Von Bedeutung
英語以外の翻訳は便宜上のみ提供されています。 バインドのバージョンについては、このドキュメントの EN-US バージョンを参照してください。
Azure OpenAI モデルの多くは、コンテンツやコードの生成、要約、検索などの高度な機能の改善を実証した生成型 AI モデルです。 これらの改善の多くでは、有害なコンテンツ、操作、人間のような行動、プライバシーなど、責任ある AI の課題も増えています。 これらのモデルの機能、制限事項、および適切なユース ケースの詳細については、「 透明性に関するメモ」を参照してください。
透明性に関するメモに加えて、Azure OpenAI モデルを責任を持って実装する AI システムの設計、開発、デプロイ、使用に役立つ技術的な推奨事項とリソースを作成しました。 Microsoft の推奨事項は、 Microsoft の責任ある AI Standard に基づき、独自のエンジニアリング チームが従うポリシー要件を設定します。 Standard のコンテンツの多くはパターンに従い、チームに潜在的な損害の特定、測定、軽減を依頼し、AI システムを運用する方法を計画します。 これらのプラクティスに合わせて、これらの推奨事項は 4 つの段階に分かれています。
- 識別 : 反復的なレッド チーミング、ストレス テスト、分析を通じて、AI システムから生じる可能性のある潜在的な損害を特定し、優先順位を付けます。
- 測定 : 明確なメトリックを確立し、測定テスト セットを作成し、反復的で体系的なテスト (手動と自動化の両方) を完了することによって、これらの害の頻度と重大度を測定します。
- 軽減 : 迅速なエンジニアリング や コンテンツ フィルターの使用などのツールと戦略を実装することで、害を軽減します。 軽減策を実装した後に、測定を繰り返して有効性をテストします。
- 運用 : デプロイと運用の準備計画を定義して実行します。
これらのステージは、Microsoft Responsible AI Standard との対応に加えて、 NIST AI リスク管理フレームワークの機能に密接に対応しています。
識別
AI システムで発生したり、AI システムによって引き起こされたりする可能性のある潜在的な損害を特定することは、責任ある AI ライフサイクルの最初の段階です。 以前に潜在的な損害を特定し始めるほど、害を軽減する効果が高まります。 潜在的な損害を評価するときは、特定のコンテキストで Azure OpenAI サービスを使用した結果として生じる可能性がある損害の種類を理解することが重要です。 このセクションでは、影響評価、反復的な赤いチーム テスト、ストレス テスト、分析を通じて損害を特定するために使用できる推奨事項とリソースについて説明します。 レッド チーミングとストレス テストとは、テスターのグループが集まり、あるシステムに意図的に探りを入れてその限界、リスク サーフェス、脆弱性を特定するアプローチです。
これらの手順では、特定のシナリオごとに潜在的な損害の優先順位付けされた一覧を作成することを目標としています。
- 特定のモデル、アプリケーション、デプロイシナリオに関連する害を特定します。
- システムで使用しているモデルとモデルの機能 (GPT-3 モデルと GPT-4 モデルなど) に関連する潜在的な損害を特定します。 上記のセクションで詳しく説明したように、各モデルにはそれぞれ異なる機能、制限、リスクがあるため、この点を考慮することが重要です。
- 開発しているシステムの意図された使用によって提示されるその他の損害または損害の範囲の拡大を特定します。 責任ある AI 影響評価を使用して、潜在的な損害を特定することを検討してください。
- たとえば、テキストを要約する AI システムについて考えてみましょう。 テキスト生成には、用途によってリスクが低いものがあります。 たとえば、医師のメモを要約するために医療分野でシステムを使用する場合、システムがオンライン記事を要約している場合よりも、不正確さから生じる損害のリスクが高くなります。
- 頻度や重大度などのリスク要素に基づいて、害の優先順位を付けます。 特定した損害の一覧に優先順位を付けるために、各損害のリスクレベルと各リスクが発生する可能性を評価します。 適切な場合は、組織内の領域専門家やリスク マネージャー、および関係する外部の利害関係者と連携することを検討してください。
