クイックスタート: 音声を認識してテキストに変換する
重要
この記事で "(プレビュー)" と付記されている項目は、現在、パブリック プレビュー段階です。 このプレビューはサービス レベル アグリーメントなしで提供されており、運用環境ではお勧めしません。 特定の機能はサポート対象ではなく、機能が制限されることがあります。 詳しくは、Microsoft Azure プレビューの追加使用条件に関するページをご覧ください。
このクイック スタートでは、Azure AI Studio でリアルタイムの音声テキスト変換を 試します。
前提条件
- Azure サブスクリプション - 無料アカウントを作成します。
- 一部の AI サービス機能は、AI Studio で無料で試すことができます。 この記事で説明されているすべての機能にアクセスするには、AI サービスを AI Studio のハブに接続する必要があります。
リアルタイムの音声テキスト変換を試す
AI Studio の [ホーム] ページに 移動し、左側のウィンドウから [AI サービス] を選択 します。
![Azure AI Studio の [AI サービス] ページのスクリーンショット。](media/ai-studio/ai-services-home.png)
AI サービスの一覧から [Speech] を選択 します。
[リアルタイムの音声テキスト変換] を選択します。
![[リアルタイム音声テキスト変換] タイルを選択するオプションのスクリーンショット。](media/ai-studio/real-time-speech-to-text-select.png)
[試してみる] セクションで、ハブの AI サービス接続を選択します。 AI サービス接続の詳細については、「AI Studio で AI サービスをハブに接続する」を参照してください。
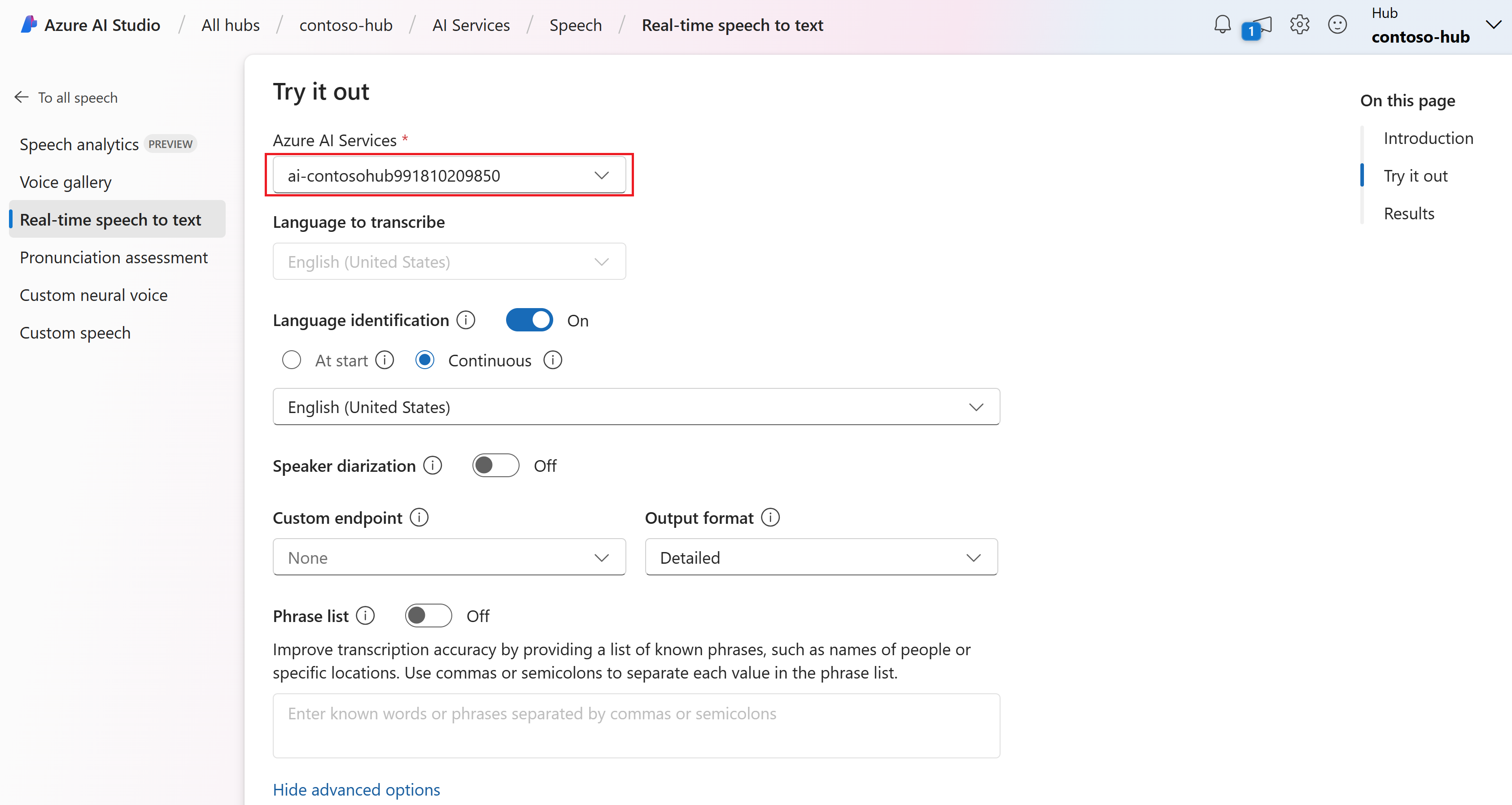
[詳細オプションの表示] を選択して、次のような音声テキスト変換オプションを構成します。
- 言語識別: サポートされている言語の一覧と照合する際に、オーディオで話されている言語を識別するために使用されます。 開始時や継続的認識などの言語識別オプションの詳細については、「言語識別」を参照してください。
- スピーカーのダイアライゼーション: オーディオ内の話者を識別して分離するために使用されます。 ダイアライゼーションは、会話に参加している異なる話者を区別します。 音声サービスは、文字起こしされた音声の特定の部分を話していた話者に関する情報を提供します。 話者のダイアライゼーションの詳細については、「話者のダイアライゼーションを使用したリアルタイムの音声テキスト変換」のクイック スタートを参照してください。
- カスタム エンドポイント: カスタム音声からデプロイされたモデルを使用して、認識の精度を向上させます。 Microsoft のベースライン モデルを使用するには、この設定を [なし] のままにします。 カスタム音声の詳細については、「カスタム音声」を参照してください。
- 出力形式: 単純な出力形式と詳細な出力形式のいずれかを選択します。 単純な出力には、表示形式とタイムスタンプが含まれます。 詳細な出力には、より多くの形式 (表示、字句、ITN、マスクされた ITN など)、タイムスタンプ、N-best リストが含まれます。
- フレーズ リスト: ユーザーの名前や特定の場所など、既知の語句の一覧を用意することで、文字起こしの精度を向上させます。 フレーズ リストの各値を区切るには、コンマまたはセミコロンを使用します。 フレーズ リストの詳細については、「フレーズ リスト」を参照してください。
アップロードするオーディオ ファイルを選択するか、リアルタイムでオーディオを録音します。 この例では、GitHub の Speech SDK リポジトリにある
Call1_separated_16k_health_insurance.wavファイルを使用します。 ファイルをダウンロードすることも、独自のオーディオ ファイルを使用することもできます。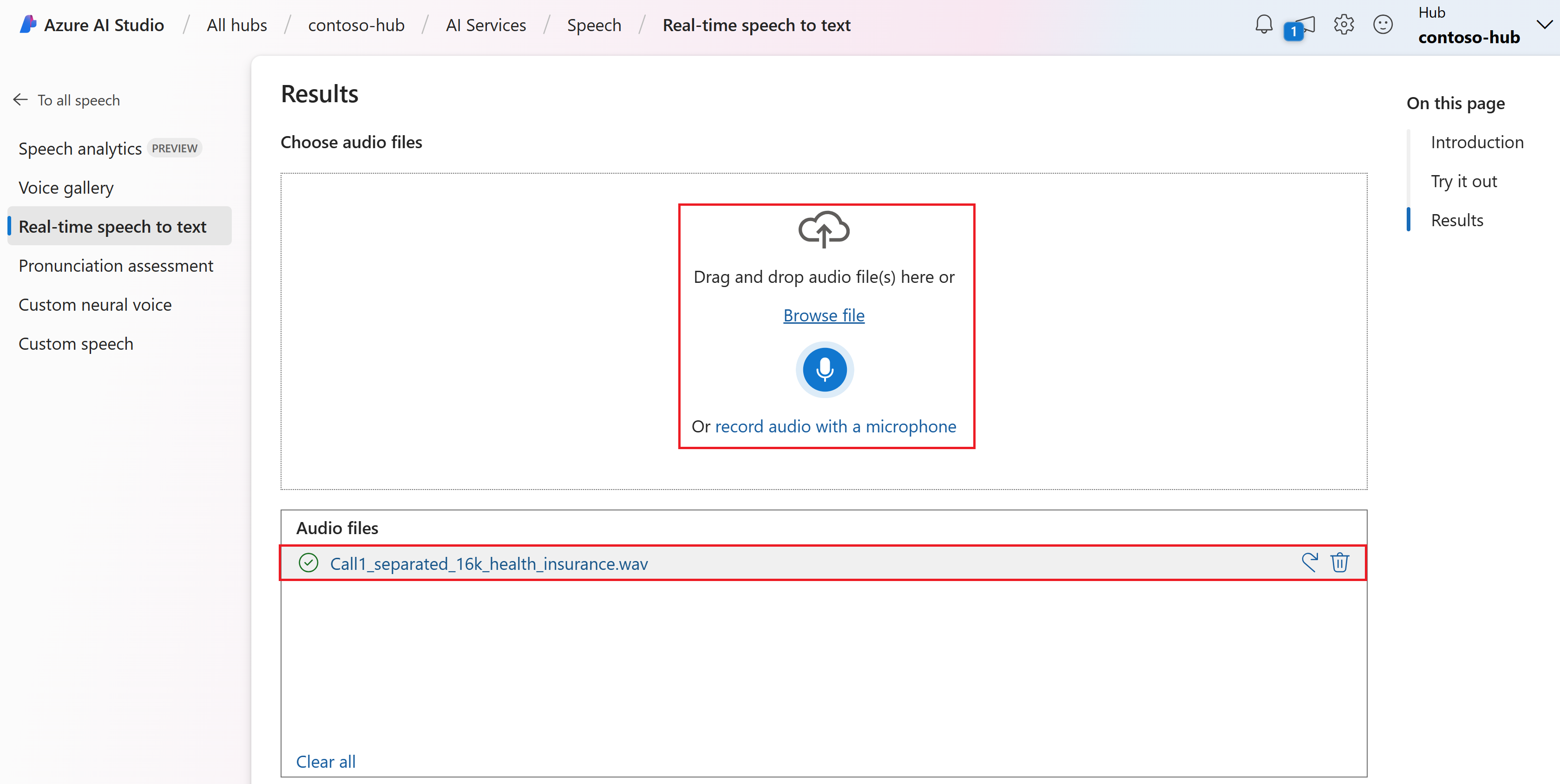
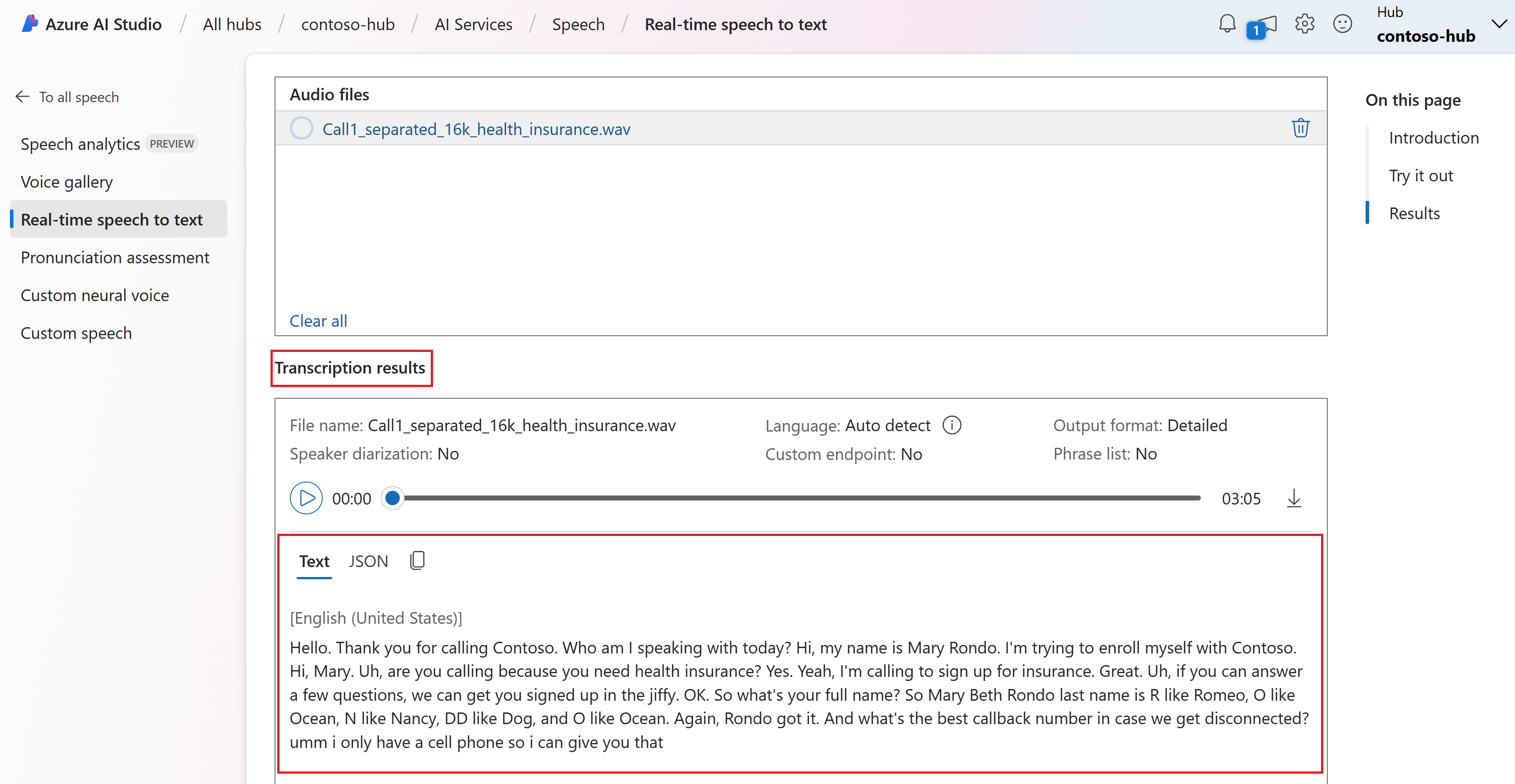
リアルタイム音声テキスト変換の結果は、[結果] セクションで表示できます。
![Azure AI Studio の [AI サービス] ページのスクリーンショット。](media/ai-studio/ai-services-home.png#lightbox)
![[リアルタイム音声テキスト変換] タイルを選択するオプションのスクリーンショット。](media/ai-studio/real-time-speech-to-text-select.png#lightbox)



リファレンス ドキュメント | パッケージ (NuGet) | GitHub のその他のサンプル
このクイックスタートでは、音声を認識してリアルタイムでテキストに変換するアプリケーションを作成して実行します。
代わりに、オーディオ ファイルを非同期的に文字起こしするには、「バッチ文字起こしとは」を参照してください。 最適な音声テキスト変換ソリューションがわからない場合は、「音声テキスト変換とは」を参照してください。
前提条件
- Azure サブスクリプション。 無料で作成できます。
- Azure ポータルで、音声リソースを作成します。
- Speech リソース キーとリージョンを取得します。 音声リソースがデプロイされたら、[リソースに移動] を選択して、キーを表示および管理します。
環境をセットアップする
Speech SDK は NuGet パッケージとして提供されていて、.NET Standard 2.0 が実装されています。 このガイドの後半で音声 SDK をインストールします。 その他の要件については、「音声 SDK のインストール」を参照してください。
環境変数を設定する
Azure AI サービスにアクセスするには、アプリケーションを認証する必要があります。 この記事では、環境変数を使って資格情報を格納する方法について説明します。 その後、コードから環境変数にアクセスして、アプリケーションを認証できます。 運用環境では、資格情報を保存してそれにアクセスする際に、安全性が高い方法を使用します。
重要
Microsoft Entra 認証と Azure リソースのマネージド ID を併用して、クラウドで実行されるアプリケーションに資格情報を格納しないようにすることをお勧めします。
API キーを使用する場合は、それを Azure Key Vault などの別の場所に安全に保存します。 API キーは、コード内に直接含めないようにし、絶対に公開しないでください。
AI サービスのセキュリティの詳細については、「Azure AI サービスに対する要求の認証」を参照してください。
Azure Cognitive Service for Speech リソース キーとリージョンの環境変数を設定するには、コンソール ウィンドウを開き、使用しているオペレーティング システムと開発環境についての指示に従います。
SPEECH_KEY環境変数を設定するには、your-key をリソースのキーの 1 つに置き換えます。SPEECH_REGION環境変数を設定するには、your-region をリソースのリージョンの 1 つに置き換えます。
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Note
現在のコンソールで環境変数のみにアクセスする必要がある場合は、環境変数を setx の代わりに set に設定できます。
環境変数を追加した後、コンソール ウィンドウを含め、環境変数を読み取る必要があるプログラムの再起動が必要になる場合があります。 たとえば、Visual Studio をエディターとして使用している場合、サンプルを実行する前に Visual Studio を再起動します。
マイクから音声を認識する
ヒント
Azure AI Speech Toolkit を試して、Visual Studio Code でサンプルを簡単にビルドして実行します。
以下の手順に従ってコンソール アプリケーションを作成し、音声 SDK をインストールします。
新しいプロジェクトを作成したいフォルダーでコマンド プロンプト ウィンドウを開きます。 次のコマンドを実行して、.NET CLI でコンソール アプリケーションを作成します。
dotnet new consoleこのコマンドは、プロジェクト ディレクトリに Program.cs ファイルを作成します。
.NET CLI を使用して、新しいプロジェクトに Speech SDK をインストールします。
dotnet add package Microsoft.CognitiveServices.SpeechProgram.cs の内容を次のコードで置き換えます。
using System; using System.IO; using System.Threading.Tasks; using Microsoft.CognitiveServices.Speech; using Microsoft.CognitiveServices.Speech.Audio; class Program { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" static string speechKey = Environment.GetEnvironmentVariable("SPEECH_KEY"); static string speechRegion = Environment.GetEnvironmentVariable("SPEECH_REGION"); static void OutputSpeechRecognitionResult(SpeechRecognitionResult speechRecognitionResult) { switch (speechRecognitionResult.Reason) { case ResultReason.RecognizedSpeech: Console.WriteLine($"RECOGNIZED: Text={speechRecognitionResult.Text}"); break; case ResultReason.NoMatch: Console.WriteLine($"NOMATCH: Speech could not be recognized."); break; case ResultReason.Canceled: var cancellation = CancellationDetails.FromResult(speechRecognitionResult); Console.WriteLine($"CANCELED: Reason={cancellation.Reason}"); if (cancellation.Reason == CancellationReason.Error) { Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}"); Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}"); Console.WriteLine($"CANCELED: Did you set the speech resource key and region values?"); } break; } } async static Task Main(string[] args) { var speechConfig = SpeechConfig.FromSubscription(speechKey, speechRegion); speechConfig.SpeechRecognitionLanguage = "en-US"; using var audioConfig = AudioConfig.FromDefaultMicrophoneInput(); using var speechRecognizer = new SpeechRecognizer(speechConfig, audioConfig); Console.WriteLine("Speak into your microphone."); var speechRecognitionResult = await speechRecognizer.RecognizeOnceAsync(); OutputSpeechRecognitionResult(speechRecognitionResult); } }音声認識言語を変更するには、
en-USを別のen-USに置き換えます。 たとえば、スペイン語 (スペイン) の場合はes-ESを使用します。 言語を指定しない場合、既定値はen-USになります。 話される可能性のある複数の言語の 1 つを識別する方法の詳細については、「言語の識別」を参照してください。新しいコンソール アプリケーションを実行して、マイクからの音声認識を開始します。
dotnet run重要
必ず
SPEECH_KEYとSPEECH_REGION環境変数を設定してください。 これらの変数を設定しない場合、サンプルは失敗してエラー メッセージが表示されます。指示されたらマイクに向って話します。 話すことがテキストとして表示されるはずです:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
解説
その他の考慮事項のいくつかを次に示します:
この例では、
RecognizeOnceAsync操作を使用して、最大 30 秒間、または無音が検出されるまでの発話を文字起こししています。 多言語での会話を含め、より長いオーディオの継続的認識については、「音声を認識する方法」を参照してください。オーディオ ファイルから音声を認識するには、
FromDefaultMicrophoneInputの代わりにFromWavFileInputを使用します。using var audioConfig = AudioConfig.FromWavFileInput("YourAudioFile.wav");MP4 などの圧縮されたオーディオ ファイルの場合は、GStreamer をインストールして、
PullAudioInputStreamまたはPushAudioInputStreamを使います。 詳しくは、「圧縮された入力オーディオを使用する方法」をご覧ください。
リソースをクリーンアップする
Azure portal または Azure コマンドライン インターフェイス (CLI) を使用して、作成した音声リソースを削除できます。
リファレンス ドキュメント | パッケージ (NuGet) | GitHub のその他のサンプル
このクイックスタートでは、音声を認識してリアルタイムでテキストに変換するアプリケーションを作成して実行します。
代わりに、オーディオ ファイルを非同期的に文字起こしするには、「バッチ文字起こしとは」を参照してください。 最適な音声テキスト変換ソリューションがわからない場合は、「音声テキスト変換とは」を参照してください。
前提条件
- Azure サブスクリプション。 無料で作成できます。
- Azure ポータルで、音声リソースを作成します。
- Speech リソース キーとリージョンを取得します。 音声リソースがデプロイされたら、[リソースに移動] を選択して、キーを表示および管理します。
環境をセットアップする
Speech SDK は NuGet パッケージとして提供されていて、.NET Standard 2.0 が実装されています。 このガイドの後半で音声 SDK をインストールします。 その他の要件については、「音声 SDK のインストール」を参照してください。
環境変数を設定する
Azure AI サービスにアクセスするには、アプリケーションを認証する必要があります。 この記事では、環境変数を使って資格情報を格納する方法について説明します。 その後、コードから環境変数にアクセスして、アプリケーションを認証できます。 運用環境では、資格情報を保存してそれにアクセスする際に、安全性が高い方法を使用します。
重要
Microsoft Entra 認証と Azure リソースのマネージド ID を併用して、クラウドで実行されるアプリケーションに資格情報を格納しないようにすることをお勧めします。
API キーを使用する場合は、それを Azure Key Vault などの別の場所に安全に保存します。 API キーは、コード内に直接含めないようにし、絶対に公開しないでください。
AI サービスのセキュリティの詳細については、「Azure AI サービスに対する要求の認証」を参照してください。
Azure Cognitive Service for Speech リソース キーとリージョンの環境変数を設定するには、コンソール ウィンドウを開き、使用しているオペレーティング システムと開発環境についての指示に従います。
SPEECH_KEY環境変数を設定するには、your-key をリソースのキーの 1 つに置き換えます。SPEECH_REGION環境変数を設定するには、your-region をリソースのリージョンの 1 つに置き換えます。
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Note
現在のコンソールで環境変数のみにアクセスする必要がある場合は、環境変数を setx の代わりに set に設定できます。
環境変数を追加した後、コンソール ウィンドウを含め、環境変数を読み取る必要があるプログラムの再起動が必要になる場合があります。 たとえば、Visual Studio をエディターとして使用している場合、サンプルを実行する前に Visual Studio を再起動します。
マイクから音声を認識する
ヒント
Azure AI Speech Toolkit を試して、Visual Studio Code でサンプルを簡単にビルドして実行します。
以下の手順に従ってコンソール アプリケーションを作成し、音声 SDK をインストールします。
Visual Studio Community で、
SpeechRecognitionという新しい C++ コンソール プロジェクトを作成します。[ツール]>[NuGet パッケージ マネージャー]>[パッケージ マネージャー コンソール] を選択します。 [パッケージ マネージャー コンソール] で、次のコマンドを実行します:
Install-Package Microsoft.CognitiveServices.SpeechSpeechRecognition.cppの内容を次のコードに置き換えます。#include <iostream> #include <stdlib.h> #include <speechapi_cxx.h> using namespace Microsoft::CognitiveServices::Speech; using namespace Microsoft::CognitiveServices::Speech::Audio; std::string GetEnvironmentVariable(const char* name); int main() { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" auto speechKey = GetEnvironmentVariable("SPEECH_KEY"); auto speechRegion = GetEnvironmentVariable("SPEECH_REGION"); if ((size(speechKey) == 0) || (size(speechRegion) == 0)) { std::cout << "Please set both SPEECH_KEY and SPEECH_REGION environment variables." << std::endl; return -1; } auto speechConfig = SpeechConfig::FromSubscription(speechKey, speechRegion); speechConfig->SetSpeechRecognitionLanguage("en-US"); auto audioConfig = AudioConfig::FromDefaultMicrophoneInput(); auto speechRecognizer = SpeechRecognizer::FromConfig(speechConfig, audioConfig); std::cout << "Speak into your microphone.