このコンテンツの適用対象:![]() v4.0 (GA)
v4.0 (GA)
はじめに
取得拡張生成 (RAG) は、ChatGPT などの事前トレーニング済み大規模言語モデル (LLM) と外部データ取得システムを組み合わせて、元のトレーニング データ以外の新しいデータを組み込んで強化された応答を生成する設計パターンです。 情報検索システムをアプリケーションに追加すると、ドキュメントとのチャット、魅力的なコンテンツの生成、データの Azure OpenAI モデルの機能へのアクセスが可能になります。 また、LLM で応答を作成する際に使用するデータをより詳細に制御できます。
Document Intelligence Layout モデルは、高度な機械学習ベースのドキュメント分析 API です。 Layout モデルにより、高度なコンテンツ抽出機能とドキュメント構造分析機能の包括的なソリューションが提供されます。 Layout モデルを使用すると、テキストと構造の要素を簡単に抽出して、任意の分割ではなくセマンティック コンテンツに基づいて、大きなテキスト本文をより小さな意味のあるチャンクに分割できます。 抽出された情報はマークダウン形式で簡単に出力できるため、提供された構成要素に基づいてセマンティック チャンキング戦略を定義できます。
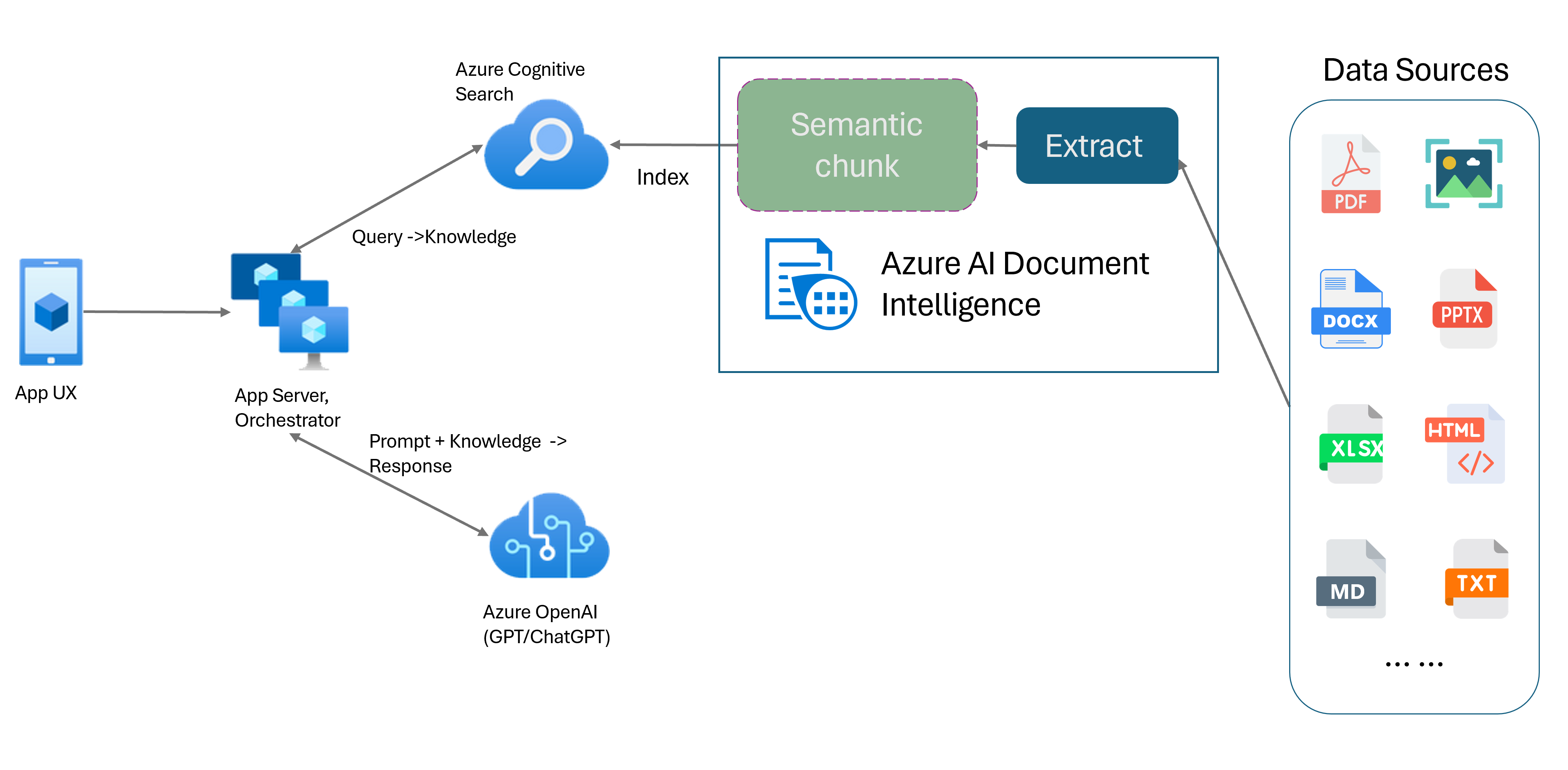
セマンティック チャンキング
長文は、自然言語処理 (NLP) アプリケーションで処理するのは困難です。 特に、文が複数の節、複雑な名詞句や動詞句、関係節、かっこで囲まれたグループで構成されている場合、非常に困難です。 人間の観察者と同様に、NLP システムも、提示されたすべての依存関係を正常に追跡する必要があります。 セマンティック チャンキングの目的は、文の表現の意味的に一貫性のあるフラグメントを見つけることです。 これらのフラグメントは独立して処理され、情報、解釈、または意味的関連性を失うことなく、セマンティック表現として再結合できます。 テキストの固有の意味は、チャンキング プロセスのガイドとして使用されます。
テキスト データのチャンキング戦略は、RAG 応答とパフォーマンスを最適化する上で重要な役割を果たします。 固定サイズとセマンティックは、2 つの異なるチャンキング方法です。
固定サイズのチャンキング。 現在 RAG で使用されているほとんどのチャンキング戦略は、チャンクと呼ばれる固定サイズのテキスト セグメントに基づいています。 固定サイズのチャンクは、ログやデータなどの強力なセマンティック構造を持たないテキストに対しては迅速かつ簡単で、効果的です。 ただし、意味の理解と正確なコンテキストを必要とするテキストにはお勧めしません。 ウィンドウが固定サイズであるという性質上、単語、文、または段落が分断されるため、理解が妨げられ、情報や理解の流れが中断される可能性があります。
