このコンテンツの適用対象:![]() v4.0 (GA) | 以前のバージョン:
v4.0 (GA) | 以前のバージョン: ![]() v3.1 (GA)
v3.1 (GA) ![]() v3.0 (GA)
v3.0 (GA)
カスタム分類モデルは、入力ファイル内の各ページを分類して、その中の 1 つ以上のドキュメントを識別できます。 分類子モデルでは、入力ファイル内の複数のドキュメントまたは 1 つのドキュメントの複数のインスタンスを識別することもできます。 Document Intelligence のカスタム モデルの使用を開始するには、ドキュメント クラスごとにトレーニング ドキュメントが 5 つだけ必要となります。 カスタム分類モデルのトレーニングを開始するには、クラスごとに少なくとも 5 つのドキュメントと、2 つのクラスのドキュメントが必要です。
カスタム分類モデルの入力要件
トレーニング データ セットが Document Intelligence の入力の要件に従っていることを確認します。
サポートされているファイル形式:
| モデル | 画像: JPEG/JPG、PNG、BMP、TIFF、HEIF |
Microsoft Office: Word ( DOCX)、Excel (XLSX)、PowerPoint (PPTX)、HTML |
|
|---|---|---|---|
| 読み込み | ✔ | ✔ | ✔ |
| Layout | ✔ | ✔ | ✔ |
| 一般的なドキュメント | ✔ | ✔ | |
| 事前構築済み | ✔ | ✔ | |
| カスタム抽出 | ✔ | ✔ | |
| カスタム分類 | ✔ | ✔ | ✔ |
最適な結果を得るには、ドキュメントごとに 1 つの鮮明な写真または高品質のスキャンを提供してください。
PDF および TIFF の場合、最大 2,000 ページを処理できます (Free レベルのサブスクリプションでは、最初の 2 ページのみが処理されます)。
ドキュメントを分析するためのファイル サイズは、有料 (S0) レベルでは 500 MB、無料 (F0) レベルでは
4MB です。画像のディメンションは、50 ピクセル x 50 ピクセルから 10,000 ピクセル x 10,000 ピクセルの間である必要があります。