\n"; auto result = speechRecognizer->RecognizeOnceAsync().get(); if (result->Reason == ResultReason::RecognizedSpeech) { std::cout << "RECOGNIZED: Text=" << result->Text << std::endl; } else if (result->Reason == ResultReason::NoMatch) { std::cout << "NOMATCH: Speech could not be recognized." << std::endl; } else if (result->Reason == ResultReason::Canceled) { auto cancellation = CancellationDetails::FromResult(result); std::cout << "CANCELED: Reason=" << (int)cancellation->Reason << std::endl; if (cancellation->Reason == CancellationReason::Error) { std::cout << "CANCELED: ErrorCode=" << (int)cancellation->ErrorCode << std::endl; std::cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails << std::endl; std::cout << "CANCELED: Did you set the speech resource key and region values?" << std::endl; } } } std::string GetEnvironmentVariable(const char* name) { #if defined(_MSC_VER) size_t requiredSize = 0; (void)getenv_s(&requiredSize, nullptr, 0, name); if (requiredSize == 0) { return ""; } auto buffer = std::make_unique<char[]>(requiredSize); (void)getenv_s(&requiredSize, buffer.get(), requiredSize, name); return buffer.get(); #else auto value = getenv(name); return value ? value : ""; #endif }音声認識言語を変更するには、
en-USを別のen-USに置き換えます。 たとえば、スペイン語 (スペイン) の場合はes-ESを使用します。 言語を指定しない場合、既定値はen-USになります。 話される可能性のある複数の言語の 1 つを識別する方法の詳細については、「言語の識別」を参照してください。新しいコンソール アプリケーションをビルドして実行し、マイクからの音声認識を開始します。
重要
必ず
SPEECH_KEYとSPEECH_REGION環境変数を設定してください。 これらの変数を設定しない場合、サンプルは失敗してエラー メッセージが表示されます。指示されたらマイクに向って話します。 話すことがテキストとして表示されるはずです:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
解説
その他の考慮事項のいくつかを次に示します:
この例では、
RecognizeOnceAsync操作を使用して、最大 30 秒間、または無音が検出されるまでの発話を文字起こししています。 多言語での会話を含め、より長いオーディオの継続的認識については、「音声を認識する方法」を参照してください。オーディオ ファイルから音声を認識するには、
FromDefaultMicrophoneInputの代わりにFromWavFileInputを使用します。auto audioConfig = AudioConfig::FromWavFileInput("YourAudioFile.wav");MP4 などの圧縮されたオーディオ ファイルの場合は、GStreamer をインストールして、
PullAudioInputStreamまたはPushAudioInputStreamを使います。 詳しくは、「圧縮された入力オーディオを使用する方法」をご覧ください。
リソースをクリーンアップする
Azure portal または Azure コマンドライン インターフェイス (CLI) を使用して、作成した音声リソースを削除できます。
リファレンス ドキュメント | パッケージ (Go) | GitHub のその他のサンプル
このクイックスタートでは、音声を認識してリアルタイムでテキストに変換するアプリケーションを作成して実行します。
代わりに、オーディオ ファイルを非同期的に文字起こしするには、「バッチ文字起こしとは」を参照してください。 最適な音声テキスト変換ソリューションがわからない場合は、「音声テキスト変換とは」を参照してください。
前提条件
- Azure サブスクリプション。 無料で作成できます。
- Azure ポータルで、音声リソースを作成します。
- Speech リソース キーとリージョンを取得します。 音声リソースがデプロイされたら、[リソースに移動] を選択して、キーを表示および管理します。
環境をセットアップする
Speech SDK for Go をインストールします。 要件と手順については、「音声 SDK のインストール」を参照してください。
環境変数を設定する
Azure AI サービスにアクセスするには、アプリケーションを認証する必要があります。 この記事では、環境変数を使って資格情報を格納する方法について説明します。 その後、コードから環境変数にアクセスして、アプリケーションを認証できます。 運用環境では、資格情報を保存してそれにアクセスする際に、安全性が高い方法を使用します。
重要
Microsoft Entra 認証と Azure リソースのマネージド ID を併用して、クラウドで実行されるアプリケーションに資格情報を格納しないようにすることをお勧めします。
API キーを使用する場合は、それを Azure Key Vault などの別の場所に安全に保存します。 API キーは、コード内に直接含めないようにし、絶対に公開しないでください。
AI サービスのセキュリティの詳細については、「Azure AI サービスに対する要求の認証」を参照してください。
Azure Cognitive Service for Speech リソース キーとリージョンの環境変数を設定するには、コンソール ウィンドウを開き、使用しているオペレーティング システムと開発環境についての指示に従います。
SPEECH_KEY環境変数を設定するには、your-key をリソースのキーの 1 つに置き換えます。SPEECH_REGION環境変数を設定するには、your-region をリソースのリージョンの 1 つに置き換えます。
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Note
現在のコンソールで環境変数のみにアクセスする必要がある場合は、環境変数を setx の代わりに set に設定できます。
環境変数を追加した後、コンソール ウィンドウを含め、環境変数を読み取る必要があるプログラムの再起動が必要になる場合があります。 たとえば、Visual Studio をエディターとして使用している場合、サンプルを実行する前に Visual Studio を再起動します。
マイクから音声を認識する
以下の手順に従って、GO モジュールを作成します。
新しいプロジェクトを作成したいフォルダーでコマンド プロンプト ウィンドウを開きます。 speech-recognition.go という名前の新しいファイルを作成します。
以下のコードを speech-recognition.go にコピーしてください:
package main import ( "bufio" "fmt" "os" "github.com/Microsoft/cognitive-services-speech-sdk-go/audio" "github.com/Microsoft/cognitive-services-speech-sdk-go/speech" ) func sessionStartedHandler(event speech.SessionEventArgs) { defer event.Close() fmt.Println("Session Started (ID=", event.SessionID, ")") } func sessionStoppedHandler(event speech.SessionEventArgs) { defer event.Close() fmt.Println("Session Stopped (ID=", event.SessionID, ")") } func recognizingHandler(event speech.SpeechRecognitionEventArgs) { defer event.Close() fmt.Println("Recognizing:", event.Result.Text) } func recognizedHandler(event speech.SpeechRecognitionEventArgs) { defer event.Close() fmt.Println("Recognized:", event.Result.Text) } func cancelledHandler(event speech.SpeechRecognitionCanceledEventArgs) { defer event.Close() fmt.Println("Received a cancellation: ", event.ErrorDetails) fmt.Println("Did you set the speech resource key and region values?") } func main() { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" speechKey := os.Getenv("SPEECH_KEY") speechRegion := os.Getenv("SPEECH_REGION") audioConfig, err := audio.NewAudioConfigFromDefaultMicrophoneInput() if err != nil { fmt.Println("Got an error: ", err) return } defer audioConfig.Close() speechConfig, err := speech.NewSpeechConfigFromSubscription(speechKey, speechRegion) if err != nil { fmt.Println("Got an error: ", err) return } defer speechConfig.Close() speechRecognizer, err := speech.NewSpeechRecognizerFromConfig(speechConfig, audioConfig) if err != nil { fmt.Println("Got an error: ", err) return } defer speechRecognizer.Close() speechRecognizer.SessionStarted(sessionStartedHandler) speechRecognizer.SessionStopped(sessionStoppedHandler) speechRecognizer.Recognizing(recognizingHandler) speechRecognizer.Recognized(recognizedHandler) speechRecognizer.Canceled(cancelledHandler) speechRecognizer.StartContinuousRecognitionAsync() defer speechRecognizer.StopContinuousRecognitionAsync() bufio.NewReader(os.Stdin).ReadBytes('\n') }次のコマンドを実行して、GitHub でホストされているコンポーネントにリンクする go.mod ファイルを作成します。
