クイック スタート: カスタム感情分析 (プレビュー)
この記事を使用して、テキストのセンチメントを検出するためのカスタム モデルをトレーニングできるカスタム センチメント分析プロジェクトの作成を開始します。 モデルとは、特定のタスクを実行するためにトレーニングされる人工知能ソフトウェアです。 このシステムでは、モデルによってテキストが分類され、タグ付けされたデータから学習することでモデルがトレーニングされます。
前提条件
- Azure サブスクリプション - 無料アカウントを作成します。
新しい Azure 言語リソースと Azure ストレージ アカウントを作成する
カスタム センチメント分析を使えるようになるためには、まず Azure 言語リソースを作成する必要があります。これにより、プロジェクトを作成してモデルのトレーニングを始めるために必要な資格情報が提供されます。 また、モデルの構築に使用するデータセットをアップロードできる Azure ストレージ アカウントも必要です。
重要
すぐに始めるには、この記事で示す手順を使用して新しい Azure 言語リソースを作成することをお勧めします。 この記事の手順を使用すると、言語リソースとストレージ アカウントを同時に作成することができ、後で行うより簡単です。
Azure portal から新しいリソースを作成します
Azure portal に移動し、新しい Azure AI Language リソースを作成します。
表示されるウィンドウで、カスタム機能からこのサービスを選択します。 画面の下部にある [続けてリソースの作成を行う] を選択します。
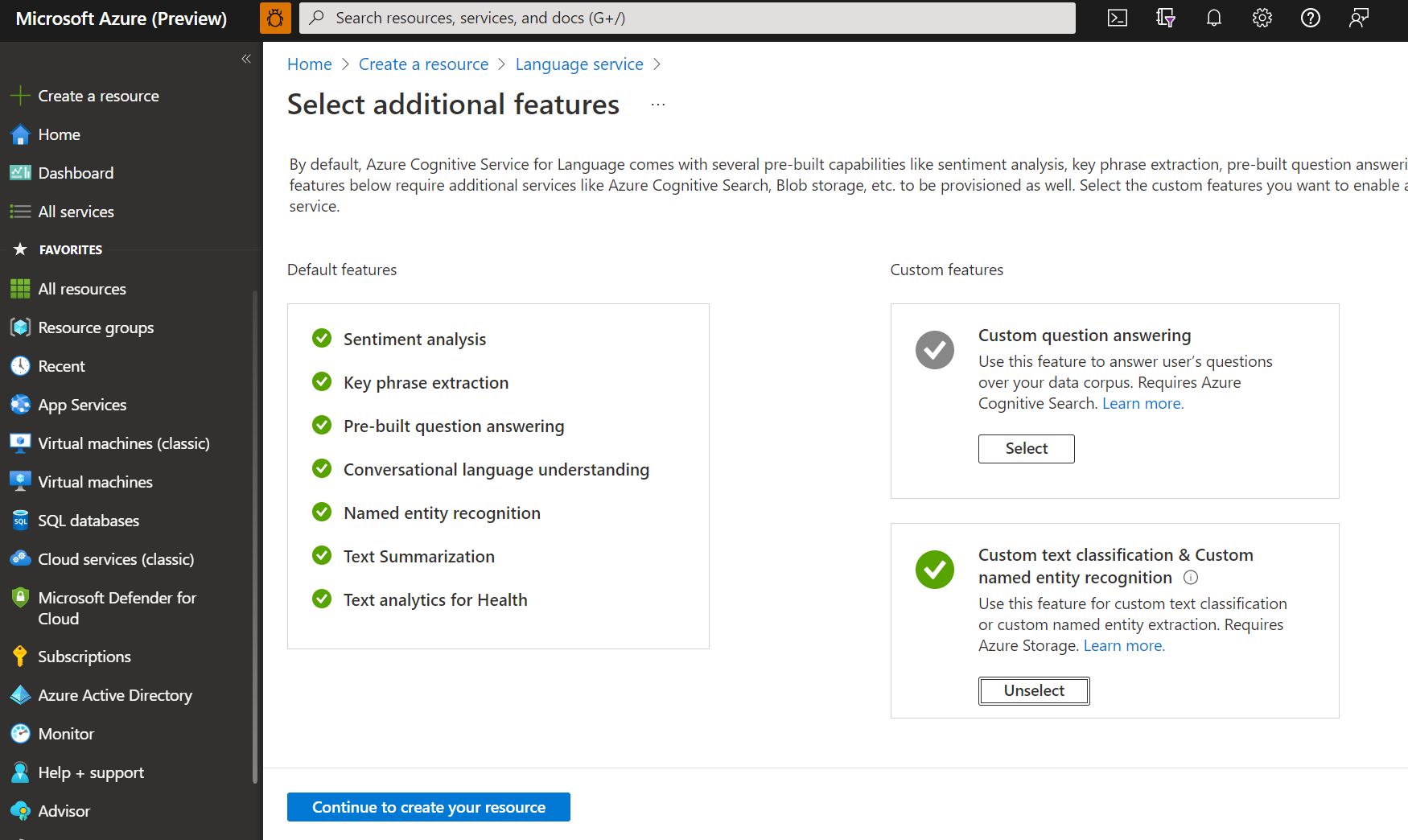
次の詳細を使用して言語リソースを作成します。
名前 説明 サブスクリプション Azure サブスクリプション。 リソース グループ リソースが格納されるリソース グループ。 既存のものを使用するか、新しく作成することができます。 リージョン 言語リソースのリージョン。 たとえば "米国西部 2" にします。 名前 リソースの名前。 Pricing tier 言語リソースの価格レベル。 Free (F0) レベルを利用してサービスを試用できます。 注意
"ログイン アカウントが選択したストレージ アカウントのリソース グループの所有者ではない" ことを通知するメッセージが表示された場合は、言語リソースを作成する前に、アカウントでそのリソース グループに所有者ロールを割り当てる必要があります。 Azure サブスクリプションの所有者に問い合わせてください。
このサービスのセクションで、既存のストレージ アカウントを選択するか、新しいストレージ アカウントを選択します。 これらの値は使用を開始するためのものであり、必ずしもご自分の運用環境で使用するストレージ アカウントの値でありません。 プロジェクトのビルド中の待機時間を回避するには、言語リソースと同じリージョンのストレージ アカウントに接続します。
ストレージ アカウントの値 推奨値 ストレージ アカウント名 任意の名前 ストレージ アカウントの種類 標準 LRS [責任ある AI の通知] がオンになっていることを確認します。 ページの下部にある [確認と作成] を選択して、[作成] を選択します。

サンプル データを BLOB コンテナーにアップロードする
Azure storage アカウントを作成し、それを言語リソースに接続したら、サンプル データセットのドキュメントをコンテナーのルート ディレクトリにアップロードする必要があります。 これらのドキュメントは、後にモデルのトレーニングに使用されます。
最初に、カスタム センチメント分析プロジェクトのサンプル データセットをダウンロードします。 .zip ファイルを開き、ドキュメントが格納されているフォルダーを展開します。 用意されているサンプル データセットにはドキュメントが複数含まれており、それぞれが顧客レビューの簡単な例です。
ストレージ アカウントにアップロードするファイルを見つける
Azure portal で、作成したストレージ アカウントに移動して選択します。
ストレージ アカウントで、左側のメニューの [データ ストレージ] の下にある [コンテナー] を選択します。 表示された画面で、[+ コンテナー] を選択します。 コンテナーに example-data という名前を付け、既定のパブリック アクセス レベルをそのまま使用します。
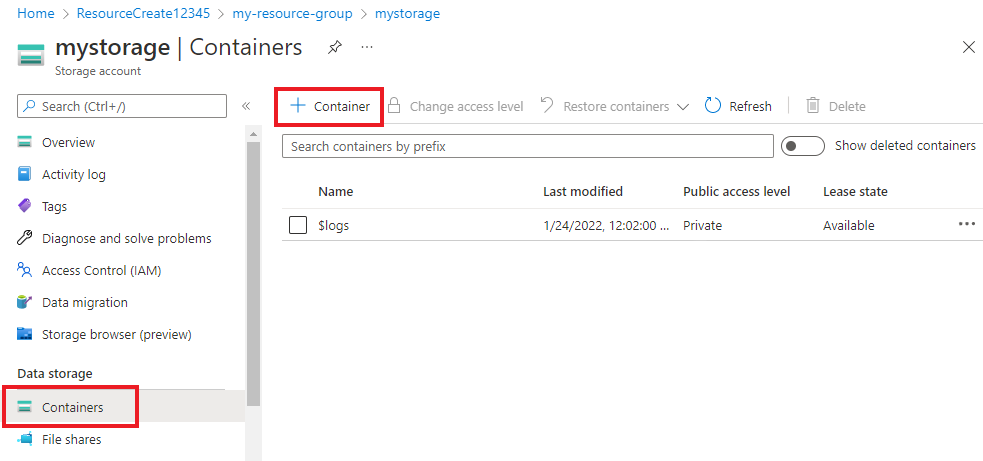
コンテナーが作成されたら、それを選択します。 次に、[アップロード] ボタンを選択して、先ほどダウンロードした
.txtおよび.jsonファイルを選択します。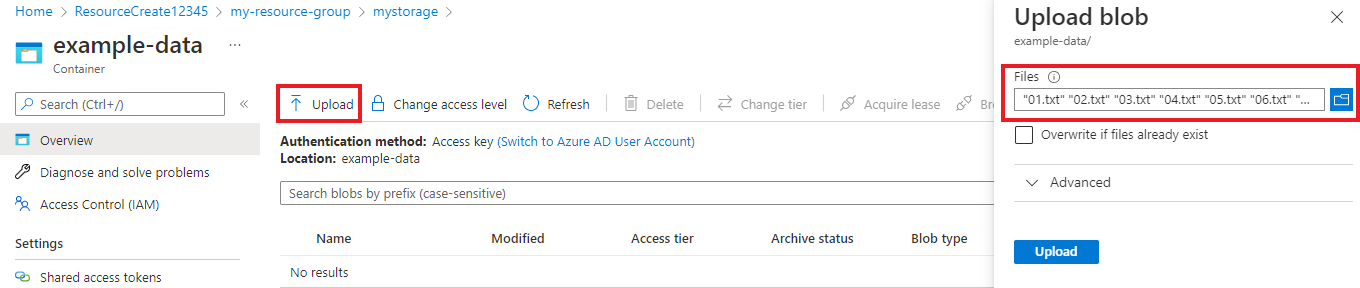


カスタム センチメント分析プロジェクトを作成する
リソースとストレージ コンテナーを構成したら、新しいカスタム センチメント分析プロジェクトを作成します。 プロジェクトは、データに基づいてカスタム ML モデルを構築するための作業領域です。 ご自分のプロジェクトにアクセスできるのは、本人と、使用されている言語リソースへのアクセス権を持つ方のみです。
Language Studio にサインインします。 サブスクリプションと言語リソースを選ぶためのウィンドウが表示されます。 上の手順で作成した言語リソースを選択します。
Language Studio で使用したい機能を選択します。
プロジェクト ページの上部メニューから、 [Create new project](新しいプロジェクトの作成) を選択します。 プロジェクトを作成すると、データのラベル付け、モデルのトレーニング、評価、改善、デプロイを実行できます。

名前、説明、プロジェクト内のファイルの言語など、プロジェクト情報を入力します。 サンプル データセットを使用する場合は、[英語] を選択します。 プロジェクトの名前は後で変更できません。 [次へ] を選択します
