この記事では、プロフェッショナルな音声微調整のために高品質の音声サンプルを準備する際のベスト プラクティスについて説明します。 データの処理方法とデータ受け入れの最小要件を理解するには、 データのアップロードを参照してください。
高品質のプロの声をゼロから作成することは、カジュアルな作業ではありません。 カスタム音声の中心的なコンポーネントは、人間の音声のオーディオ サンプルの大規模なコレクションです。 これらのオーディオの録音は高品質のものであることが必要です。 この種の録音に参加した経験があるボイス タレントを選び、録音エンジニアの手で、プロフェッショナルの機器を使用してボイス タレントの声を録音します。
ただし、これらの録音を行う前に、オーディオ サンプルを作成するためにボイス タレントが読み上げる台本を用意する必要があります。
小さくても重要な詳細を積み重ねることが、プロフェッショナルな音声録音の実現につながります。 このガイドは、良好で一貫した結果を得るために役立つプロセスのロードマップです。
高品質の音声を実現するためのデータ準備のヒント
非常に自然なカスタム音声は、トレーニング データの品質やサイズなど、いくつかの要因に依存します。
トレーニング データの質は第一の要因です。 たとえば、同じトレーニング セットでは、高品質のカスタム音声を作成するために、一貫した音量、読み上げ速度、読み上げピッチ、スピーキング スタイルが不可欠です。 また、レコーディング時のバックグラウンド ノイズを避け、スクリプトとレコーディングが一致するようにする必要があります。 データの品質を確保するには、スクリプトの選択基準とレコーディングの要件に従う必要があります。
トレーニング データのサイズに関しては、ほとんどの場合、300 個の発話で適切なカスタム音声を作成できます。 テストによると、ほとんどの言語で、トレーニング データを増やしても必ずしも音声自体の自然性が向上するとは限りません (MOS スコアでテスト済み)。ただし、より多くの単語インスタンスをカバーするトレーニング データが増えるほど、異常などの音声の不満足な部分の比率を減らせる可能性が高くなります。 音声の不満足な部分がどのように聞こえるかについては、GitHub の例を参照してください。
場合によっては、固有の特性を持つ音声ペルソナが必要な場合があります。 たとえば、漫画のペルソナには、特殊な話し方の音声や、ダイナミックなイントネーションの音声などが必要です。 このような場合は、少なくとも 1000 (できれば 2000) の発話を準備し、プロのレコーディング スタジオでレコーディングすることをお勧めします。 音声モデルの品質を向上させる方法の詳細については、カスタム音声を 使用するための特性と制限事項を参照してください。
音声録音のロール
カスタム音声録音プロジェクトには、次の 4 つの基本的な役割があります。
| 役割 | 目的 |
|---|---|
| ボイス タレント | このユーザーの声は、カスタム音声の基礎を形成します。 |
| 録音エンジニア | 録音の技術的側面を監督し、録音機器を操作します。 |
| ディレクター | 台本を準備し、ボイス タレントの演技を指導します。 |
| エディター | オーディオ ファイルを最終処理し、Speech サービスにアップロードする準備をします。 |
1 人が複数の役割を兼ねることができます。 このガイドでは、読者がディレクターの役割を務め、ボイス タレントと録音エンジニアの両方を雇うと想定しています。 録音を自分自身で行う場合は、この記事に、録音エンジニアのロールに関する情報がいくらか含まれています。 エディターの役割は録音セッション終了後まで必要とされません。 それまでは、ディレクターまたは録音エンジニアがこの役割を果たすことができます。
ボイス タレントを選択する
ボイス タレントの適任候補は、ボイスオーバー、ボイス キャラクターの仕事、アナウンス、またはニュースの読み上げの経験がある演者です。 好みの自然な声を持ったボイス タレントを選びます。 ユニークな "キャラクター" 音声を作ることは可能ですが、そのような声を一貫して演じることはほとんどのタレントにとって難しく、喉に負担がかかる可能性があります。 ボイス タレントを選ぶにあたって、たった 1 つの最も重要な要素は一貫性です。 同じ音声スタイルのための録音は、すべて同じ日に同じ部屋で録音されたように聞こえる必要があります。 優れた録音の実践とエンジニアリングによって、この理想に近づくことができます。