go mod init speech-recognition go get github.com/Microsoft/cognitive-services-speech-sdk-go重要
必ず
SPEECH_KEYとSPEECH_REGION環境変数を設定してください。 これらの変数を設定しない場合、サンプルは失敗してエラー メッセージが表示されます。コードをビルドして実行します:
go build go run speech-recognition
リソースをクリーンアップする
Azure portal または Azure コマンドライン インターフェイス (CLI) を使用して、作成した音声リソースを削除できます。
リファレンス ドキュメント | GitHub のその他のサンプル
このクイックスタートでは、音声を認識してリアルタイムでテキストに変換するアプリケーションを作成して実行します。
代わりに、オーディオ ファイルを非同期的に文字起こしするには、「バッチ文字起こしとは」を参照してください。 最適な音声テキスト変換ソリューションがわからない場合は、「音声テキスト変換とは」を参照してください。
前提条件
- Azure サブスクリプション。 無料で作成できます。
- Azure ポータルで、音声リソースを作成します。
- Speech リソース キーとリージョンを取得します。 音声リソースがデプロイされたら、[リソースに移動] を選択して、キーを表示および管理します。
環境をセットアップする
環境を設定するには、音声 SDK をインストールします。 このクイックスタートのサンプルは、Java ランタイムで動作します。
Apache Maven をインストールします。 次に
mvn -vを実行して、インストールが成功したことを確認します。プロジェクトのルートに新しい
pom.xmlファイルを作成し、その中に以下のコードをコピーします:<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.microsoft.cognitiveservices.speech.samples</groupId> <artifactId>quickstart-eclipse</artifactId> <version>1.0.0-SNAPSHOT</version> <build> <sourceDirectory>src</sourceDirectory> <plugins> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>3.7.0</version> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> </plugins> </build> <dependencies> <dependency> <groupId>com.microsoft.cognitiveservices.speech</groupId> <artifactId>client-sdk</artifactId> <version>1.40.0</version> </dependency> </dependencies> </project>Speech SDK と依存関係をインストールします。
mvn clean dependency:copy-dependencies
環境変数の設定
Azure AI サービスにアクセスするには、アプリケーションを認証する必要があります。 この記事では、環境変数を使って資格情報を格納する方法について説明します。 その後、コードから環境変数にアクセスして、アプリケーションを認証できます。 運用環境では、資格情報を保存してそれにアクセスする際に、安全性が高い方法を使用します。
重要
Microsoft Entra 認証と Azure リソースのマネージド ID を併用して、クラウドで実行されるアプリケーションに資格情報を格納しないようにすることをお勧めします。
API キーを使用する場合は、それを Azure Key Vault などの別の場所に安全に保存します。 API キーは、コード内に直接含めないようにし、絶対に公開しないでください。
AI サービスのセキュリティの詳細については、「Azure AI サービスに対する要求の認証」を参照してください。
Azure Cognitive Service for Speech リソース キーとリージョンの環境変数を設定するには、コンソール ウィンドウを開き、使用しているオペレーティング システムと開発環境についての指示に従います。
SPEECH_KEY環境変数を設定するには、your-key をリソースのキーの 1 つに置き換えます。SPEECH_REGION環境変数を設定するには、your-region をリソースのリージョンの 1 つに置き換えます。
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Note
現在のコンソールで環境変数のみにアクセスする必要がある場合は、環境変数を setx の代わりに set に設定できます。
環境変数を追加した後、コンソール ウィンドウを含め、環境変数を読み取る必要があるプログラムの再起動が必要になる場合があります。 たとえば、Visual Studio をエディターとして使用している場合、サンプルを実行する前に Visual Studio を再起動します。
マイクから音声を認識する
以下の手順に従って、音声認識のためのコンソール アプリケーションを作成します。
同じプロジェクト ルート ディレクトリに SpeechRecognition.java という名前の新しいファイルを作成します。
以下のコードを SpeechRecognition.java にコピーします:
import com.microsoft.cognitiveservices.speech.*; import com.microsoft.cognitiveservices.speech.audio.AudioConfig; import java.util.concurrent.ExecutionException; import java.util.concurrent.Future; public class SpeechRecognition { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" private static String speechKey = System.getenv("SPEECH_KEY"); private static String speechRegion = System.getenv("SPEECH_REGION"); public static void main(String[] args) throws InterruptedException, ExecutionException { SpeechConfig speechConfig = SpeechConfig.fromSubscription(speechKey, speechRegion); speechConfig.setSpeechRecognitionLanguage("en-US"); recognizeFromMicrophone(speechConfig); } public static void recognizeFromMicrophone(SpeechConfig speechConfig) throws InterruptedException, ExecutionException { AudioConfig audioConfig = AudioConfig.fromDefaultMicrophoneInput(); SpeechRecognizer speechRecognizer = new SpeechRecognizer(speechConfig, audioConfig); System.out.println("Speak into your microphone."); Future<SpeechRecognitionResult> task = speechRecognizer.recognizeOnceAsync(); SpeechRecognitionResult speechRecognitionResult = task.get(); if (speechRecognitionResult.getReason() == ResultReason.RecognizedSpeech) { System.out.println("RECOGNIZED: Text=" + speechRecognitionResult.getText()); } else if (speechRecognitionResult.getReason() == ResultReason.NoMatch) { System.out.println("NOMATCH: Speech could not be recognized."); } else if (speechRecognitionResult.getReason() == ResultReason.Canceled) { CancellationDetails cancellation = CancellationDetails.fromResult(speechRecognitionResult); System.out.println("CANCELED: Reason=" + cancellation.getReason()); if (cancellation.getReason() == CancellationReason.Error) { System.out.println("CANCELED: ErrorCode=" + cancellation.getErrorCode()); System.out.println("CANCELED: ErrorDetails=" + cancellation.getErrorDetails()); System.out.println("CANCELED: Did you set the speech resource key and region values?"); } } System.exit(0); } }音声認識言語を変更するには、