- 最も優先度の高い損害から始まる赤いチーム テストとストレス テストを実施し、特定された損害が実際にシナリオで発生しているかどうかをより深く理解し、最初に予想していなかった新しい損害を特定します。
- この情報を、関係する利害関係者と共有します。これには組織の内部コンプライアンス プロセスを使用します。
この識別ステージの最後には、ドキュメント化された優先順位付けされた損害の一覧が必要です。 システムの追加のテストと使用によって新しい損害や新しい損害のインスタンスが発生した場合は、上記のプロセスをもう一度実行することで、この一覧を更新して改善できます。
測る
優先順位付けされた損害の一覧が特定されたら、次の段階では、各損害を体系的に測定するためのアプローチを開発し、AI システムの評価を行います。 測定には、手動と自動のアプローチがあります。 両方実行することをお勧めしますが、まずは手動測定から始めることをお勧めします。
手動測定は次の場合に役立ちます。
- 少数の優先度が高い問題の進行状況を測定する。 特定の損害を軽減する場合、自動測定に移行する前に、損害が観察されなくなるまで、小さなデータセットに対して手動で進行状況を確認し続けることが多くの場合最も生産性が高くなります。
- 自動測定が単独で使用できるほど信頼できるものになるまで、メトリックを定義して報告する。
- スポット チェックを定期的に行い、自動測定の品質を測定します。
自動測定は次の場合に役立ちます。
- より包括的な結果を提供するために、カバレッジを上げて大規模に測定を行う。
- システム、使用状況、軽減策の進化に伴う回帰を監視するための継続的な測定を行う。
以下では、潜在的な損害について AI システムを測定するための具体的な推奨事項を示します。 最初にこのプロセスを手動で完了してから、このプロセスを自動化する計画を策定することをお勧めします。
優先順位付けされた各損害を生成する可能性が高い入力を作成します 。優先順位付けされた各損害を生み出す可能性が高いターゲット入力の多くの多様な例を生成することによって、測定セットを作成します。
システム出力の生成: システム出力を生成するための入力として、測定セットの例をシステムに渡します。 出力を文書化します。
システム出力を評価して関連する利害関係者に結果を報告する
- 明確なメトリックを定義します。 システムの使用目的ごとに、有害な可能性がある各出力の頻度と重大度を測定するメトリックを確立します。 明確な定義を作成して、特定した優先順位付けされた損害の種類ごとに、システムとシナリオのコンテキストで有害または問題と見なされる出力を分類します。
- 明確なメトリック定義に対して出力を評価し、有害な出力の発生を記録して定量化します。 軽減策を評価し、回帰がないことを監視するために、定期的に測定を繰り返します。
- この情報を、関係する利害関係者と共有します。これには組織の内部コンプライアンス プロセスを使用します。
この測定ステージの最後には、潜在的な損害ごとにシステムがどのように実行されるかをベンチマークするための定義済みの測定アプローチと、文書化された結果の初期セットが必要です。 軽減策の実装とテストを続けるにつれて、メトリックと測定セットを引き続き調整し (たとえば、最初は予期していなかった新しい害のメトリックを追加するため)、結果を更新する必要があります。
緩和する
Azure OpenAI などの大規模言語モデルによって引き起こされる損害を軽減するには、実験と継続的な測定を含む反復的な多層アプローチが必要です。 このプロセスの初期段階で特定された損害に対する 4 つのレイヤーの軽減策を含む軽減計画を策定することをお勧めします。
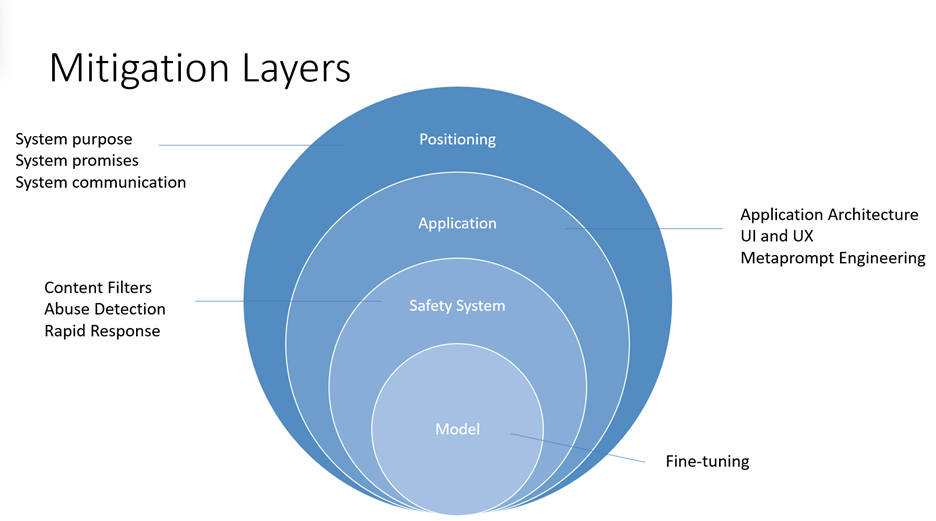
- モデル レベルでは、使用するモデルと、モデル開発者がモデルを意図した用途に合わせて調整し、潜在的に有害な用途や結果のリスクを軽減するために実行された微調整手順を理解することが重要です。
- たとえば、GPT-4 の場合、モデル開発者は、強化学習方法を責任ある AI ツールとして使用して、デザイナーの意図した目標に合わせてモデルをより適切に調整できるようになりました。
- 安全システム レベルでは、有害なコンテンツの出力をブロックするのに役立つ Azure OpenAI コンテンツ フィルターなど、実装されているプラットフォーム レベルの軽減策を理解する必要があります。