PDF がパスワードでロックされている場合は、送信前にロックを解除する必要があります。
抽出するテキストの最小の高さは、1024 x 768 ピクセルのイメージの場合は 12 ピクセルです。 このディメンションは、150 DPI (1 インチあたりのドット数) で約
8ポイントのテキストに相当します。カスタム モデル トレーニングにおけるトレーニング データの最大ページ数は、カスタム テンプレート モデルの場合は 500、カスタム ニューラル モデルの場合は 50,000 です。
カスタム抽出モデル トレーニングにおけるトレーニング データの合計サイズは、テンプレート モデルの場合は 50 MB、ニューラル モデルの場合は
1GB です。カスタム分類モデル トレーニングの場合、トレーニング データの合計サイズは
1GB で、最大 10,000 ページです。 2024-11-30 (GA) の場合、トレーニング データの合計サイズは2GB で、最大 10,000 ページです。
トレーニング データのヒント
次のヒントを使って、トレーニングのためにデータ セットをさらに最適化してください。
可能であれば、画像ベースのドキュメントではなく、テキストベースの PDF ドキュメントを使用します。 スキャンした PDF は画像として処理されます。
フォームの画像の品質が低い場合は、より大きなデータ セット (たとえば 10 から 15 の画像) を使用します。
トレーニング データをアップロードする
トレーニングに使用する一連のフォームまたはドキュメントをまとめたら、それを Azure BLOB Storage コンテナーにアップロードする必要があります。 コンテナーを含む Azure Storage アカウントを作成する方法がわからない場合は、Azure portal の Azure Storage に関するクイックスタートに従ってください。 Free 価格レベル (F0) を使用してサービスを試用し、後から運用環境用の有料レベルにアップグレードすることができます。 データセットがフォルダーとして編成されている場合は、Studio がフォルダー名をラベルに使用してラベル付けプロセスを簡素化できるため、その構造を保持します。
