Custom Speech を使用すると、アプリケーションや製品の音声認識の正確性を評価して改善できます。 Custom Speech モデルは、リアルタイムの音声テキスト変換、音声翻訳、バッチ文字起こしに使用できます。
音声認識では、Microsoft が所有するデータを使用してトレーニングされ、一般的に使用される音声言語を反映する基本モデルとしてユニバーサル言語モデルが活用されます。面倒な設定はありません。 この基本モデルは、さまざまな一般的なドメインを表す方言と発音を使用して事前にトレーニングされています。 音声認識要求を行うと、既定では、サポートされている各言語の最新の基本モデルが使用されます。 この基本モデルは、ほとんどの音声認識シナリオで適切に動作します。
カスタム モデルを使用すると、モデルをトレーニングするテキスト データを提供することによって、ベース モデルを拡張し、アプリケーションに特有のドメイン固有のボキャブラリの認識を向上させることができます。 また、参照文字起こしを含むオーディオ データを提供することで、アプリケーションの特定のオーディオ条件に基づいた認識を改善する際にも使用できます。
また、データがパターンに従う場合に構造化テキストを使用してモデルをトレーニングし、カスタムの発音を指定したり、カスタムの逆テキスト正規化、カスタムの書き換え、カスタムの不適切表現のフィルター処理を使用して表示テキストのフォーマットをカスタマイズしたりすることができます。
動作のしくみ
Custom Speech を使用すると、独自データのアップロード、カスタム モデルのテストとトレーニング、モデル間での正確性の比較、カスタム エンドポイントへのモデルのデプロイを行うことができます。
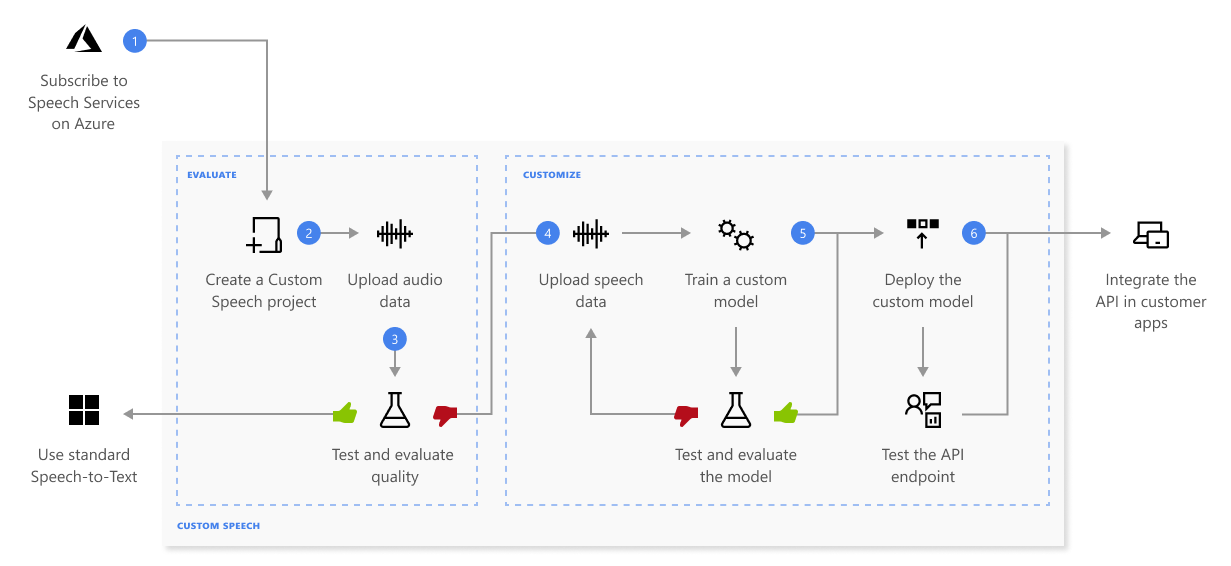
ここでは、上の図に示されている一連の手順について詳しく説明します。
プロジェクトを作成し、モデルを選択します。 Azure portal で作成する音声リソース を使用します。 オーディオ データを使用してカスタム モデルをトレーニングする場合は、オーディオ データをトレーニングするための専用ハードウェアがあるリージョンのサービス リソースを選択します。 詳細については、リージョン テーブルの脚注を参照してください。
テスト データをアップロードします。 テスト データをアップロードして、ご利用のアプリケーション、ツール、製品に使用する音声テキスト変換プランを評価します。
モデルをトレーニングします。 書き込まれたトランスクリプトと関連テキストを、対応するオーディオ データとともに提供します。 トレーニング前後のモデルのテストは省略可能ですが、推奨されます。
注
Custom Speech モデルの使用とエンドポイント ホスティングには料金が発生します。 基本モデルが 2023 年 10 月 1 日以降に作成された場合、Custom Speech モデルのトレーニングに対しても課金が行われます。 基本モデルが 2023 年 10 月より前に作成されたものである場合、トレーニングに対する課金は行われません。 詳細については、「Azure AI Speech の価格」と音声テキスト変換 3.2 への移行ガイドの「適応に対する課金」セクションを参照してください。
認識品質をテストします。 Speech Studio を使用して、アップロードした音声を再生し、テスト データの音声認識品質を調査します。