- アプリケーション レベルでは、アプリケーション開発者は metaprompt とユーザー中心の設計とユーザー エクスペリエンスの軽減策を実装できます。 メタプロンプトは、その動作をガイドするためにモデルに提供される命令です。使用は、システムが期待に従って動作するように導く上で重要な違いを生み出すことができます。 ユーザー中心の設計とユーザー エクスペリエンス (UX) の介入も、AI への誤用や過度の依存を防ぐための主要な軽減ツールです。
- 配置レベルでは、システムの機能と制限について、システムを使用または影響を受けるユーザーを教育する多くの方法があります。
以下では、さまざまなレイヤーで軽減策を実装するための具体的な推奨事項を示します。 これらの軽減策のすべてがすべてのシナリオに適しているわけではありません。逆に、一部のシナリオではこれらの軽減策が不十分な場合があります。 シナリオと特定した優先順位付けされた損害を慎重に検討し、軽減策を実装する際に、システムとシナリオに対 する有効性を測定して文書化 するプロセスを開発します。
モデル レベルの軽減策: 構築しているシステムに最適な Azure OpenAI ベース モデルを確認して特定し、その機能、制限事項、および特定した潜在的な損害のリスクを軽減するために行われた対策について自分自身を教育します。 たとえば、GPT-4 を使用している場合は、この透明性に関するメモを読むだけでなく、OpenAI の GPT-4 システム カード を確認して、モデルによって提示される安全性の課題と、デプロイ用に GPT-4 を準備するために OpenAI が採用した安全プロセスについて説明します。 さまざまなバージョンのモデルを試して実験し(レッドチーミング(攻撃側視点での評価)と測定を含む)、害の現れ方がどのように異なるかを確認する価値があります。
安全システム レベルの軽減策:Azure OpenAI コンテンツ フィルターなどのプラットフォーム レベルのソリューションの有効性を特定して評価し、特定した潜在的な損害を軽減します。
アプリケーション レベルの軽減策: metaprompt チューニングを含むプロンプト エンジニアリングは、さまざまな種類の損害に対する 効果的な軽減策となる可能性があります 。 ここに記載されている metaprompt ("システム メッセージ" または "システム プロンプト" とも呼ばれます) のガイダンスとベスト プラクティスを確認して実装 します。
ユーザーが、意図したとおりにシステムを使用するようにガイドし、AI システムへの過度の依存を防ぐために、次のユーザー中心の設計とユーザー エクスペリエンス (UX) の介入、ガイダンス、ベスト プラクティスを実装することをお勧めします。
- 介入の確認と編集: ユーザー エクスペリエンス (UX) を設計して、システムを使用するユーザーが、AI によって生成された出力を受け入れる前にレビューおよび編集することを奨励します ( HAX G9: 効率的な修正のサポートを参照)。
- ユーザーがシステムを使用し始めたときや使用中の適切なタイミングで、AI によって生成された出力に潜在的な不正確さがあることを強調し、システムがどれくらい効果的に機能できるかを明確に示します (HAX G2 を参照してください)。 最初の実行エクスペリエンス (FRE) では、AI によって生成された出力に不正確が含まれている可能性があり、情報を検証する必要があることをユーザーに通知します。 エクスペリエンス全体を通じて、システムが誤って生成する可能性がある特定の種類のコンテンツに関連して、AI によって生成された出力で潜在的な不正確さを確認するためのリマインダーを含めます。 たとえば、システムの数値の精度が低いと測定プロセスで判断された場合は、生成された出力で数値をマークしてユーザーに警告し、その数値を確認するか、外部ソースに検証を求めるように促します。
- ユーザーの責任。 AI によって生成されたコンテンツをレビューするときに、最終的なコンテンツに対する責任があることをユーザーに通知します。 たとえば、コードの提案を行うときに、開発者に提案を受け入れる前にレビューとテストを行うよう促します。