Document Intelligence Studio で分類プロジェクトを作成する
Document Intelligence Studio を使用すると、データセットの完成とモデルのトレーニングに必要なすべての API 呼び出しを利用し、調整することができます。
まず、Document Intelligence Studio に移動します。 Studio を初めて使用するときは、サブスクリプション、リソース グループ、リソースを初期化する必要があります。 次に、カスタム プロジェクトの前提条件に従って、トレーニング データセットにアクセスする Studio を構成します。
スタジオで [カスタム分類モデル] タイルを選択し、ページのカスタム モデル セクションで [プロジェクトの作成] ボタンを選択します。
Create Projectダイアログで、プロジェクトの名前と必要に応じて説明を入力し、[続行] を選択します。次に、続行する前に、Document Intelligence リソースを選択するか、作成を選択します。
次に、カスタム モデルのトレーニング データセットをアップロードするために使用したストレージ アカウントを選択します。 トレーニング ドキュメントがコンテナーのルートにある場合は、フォルダー パスが空である必要があります。 ドキュメントがサブフォルダーにある場合は、[フォルダー パス] フィールドにコンテナー ルートからの相対パスを入力します。 ストレージ アカウントが構成された後、[続行] を選択します。
重要
フォルダー名がドキュメントのラベルまたはクラスであるフォルダーごとにトレーニング データセットを整理するか、Studio でラベルを割り当てることができるドキュメントのフラット リストを作成できます。
カスタム分類子をトレーニングするには、データセット内の各ドキュメントのレイアウト モデルからの出力が必要です。 モデル トレーニング プロセスの前に、すべてのドキュメントでレイアウトを実行します。
最後に、プロジェクトの設定を確認し、[プロジェクトの作成] を選択して新しいプロジェクトを作成します。 これで、ラベル付けウィンドウに表示され、データセット内のファイルが一覧表示されます。
