重要
この記事で "(プレビュー)" と付記されている項目は、現在、パブリック プレビュー段階です。 このプレビューはサービス レベル アグリーメントなしで提供されており、運用環境ではお勧めしません。 特定の機能はサポート対象ではなく、機能が制限されることがあります。 詳しくは、Microsoft Azure プレビューの追加使用条件に関するページをご覧ください。
この記事では、マネージド コンピューティングを使用して、Azure AI Foundry ポータルでモデルを微調整する方法について説明します。 ファインチューニングするには、事前トレーニング済みモデルを新しい関連タスクまたはドメインに適応させる必要があります。 ファインチューニングにマネージド コンピューティングを使用する場合は、コンピューティング リソースを使用して、学習速度、バッチ サイズ、トレーニング エポックの数などのトレーニング パラメーターを調整して、特定のタスクに合わせてモデルのパフォーマンスを最適化します。
事前トレーニング済みモデルをファインチューニングして関連タスクに使用する方が、新しいモデルを構築するよりも効率的です。これは、ファインチューニングは事前トレーニング済みモデルの既存の知識に基づいており、トレーニングに必要な時間とデータが削減されるためです。
モデルのパフォーマンスを向上させるために、トレーニング データを使用して基礎モデルをファインチューニングすることを検討できます。 Azure AI Foundry ポータルのファインチューニング設定を使用して、基礎モデルを簡単にファインチューニングできます。
前提条件
注
この機能には ハブ ベースのプロジェクト を使用する必要があります。 Foundry プロジェクトはサポートされていません。 「 自分が持っているプロジェクトの種類を確認する方法 」と 「ハブ ベースのプロジェクトを作成する」を参照してください。
- Azure サブスクリプション。 Azure サブスクリプションをお持ちでない場合は、無料アカウントを作成してください。
- ない場合は、 ハブ ベースのプロジェクトを作成します。
- Azure AI Foundry ポータルでの操作に対するアクセス権を付与するには、Azure ロールベースのアクセス制御 (Azure RBAC) を使用します。 この記事の手順を実行するには、ユーザー アカウントに、Azure サブスクリプションの所有者か共同作成者ロールを割り当てる必要があります。 アクセス許可について詳しくは、「Azure AI Foundry ポータルでのロールベースのアクセス制御」をご覧ください。
マネージド コンピューティングを使用して基礎モデルをファインチューニングする
ヒント
Azure AI Foundry ポータルで 左側のウィンドウをカスタマイズ できるため、これらの手順に示されている項目とは異なる項目が表示される場合があります。 探しているものが表示されない場合は、左側のペインの下部にある… もっと見るを選択してください。
Azure AI Foundry にサインインします。
まだプロジェクトを開いていない場合は選びます。
左側のペインから [微調整] を選択します。
- [モデルのファインチューニング] を選択し、ファインチューニングするモデルを追加します。 この記事では、Phi-3-mini-4k-instruct を使用して説明します。