ヒント
データセットは、すべて同じ言語である必要はありません。 サポートされる言語がそれぞれ異なる複数のドキュメントを得ることができます。 データセットに異なる言語のドキュメントが含まれる場合や、実行時に異なる言語のテキストが必要になると考えられる場合は、プロジェクトの基本情報を入力するときに、[多言語データセットを有効にする] オプションを選択します。 このオプションは、後で [プロジェクトの設定] ページから有効にすることができます。
[新しいプロジェクトの作成] を選択すると、ストレージ アカウントを接続するためのウィンドウが表示されます。 既にストレージ アカウントを接続している場合は、そのストレージ アカウントが表示されます。 まだ接続していない場合は、表示されるドロップダウンからストレージ アカウントを選択し、[ストレージ アカウントの接続] を選択します。これにより、ストレージ アカウントに必要なロールが設定されます。 ストレージ アカウントの所有者として割り当てられていない場合、この手順でエラーが返される可能性があります。
Note
- この手順は、使用する新しいリソースごとに 1 回だけ行う必要があります。
- この処理は元に戻すことができません。ストレージ アカウントを言語リソースに接続すると、後で切断することはできません。
- 言語リソースは 1 つのストレージ アカウントにのみ接続できます。
データセットをアップロードしたコンテナーを選択します。
既にデータのラベル付けを完了している場合は、それがサポートされている形式に従っていることを確認し、[はい、ファイルは既にラベル付けされており、JSON ラベル ファイルを書式設定しています] を選択し、ドロップダウン メニューからラベル ファイルを選択します。 [次へ] を選択します。 クイックスタートのデータセットを使用している場合、JSON ラベル ファイルの書式設定を確認する必要はありません。
入力したデータを確認し、 [Create Project](プロジェクトの作成) を選びます。

モデルをトレーニングする
通常、プロジェクトを作成したら、プロジェクトに接続されているコンテナーにあるドキュメントのラベル付けを開始します。 このクイックスタートでは、サンプルのラベル付けされたデータセットをインポートし、サンプルの JSON ラベル ファイルを使用してプロジェクトを初期化しました。
Language Studio 内からモデルのトレーニングを開始するには:
左側のメニューから [トレーニング ジョブ] を選択します。
上部のメニューから [Start a training job] (トレーニング ジョブの開始) を選択します。
[新しいモデルのトレーニング] を選択し、テキスト ボックスにモデル名を入力します。 また、[既存のモデルを上書きする] オプションを選択し、ドロップダウン メニューから上書きするモデルを選択することにより、既存のモデルを上書きすることもできます。 トレーニング済みモデルを上書きすると、元に戻すことはできません。ただし、新しいモデルをデプロイするまで、デプロイされているモデルには影響しません。
既定では、システムは指定された割合で、ラベル付きデータをトレーニング セットとテスト セットに分割します。 テスト セットにドキュメントがある場合は、トレーニング データとテスト データを手動で分割できます。
[トレーニング] ボタンを選択します。
一覧からトレーニング ジョブ ID を選択すると、サイド ペインが表示され、そのジョブの [トレーニングの進行状況]、[ジョブの状態]、その他の詳細を確認できます。
注意
- 正常に完了したトレーニング ジョブでのみ、モデルが生成されます。
- トレーニングは、ラベル付けされたデータのサイズに応じて、数分から数時間かかる場合があります。
- 一度に実行できるトレーニング ジョブは 1 つだけです。 実行中のジョブが完了するまで、同じプロジェクト内で他のトレーニング ジョブを開始することはできません。

モデルをデプロイする
通常はモデルをトレーニングした後、その評価の詳細を確認し、必要に応じて改善を行います。 このクイックスタートでは、モデルをデプロイして Language Studio で試せるようにするところまで行いますが、予測 API を呼び出すこともできます。
Language Studio 内からモデルのデプロイを開始するには、次の手順を行います。
左側のメニューから [Deploying a model](モデルのデプロイ) を選びます。
[デプロイの追加] を選択して、新しいデプロイ ジョブを開始します。
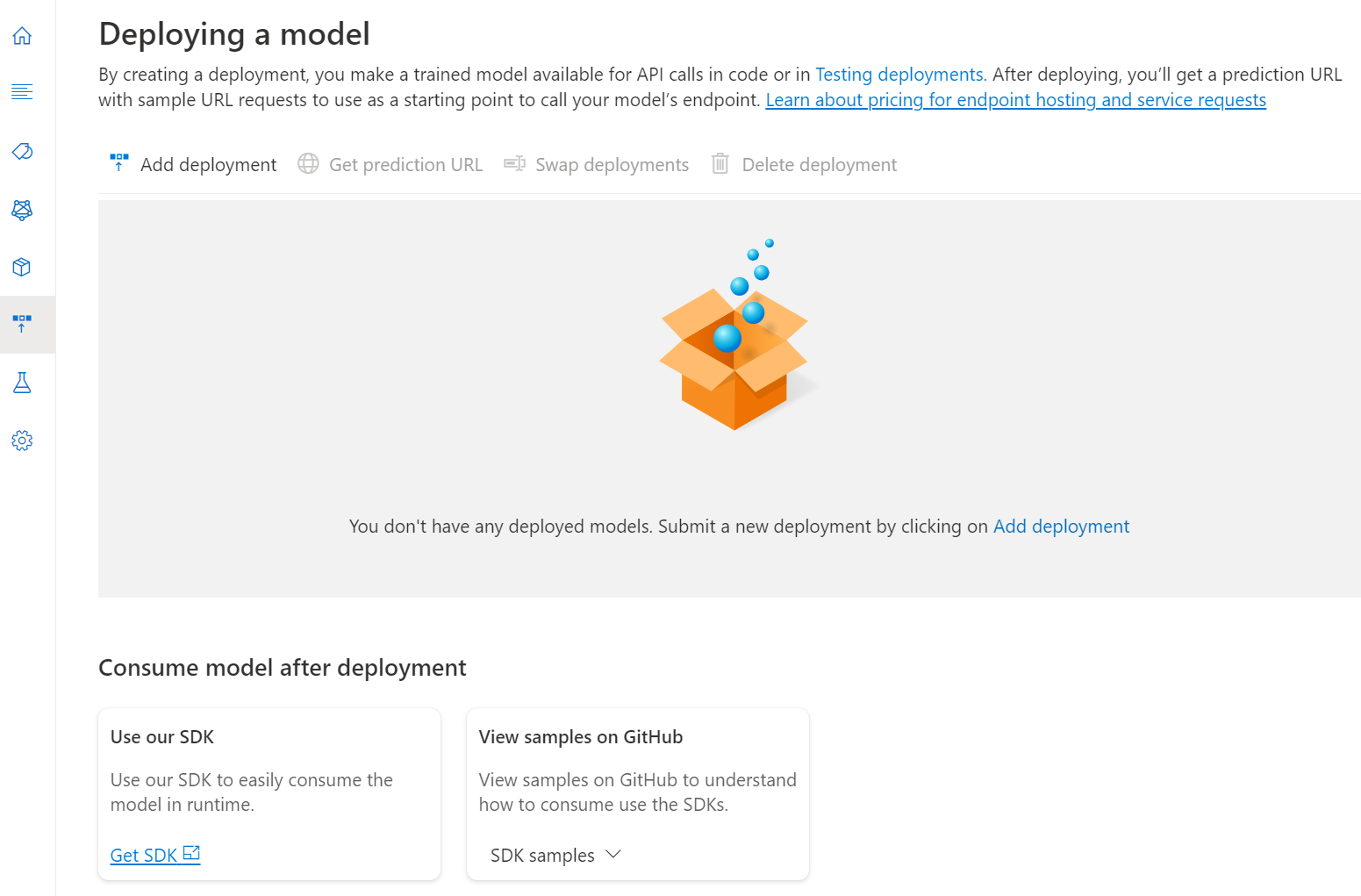
[デプロイの新規作成] を選択して新しいデプロイを作成し、下のドロップダウンからトレーニング済みのモデルを割り当てます。 既存のデプロイを上書きすることもできます。そのためにはこのオプションを選択して、下のドロップダウンから割り当てるトレーニング済みモデルを選択します。
注意
既存のデプロイを上書きしても、予測 API の呼び出しを変更する必要はありませんが、その結果は、新しく割り当てたモデルに基づくものになります。
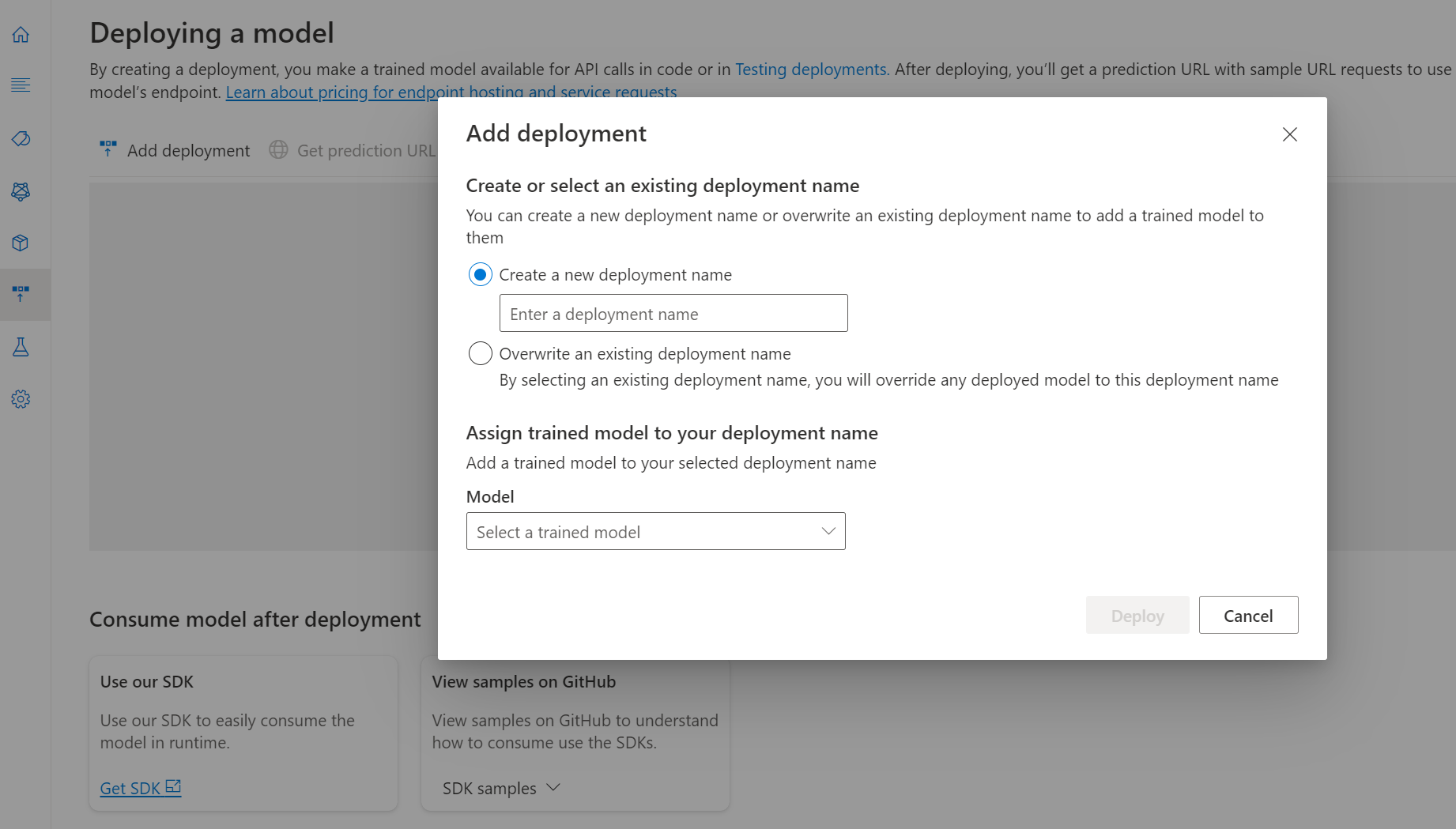
[デプロイ] を選択して、デプロイ ジョブを開始します。
デプロイが成功すると、その横に有効期限が表示されます。 デプロイの有効期限とは、デプロイされたモデルを予測に使用できなくなるときであり、通常は、トレーニング構成の有効期限が切れる 12 か月後に発生します。


モデルのテスト
モデルがデプロイされたら、モデルの使用を開始して 予測 API を使ってテキストを分類できます。 このクイックスタートでは、Language Studio を使用して、カスタム センチメント分析タスクを送信し、結果を視覚化します。 先ほどダウンロードしたサンプル データセットには、この手順で使用できるテスト ドキュメントがいくつかあります。
