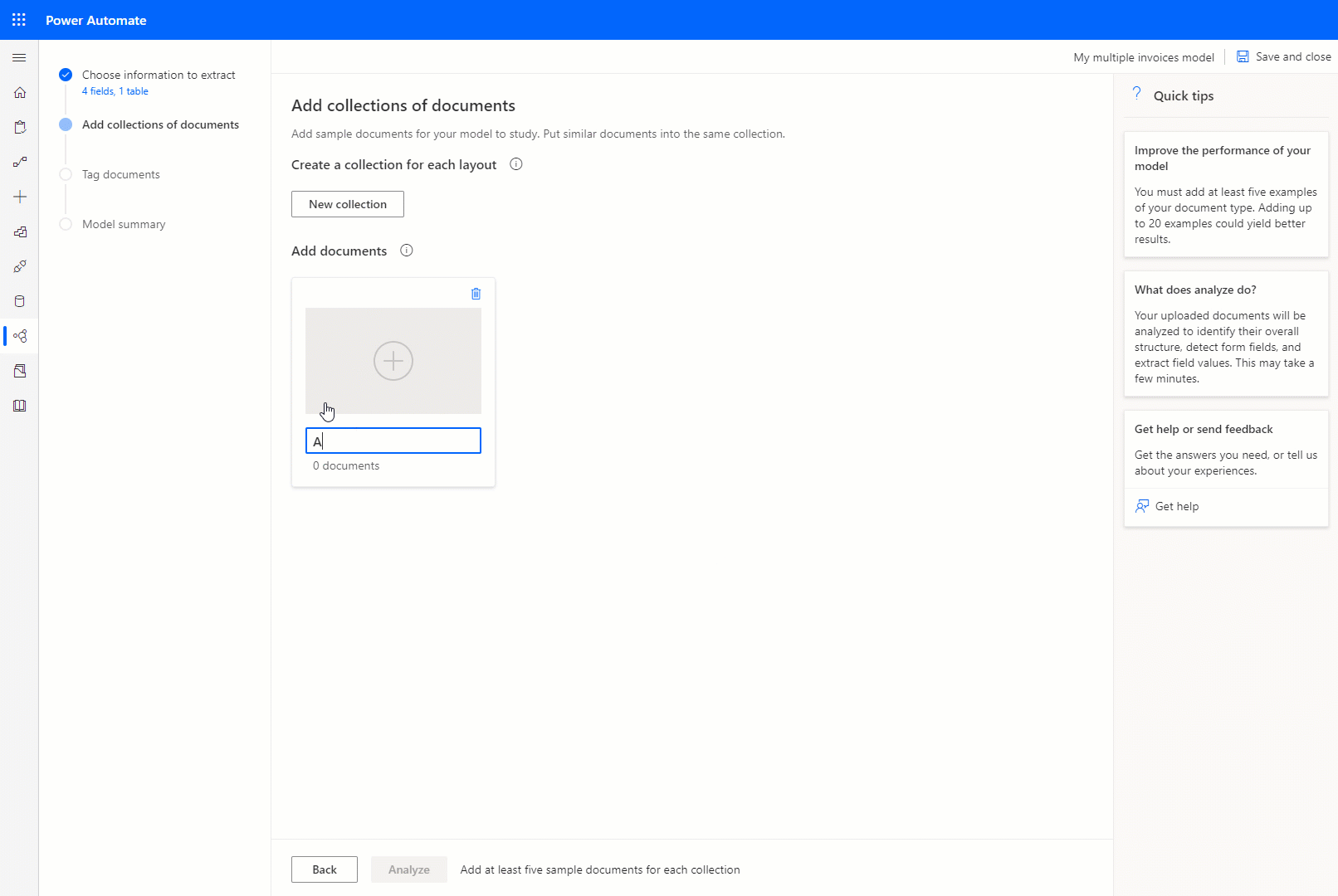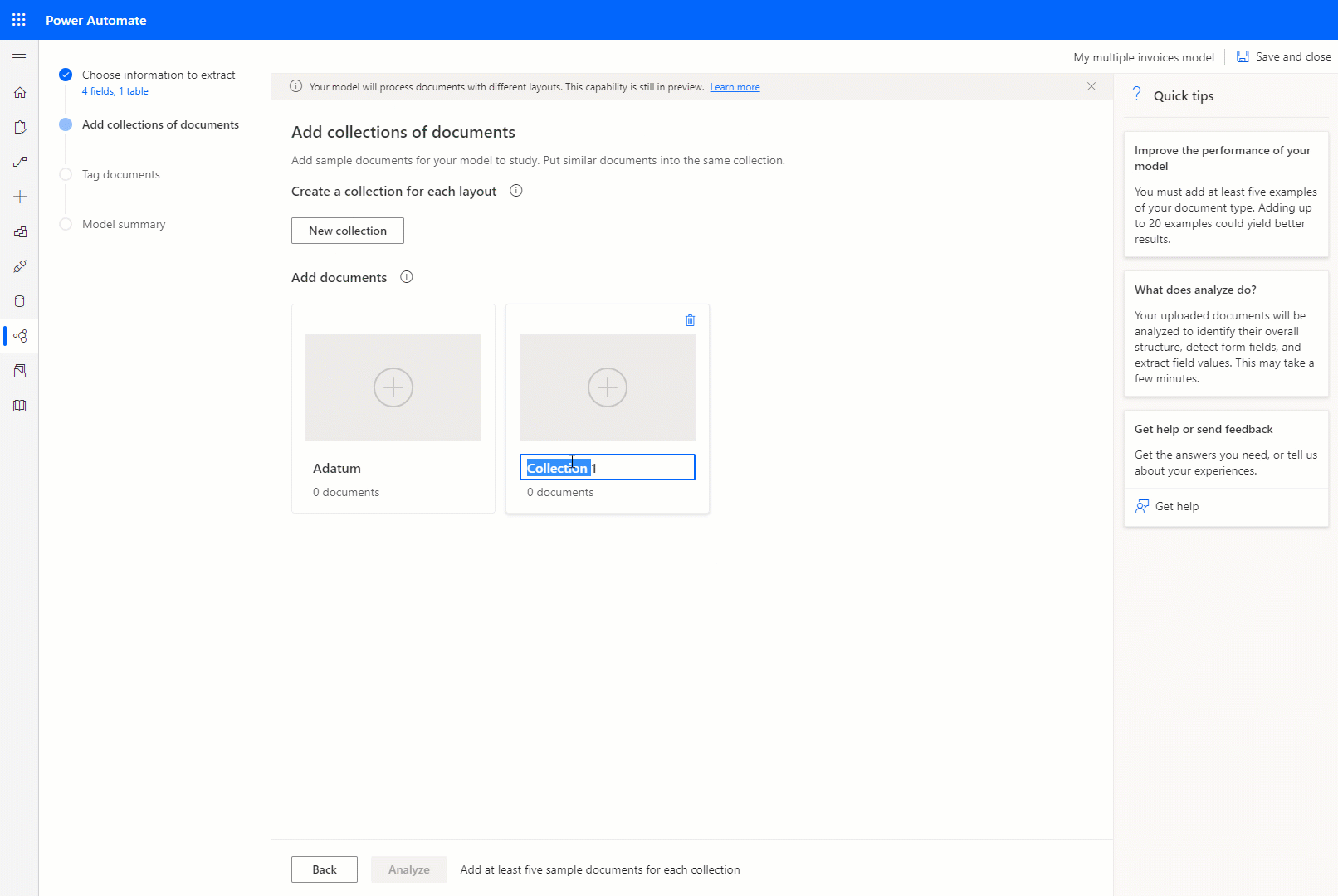