- [次へ] を選択すると、使用可能なファインチューニング オプションが表示されます。 一部の基盤モデルでは、[マネージド コンピューティング] オプションのみがサポートされます。
または、プロジェクトの左側のサイドバーから [モデルカタログ] を選択し、ファインチューニングする基礎モデルのモデル カードを見つけることができます。
- モデル カードで [ファインチューニング] を選択すると、使用可能なファインチューニング オプションが表示されます。 一部の基盤モデルでは、[マネージド コンピューティング] オプションのみがサポートされます。
個人用コンピューティング リソースを使用するには、[マネージド コンピューティング] を選択します。 この操作により、ファインチューニング設定を指定するためのウィンドウの [基本設定] ページが開きます。

ファインチューニング設定を構成する
このセクションでは、マネージド コンピューティングを使用して、モデルのファインチューニングを構成する手順について説明します。
[基本設定] ページでファインチューニングされたモデルの名前を指定し、[次へ] を選択して [コンピューティング] ページに移動します。
モデルのファインチューニングに使用する Azure Machine Learning コンピューティング クラスターを選択します。 GPU コンピューティングでファインチューニングが実行されます。 使用する予定のコンピューティング SKU に十分なコンピューティング クォータがあることを確認します。
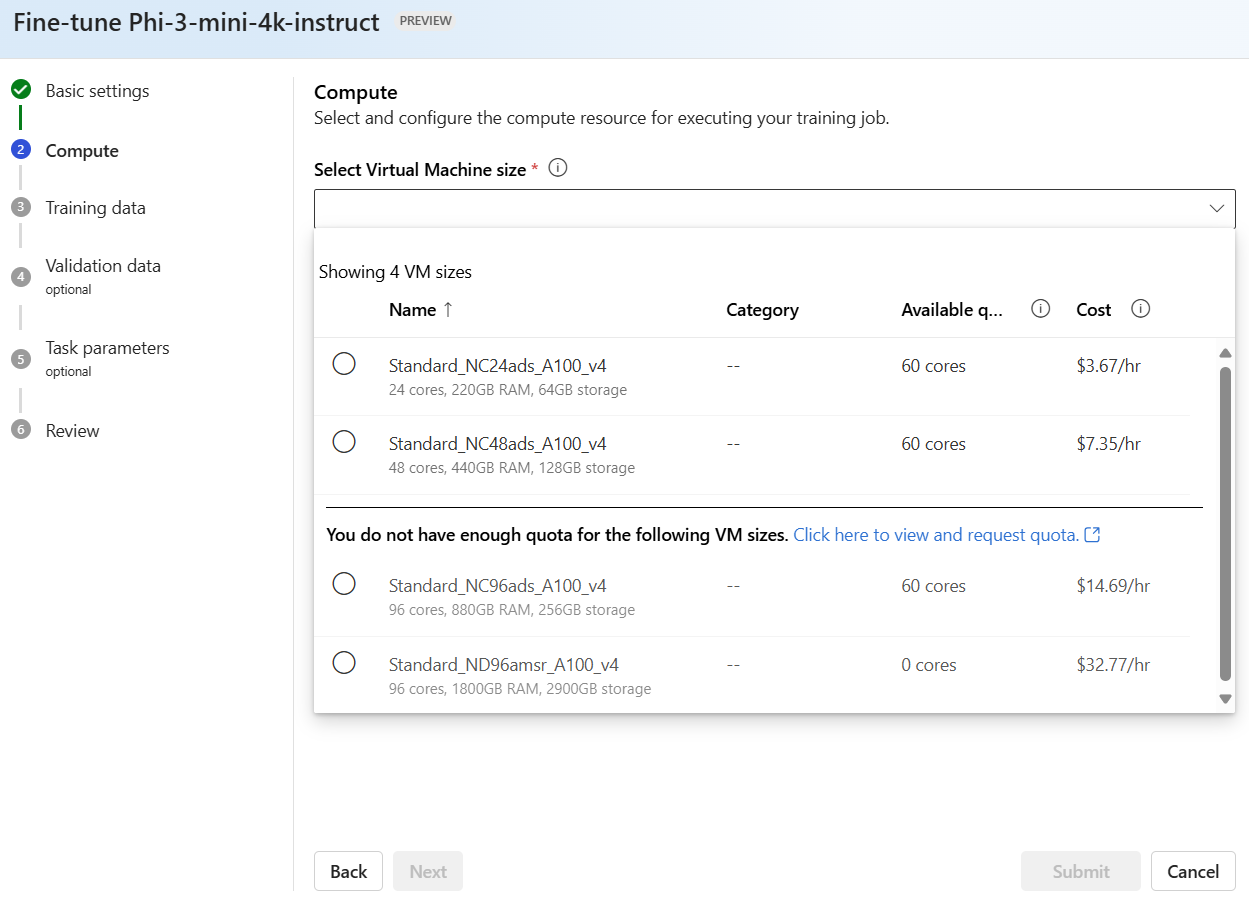
[次へ] を選択して、[トレーニング データ] ページに移動します。 このページでは、[タスクの種類] に [チャット完成] が事前に選択されています。
モデルのファインチューニングに使用するトレーニング データを提供します。 ローカル ファイル (JSONL、CSV、または TSV 形式) をアップロードするか、プロジェクトから既存の登録済みデータセットを選ぶかを選択できます。
[次へ] を選択して、[検証データ] ページに移動します。 検証のためにトレーニング データの自動分割を予約するには、[トレーニング データの自動分割] の選択を維持します。 または、ローカル ファイル (JSONL、CSV、または TSV 形式) をアップロードするか、プロジェクトから既存の登録済みデータセットを選択して、別の検証データセットを指定することもできます。
[次へ] を選択して、[タスクのパラメーター] ページに移動します。 ハイパーパラメーターのチューニングは、実際のアプリケーションで大規模言語モデル (LLM) を最適化するために不可欠です。 これにより、パフォーマンスが向上し、リソースの効率的な使用が可能になります。 既定の設定を維持するか、エポックや学習率などのパラメーターをカスタマイズするかを選択できます。
[次へ] を選択して [レビュー] ページに移動し、すべての設定が適切であることを確認します。
[送信] を選択して、ファインチューニング ジョブを送信します。 ジョブが完了すると、微調整したモデルの評価メトリックを表示できます。 その後、このモデルを、推論のためにエンドポイントにデプロイできます。