Language Studio 内からデプロイされたモデルをテストするには、次の手順を行います。
左側のメニューから [デプロイのテスト] を選びます。
テストするデプロイを選択します。 テストできるのは、デプロイに割り当てられているモデルのみです。
多言語プロジェクトの場合は、[言語] ドロップダウンから、テストするテキストの言語を選択します。
ドロップダウンからクエリ/テストするデプロイを選択します。
要求に送信するテキストを入力するか、使用する
.txtファイルをアップロードできます。上部のメニューから [テストの実行] を選択します。
[Result](結果) タブでは、テキストから抽出されたエンティティとその型を確認できます。 [JSON] タブで JSON 応答を表示することもできます。
プロジェクトをクリーンアップする
プロジェクトが不要な場合は、Language Studio を使ってプロジェクトを削除できます。 上部で使用している機能を選択し、削除したいプロジェクトを選択します。 上部のメニューから [削除] を選んで、プロジェクトを削除します。
前提条件
- Azure サブスクリプション - 無料アカウントを作成します。
新しい Azure 言語リソースと Azure ストレージ アカウントを作成する
カスタム センチメント分析を使えるようになるためには、まず Azure 言語リソースを作成する必要があります。これにより、プロジェクトを作成してモデルのトレーニングを開始するために必要な資格情報が提供されます。 また、モデルの構築時に使用するデータセットをアップロードできるように、Azure ストレージ アカウントも必要です。
重要
すぐに始めるには、この記事に記載されている手順を使用して新しい Azure 言語リソースを作成することをお勧めします。言語リソースの作成と、ストレージ アカウントの作成、接続、またはその両方を同時に行うことができ、後で行うより簡単だからです。
Azure portal から新しいリソースを作成します
Azure portal に移動し、新しい Azure AI Language リソースを作成します。
表示されるウィンドウで、カスタム機能からこのサービスを選択します。 画面の下部にある [続けてリソースの作成を行う] を選択します。
次の詳細を使用して言語リソースを作成します。
名前 説明 サブスクリプション Azure サブスクリプション。 リソース グループ リソースが格納されるリソース グループ。 既存のものを使用するか、新しく作成することができます。 リージョン 言語リソースのリージョン。 たとえば "米国西部 2" にします。 名前 リソースの名前。 Pricing tier 言語リソースの価格レベル。 Free (F0) レベルを利用してサービスを試用できます。 注意
"ログイン アカウントが選択したストレージ アカウントのリソース グループの所有者ではない" ことを通知するメッセージが表示された場合は、言語リソースを作成する前に、アカウントでそのリソース グループに所有者ロールを割り当てる必要があります。 Azure サブスクリプションの所有者に問い合わせてください。
このサービスのセクションで、既存のストレージ アカウントを選択するか、新しいストレージ アカウントを選択します。 これらの値は使用を開始するためのものであり、必ずしもご自分の運用環境で使用するストレージ アカウントの値でありません。 プロジェクトのビルド中の待機時間を回避するには、言語リソースと同じリージョンのストレージ アカウントに接続します。
ストレージ アカウントの値 推奨値 ストレージ アカウント名 任意の名前 ストレージ アカウントの種類 標準 LRS [責任ある AI の通知] がオンになっていることを確認します。 ページの下部にある [確認と作成] を選択して、[作成] を選択します。
サンプル データを BLOB コンテナーにアップロードする
Azure storage アカウントを作成し、それを言語リソースに接続したら、サンプル データセットのドキュメントをコンテナーのルート ディレクトリにアップロードする必要があります。 これらのドキュメントは、後にモデルのトレーニングに使用されます。
最初に、カスタム センチメント分析プロジェクトのサンプル データセットをダウンロードします。 .zip ファイルを開き、ドキュメントが格納されているフォルダーを展開します。 用意されているサンプル データセットにはドキュメントが複数含まれており、それぞれが顧客レビューの簡単な例です。
ストレージ アカウントにアップロードするファイルを見つける
Azure portal で、作成したストレージ アカウントに移動して選択します。
ストレージ アカウントで、左側のメニューの [データ ストレージ] の下にある [コンテナー] を選択します。 表示された画面で、[+ コンテナー] を選択します。 コンテナーに example-data という名前を付け、既定のパブリック アクセス レベルをそのまま使用します。
コンテナーが作成されたら、それを選択します。 次に、[アップロード] ボタンを選択して、先ほどダウンロードした
.txtおよび.jsonファイルを選択します。
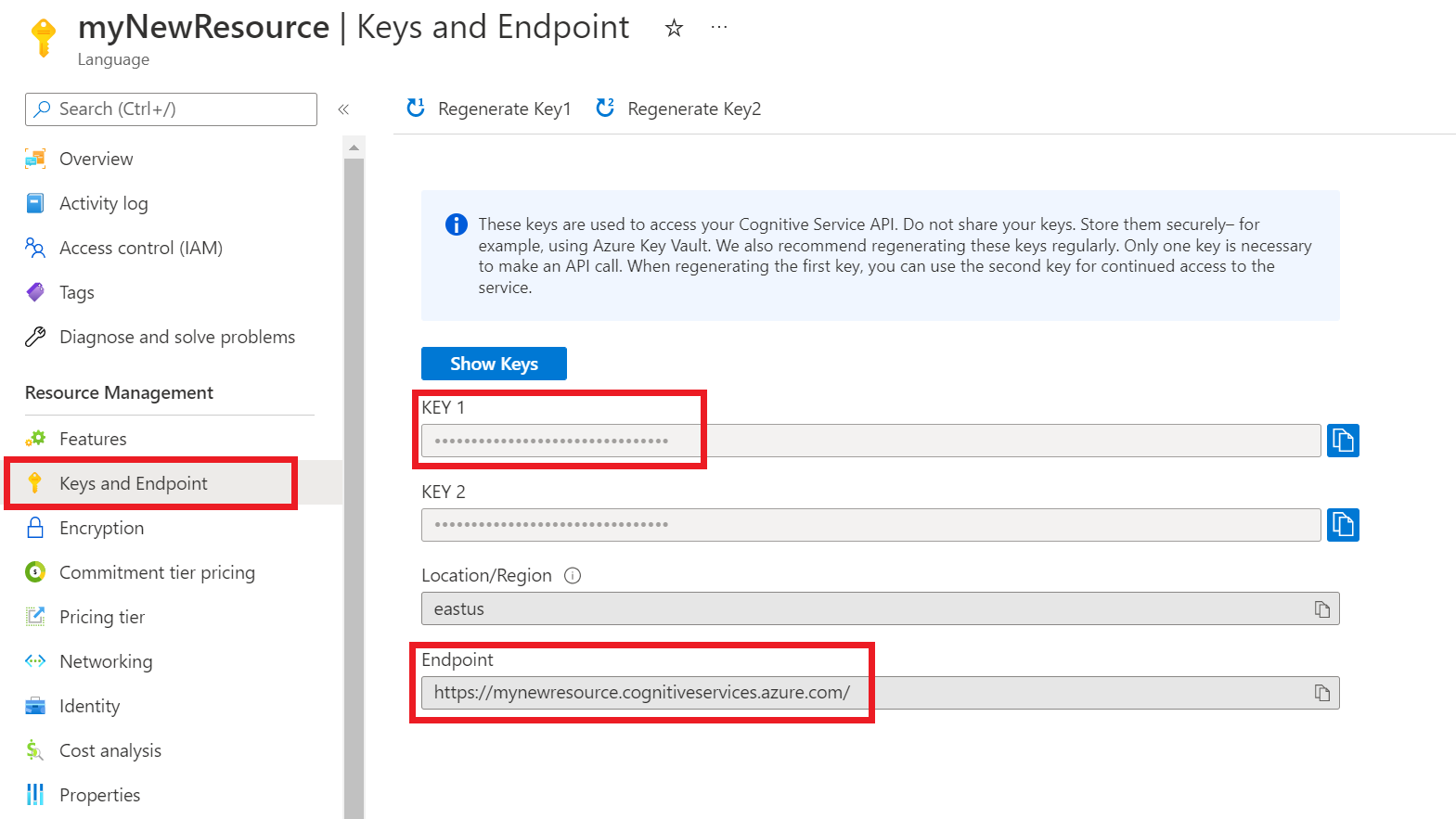
キーとエンドポイントを取得する
次に、アプリケーションを API に接続するには、リソースのキーとエンドポイントが必要です。 このクイックスタートで後に示すコードに、自分のキーとエンドポイントを貼り付けます。
言語リソースが正常にデプロイされたら、[次の手順] の [リソースに移動] ボタンをクリックします。
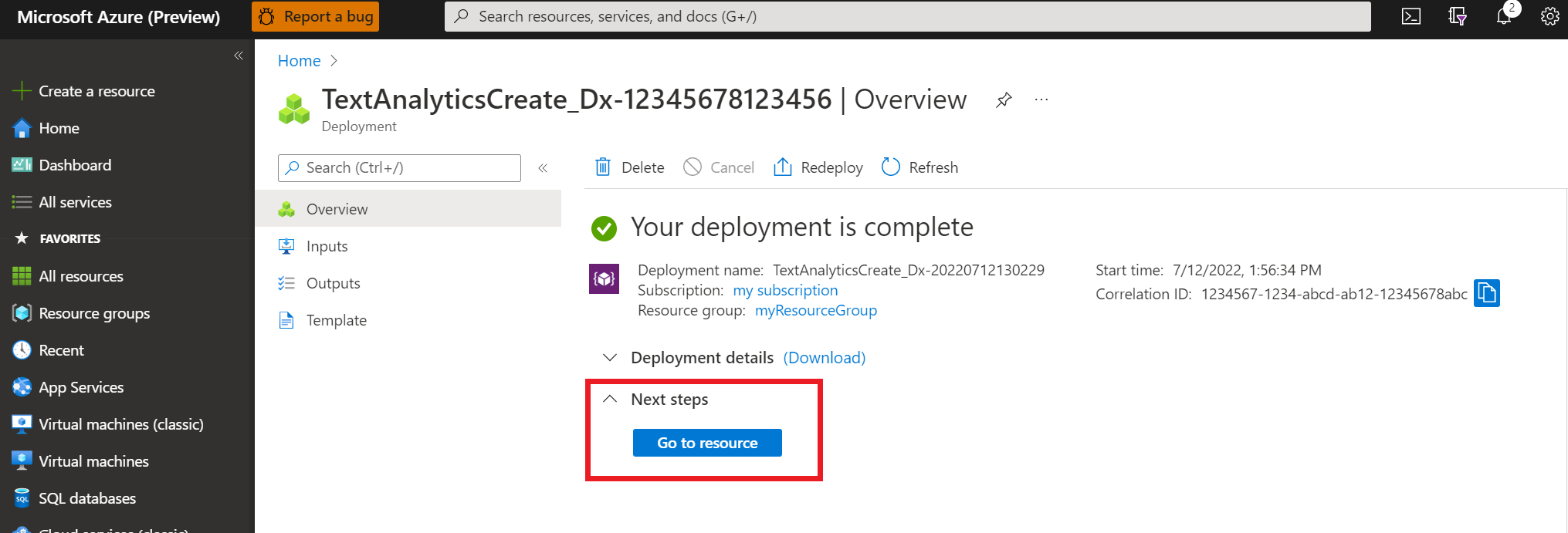
リソースのスクリーンで、左側のナビゲーション メニューの [キーとエンドポイント] を選択します。 以下の手順では、キーの 1 つとエンドポイントを使用します。