ボイス タレントは、一貫した速さ、音量、ピッチ、明瞭なディクテーションを含むトーンで話すことができる必要があります。 また、ピッチの変化、感情的な効果、話し方の癖を制御できる必要もあります。 音声サンプルの録音は、他の種類の声の仕事よりも疲労度が大きい可能性があるので、ほとんどのボイス タレントは、1 日に 2 時間から 3 時間だけ録音ができます。 セッションを週に 3 日から 4 日に制限し、可能であれば、間に 1 日の休みを入れてください。
ボイス タレントと協力して、カスタム音声の全体的なサウンドと感情的なトーンを定義するペルソナを開発します。 ペルソナの読み上げスタイルを定義し、ボイス タレントに、必要なスタイルに合った方法で台本を読むように依頼します。 一連のトレーニング データの録音全体を通して、読み上げスタイルの一貫性が保たれるようにします。
たとえば、もともと明るいパーソナリティを持つペルソナは、その声にも楽観的な調子を帯びます。 ただし、一連のトレーニング データのすべての録音でこのパーソナリティが一貫して現れる必要があります。 既存の音声を聞いて、何を目指しているのかを把握します。
ヒント
自分が行う音声録音は自分が主導権を持ちたいと考えるのが普通です。 ボイス タレントはプロジェクトの雇用契約に従う必要があります。
台本を作成する
カスタム音声録音セッションの開始点は、音声タレントが話す発話を含むスクリプトです。 "発話" という用語には、文全体と短いフレーズの両方が含まれます。 カスタム音声を作成するには、トレーニング データとして少なくとも 300 個の録音された発話が必要です。
台本内の発話は、フィクション、ノンフィクション、スピーチのトランスクリプト、ニュース レポート、印刷形態で利用可能なその他の資料など、あらゆる場所から取得できます。 考えられる法的な問題の簡単な説明については、「合法性」のセクションを参照してください。 独自のテキストを記述することもできます。
発話は、同じソースや同じ種類のソースに由来する必要はなく、相互に関連がある必要もありません。 ただし、「ログインに成功しました」のような定型句を音声アプリケーションで使用する場合は、必ずそれらを台本に含めてください。 これにより、カスタム音声でそれらのフレーズを発音する可能性が高くなります。
録音台本には、一般的な文とドメイン固有の文の両方を含めることをお勧めします。 たとえば、2,000 個の文を録音する場合、それらのうちの 1,000 個は一般的な文とし、あとの 1,000 個は、対象ドメインからの文か、アプリケーションのユース ケースにすることができます。
各言語の 'General'、'Chat'、'Customer Service' の各ドメインのサンプル台本が用意されており、録音台本の準備に役立てられます。 これらの Microsoft 共有台本を直接録音に使用することも、独自に作成するための参考として使用することもできます。
台本の選択条件
プロの音声微調整に適したコーパス (録音されたオーディオ サンプル) を作成するために従うことができる一般的なガイドラインを次に示します。
ほとんどのユース ケースでは、文の長さは 2 ~ 15 秒にすることをお勧めします。ラテン語ベースの言語の場合は 5 ~ 30 語、ラテン語以外の言語の場合は 4 ~ 80 語です。 スクリプトのバランスを取り、さまざまな文の種類と長さを含めます。 スクリプトに重複する文が含まれていないことを確認します。
ユース ケースで、質問、感嘆符、特に長い文と短い文の組み合わせに重点を置く必要がある場合は、非常に短い語句と最大 20 秒の長さの語句と共に、質問や感嘆符として文の適切な部分を含めるのが推奨されます。
さまざまな文の種類のバランスを取る方法については、次の表を参照してください。
文の種類 対象範囲 ステートメント文 ステートメント文は、台本の 70% から 80% にする必要があります。 短い単語または語句 短い単語または語句の台本は、発話の合計の約 10% にする必要があり、ケースごとに 5 個から 7 個の単語にします。
短い単語または語句は、読み上げ中に一時停止するように音声タレントに思い出させるために、コンマで区切る必要があります。質問文 (省略可能) 質問文は、ドメイン台本の約 10% から 20% にする必要があり、5% から 10% の上昇調と 5% から 10% の下降調を含めます。
生成された音声に質問を正確に伝える場合は、これらの文が必要です。感嘆文 (省略可能) 感嘆文は、台本の約 10% から 20% にする必要があります。
生成された音声に感嘆符を正確に伝える場合は、これらの文が必要です。注
言語に基づいて 1 秒あたりの単語数を想定することで、文内の単語数を推定できます。
ベスト プラクティスには次のようなものがあります。