セマンティック チャンキング。 この方法では、意味の理解に基づいてテキストがチャンクに分割されます。 分割境界では、文の主語に焦点が当てられ、アルゴリズムが複雑な大量の計算リソースが使用されます。 ただし、各チャンク内で意味の一貫性が維持されるという明確な利点があります。 これは、テキストの要約、感情分析、ドキュメントの分類の各タスクに役立ちます。
Document Intelligence Layout モデルを使用したセマンティック チャンキング
Markdown は、構造化され、フォーマットされたマークアップ言語であり、RAG (取得拡張生成) でセマンティック チャンキングを有効にするための一般的な入力です。 Layout モデルの Markdown コンテンツを使用して、段落境界に基づいてドキュメントを分割し、テーブル用の特定のチャンクを作成し、チャンキング戦略を微調整して生成される応答の品質を向上することができます。
Layout モデルを使用する利点
処理の簡略化。 API を 1 回呼び出すだけで、デジタル PDF、スキャンされた PDF、画像、Office ファイル (docx、xlsx、pptx)、HTML などのさまざまな種類のドキュメントを解析できます。
スケーラビリティと AI 品質。 Layout モデルは、光学式文字認識 (OCR)、テーブル抽出、ドキュメント構造分析でスケーラビリティに優れています。 309 の印刷言語と 12 の手書き言語がサポートされ、AI 機能主導で高品質の結果が保証されます。
大規模言語モデル (LLM) の互換性。 Layout モデルのマークダウン形式の出力は LLM に適しており、ワークフローへのシームレスな統合を容易にします。 ドキュメント内のテーブルを Markdown 形式に変換でき、LLM をより深く理解するためにドキュメントを解析する多大な労力を省くことができます。
Document Intelligence Studio で処理されたテキスト画像と Layout モデルを使ったマークダウンの出力

Layout モデルを使用して Document Intelligence Studio で処理されたテーブル画像

概要
Document Intelligence レイアウト モデル 2024-11-30 (GA) では、次の開発オプションがサポートされています。
開始する準備はできましたか?