カスタム センチメント分析プロジェクトを作成する
リソースとストレージ コンテナーを構成したら、新しいカスタム センチメント分析プロジェクトを作成します。 プロジェクトは、データに基づいてカスタム ML モデルを構築するための作業領域です。 ご自分のプロジェクトにアクセスできるのは、本人と、使用されている言語リソースへのアクセス権を持つ方のみです。
プロジェクト ジョブのインポートをトリガーする
ラベル ファイルをインポートするには、次の URL、ヘッダー、JSON 本文を使って POST 要求を送信します。
同じ名前のプロジェクトが既に存在する場合は、そのプロジェクトのデータを置き換えます。
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/:import?api-version={API-VERSION}
| プレースホルダー | 値 | 例 |
|---|---|---|
{ENDPOINT} |
API 要求を認証するためのエンドポイント。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
プロジェクトの名前。 この値は、大文字と小文字が区別されます。 | myProject |
{API-VERSION} |
呼び出している API のバージョン。 ここで参照される値は、リリース済みの最新バージョン用です。 その他の利用可能な API バージョンの詳細を確認する | 2023-04-15-preview |
ヘッダー
要求を認証するには、次のヘッダーを使います。
| Key | 値 |
|---|---|
Ocp-Apim-Subscription-Key |
リソースへのキー。 API 要求の認証に使われます。 |
Body
要求では次の JSON を使います。 次のプレースホルダーの値を実際の値に置き換えてください。
{
"projectFileVersion": "2023-04-15-preview",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectKind": "CustomTextSentiment",
"storageInputContainerName": "text-sentiment",
"projectName": "TestSentiment",
"multilingual": false,
"description": "This is a Custom sentiment analysis project.",
"language": "en-us"
},
"assets": {
"projectKind": "CustomTextSentiment",
"documents": [
{
"location": "documents/document_1.txt",
"language": "en-us",
"sentimentSpans": [
{
"category": "negative",
"offset": 0,
"length": 28
}
]
},
{
"location": "documents/document_2.txt",
"language": "en-us",
"sentimentSpans": [
{
"category": "negative",
"offset": 0,
"length": 24
}
]
},
{
"location": "documents/document_3.txt",
"language": "en-us",
"sentimentSpans": [
{
"category": "neutral",
"offset": 0,
"length": 18
}
]
}
]
}
}
| Key | プレースホルダー | 値 | 例 |
|---|---|---|---|
| api-version | {API-VERSION} |
呼び出している API のバージョン。 ここで使用するバージョンは、URL 内と同じ API バージョンである必要があります。 その他の利用可能な API バージョンの詳細を確認する | 2023-04-15-preview |
| projectName | {PROJECT-NAME} |
プロジェクトの名前。 この値は、大文字と小文字が区別されます。 | myProject |
| projectKind | CustomTextSentiment |
プロジェクトの種類。 | CustomTextSentiment |
| language | {LANGUAGE-CODE} |
プロジェクトで使用されるドキュメントの言語コードを指定する文字列。 プロジェクトが多言語プロジェクトの場合は、ほとんどのドキュメントの言語コードを選択します。 多言語サポートの詳細については、言語サポートをご覧ください。 | en-us |
| 複数言語 | true |
データセットで複数の言語のドキュメントを得ることを可能とするブール値であり、モデルがデプロイされる場合に、サポートする任意の言語 (必ずしもトレーニング ドキュメントに含まれているとは限りません) でモデルに関するクエリを実行することができます。 多言語サポートの詳細については、言語サポートをご覧ください。 | true |
| storageInputContainerName | {CONTAINER-NAME} |
ドキュメントをアップロードした Azure ストレージ コンテナーの名前。 | myContainer |
| ドキュメント | [] | プロジェクト内のすべてのドキュメントと、このドキュメントにラベル付けされたクラスを含む配列。 | [] |
| location | {DOCUMENT-NAME} |
ストレージ コンテナー内のドキュメントの場所。 すべてのドキュメントはコンテナーのルートに含まれているので、これはドキュメント名にする必要があります。 | doc1.txt |