en-USを別のen-USに置き換えます。 たとえば、スペイン語 (スペイン) の場合はes-ESを使用します。 言語を指定しない場合、既定値はen-USになります。 話される可能性のある複数の言語の 1 つを識別する方法の詳細については、「言語の識別」を参照してください。新しいコンソール アプリケーションを実行して、マイクからの音声認識を開始します。
javac SpeechRecognition.java -cp ".;target\dependency\*" java -cp ".;target\dependency\*" SpeechRecognition重要
必ず
SPEECH_KEYとSPEECH_REGION環境変数を設定してください。 これらの変数を設定しない場合、サンプルは失敗してエラー メッセージが表示されます。指示されたらマイクに向って話します。 話すことがテキストとして表示されるはずです:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
解説
その他の考慮事項のいくつかを次に示します:
この例では、
RecognizeOnceAsync操作を使用して、最大 30 秒間、または無音が検出されるまでの発話を文字起こししています。 多言語での会話を含め、より長いオーディオの継続的認識については、「音声を認識する方法」を参照してください。オーディオ ファイルから音声を認識するには、
fromDefaultMicrophoneInputの代わりにfromWavFileInputを使用します。AudioConfig audioConfig = AudioConfig.fromWavFileInput("YourAudioFile.wav");MP4 などの圧縮されたオーディオ ファイルの場合は、GStreamer をインストールして、
PullAudioInputStreamまたはPushAudioInputStreamを使います。 詳しくは、「圧縮された入力オーディオを使用する方法」をご覧ください。
リソースをクリーンアップする
Azure portal または Azure コマンドライン インターフェイス (CLI) を使用して、作成した音声リソースを削除できます。
リファレンスドキュメント | パッケージ (npm) | GitHub のその他のサンプル | ライブラリのソース コード
このクイックスタートでは、音声を認識してリアルタイムでテキストに変換するアプリケーションを作成して実行します。
代わりに、オーディオ ファイルを非同期的に文字起こしするには、「バッチ文字起こしとは」を参照してください。 最適な音声テキスト変換ソリューションがわからない場合は、「音声テキスト変換とは」を参照してください。
前提条件
- Azure サブスクリプション。 無料で作成できます。
- Azure ポータルで、音声リソースを作成します。
- Speech リソース キーとリージョンを取得します。 音声リソースがデプロイされたら、[リソースに移動] を選択して、キーを表示および管理します。
また、ローカル コンピューターに .wav オーディオ ファイルも必要です。 独自の .wav ファイル (最大 30 秒) を使用することも、https://crbn.us/whatstheweatherlike.wav サンプル ファイルをダウンロードすることもできます。
環境を設定する
環境を設定するには、Speech SDK for JavaScript をインストールします。 コマンド npm install microsoft-cognitiveservices-speech-sdk を実行します。 詳しいインストール手順については、「音声 SDK のインストール」を参照してください。
環境変数を設定する
Azure AI サービスにアクセスするには、アプリケーションを認証する必要があります。 この記事では、環境変数を使って資格情報を格納する方法について説明します。 その後、コードから環境変数にアクセスして、アプリケーションを認証できます。 運用環境では、資格情報を保存してそれにアクセスする際に、安全性が高い方法を使用します。
重要
Microsoft Entra 認証と Azure リソースのマネージド ID を併用して、クラウドで実行されるアプリケーションに資格情報を格納しないようにすることをお勧めします。
API キーを使用する場合は、それを Azure Key Vault などの別の場所に安全に保存します。 API キーは、コード内に直接含めないようにし、絶対に公開しないでください。
AI サービスのセキュリティの詳細については、「Azure AI サービスに対する要求の認証」を参照してください。
Azure Cognitive Service for Speech リソース キーとリージョンの環境変数を設定するには、コンソール ウィンドウを開き、使用しているオペレーティング システムと開発環境についての指示に従います。
SPEECH_KEY環境変数を設定するには、your-key をリソースのキーの 1 つに置き換えます。SPEECH_REGION環境変数を設定するには、your-region をリソースのリージョンの 1 つに置き換えます。
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Note
現在のコンソールで環境変数のみにアクセスする必要がある場合は、環境変数を setx の代わりに set に設定できます。
環境変数を追加した後、コンソール ウィンドウを含め、環境変数を読み取る必要があるプログラムの再起動が必要になる場合があります。 たとえば、Visual Studio をエディターとして使用している場合、サンプルを実行する前に Visual Studio を再起動します。
ファイルから音声を認識する
ヒント
Azure AI Speech Toolkit を試して、Visual Studio Code でサンプルを簡単にビルドして実行します。
以下の手順に従って、音声認識のための Node.js コンソール アプリケーションを作成します。
新しいプロジェクトを作成するコマンド プロンプト ウィンドウを開き、SpeechRecognition.js という名前の新しいファイルを作成します。
Speech SDK for JavaScript をインストールします。
npm install microsoft-cognitiveservices-speech-sdk以下のコードを SpeechRecognition.js にコピーします:
const fs = require("fs"); const sdk = require("microsoft-cognitiveservices-speech-sdk"); // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" const speechConfig = sdk.SpeechConfig.fromSubscription(process.env.SPEECH_KEY, process.env.SPEECH_REGION); speechConfig.speechRecognitionLanguage = "en-US"; function fromFile() { let audioConfig = sdk.AudioConfig.fromWavFileInput(fs.readFileSync("YourAudioFile.wav")); let speechRecognizer = new sdk.SpeechRecognizer(speechConfig, audioConfig); speechRecognizer.recognizeOnceAsync(result => { switch (result.reason) { case sdk.ResultReason.RecognizedSpeech: console.log(`RECOGNIZED: Text=${result.text}`); break; case sdk.ResultReason.NoMatch: console.log("NOMATCH: Speech could not be recognized."); break; case sdk.ResultReason.Canceled: const cancellation = sdk.CancellationDetails.fromResult(result); console.log(`CANCELED: Reason=${cancellation.reason}`); if (cancellation.reason == sdk.CancellationReason.Error) { console.log(`CANCELED: ErrorCode=${cancellation.ErrorCode}`); console.log(`CANCELED: ErrorDetails=${cancellation.errorDetails}`); console.log("CANCELED: Did you set the speech resource key and region values?"); } break; } speechRecognizer.close(); }); } fromFile();SpeechRecognition.js で、YourAudioFile.wav を独自の .wav ファイルに置き換えます。 この例では、.wav ファイルからの音声のみを認識します。 他の音声形式について詳しくは、「圧縮された入力オーディオを使用する方法」をご覧ください。 この例では、最大 30 秒の音声をサポートしています。
音声認識言語を変更するには、
en-USを別のen-USに置き換えます。 たとえば、スペイン語 (スペイン) の場合はes-ESを使用します。 言語を指定しない場合、既定値はen-USになります。 話される可能性のある複数の言語の 1 つを識別する方法の詳細については、「言語の識別」を参照してください。新しいコンソール アプリケーションを実行して、ファイルからの音声認識を開始します。
node.exe SpeechRecognition.js重要
必ず
SPEECH_KEYとSPEECH_REGION環境変数を設定してください。 これらの変数を設定しない場合、サンプルは失敗してエラー メッセージが表示されます。オーディオ ファイルからの音声は、次のようなテキストとして出力されるはずです。