モデルを定量的にテストします。 音声テキスト変換モデルの正確性を評価して改善します。 Speech サービスには、さらにトレーニングが必要かどうかを判定するために使用できる定量的な単語誤り率 (WER) が用意されています。
モデルをデプロイします。 テスト結果に問題がなければ、モデルをカスタム エンドポイントにデプロイします。 バッチ文字起こしを除き、Custom Speech モデルを使用するには、カスタム エンドポイントをデプロイする必要があります。
ヒント
バッチ文字起こし API で Custom Speech を使用するには、ホストされたデプロイ エンドポイントは必要ありません。 Custom Speech モデルがバッチ文字起こしにのみ使用される場合は、リソースを節約できます。 詳細については、Speech Services の価格に関するページを参照してください。
モデルを選択する
Custom Speech モデルを使用するには、次のようにいくつかの方法があります。
- 基本モデルには、さまざまなシナリオですぐに利用できる正確な音声認識があります。 基本モデルは、精度と品質を向上させるために定期的に更新されます。 基本モデルを使用する場合は、最新の既定の基本モデルを使用することをお勧めします。 必要なカスタマイズ機能が古いモデルでしか使用できない場合は、古い基本モデルを選択できます。
- カスタム モデルは基本モデルを拡張して、カスタム ドメインのすべての領域で共有されるドメイン固有のボキャブラリを含みます。
- カスタム ドメインに複数の領域があり、それぞれが特定のボキャブラリを持つ場合は、複数のカスタム モデルを使用できます。
基本モデルで十分かどうかを確認するお勧めの方法の 1 つは、基本モデルから生成された文字起こしを分析し、同じ音声で人間が生成した文字起こしと比較することです。 文字起こしを比較して、単語誤り率 (WER) スコアを取得できます。 WER スコアが高い場合は、誤って識別された単語を認識するようにカスタム モデルをトレーニングすることをお勧めします。
ボキャブラリがドメイン領域によって異なる場合は、複数のモデルを使用することをお勧めします。 たとえば、オリンピックの解説者がレポートする各種競技は、それぞれが独自の用語に関連付けられています。 オリンピック競技の各ボキャブラリは他の競技と大きく異なるため、競技に固有のカスタム モデルを作成すると、その特定の競技に関連する発話データを制限することで精度が向上します。 その結果、モデルでは、照合するために関連性のないデータをふるいにかける必要がありません。 それでも、トレーニングには十分な種類のトレーニング データが必要です。 アクセント、性別、年齢などが異なるさまざまな解説者の音声を含めます。
モデルの安定性とライフサイクル
Custom Speech を使用してエンドポイントにデプロイされた基本モデルまたはカスタム モデルは、更新を決定するまで固定されます。 新しい基本モデルがリリースされても、音声認識の正確性と品質は一貫したままです。 これにより、新しいモデルを使用することを決定するまで、特定のモデルの動作を固定できます。
独自のモデルをトレーニングするか、基本モデルのスナップショットを使用するかにかかわらず、期間限定でモデルを使用できます。 詳細については、「モデルとエンドポイントのライフサイクル」を参照してください。
責任ある AI
AI システムには、テクノロジだけでなく、それを使用する人、それによって影響を受ける人、それがデプロイされる環境も含まれます。 「透明性に関するメモ」を読み、システムでの責任ある AI の使用とデプロイについて確認してください。