| sentimentSpans | {sentimentSpans} |
ドキュメントのセンチメント (肯定的、中立、否定的)、センチメントの開始位置、およびその長さ。 | [] |
API 要求を送信すると、ジョブが正しく送信されたことを示す 202 応答を受け取ります。 応答ヘッダーで、operation-location の値を抽出します。 それは次のように書式設定されています。
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
この操作は非同期であるため、{JOB-ID} を使って要求が識別されます。 この URL を使用してインポート ジョブの状態を取得します。
この要求で考えられるエラー シナリオ:
- 指定された
storageInputContainerNameが存在しません。 - 無効な言語コードが使用されているか、言語コードの種類が文字列でない場合。
multilingual値は文字列であり、ブール値ではありません。
インポート ジョブの状態を取得する
次の GET 要求を使用して、プロジェクトのインポートの状態を取得します。 次のプレースホルダーの値を実際の値に置き換えてください。
要求 URL
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
| プレースホルダー | 値 | 例 |
|---|---|---|
{ENDPOINT} |
API 要求を認証するためのエンドポイント。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
プロジェクトの名前。 この値は、大文字と小文字が区別されます。 | myProject |
{JOB-ID} |
モデルのトレーニングの状態を取得するための ID。 この値は、前のステップで受け取った location ヘッダーの値に含まれています。 |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
呼び出している API のバージョン。 ここで参照される値は、リリース済みの最新バージョン用です。 その他の利用可能な API バージョンの詳細を確認する | 2023-04-15-preview |
ヘッダー
要求を認証するには、次のヘッダーを使います。
| Key | 値 |
|---|---|
Ocp-Apim-Subscription-Key |
リソースへのキー。 API 要求の認証に使われます。 |
モデルをトレーニングする
通常、プロジェクトを作成したら、プロジェクトに接続されているコンテナーにあるドキュメントのタグ付けを開始します。 このクイックスタートでは、サンプルのタグ付けされたデータセットをインポートし、サンプルの JSON タグ ファイルを使用してプロジェクトを初期化しました。
モデルのトレーニングを開始する
プロジェクトがインポートされたら、モデルのトレーニングを開始できます。
トレーニング ジョブを送信するには、次の URL、ヘッダー、JSON 本文を使用して POST 要求を送信します。 プレースホルダーの値は、実際の値に置き換えます。
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/:train?api-version={API-VERSION}
| プレースホルダー | 値 | 例 |
|---|---|---|
{ENDPOINT} |
API 要求を認証するためのエンドポイント。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
プロジェクトの名前。 この値は、大文字と小文字が区別されます。 | myProject |
{API-VERSION} |
呼び出している API のバージョン。 ここで参照される値は、リリース済みの最新バージョン用です。 その他の利用可能な API バージョンの詳細を確認する | 2023-04-15-preview |
ヘッダー
要求を認証するには、次のヘッダーを使います。
| Key | 値 |
|---|---|
Ocp-Apim-Subscription-Key |
リソースへのキー。 API 要求の認証に使われます。 |
要求本文
要求本文では次の JSON を使います。 トレーニングが完了すると、モデルに {MODEL-NAME} が与えられます。 正常に完了したトレーニング ジョブでのみ、モデルが生成されます。
{
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"evaluationOptions": {
"kind": "percentage",
"trainingSplitPercentage": 80,
"testingSplitPercentage": 20
}
}
| Key | プレースホルダー | 値 | 例 |
|---|---|---|---|
| modelLabel | {MODEL-NAME} |
トレーニングが正常に行われた後にモデルに割り当てられるモデル名。 | myModel |
| trainingConfigVersion | {CONFIG-VERSION} |
これは、モデルをトレーニングするために使用されるモデル バージョンです。 | 2023-04-15-preview |
| evaluationOptions | データをトレーニング用セットとテスト用セットに分割するオプション。 | {} |
|
| kind | percentage |
分割方法。 指定できる値は percentage または manual です。 |
percentage |
| trainingSplitPercentage | 80 |
トレーニング セットに含まれるタグ付きデータの割合。 推奨値は 80 です。 |
80 |
| testingSplitPercentage | 20 |
