カスタム NER モデルの評価と詳細を表示する
モデルのトレーニングが完了したら、モデルのパフォーマンスを表示し、テスト セットのドキュメントに対して抽出されたエンティティを確認できます。
注意
[トレーニング データからテスト セットを自動的に分割する] オプションを使用すると、テスト セットがデータからランダムに選択されるため、新しいモデルをトレーニングするたびにモデル評価の結果が異なる可能性があります。 モデルをトレーニングするたびに同じテスト セットで評価が計算されるようにするには、トレーニング ジョブを開始するときに [トレーニング データとテスト データの手動分割を使用する] オプションを使用し、データにラベルを付けるときにテスト ドキュメントを定義してください。
前提条件
モデルの評価を表示する前に、次のものが必要です。
- 構成済みの Azure Blob Storage アカウントで正常に作成されたプロジェクト
- ストレージ アカウントにアップロードされたテキスト データ。
- ラベルの付いたデータ
- 正常にトレーニングされたモデル
詳細については、「プロジェクト開発ライフサイクル」を参照してください。
モデルの詳細
Language Studio でプロジェクトのページに移動します。
画面の左側にあるメニューから [モデルのパフォーマンス] を選びます。
このページでは、正常にトレーニングされたモデル、各モデルの F1 スコア、およびモデルの有効期限のみを表示できます。 モデル名を選択すると、そのパフォーマンスに関する詳細を確認できます。
Note
テスト セットでラベル付けも予測もされていないエンティティは、結果の一部として表示されません。
このタブでは、F1 スコア、精度、リコール、トレーニング ジョブの日付と時刻、トレーニング時間の合計、このトレーニング ジョブに含まれるトレーニングおよびテスト ドキュメントの数など、モデルの詳細を表示できます。
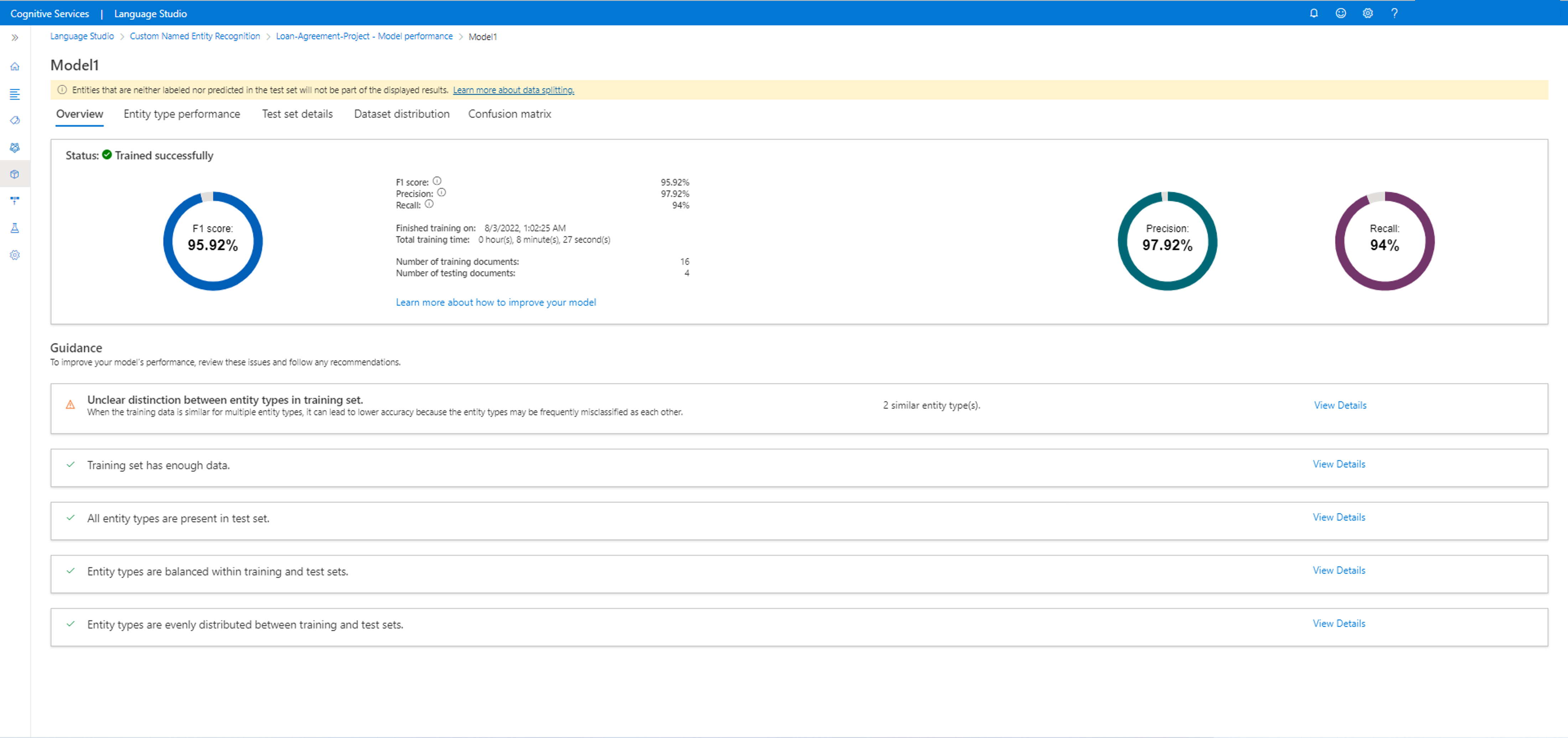