データにラベルを付ける
プロジェクトでは、各ドキュメントに適切なクラス ラベルを付けるだけで済みます。
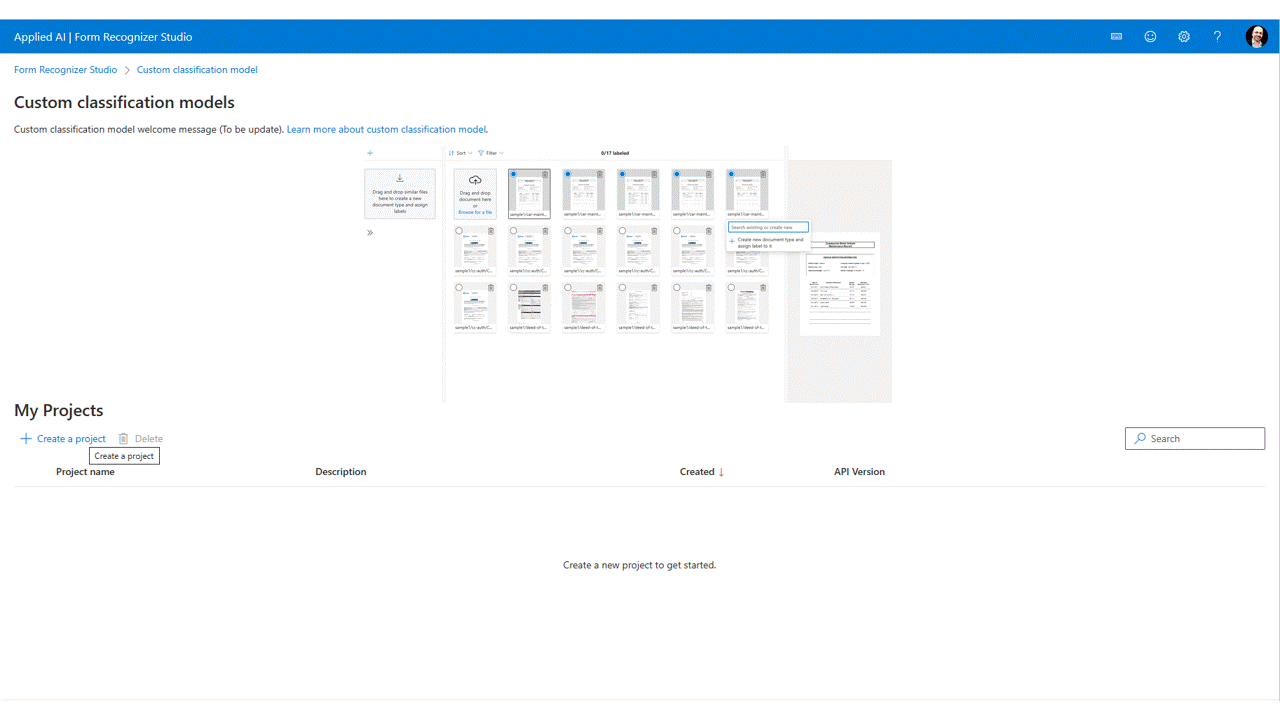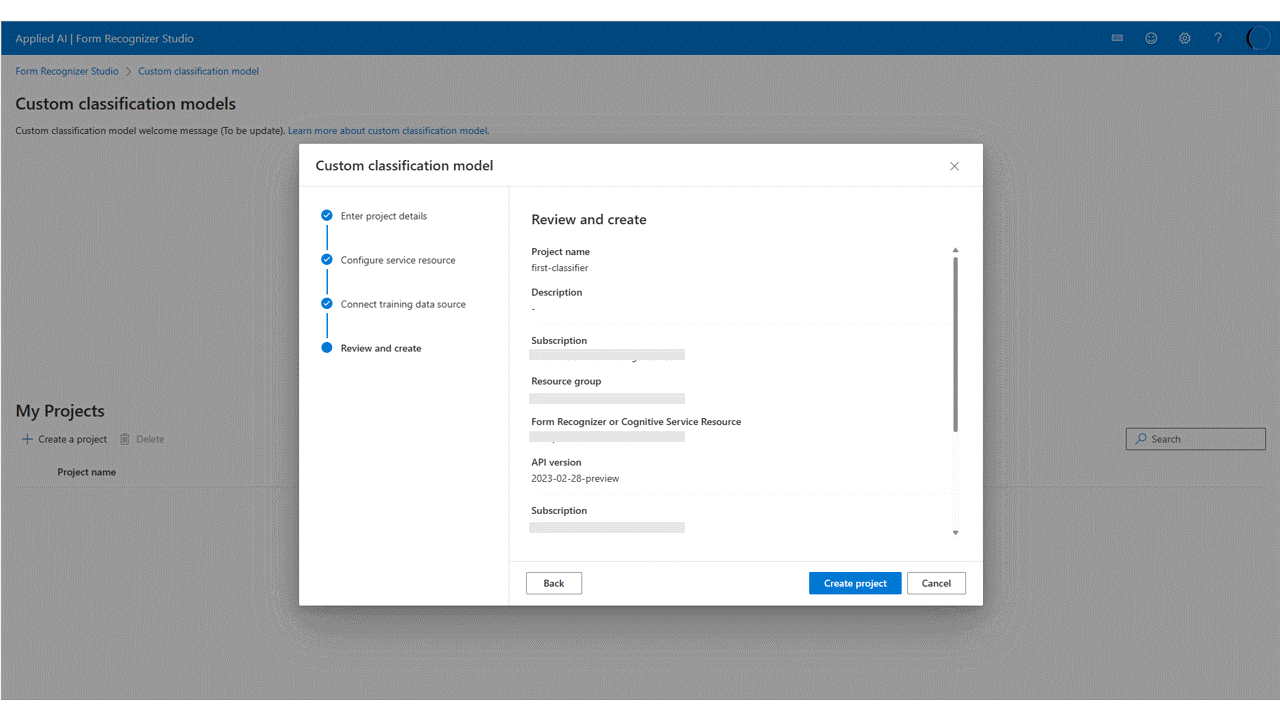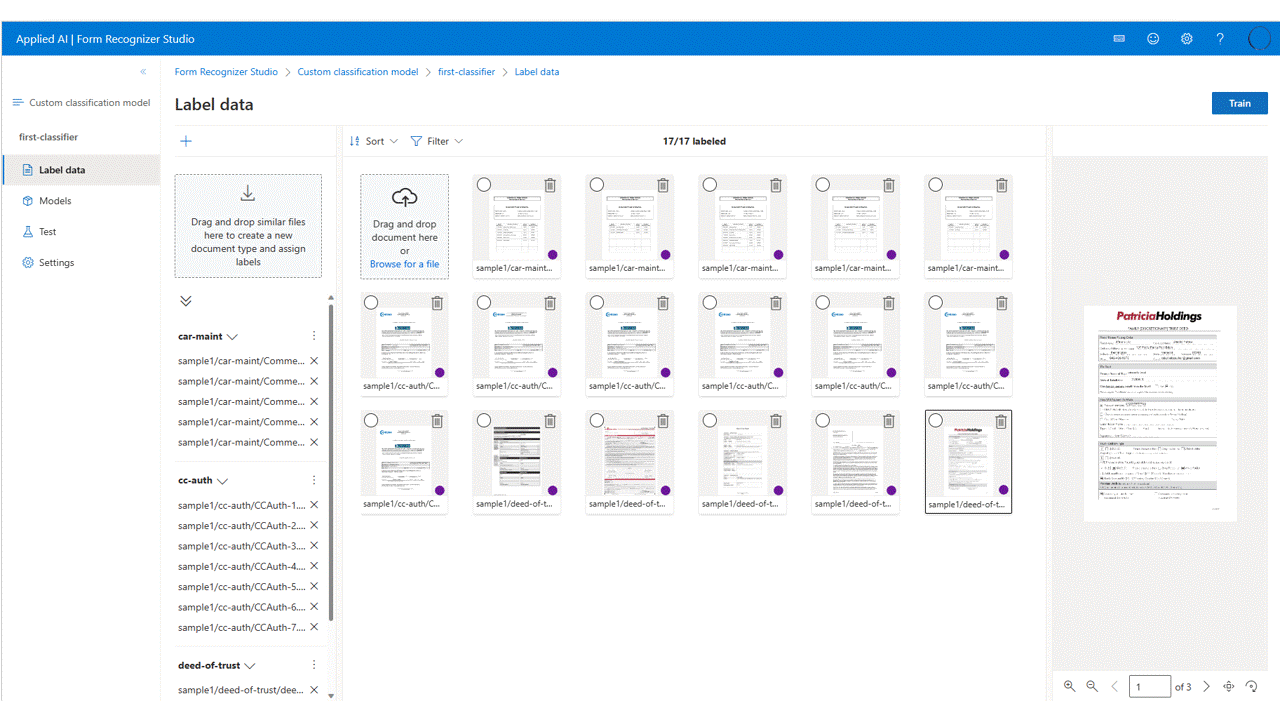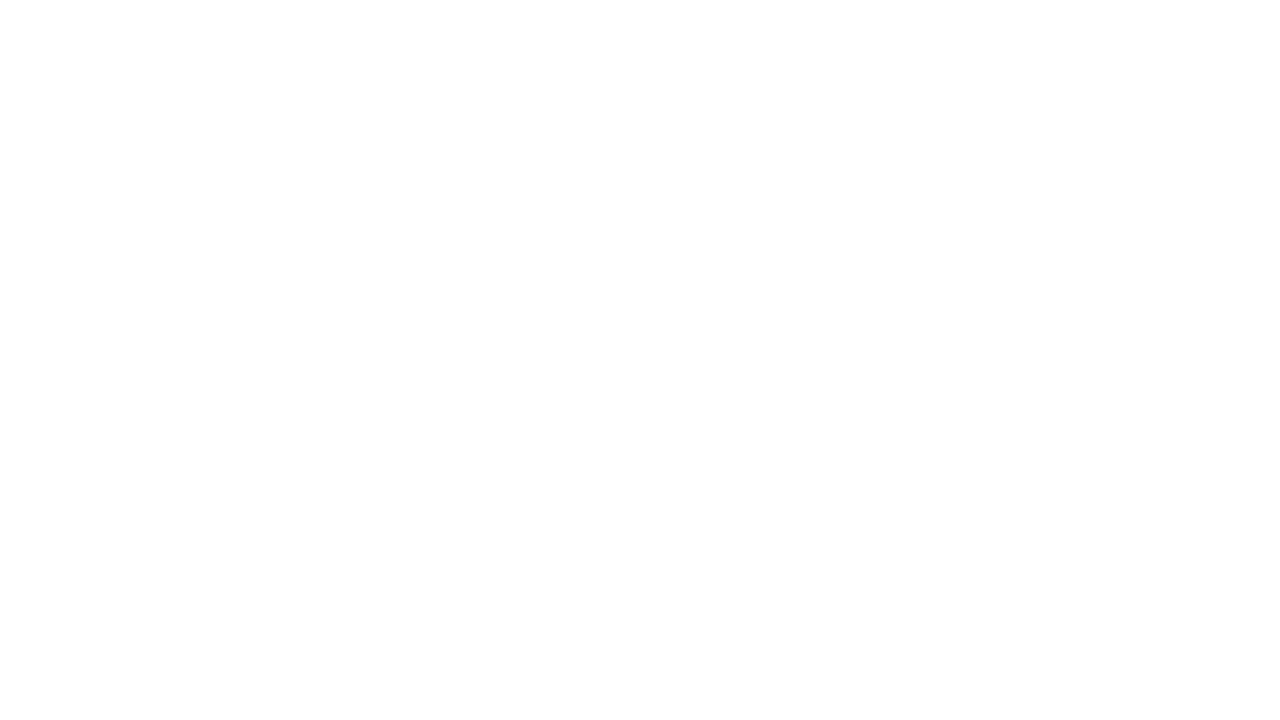
ストレージにアップロードしたファイルがファイル リストに表示され、ラベルを付ける準備が整いました。 データセットにラベルを付けるには、いくつかのオプションがあります。
ドキュメントがフォルダーに整理されている場合、Studio では、フォルダー名をラベルとして使用するように求められます。 この手順により、ラベル付けが 1 つの選択に簡略化されます。
ドキュメントにラベルを割り当てるには、
add label selection markを選択してラベルを割り当てます。ドキュメントの選択を制御して複数選択し、ラベルを割り当てる
これで、データセット内のすべてのドキュメントにラベルが付けられました。 ストレージ アカウントを確認すると、トレーニング データセット内の各ドキュメントに対応する .ocr.json ファイルと、ラベル付けされた各クラスの新しい class-name.jsonl ファイルがあります。 このトレーニング データセットは、モデルをトレーニングするために送信されます。
モデルをトレーニングする
データセットにラベルが付いたので、モデルをトレーニングする準備が整いました。 右上隅にある [ツール] を選択します。
[モデルのトレーニング] ダイアログで、一意の分類子 ID と、必要に応じて説明を指定します。 分類子 ID は文字列データ型を受け取ります。
[トレーニング] を選択してトレーニング プロセスを開始します。
分類子モデルは数分でトレーニングされます。
[モデル] メニューに移動して、トレーニング操作の状態を表示します。
モデルのテスト
モデルのトレーニングが完了したら、モデルの一覧ページでモデルを選択して、モデルをテストできます。