テスト セットに含まれるタグ付きデータの割合。 推奨値は 20 です。 |
20 |
注意
trainingSplitPercentage と testingSplitPercentage は、Kind が percentage に設定されている場合にのみ必要であり、両方の割合の合計は 100 に等しくなる必要があります。
API 要求を送信すると、ジョブが正しく送信されたことを示す 202 応答を受け取ります。 応答ヘッダーで、location の値を抽出します。 それは次のように書式設定されています。
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
この操作は非同期であるため、要求を識別するために、{JOB ID} が使われます。 この URL を使用してトレーニングの状態を取得できます。
トレーニング ジョブの状態を取得する
トレーニングには 10 分から 30 分かかる場合があります。 次の要求を使用して、トレーニング ジョブが正常に完了するまで状態をポーリングし続けることができます。
モデルのトレーニングの進行状況を表す状態を取得するには、次の GET 要求を使用します。 プレースホルダーの値は、実際の値に置き換えます。
要求 URL
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
| プレースホルダー | 値 | 例 |
|---|---|---|
{ENDPOINT} |
API 要求を認証するためのエンドポイント。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
プロジェクトの名前。 この値は、大文字と小文字が区別されます。 | myProject |
{JOB-ID} |
モデルのトレーニングの状態を取得するための ID。 この値は、前のステップで受け取った location ヘッダーの値に含まれています。 |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
呼び出している API のバージョン。 ここで参照される値は、リリース済みの最新バージョン用です。 使用可能な他の API バージョンの詳細については、「モデルのライフサイクル」を参照してください。 | 2023-04-15-preview |
ヘッダー
要求を認証するには、次のヘッダーを使います。
| Key | 値 |
|---|---|
Ocp-Apim-Subscription-Key |
リソースへのキー。 API 要求の認証に使われます。 |
応答本文
要求を送信すると、次の応答を受け取ります。
{
"result": {
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"estimatedEndDateTime": "2022-04-18T15:47:58.8190649Z",
"trainingStatus": {
"percentComplete": 3,
"startDateTime": "2022-04-18T15:45:06.8190649Z",
"status": "running"
},
"evaluationStatus": {
"percentComplete": 0,
"status": "notStarted"
}
},
"jobId": "{JOB-ID}",
"createdDateTime": "2022-04-18T15:44:44Z",
"lastUpdatedDateTime": "2022-04-18T15:45:48Z",
"expirationDateTime": "2022-04-25T15:44:44Z",
"status": "running"
}
モデルをデプロイする
通常はモデルをトレーニングした後、その評価の詳細を確認し、必要に応じて改善を行います。 このクイックスタートでは、モデルをデプロイして Language Studio で試せるようにするところまで行いますが、予測 API を呼び出すこともできます。
デプロイ ジョブを送信する
デプロイ ジョブを送信するには、次の URL、ヘッダー、JSON 本文を使って PUT 要求を送信します。 プレースホルダーの値は、実際の値に置き換えます。
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/deployments/{deploymentName}?api-version={API-VERSION}
| プレースホルダー | 値 | 例 |
|---|---|---|
{ENDPOINT} |
API 要求を認証するためのエンドポイント。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
プロジェクトの名前。 この値は、大文字と小文字が区別されます。 | myProject |
{DEPLOYMENT-NAME} |
デプロイの名前。 この値は、大文字と小文字が区別されます。 | staging |
{API-VERSION} |
呼び出している API のバージョン。 ここで参照される値は、リリース済みの最新バージョン用です。 使用可能な他の API バージョンの詳細については、モデルのライフサイクルに関するページを参照してください。 | 2023-04-15-preview |
ヘッダー
要求を認証するには、次のヘッダーを使います。
| Key | 値 |
|---|---|
Ocp-Apim-Subscription-Key |
リソースへのキー。 API 要求の認証に使われます。 |
要求本文
要求の本文で次の JSON を使います。 デプロイに割り当てるモデルの名前を使います。
{
"trainedModelLabel": "{MODEL-NAME}"
}
| Key | プレースホルダー | 値 | 例 |
|---|---|---|---|