- 対話での AI の役割を開示します。 (別の人間ではなく) AI システムと対話していることをユーザーに認識させる。 必要に応じて、コンテンツが AI モデルによって部分的または完全に生成されたことをコンテンツ コンシューマーに通知します。このような通知は、法律または適用されるベスト プラクティスによって要求される可能性があり、AI によって生成された出力への不適切な依存を減らし、消費者がそのようなコンテンツを解釈して行動する方法について独自の判断を使用するのに役立ちます。
- システムの擬人化を防止します。 AIモデルは、意見、感情的な表現、またはその他の形式を含む内容を生成することがあります。これにより、それらが人間のように見える、または人間の特性と誤解される可能性があり、本来持たない機能を持っていると人々を誤解させる恐れがあります。 こうした出力のリスクを軽減するメカニズムを実装するか、出力の誤解を防ぐのに役立つ開示を組み込んでください。
- 参照と情報源を引用します。 システムで、モデルに送信された参照に基づいてコンテンツが生成される場合、情報源を明確に引用すると、AI で生成されたコンテンツの出所をユーザーが理解するのに役立ちます。
- 必要に応じて、入力と出力の長さを制限します。 入力と出力の長さを制限すると、望ましくないコンテンツの生成、意図した用途以外のシステムの誤用、その他の有害なまたは意図しない使用の可能性を低減できます。
- 構造入力および/またはシステム出力。 アプリケーション内で プロンプト エンジニアリング 手法を使用してシステムへの入力を構造化し、オープンエンドの応答を防ぎます。 出力を特定の形式またはパターンで構造化するように制限することもできます。 たとえば、システムがクエリに応じて架空のキャラクターのダイアログを生成する場合は、入力を制限して、ユーザーがあらかじめ定められた概念のセットに対してのみ問い合わせできるようにします。
- 事前に決定された応答を準備します。 モデルが攻撃的、不適切、またはその他の有害な応答を生成する可能性のある特定のクエリがあります。 有害または攻撃的なクエリや応答が検出された場合、事前に決められた応答をユーザーに返すようにシステムを設計できます。 事前に定義する応答は、慎重に作成する必要があります。 たとえば、アプリケーションは、"あなたは誰ですか" などの質問に対して、システムが擬人化された応答を返さないように、事前に作成された回答を提供することができます。 また、"使用条件は何ですか" などの質問に対して事前に定義された回答を使用して、ユーザーを適切なポリシーに誘導することもできます。
- ソーシャル メディアへの自動投稿を制限します。 ユーザーが製品やサービスを自動化する方法を制限します。 たとえば、AI によって生成されたコンテンツの外部サイト (ソーシャル メディアを含む) への自動投稿を禁止したり、生成されたコードの自動実行を禁止したりできます。
- ボット検出。 ユーザーが製品上に API を構築することを禁止するメカニズムを考案して実装します。
配置レベルの軽減策:
- 適切な透明性を提供します。 システムを使用するユーザーがシステムの使用に関して情報に基づいた意思決定を行えるように、ユーザーに適切なレベルの透明性を提供することが重要です。
- システム ドキュメントを提供します。 システムの機能と制限の説明を含む、システムに関する教材を作成して提供します。 たとえば、これは、システム経由でアクセスできる "詳細情報" ページの形式にすることができます。
- ユーザー ガイドラインとベスト プラクティスを公開します。 ユーザーと利害関係者が、プロンプトの作成、世代を受け入れる前の世代のレビューなどに関するベスト プラクティスを公開することで、システムを適切に使用できるようにします。このようなガイドラインは、システムのしくみを理解するのに役立ちます。 可能な場合、ガイドラインとベスト プラクティスを UX に直接組み込みます。
特定された潜在的な損害に対処するための軽減策を実装するときは、そのような軽減策の有効性を継続的に測定するためのプロセスを開発し、測定結果を文書化し、それらの測定結果を確認してシステムを継続的に改善することが重要です。
操作
測定と軽減のシステムを導入したら、デプロイと運用の準備計画を定義して実行することをお勧めします。 このステージでは、関係する利害関係者と共にシステムと軽減計画の適切なレビューを行い、テレメトリとフィードバックを収集するためのパイプラインを確立し、インシデント応答とロールバックの計画を作成します。