RECOGNIZED: Text=I'm excited to try speech to text.
解説
この例では、recognizeOnceAsync 操作を使用して、最大 30 秒間、または無音が検出されるまでの発話を文字起こししています。 多言語での会話を含め、より長いオーディオの継続的認識については、「音声を認識する方法」を参照してください。
注意
マイクからの音声認識は、Node.js ではサポートされていません。 これがサポートされているのは、ブラウザー ベースの JavaScript 環境内のみです。 詳細については、GitHub で、React のサンプルとマイクからの音声変換の実装に関するページを参照してください。
React サンプルには、認証トークンの交換と管理のための設計パターンが示されています。 音声テキスト変換のための、マイクまたはファイルからのオーディオのキャプチャについても示されています。
リソースをクリーンアップする
Azure portal または Azure コマンドライン インターフェイス (CLI) を使用して、作成した音声リソースを削除できます。
リファレンス ドキュメント | パッケージ (PyPi) | GitHub のその他のサンプル
このクイックスタートでは、音声を認識してリアルタイムでテキストに変換するアプリケーションを作成して実行します。
代わりに、オーディオ ファイルを非同期的に文字起こしするには、「バッチ文字起こしとは」を参照してください。 最適な音声テキスト変換ソリューションがわからない場合は、「音声テキスト変換とは」を参照してください。
前提条件
- Azure サブスクリプション。 無料で作成できます。
- Azure ポータルで、音声リソースを作成します。
- Speech リソース キーとリージョンを取得します。 音声リソースがデプロイされたら、[リソースに移動] を選択して、キーを表示および管理します。
環境をセットアップする
Speech SDK Python は、Python パッケージ インデックス (PyPI) モジュールとして入手できます。 Speech SDK for Python は、Windows、Linux、macOS との互換性があります。
- Windows で、お使いのプラットフォームに対応した Microsoft Visual Studio の Visual C++ 再頒布可能パッケージ 2015、2017、2019、および 2022 をインストールします。 このパッケージを初めてインストールする場合、再起動が必要になる可能性があります。
- Linux では、x64 ターゲット アーキテクチャを使う必要があります。
Python の 3.7 以降のバージョンをインストールします。 その他の要件については、「音声 SDK のインストール」を参照してください。
環境変数を設定する
Azure AI サービスにアクセスするには、アプリケーションを認証する必要があります。 この記事では、環境変数を使って資格情報を格納する方法について説明します。 その後、コードから環境変数にアクセスして、アプリケーションを認証できます。 運用環境では、資格情報を保存してそれにアクセスする際に、安全性が高い方法を使用します。
重要
Microsoft Entra 認証と Azure リソースのマネージド ID を併用して、クラウドで実行されるアプリケーションに資格情報を格納しないようにすることをお勧めします。
API キーを使用する場合は、それを Azure Key Vault などの別の場所に安全に保存します。 API キーは、コード内に直接含めないようにし、絶対に公開しないでください。
AI サービスのセキュリティの詳細については、「Azure AI サービスに対する要求の認証」を参照してください。
Azure Cognitive Service for Speech リソース キーとリージョンの環境変数を設定するには、コンソール ウィンドウを開き、使用しているオペレーティング システムと開発環境についての指示に従います。
SPEECH_KEY環境変数を設定するには、your-key をリソースのキーの 1 つに置き換えます。SPEECH_REGION環境変数を設定するには、your-region をリソースのリージョンの 1 つに置き換えます。
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Note
現在のコンソールで環境変数のみにアクセスする必要がある場合は、環境変数を setx の代わりに set に設定できます。
環境変数を追加した後、コンソール ウィンドウを含め、環境変数を読み取る必要があるプログラムの再起動が必要になる場合があります。 たとえば、Visual Studio をエディターとして使用している場合、サンプルを実行する前に Visual Studio を再起動します。
マイクから音声を認識する
ヒント
Azure AI Speech Toolkit を試して、Visual Studio Code でサンプルを簡単にビルドして実行します。
以下の手順に従って、コンソール アプリケーションを作成します。
新しいプロジェクトを作成したいフォルダーでコマンド プロンプト ウィンドウを開きます。 speech_recognition.py という名前の新しいファイルを作成します。
次のコマンドを実行して、Speech SDK をインストールします。
pip install azure-cognitiveservices-speech以下のコードを speech_recognition.py にコピーします:
import os import azure.cognitiveservices.speech as speechsdk def recognize_from_microphone(): # This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" speech_config = speechsdk.SpeechConfig(subscription=os.environ.get('SPEECH_KEY'), region=os.environ.get('SPEECH_REGION')) speech_config.speech_recognition_language="en-US" audio_config = speechsdk.audio.AudioConfig(use_default_microphone=True) speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_config) print("Speak into your microphone.") speech_recognition_result = speech_recognizer.recognize_once_async().get() if speech_recognition_result.reason == speechsdk.ResultReason.RecognizedSpeech: print("Recognized: {}".format(speech_recognition_result.text)) elif speech_recognition_result.reason == speechsdk.ResultReason.NoMatch: print("No speech could be recognized: {}".format(speech_recognition_result.no_match_details)) elif speech_recognition_result.reason == speechsdk.ResultReason.Canceled: cancellation_details = speech_recognition_result.cancellation_details print("Speech Recognition canceled: {}".format(cancellation_details.reason)) if cancellation_details.reason == speechsdk.CancellationReason.Error: print("Error details: {}".format(cancellation_details.error_details)) print("Did you set the speech resource key and region values?") recognize_from_microphone()音声認識言語を変更するには、
en-USを別のen-USに置き換えます。 たとえば、スペイン語 (スペイン) の場合はes-ESを使用します。 言語を指定しない場合、既定値はen-USになります。 話される可能性のある複数の言語の 1 つを識別する方法の詳細については、言語の識別に関するページを参照してください。新しいコンソール アプリケーションを実行して、マイクからの音声認識を開始します。
python speech_recognition.py重要
必ず
SPEECH_KEYとSPEECH_REGION環境変数を設定してください。 これらの変数を設定しない場合、サンプルは失敗してエラー メッセージが表示されます。指示されたらマイクに向って話します。 話すことがテキストとして表示されるはずです:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
解説
その他の考慮事項のいくつかを次に示します:
この例では、
recognize_once_async操作を使用して、最大 30 秒間、または無音が検出されるまでの発話を文字起こししています。 多言語での会話を含め、より長いオーディオの継続的認識については、「音声を認識する方法」を参照してください。オーディオ ファイルから音声を認識するには、
use_default_microphoneの代わりにfilenameを使用します。audio_config = speechsdk.audio.AudioConfig(filename="YourAudioFile.wav")MP4 などの圧縮されたオーディオ ファイルの場合は、GStreamer をインストールして、
PullAudioInputStreamまたはPushAudioInputStreamを使います。 詳しくは、「圧縮された入力オーディオを使用する方法」をご覧ください。
リソースをクリーンアップする
Azure portal または Azure コマンドライン インターフェイス (CLI) を使用して、作成した音声リソースを削除できます。