| trainedModelLabel | {MODEL-NAME} |
デプロイに割り当てられるモデル名。 正常にトレーニングされたモデルのみ割り当てることができます。 この値は、大文字と小文字が区別されます。 | myModel |
API 要求を送信すると、ジョブが正しく送信されたことを示す 202 応答を受け取ります。 応答ヘッダーで、operation-location の値を抽出します。 それは次のように書式設定されています。
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
この操作は非同期であるため、{JOB-ID} を使って要求が識別されます。 この URL を使用してデプロイの状態を取得できます。
デプロイ ジョブの状態を取得する
デプロイ ジョブの状態を照会するには、次の GET 要求を使います。 前のステップで取得した URL を使うことも、プレースホルダーの値を実際の値に置き換えることもできます。
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
| プレースホルダー | 値 | 例 |
|---|---|---|
{ENDPOINT} |
API 要求を認証するためのエンドポイント。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
プロジェクトの名前。 この値は、大文字と小文字が区別されます。 | myProject |
{DEPLOYMENT-NAME} |
デプロイの名前。 この値は、大文字と小文字が区別されます。 | staging |
{JOB-ID} |
モデルのトレーニングの状態を取得するための ID。 これは、前のステップで受け取った location ヘッダーの値に含まれています。 |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
呼び出している API のバージョン。 ここで参照される値は、リリース済みの最新バージョン用です。 使用可能な他の API バージョンの詳細については、モデルのライフサイクルに関するページを参照してください。 | 2023-04-15-preview |
ヘッダー
要求を認証するには、次のヘッダーを使います。
| Key | 値 |
|---|---|
Ocp-Apim-Subscription-Key |
リソースへのキー。 API 要求の認証に使われます。 |
応答本文
要求を送信すると、次の応答を受け取ります。 [status](状態) パラメーターが [succeeded](成功) に変更されるまで、このエンドポイントのポーリングを続けます。 要求の成功を示す 200 コードを取得します。
{
"jobId":"{JOB-ID}",
"createdDateTime":"{CREATED-TIME}",
"lastUpdatedDateTime":"{UPDATED-TIME}",
"expirationDateTime":"{EXPIRATION-TIME}",
"status":"running"
}
テキストを分類する
モデルが正常にデプロイされたら、モデルの使用を開始して 予測 API を使ってテキストを分類できます。 先ほどダウンロードしたサンプル データセットに、この手順で使用できるテスト ドキュメントがいくつか用意されています。
カスタム センチメント分析タスクを送信する
この POST 要求を使用して、テキスト分類タスクを開始します。
{ENDPOINT}/language/analyze-text/jobs?api-version={API-VERSION}
| プレースホルダー | 値 | 例 |
|---|---|---|
{ENDPOINT} |
API 要求を認証するためのエンドポイント。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
呼び出している API のバージョン。 ここで参照される値は、リリース済みの最新バージョン用です。 | 2023-04-15-preview |
ヘッダー
| Key | 価値 |
|---|---|
| Ocp-Apim-Subscription-Key | この API へのアクセスを提供するキー。 |
Body
{
"displayName": "Detecting sentiment",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "{LANGUAGE-CODE}",
"text": "Text1"
},
{
"id": "2",
"language": "{LANGUAGE-CODE}",
"text": "Text2"
}
]
},
"tasks": [
{
"kind": "CustomTextSentiment",
"taskName": "Sentiment analysis",
"parameters": {
"projectName": "{PROJECT-NAME}",
"deploymentName": "{DEPLOYMENT-NAME}"
}
}
]
}
| Key | プレースホルダー | 値 | 例 |
|---|---|---|---|
displayName |
{JOB-NAME} |
ジョブの名前。 | MyJobName |
documents |
[{},{}] | タスクを実行するドキュメントのリスト。 | [{},{}] |
id |
{DOC-ID} |
ドキュメント名または ID。 | doc1 |
language |
{LANGUAGE-CODE} |
ドキュメントの言語コードを指定する文字列。 このキーが指定されていない場合、サービスではプロジェクトの作成時に選択されたプロジェクトの既定の言語を想定します。 | en-us |
text |
{DOC-TEXT} |
タスクを実行するドキュメント タスク。 | Lorem ipsum dolor sit amet |