- 動詞、名詞、形容詞など、品詞のバランスよく含めます。
- 発音をバランスよく含めます。 A から Z までのすべての文字を含めます。これにより、テキスト読み上げエンジンは、ご自身のスタイルで各文字を発音する方法を学習できます。
- 読み上げる話者にとって読みやすく、理解できる、常識的な台本にします。
- 単語またはフレーズの類似パターン ("easy" や "easier" など) が多くなりすぎないようにします。
- すべての文の種類で、住所、単位、電話、数量、日付など、さまざまな形式の数値を含めます。
- カスタム音声で読み上げられる内容の場合は、綴りの文を含めるようにします。 たとえば、"Apple のスペルは A P P L E" のようにします。
注
より自然なイントネーションとより優れた会話機能を提供するコンテキスト処理モードの場合:
- 記録には文レベルのテキストではなく、段落レベルのテキストを使用します。 このアプローチは、文間の自然な音声フローをキャプチャし、コンテキスト情報を保持するのに役立ちます。
- 各録音は、理想的には 30 秒より長くする必要があります (ラテン語ベースの言語では 60 語以上、ラテン語以外の言語では 160 語を含む)。
- 30 分を超える合計オーディオまたは 300 個の発話を含むコンテキスト トレーニング セットは、カスタム音声のトレーニングに使用できます。
複数の文を 1 行または 1 つの発話に配置しないようにします。 発話で各台詞を分離します。
文が明確であるようにします。 一般に、数値や省略形などの標準以外の単語は読みにくいため、含めすぎないようにします。 一部のアプリケーションでは、多くの数値や頭字語の読み上げが必要な場合があります。 こうした場合、これらの単語を含めることはできますが、それらを音声形式で正規化します。
次に、いくつかのベスト プラクティスの例を示します。
- 省略形を含む台詞の場合、"BTW" ではなく、"by the way" と書きます。
- 数字を含む台詞の場合、"911" ではなく、"9 1 1" と書きます。
- 頭字語を含む台詞の場合、"ABC" ではなく、"A B C" と書きます。
そのようにして、ボイス タレントがこれらの単語を期待どおりに発音するようにしてください。 トレーニング プロセス中、台本と録音が一致する状態に保ちます。
台本には、多くの異なる言葉および文を、また、さまざまな長さ、構造、叙法の文を含める必要があります。
台本の誤りを注意深くチェックします。 可能であれば、他の人にもチェックしてもらいます。 ボイス タレントと一緒に台本をリハーサルすると、さらに誤りを見つけられる可能性があります。
ボイス タレント スクリプトとトレーニング スクリプトの違い
トレーニング スクリプトは、ボイス タレント スクリプトとは異なる場合があります。特に、数字、記号、省略形、日付、時刻を含むスクリプトの場合です。 ボイス タレント用に準備された台本は、ネイティブの読み上げの慣例 (50% や $45 など) に従う必要があります。 トレーニングに使用するスクリプトは、50 パーセントや 45 ドルなど、オーディオ録音と一致するように正規化する必要があります。
注
GitHub のボイス タレント用のサンプル スクリプトをいくつか提供します。 サンプル スクリプトをトレーニングに使用するには、ファイルをアップロードする前に、ボイス タレントの録音に従って正規化する必要があります。
次の表は、ボイス タレントのスクリプトとトレーニング用の正規化されたスクリプトの違いを示しています。
| カテゴリ | ボイス タレント スクリプトの例 | トレーニング スクリプトの例 (正規化) |
|---|---|---|
| 数字 | 123 | 百二十三 |
| シンボル | 50% | 50 パーセント |
| 省略形 | 至急 | できるだけ早く |
| 日付と時刻 | 3月3日 17:00 | 3 月 3 日午後 5 時 |
よくある台本の欠陥
台本の品質が低いと、トレーニング結果に悪影響を及ぼす可能性があります。 高品質のトレーニング結果を得るには、欠陥を回避することが重要です。
台本の欠陥は通常、次のカテゴリに分類されます。
| カテゴリ | 例 |
|---|---|
| 意味のないコンテンツ。 | "無色の緑のアイデアが猛烈に眠ります。" |
| 文が不完全。 | - "これが私の最後のイブでした" (主題がない、具体的な意味がない) - "彼らは既に面白い (末尾に引用符がなく、完全な文ではない) |