リファレンス ドキュメント | パッケージ (ダウンロード) | GitHub のその他のサンプル
このクイックスタートでは、音声を認識してリアルタイムでテキストに変換するアプリケーションを作成して実行します。
代わりに、オーディオ ファイルを非同期的に文字起こしするには、「バッチ文字起こしとは」を参照してください。 最適な音声テキスト変換ソリューションがわからない場合は、「音声テキスト変換とは」を参照してください。
前提条件
- Azure サブスクリプション。 無料で作成できます。
- Azure ポータルで、音声リソースを作成します。
- Speech リソース キーとリージョンを取得します。 音声リソースがデプロイされたら、[リソースに移動] を選択して、キーを表示および管理します。
環境をセットアップする
Speech SDK for Swift は、フレームワーク バンドルとして配布されています。 このフレームワークでは、iOS と macOS の両方について、Objective-C と Swift の両方がサポートされています。
音声 SDK は、Xcode プロジェクトで CocoaPod として使用することも、直接ダウンロードして手動でリンクすることもできます。 このガイドでは CocoaPod を使用します。 CocoaPod 依存関係マネージャーをそのインストールの手順に従ってインストールします。
環境変数の設定
Azure AI サービスにアクセスするには、アプリケーションを認証する必要があります。 この記事では、環境変数を使って資格情報を格納する方法について説明します。 その後、コードから環境変数にアクセスして、アプリケーションを認証できます。 運用環境では、資格情報を保存してそれにアクセスする際に、安全性が高い方法を使用します。
重要
Microsoft Entra 認証と Azure リソースのマネージド ID を併用して、クラウドで実行されるアプリケーションに資格情報を格納しないようにすることをお勧めします。
API キーを使用する場合は、それを Azure Key Vault などの別の場所に安全に保存します。 API キーは、コード内に直接含めないようにし、絶対に公開しないでください。
AI サービスのセキュリティの詳細については、「Azure AI サービスに対する要求の認証」を参照してください。
Azure Cognitive Service for Speech リソース キーとリージョンの環境変数を設定するには、コンソール ウィンドウを開き、使用しているオペレーティング システムと開発環境についての指示に従います。
SPEECH_KEY環境変数を設定するには、your-key をリソースのキーの 1 つに置き換えます。SPEECH_REGION環境変数を設定するには、your-region をリソースのリージョンの 1 つに置き換えます。
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Note
現在のコンソールで環境変数のみにアクセスする必要がある場合は、環境変数を setx の代わりに set に設定できます。
環境変数を追加した後、コンソール ウィンドウを含め、環境変数を読み取る必要があるプログラムの再起動が必要になる場合があります。 たとえば、Visual Studio をエディターとして使用している場合、サンプルを実行する前に Visual Studio を再起動します。
マイクから音声を認識する
以下の手順に従って、macOS アプリケーションで音声を認識します。
Azure-Samples/cognitive-services-speech-sdk リポジトリを複製して、Swift でマイクからの音声を認識する (macOS) サンプル プロジェクトを取得します。 このリポジトリには、iOS サンプルもあります。
ターミナルで、ダウンロードしたサンプル アプリ (
helloworld) のディレクトリに移動します。pod installコマンドを実行します。 このコマンドにより、サンプル アプリと依存関係としての音声 SDK の両方を含んだ、helloworld.xcworkspaceという Xcode ワークスペースが生成されます。Xcode で
helloworld.xcworkspaceワークスペースを開きます。次に示すように、AppDelegate.swift という名前のファイルを開き、
applicationDidFinishLaunchingメソッドとrecognizeFromMicメソッドを見つけます。import Cocoa @NSApplicationMain class AppDelegate: NSObject, NSApplicationDelegate { var label: NSTextField! var fromMicButton: NSButton! var sub: String! var region: String! @IBOutlet weak var window: NSWindow! func applicationDidFinishLaunching(_ aNotification: Notification) { print("loading") // load subscription information sub = ProcessInfo.processInfo.environment["SPEECH_KEY"] region = ProcessInfo.processInfo.environment["SPEECH_REGION"] label = NSTextField(frame: NSRect(x: 100, y: 50, width: 200, height: 200)) label.textColor = NSColor.black label.lineBreakMode = .byWordWrapping label.stringValue = "Recognition Result" label.isEditable = false self.window.contentView?.addSubview(label) fromMicButton = NSButton(frame: NSRect(x: 100, y: 300, width: 200, height: 30)) fromMicButton.title = "Recognize" fromMicButton.target = self fromMicButton.action = #selector(fromMicButtonClicked) self.window.contentView?.addSubview(fromMicButton) } @objc func fromMicButtonClicked() { DispatchQueue.global(qos: .userInitiated).async { self.recognizeFromMic() } } func recognizeFromMic() { var speechConfig: SPXSpeechConfiguration? do { try speechConfig = SPXSpeechConfiguration(subscription: sub, region: region) } catch { print("error \(error) happened") speechConfig = nil } speechConfig?.speechRecognitionLanguage = "en-US" let audioConfig = SPXAudioConfiguration() let reco = try! SPXSpeechRecognizer(speechConfiguration: speechConfig!, audioConfiguration: audioConfig) reco.addRecognizingEventHandler() {reco, evt in print("intermediate recognition result: \(evt.result.text ?? "(no result)")") self.updateLabel(text: evt.result.text, color: .gray) } updateLabel(text: "Listening ...", color: .gray) print("Listening...") let result = try! reco.recognizeOnce() print("recognition result: \(result.text ?? "(no result)"), reason: \(result.reason.rawValue)") updateLabel(text: result.text, color: .black) if result.reason != SPXResultReason.recognizedSpeech { let cancellationDetails = try! SPXCancellationDetails(fromCanceledRecognitionResult: result) print("cancelled: \(result.reason), \(cancellationDetails.errorDetails)") print("Did you set the speech resource key and region values?") updateLabel(text: "Error: \(cancellationDetails.errorDetails)", color: .red) } } func updateLabel(text: String?, color: NSColor) { DispatchQueue.main.async { self.label.stringValue = text! self.label.textColor = color } } }AppDelegate.m で、音声リソース キーとリージョン用に先ほど設定した環境変数を使用します。
sub = ProcessInfo.processInfo.environment["SPEECH_KEY"] region = ProcessInfo.processInfo.environment["SPEECH_REGION"]音声認識言語を変更するには、
en-USを別のen-USに置き換えます。 たとえば、スペイン語 (スペイン) の場合はes-ESを使用します。 言語を指定しない場合、既定値はen-USになります。 話される可能性のある複数の言語の 1 つを識別する方法の詳細については、「言語の識別」を参照してください。デバッグ出力が表示されるようにするには、[表示]>[デバッグ領域]>[コンソールのアクティブ化] を選択します。