また、モデルを改善する方法に関するガイダンスも表示されます。 [詳細の表示] をクリックすると、サイド パネルが開き、モデルを改善する方法に関するガイダンスが表示されます。 この例では、BorrowerAddress エンティティと BorrowerName エンティティが $none エンティティと混同されています。 混同されたエンティティをクリックすると、[データのラベル付け] ページに移動し、より多くのデータに正しいエンティティのラベルを付けられます。
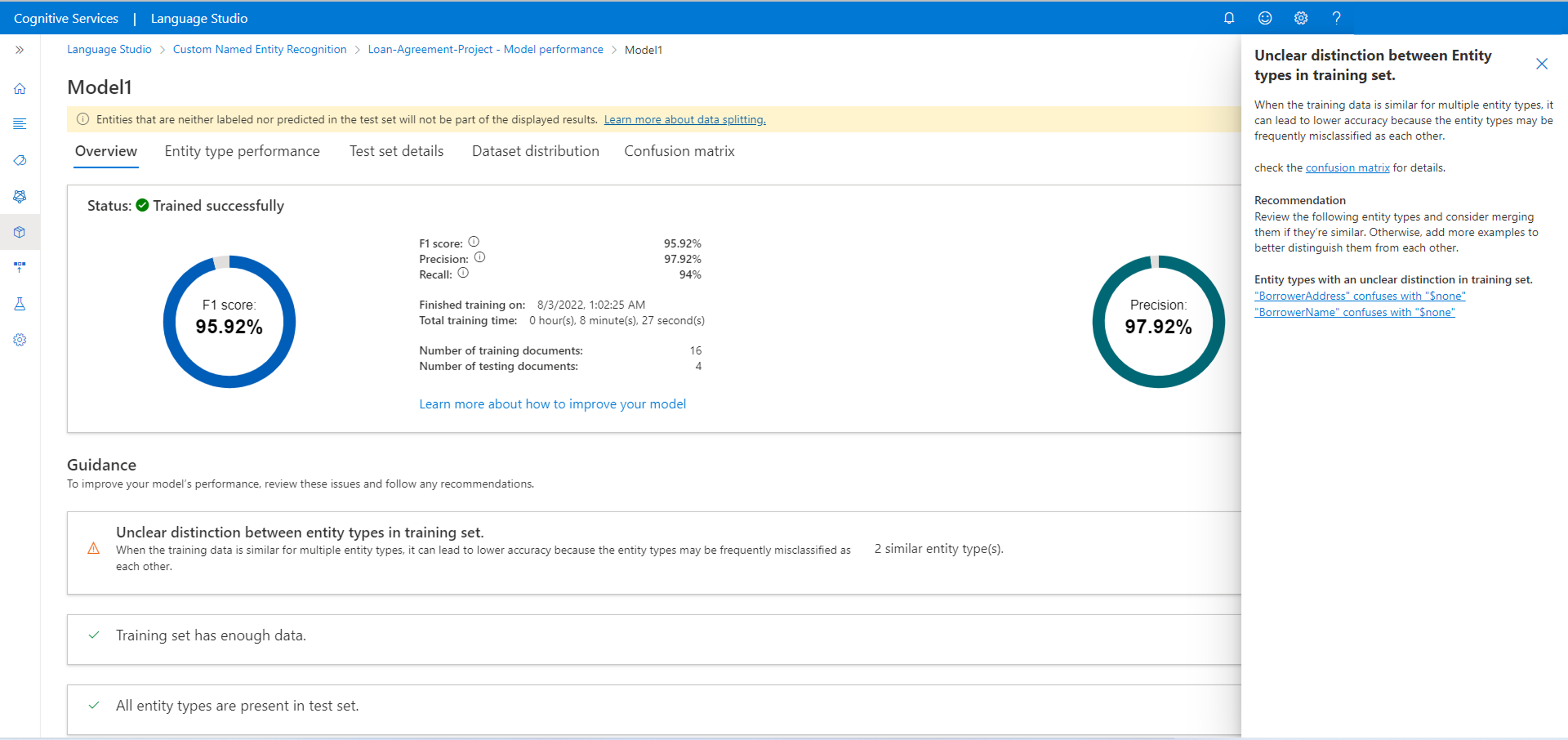
モデルのパフォーマンスの概念におけるモデル ガイダンスと混同行列の詳細について説明します。







モデル データの読み込みまたはエクスポート
モデル データを読み込むには:
モデル評価ページで任意のモデルを選択します。
[モデル データの読み込み] ボタンを選択します。
表示されるウィンドウで、キャプチャする必要がある未保存の変更がないことを確認し、[データの読み込み] を選択します。
モデル データのプロジェクトへの読み込みが完了するまで待ちます。 完了すると、[Schema design] (スキーマ デザイン) ページにリダイレクトされます。
モデル データをエクスポートするには:
モデル評価ページで任意のモデルを選択します。
[モデル データのエクスポート] ボタンを選択します。 モデルの JSON スナップショットがローカルにダウンロードされるまで待ちます。
モデルを削除する
Language Studio 内からモデルを削除するには:
左側のメニューから [モデルのパフォーマンス] を選びます。
削除するモデル名を選び、上部のメニューから [削除] を選択します。
表示されたウィンドウで [OK] を選択してモデルを削除します。
次のステップ
- モデルをデプロイする
- 評価で使用されるメトリックについて学習してください。