| 文の入力ミス。 | - 小文字で始まる - 必要な場合に終了句読点がない - スペルミス - 句読点がない: 末尾にピリオドがない (ニュース タイトルを除く) - 末尾にコンマ、質問、感嘆符を除く記号がある - 次のような間違った形式 - 45$ ($45 のはず) - 単語または句読点の間にスペースがない、または余分なスペースがある |
| 類似した形式に重複がある。パターンごとに 1 つで十分です。 | - "現在ニューヨークは午後 1 時です" - "現在ニューヨークは午後 2 時です" - "現在ニューヨークは午後 3 時です" - "現在シアトルは午後 1 時です" - "現在ワシントン D.C. は午後 1 時です" |
| 一般的でない外国語: 台本で使用できるのは、一般的に使用されている外国語のみです。 | 英語では、一般的なスピーチでフランス語の "faux" を使用する可能性はありますが、"coincer la bulle" のようなフランス語の表現は珍しいでしょう。 |
| 絵文字やその他の一般的でない記号 |
台本の書式
台本は録音セッション中に使用するものであるため、扱いやすい任意の形式にまとめることができます。 Speech Studio で別途必要とされるテキスト ファイルを作成します。
基本的な台本書式には 3 つの列が含まれます。
- 1 から始まる発話番号。 番号を付けることで、(「356 番をもう一度言ってみましょう」のように) スタジオ内の誰もが特定の発話を容易に参照できます。 Microsoft Word の段落番号機能を使用して、テーブルの行に自動的に番号を付けることができます。
- 完了した録音から発話を見つけやすくするために、各発話のテイク番号またはタイム コードを書き込む空の列。
- 発話そのもののテキスト。
注
ほとんどのスタジオでは、"テイク" と呼ばれる短いセグメントで録音を行います。 各テイクには通常、10 から 24 の発話が含まれます。 後から発話を見つけるためには、テイク番号をメモしておくだけで十分です。 より長めの録音を好むスタジオで録音する場合は、代わりにタイム コードをメモすることができます。 スタジオには、よく目立つ時間表示があります。
それぞれの行の後に、メモを書き込むための十分なスペースを残します。 複数のページにまたがった発話がないことを確認してください。 ページ番号を付けて、台本を用紙の片面に印刷します。
台本は 3 部印刷します。1 部はボイス タレント用、1 部は録音エンジニア用、1 部はディレクター (自分) 用です。 ホチキスの代わりにペーパー クリップを使用してください。経験を積んだボイス アーティストは、ページをめくるときに音が立たないよう、ページをばらばらにします。
ボイス タレント ステートメント
ニューラル音声をトレーニングするには、音声データの使用に同意した音声タレントによって記録されたオーディオ ファイルを含む音声 タレント プロファイルを作成 して、プロの音声モデルを微調整する必要があります。 録音の台本を準備するときは、ステートメント文を必ず含めてください。
合法性
著作権法下では、著作権で保護されたテキストを演者が読み上げることは、作品の著者に対価の支払いが発生する実演とみなされる場合があります。 このパフォーマンスは、最終製品であるカスタム音声では認識できません。 とはいえ、著作権で保護された作品をこの目的のために使用することの合法性は十分に確立されていません。 Microsoft はこの問題に関する法律上の助言を提供できません。ご自身の弁護士に相談してください。
幸いにも、これらの問題を全面的に回避することは可能です。 許可またはライセンスなしで使用できる多くのテキスト ソースがあります。
| テキスト ソース | 説明 |
|---|---|
| CMU Arctic コーパス | 著作権切れの作品から抜粋された約 1,100 の文で、特に音声合成プロジェクトで利用されます。 優れた出発点です。 |
| 著作権が 切れた作品 |
一般的には、1923 年よりも前に出版された作品です。 英語の場合、Project Gutenberg でそのような作品が数万点提供されています。 言葉遣いが近代英語に近いため、より新しい作品を重視するとよいでしょう。 |
| 政府機関の著作物 | 米国政府によって作成された著作物は米国内では著作権で保護されませんが、他の国または地域においては政府が著作権を主張する可能性があります。 |
| パブリック ドメイン | 著作権が明示的に放棄されているか、パブリック ドメインで公開されている著作物。 一部の法域では著作権の完全放棄が不可能な場合があります。 |