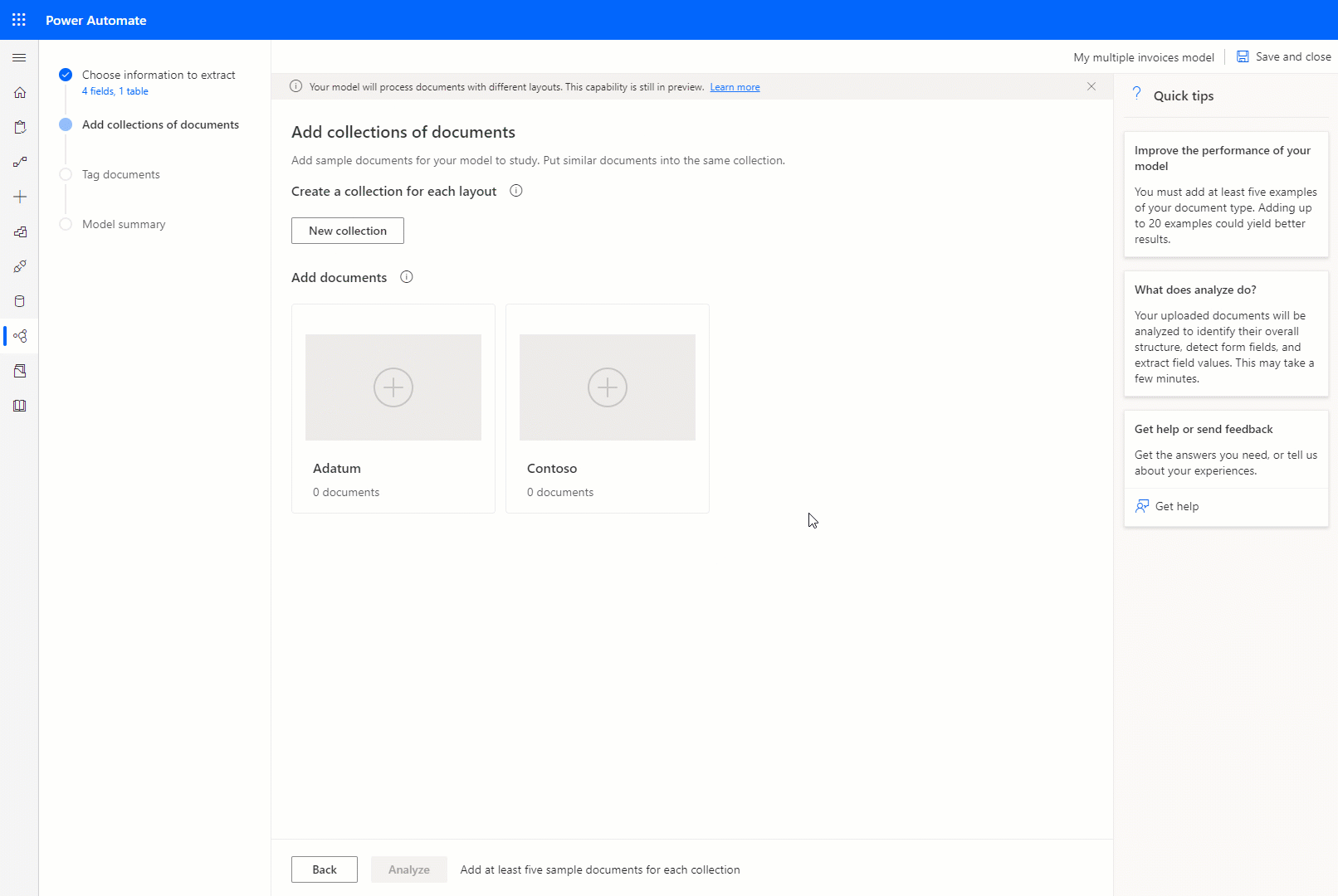
作成するコレクションごとに、1 つのコレクションにつき少なくとも 5 つのサンプル ドキュメントをアップロードする必要があります。 JPG、PNG、PDF 形式のファイルを使用できます。
注意
モデルごとに最大 200 のコレクションを作成できます。