tasks |
実行するタスクのリスト。 | [] |
|
taskName |
CustomTextSentiment |
タスク名 | CustomTextSentiment |
parameters |
タスクに渡すパラメーターのリスト。 | ||
project-name |
{PROJECT-NAME} |
プロジェクトの名前。 この値は、大文字と小文字が区別されます。 | myProject |
deployment-name |
{DEPLOYMENT-NAME} |
デプロイの名前。 この値は、大文字と小文字が区別されます。 | prod |
[応答]
タスクが正常に送信されたことを示す 202 応答を受け取ります。 応答のヘッダーで、operation-location を抽出します。
operation-location は次のように書式設定されています。
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
この URL を使用して、タスクの完了状態をクエリし、タスクが完了したときに結果を取得できます。
タスクの結果を取得する
カスタム エンティティ認識タスクの状態と結果を照会するには、次の GET 要求を使います。
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
| プレースホルダー | 値 | 例 |
|---|---|---|
{ENDPOINT} |
API 要求を認証するためのエンドポイント。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
呼び出している API のバージョン。 ここで参照される値は、リリース済みの最新バージョン用です。 | 2023-04-15-preview |
ヘッダー
| Key | 価値 |
|---|---|
| Ocp-Apim-Subscription-Key | この API へのアクセスを提供するキー。 |
応答本文
応答は、次のパラメーターを含む JSON ドキュメントです
{
"createdDateTime": "2021-05-19T14:32:25.578Z",
"displayName": "MyJobName",
"expirationDateTime": "2021-05-19T14:32:25.578Z",
"jobId": "xxxx-xxxx-xxxxx-xxxxx",
"lastUpdateDateTime": "2021-05-19T14:32:25.578Z",
"status": "succeeded",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "EntityRecognitionLROResults",
"taskName": "Recognize Entities",
"lastUpdateDateTime": "2020-10-01T15:01:03Z",
"status": "succeeded",
"results": {
"documents": [
{
"entities": [
{
"category": "Event",
"confidenceScore": 0.61,
"length": 4,
"offset": 18,
"text": "trip"
},
{
"category": "Location",
"confidenceScore": 0.82,
"length": 7,
"offset": 26,
"subcategory": "GPE",
"text": "Seattle"
},
{
"category": "DateTime",
"confidenceScore": 0.8,
"length": 9,
"offset": 34,
"subcategory": "DateRange",
"text": "last week"
}
],
"id": "1",
"warnings": []
}
],
"errors": [],
"modelVersion": "2020-04-01"
}
}
]
}
}
リソースをクリーンアップする
プロジェクトが不要になったら、次の DELETE 要求で削除できます。 プレースホルダーの値は、実際の値に置き換えます。
{Endpoint}/language/authoring/analyze-text/projects/{projectName}?api-version={API-VERSION}
| プレースホルダー | 値 | 例 |
|---|---|---|
{ENDPOINT} |
API 要求を認証するためのエンドポイント。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
プロジェクトの名前。 この値は、大文字と小文字が区別されます。 | myProject |
{API-VERSION} |
呼び出している API のバージョン。 ここで参照される値は、リリース済みの最新バージョン用です。 その他の利用可能な API バージョンの詳細を確認する | 2023-04-15-preview |
ヘッダー
要求を認証するには、次のヘッダーを使います。
| Key | 価値 |
|---|---|
| Ocp-Apim-Subscription-Key | リソースへのキー。 API 要求の認証に使われます。 |
API 要求を送信すると、成功を示す 202 応答を受け取ります。これは、プロジェクトが削除されたことを意味します。 呼び出しが成功すると、ジョブの状態を確認するために使用する Operation-Location ヘッダーが返されます。
次の手順
カスタム センチメント分析モデルを作成したら、次のことができます。
独自のカスタム センチメント分析プロジェクトの作成を開始するときは、ハウツー記事を使用して、モデルの開発の詳細について確認してください。