メニューから [製品]、[実行] の順に選択するか、[再生] ボタンを選択して、コード例のビルドや実行を行います。
重要
必ず
SPEECH_KEYとSPEECH_REGION環境変数を設定してください。 これらの変数を設定しない場合、サンプルは失敗してエラー メッセージが表示されます。
アプリのボタンを選択して何か話すと、画面の下の部分に、話しをしたテキストが表示されるはずです。 アプリを初めて実行すると、アプリにコンピューターのマイクへのアクセス権を付与するように求められます。
解説
この例では、recognizeOnce 操作を使用して、最大 30 秒間、または無音が検出されるまでの発話を文字起こししています。 多言語での会話を含め、より長いオーディオの継続的認識については、「音声を認識する方法」を参照してください。
Objective-C
Speech SDK for Object-C は、クライアント ライブラリおよびリファレンス ドキュメントを Speech SDK for Swift と共有しています。 Objective-C コードの例については、GitHub の「macOS 上の Objective-C でマイクからの音声を認識する」を参照してください。
リソースをクリーンアップする
Azure portal または Azure コマンドライン インターフェイス (CLI) を使用して、作成した音声リソースを削除できます。
Speech to Text REST API リファレンス | Speech to Text REST API for short audio リファレンス | GitHub のその他のサンプル
このクイックスタートでは、音声を認識してリアルタイムでテキストに変換するアプリケーションを作成して実行します。
代わりに、オーディオ ファイルを非同期的に文字起こしするには、「バッチ文字起こしとは」を参照してください。 最適な音声テキスト変換ソリューションがわからない場合は、「音声テキスト変換とは」を参照してください。
前提条件
- Azure サブスクリプション。 無料で作成できます。
- Azure ポータルで、音声リソースを作成します。
- Speech リソース キーとリージョンを取得します。 音声リソースがデプロイされたら、[リソースに移動] を選択して、キーを表示および管理します。
また、ローカル コンピューターに .wav オーディオ ファイルも必要です。 独自の .wav ファイル (最大 60 秒) を使用することも、https://crbn.us/whatstheweatherlike.wav サンプル ファイルをダウンロードすることもできます。
環境変数を設定する
Azure AI サービスにアクセスするには、アプリケーションを認証する必要があります。 この記事では、環境変数を使って資格情報を格納する方法について説明します。 その後、コードから環境変数にアクセスして、アプリケーションを認証できます。 運用環境では、資格情報を保存してそれにアクセスする際に、安全性が高い方法を使用します。
重要
Microsoft Entra 認証と Azure リソースのマネージド ID を併用して、クラウドで実行されるアプリケーションに資格情報を格納しないようにすることをお勧めします。
API キーを使用する場合は、それを Azure Key Vault などの別の場所に安全に保存します。 API キーは、コード内に直接含めないようにし、絶対に公開しないでください。
AI サービスのセキュリティの詳細については、「Azure AI サービスに対する要求の認証」を参照してください。
Azure Cognitive Service for Speech リソース キーとリージョンの環境変数を設定するには、コンソール ウィンドウを開き、使用しているオペレーティング システムと開発環境についての指示に従います。
SPEECH_KEY環境変数を設定するには、your-key をリソースのキーの 1 つに置き換えます。SPEECH_REGION環境変数を設定するには、your-region をリソースのリージョンの 1 つに置き換えます。
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Note
現在のコンソールで環境変数のみにアクセスする必要がある場合は、環境変数を setx の代わりに set に設定できます。
環境変数を追加した後、コンソール ウィンドウを含め、環境変数を読み取る必要があるプログラムの再起動が必要になる場合があります。 たとえば、Visual Studio をエディターとして使用している場合、サンプルを実行する前に Visual Studio を再起動します。
ファイルから音声を認識する
コンソール ウィンドウを開き、次の cURL コマンドを実行します。 YourAudioFile.wav をご利用のオーディオ ファイルのパスおよび名前に置き換えます。
curl --location --request POST "https://%SPEECH_REGION%.stt.speech.microsoft.com/speech/recognition/conversation/cognitiveservices/v1?language=en-US&format=detailed" ^
--header "Ocp-Apim-Subscription-Key: %SPEECH_KEY%" ^
--header "Content-Type: audio/wav" ^
--data-binary "@YourAudioFile.wav"
重要
必ず SPEECH_KEY と SPEECH_REGION 環境変数を設定してください。 これらの変数を設定しない場合、サンプルは失敗してエラー メッセージが表示されます。
次に示したような応答が表示されるはずです。 DisplayText は、オーディオ ファイルから認識されたテキストである必要があります。 コマンドは、最大 60 秒のオーディオを認識し、テキストに変換します。
{
"RecognitionStatus": "Success",
"DisplayText": "My voice is my passport, verify me.",
"Offset": 6600000,
"Duration": 32100000
}
詳細については、「Speech to text REST API for short audio」を参照してください。
リソースをクリーンアップする
Azure portal または Azure コマンドライン インターフェイス (CLI) を使用して、作成した音声リソースを削除できます。
このクイックスタートでは、音声を認識してリアルタイムでテキストに変換するアプリケーションを作成して実行します。
代わりに、オーディオ ファイルを非同期的に文字起こしするには、「バッチ文字起こしとは」を参照してください。 最適な音声テキスト変換ソリューションがわからない場合は、「音声テキスト変換とは」を参照してください。
前提条件
- Azure サブスクリプション。 無料で作成できます。
- Azure ポータルで、音声リソースを作成します。
- Speech リソース キーとリージョンを取得します。 音声リソースがデプロイされたら、[リソースに移動] を選択して、キーを表示および管理します。
環境をセットアップする
次の手順を実行し、対象プラットフォームに対する他の要件を Azure Cognitive Service for Speech CLI クイックスタートで確認します。
次の .NET CLI コマンドを実行して、Speech CLI をインストールします。
dotnet tool install --global Microsoft.CognitiveServices.Speech.CLI次のコマンドを実行して、Azure Cognitive Service for Speech リソースのキーとリージョンを構成します。
SUBSCRIPTION-KEYは Speech リソースのキーに、REGIONは Speech リソースのリージョンに置き換えます。spx config @key --set SUBSCRIPTION-KEY spx config @region --set REGION
マイクから音声を認識する
次のコマンドを実行して、マイクからの音声認識を開始します。
spx recognize --microphone --source en-USマイクに向かって話すと、自分が発した言葉がテキストに文字起こしされ、リアルタイムで表示されます。 Azure Cognitive Service for Speech CLI は、無音の状態で一定時間 (30 秒) が経過するか、Ctrl+C キーを押したときに停止します。
Connection CONNECTED... RECOGNIZED: I'm excited to try speech to text.
解説
その他の考慮事項のいくつかを次に示します:
オーディオ ファイルから音声を認識するには、
--microphoneの代わりに--fileを使用します。 MP4 などの圧縮されたオーディオ ファイルの場合は、GStreamer をインストールして、--formatを使います。 詳しくは、「圧縮された入力オーディオを使用する方法」をご覧ください。spx recognize --file YourAudioFile.wav spx recognize --file YourAudioFile.mp4 --format any特定の単語または発話の認識精度を高めるには、フレーズ リストを使用します。 フレーズ リストは、
recognizeコマンドを使用して、インラインで、またはテキスト ファイルで含めます:spx recognize --microphone --phrases "Contoso;Jessie;Rehaan;" spx recognize --microphone --phrases @phrases.txt音声認識言語を変更するには、
en-USを別のen-USに置き換えます。 たとえば、スペイン語 (スペイン) の場合はes-ESを使用します。 言語を指定しない場合、既定値はen-USになります。spx recognize --microphone --source es-ES30 秒よりも長いオーディオを継続的に認識する場合は、
--continuousを追加します。spx recognize --microphone --source es-ES --continuousファイルの入力や出力など、音声認識の他のオプションに関する情報を見るには、次のコマンドを実行します:
spx help recognize
リソースをクリーンアップする
Azure portal または Azure コマンドライン インターフェイス (CLI) を使用して、作成した音声リソースを削除できます。