Azure OpenAI サービスを使用するシステムを適切にデプロイして運用するための、具体的なリスク軽減対策を含むいくつかの推奨事項として、次のようなものがあります。
組織内のコンプライアンス チームと協力して、このシステムにはどの種類のレビューがいつ必要になるかを理解します (たとえば法的レビュー、プライバシー レビュー、セキュリティ レビュー、アクセシビリティ レビューなど)。
以下を開発して実装します。
- 段階的デリバリー計画を策定します。 Azure OpenAI サービスを使用するシステムの起動は、"段階的デリバリー" アプローチを使用して徐々に行うことをお勧めします。 このようにすると、システムを広範にリリースする前に限定的な人数のユーザーがシステムを試用してフィードバックを提供し、問題や懸念事項を報告し、改善を提案するという機会を作ることができます。 また、予期しない障害モード、予期しないシステム動作、および予期しない懸念の報告のリスクを管理するのにも役立ちます。
- インシデント応答計画を策定する。 インシデント対応計画を策定し、インシデント 1 件の対応に必要な時間を評価します。
- ロールバック計画を作成する 予期しないインシデントが発生した場合に備えて、システムを迅速かつ効率的にロールバックできることを確認します。
- 予期しない損害に対して直ちに対処する準備をします。 問題のあるプロンプトや応答が検出されたときに、可能な限りリアルタイムに近いタイミングでブロックするのに必要な、機能とプロセスを構築します。 予期しない損害が発生した場合は、問題のあるプロンプトと対応をできるだけ早くブロックし、適切な軽減策を開発して展開し、インシデントを調査し、長期的なソリューションを実装します。
- システムを悪用している人物をブロックするメカニズムを開発します。 コンテンツ ポリシーに違反するユーザー (ヘイト スピーチを生成するなど) を特定するメカニズムを開発します。あるいは、意図しない目的や有害な目的でシステムを使用しているユーザーを特定し、さらなる悪用に対してアクションを実行します。 たとえば、あるユーザーがシステムを頻繁に使用しており、生成したコンテンツがコンテンツ安全性システムによってブロックまたは報告された場合は、それ以降はそのユーザーによるシステムの使用を禁止することを検討します。 必要に応じて、異議申し立てメカニズムを実装します。
- 効果的なユーザー フィードバック チャネルを構築します。 フィードバック チャネルを実装して、これを通して利害関係者 (および該当する場合は一般の人々) がフィードバックを提出したり、生成されたコンテンツの問題など、システムの使用中に発生したことを報告したりできるようにします。 このようなフィードバックがどのように処理され、検討され、対処されるかを文書化します。 フィードバックを評価し、ユーザーのフィードバックに基づいてシステムを改善する作業を行います。 1 つのアプローチとして、生成されたコンテンツを含むボタンを含めることができます。これにより、ユーザーはコンテンツを "不正確"、"有害"、または "不完全" と識別できます。これにより、より広く使用され、構造化され、分析用のフィードバック信号が提供される可能性があります。
- テレメトリ データ。 ユーザーの満足度やシステムを意図したとおりに使用できる能力を示すシグナルを (適用されるプライバシー法、ポリシー、コミットメントに従って) 特定して記録します。 利用統計情報を使用してギャップを特定し、システムを改善します。
このドキュメントは法的助言を提供することを意図したものではなく、またそのように解釈されるべきではありません。 事業を展開している管轄によっては、AI システムに適用されるさまざまな規制または法的要件がある場合があります。 お客様のシステムに適用される可能性のある法律や規制について不明な場合、特にその法律や規制がここで示した推奨事項に影響を与える可能性があると考えられる場合は、法務の専門家に相談してください。 ここで示している推奨事項のすべてが、どのシナリオにも適しているとは限らないことと、逆にここで示した推奨事項とリソースだけでは、シナリオによっては不十分な場合があることに注意してください。