ドキュメント インテリジェンス スタジオ
開始するには、Document Intelligence Studio クイックスタートに従います。 次に、提供されたサンプル コードを使用して、Document Intelligence の機能を独自のアプリケーションに統合できます。
Layout モデルから開始します。 スタジオで RAG を使用するには、次の分析オプションを選択する必要があります。
**Required**- 分析の実行範囲 → 現在のドキュメント。
- ページ範囲 → すべてのページ。
- 出力形式のスタイル → Markdown。
**Optional**- さらに、関連するオプションの検出パラメータを選択することもできます。
[保存] を選択します。
![Document Intelligence Studio の RAG 必須オプションを含む [オプションの分析] ダイアログ ウィンドウのスクリーンショット。](../media/rag/rag-analyze-options.png?view=doc-intel-4.0.0)
[分析の実行] ボタンを選択して出力を表示します。
![Document Intelligence Studio の [分析の実行] ボタンのスクリーンショット。](../media/rag/run-analysis.png?view=doc-intel-4.0.0)
SDK または REST API
Document Intelligence クイックスタートに従って、好みのプログラミング言語 SDK または REST API を使用できます。 Layout モデルを使用して、ドキュメントからコンテンツと構造を抽出します。
マークダウン出力形式でドキュメントを分析するためのコード サンプルとヒントについては、GitHub リポジトリで確認することもできます。
セマンティック チャンキングを使用してドキュメントとのチャットを構築する
独自のデータに基づく Azure OpenAI を使用すると、ドキュメントでサポートされているチャットを実行できます。 独自のデータに基づく Azure OpenAI では、Document Intelligence Layout モデルを適用して、テーブルと段落に基づいて長いテキストをチャンクに分割し、ドキュメント データを抽出および解析します。 GitHub リポジトリ内にある Azure OpenAI サンプル スクリプトを使用して、チャンキング戦略をカスタマイズすることもできます。
Azure AI Document Intelligence は、ドキュメント ローダーの 1 つとして、LangChain と統合されました。 これを使用して、簡単にデータを読み込んで Markdown 形式に出力できます。 詳細については、LangChain のドキュメント ローダーとして Azure AI Document Intelligence を、リトリーバーとして Azure Search を使用した RAG パターンの簡単なデモを示すサンプル コードを参照してください。
"データとチャット" ソリューション アクセラレータのコード サンプルでは、エンドツーエンドのベースライン RAG パターンのサンプルを示します。 これは、リトリーバーとして Azure AI 検索を使用し、ドキュメントの読み込みとセマンティック チャンキングに Azure AI Document Intelligence を使用します。
ユース ケース
ドキュメント内で特定のセクションを探す場合、セマンティック チャンキングを使用して、セクション ヘッダーに基づいてドキュメントを小さなチャンクに分割すると、探しているセクションをすばやくかつ簡単に見つけることができます。
# pip install azure-ai-documentintelligence==1.0.0b1
# pip install langchain langchain-community azure-ai-documentintelligence
from azure.ai.documentintelligence import DocumentIntelligenceClient
endpoint = "https://<my-custom-subdomain>.cognitiveservices.azure.com/"
key = "<api_key>"
from langchain_community.document_loaders import AzureAIDocumentIntelligenceLoader
from langchain.text_splitter import MarkdownHeaderTextSplitter
# Initiate Azure AI Document Intelligence to load the document. You can either specify file_path or url_path to load the document.
loader = AzureAIDocumentIntelligenceLoader(file_path="<path to your file>", api_key = key, api_endpoint = endpoint, api_model="prebuilt-layout")
docs = loader.load()
# Split the document into chunks base on markdown headers.
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
text_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
docs_string = docs[0].page_content
splits = text_splitter.split_text(docs_string)
splits
次のステップ
Document Intelligence Studio を使用して独自のフォームとドキュメントを処理する方法を学習します。
Document Intelligence クイックスタートを完了し、選択した開発言語でドキュメント処理アプリの作成を開始します。