モデルを選択し、[テスト] ボタンを選択します。
ファイルを参照するか、ドキュメント セレクターにファイルをドロップして、新しいファイルを追加します。
ファイルを選択した後、[分析] ボタンを選択してモデルをテストします。
モデルの結果は、識別されたドキュメントの一覧、識別された各ドキュメントの信頼度スコア、および識別された各ドキュメントのページ範囲と共に表示されます。
識別された各ドキュメントの結果を評価して、モデルを検証します。
SDK または API を使用したカスタム分類子のトレーニング
Studio は、カスタム分類子をトレーニングするために API 呼び出しをオーケストレーションします。 分類子トレーニング データセットには、トレーニング モデルの API のバージョンと一致するレイアウト API からの出力が必要です。 古い API バージョンのレイアウト結果を使用すると、モデルの精度が低下する可能性があります。
データセットにレイアウト結果が含まれていない場合、Studio によってトレーニング データセットのレイアウト結果が生成されます。 API または SDK を使用して分類子をトレーニングする場合は、個々のドキュメントを含むフォルダーにレイアウト結果を追加する必要があります。 このレイアウト結果は、レイアウトを直接呼び出すときの API 応答の形式にする必要があります。 SDK オブジェクト モデルは異なります。 layout results が API の結果であり、SDK response ではないことを確認します。
トラブルシューティング
分類モデルには、各トレーニング ドキュメントのレイアウト モデルの結果が必要です。 レイアウト結果を指定しない場合、Studio は分類子をトレーニングする前に各ドキュメントのレイアウト モデルを実行しようとします。 このプロセスはスロットルされ、429 応答になる可能性があります。
Studio では、分類モデルを使用してトレーニングする前に、各ドキュメントでレイアウト モデルを実行し、元のドキュメントと同じ場所にアップロードします。 レイアウト結果が追加されたら、ドキュメントを使用して分類子モデルをトレーニングできます。