| 寛大なライセンスの著作物 | クリエイティブ コモンズや GNU Free Documentation License (GFDL) などのライセンス下で配布される著作物。 Wikipedia は GFDL を使用しています。 ただし、一部のライセンスでは、カスタム音声モデルの作成に影響する可能性があるライセンスコンテンツのパフォーマンスに制限が課される場合があるため、ライセンスをよくお読みください。 |
台本の録音
音声の仕事に特化したプロの録音スタジオで台本を録音してください。 そのようなスタジオは、録音ブースと適切な機器を備え、機器を操作する適任のスタッフを擁しています。 録音コストを抑えようとしすぎないことをお勧めします。
プロジェクトについてスタジオの録音エンジニアと話し合い、エンジニアのアドバイスを聞きます。 録音ではダイナミック レンジ圧縮をほとんど、または一切使用しないでください (最大4:1)。 オーディオは音量が一貫していて、信号対雑音比が高く、不要な音が入っていないことが重要です。
録音の要件
高品質のトレーニング結果を得るには、録音またはデータの準備中に次の要件に従います。
明確ではっきり発音される
自然な速度: オーディオ ファイル間で速度が遅すぎたり速すぎたりしない。
適度な音量、韻律、区切り: 同じ文内または文間で安定しており、句読点の区切り方が正しい。
録音中のノイズなし
ペルソナの設計に合わせる
アクセントの間違いがない: ターゲットの設計に適合させる
間違った発音がない
次の仕様を参照して、ベスト プラクティスとしてオーディオ サンプルを準備できます。
| プロパティ | 値 |
|---|---|
| ファイル形式 | *.wav、モノラル |
| サンプリング レート | 24 KHz |
| サンプル形式 | 16 ビット、PCM |
| ピーク ボリューム レベル | -3 dB から -6 dB |
| SNR | > 35 dB |
| 無音 | - 最初と最後に 200 ミリ秒を超えない何らかの無音 (100 ミリ秒をお勧めします) が必要 - 単語間または文の間の無音が -30 dB 未満 - 最後の単語の発話後の波動の無音が -60 dB 未満 |
| 環境ノイズまたはエコー | - 発話前の波動の先頭のノイズ レベルが -70 dB 未満 |
注
48 KHz 24 ビット PCM の形式など、より高いサンプリング レートとビット深度で録音できます。 プロの音声を微調整する際に、周波数を 24 KHz 16 ビット PCM に自動的にダウンサンプリングします。
高い信号雑音比 (SNR) は、オーディオのノイズが低いことを示します。 一般に、専門スタジオでの録音によって、SNR が 35 以上に達するようにすることができます。 SNR が 20 未満のオーディオでは、生成される音声に明らかなノイズが含まれる可能性があります。
発音スコアが低い場合や SNR が悪い場合は、発話を録音し直すことを検討してください。 再録音できない場合は、それらの発話をデータから除外することを検討してください。
一般的なオーディオ エラー
高品質のトレーニング結果を得るためには、オーディオ エラーを回避することを強くお勧めします。 オーディオ エラーは通常、次のカテゴリに分類されます。
音声ファイル名が台本 ID と一致しません。
WAR ファイルの形式が無効であるため、読み取ることができません。
音声のサンプリング レートが 16 KHz を下回っています。 .wav ファイルのサンプリング レートは、高品質のニューラル音声の 24 KHz 以上にすることをお勧めします。
ボリューム のピークが、-3 dB (最大ボリュームの 70%) から -6 dB (50%) の範囲内にありません。
波形のオーバーフロー: 波形は、ピーク値でカットされるため、完全ではありません。
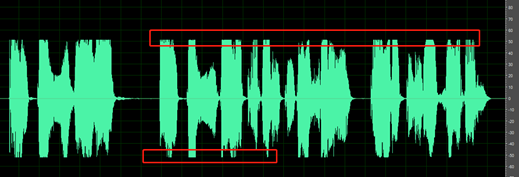
録音の無音部分がクリーンではありません。周囲の雑音、口のノイズ、エコーなどの音が聞こえます。
たとえば、次のオーディオには、音声間に環境ノイズが含まれています。
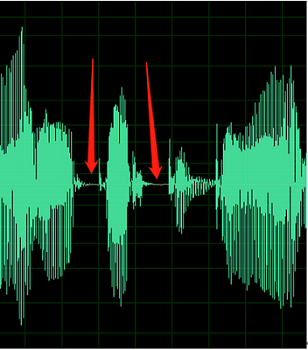
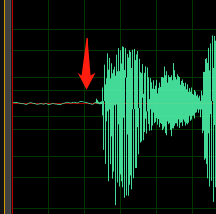
以下のサンプルには、DC オフセットまたはエコーの形跡が含まれています。
全体的にボリュームが低すぎます。 ボリュームが -18 dB (最大ボリュームの 10%) 未満の場合、データは問題ありとしてタグ付けされます。 すべてのオーディオ ファイルが同じボリューム レベルで一貫性を持つ必要があります。
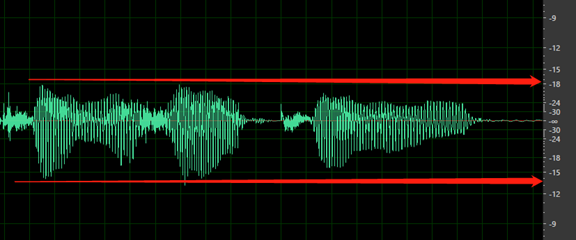
最初の単語の前または最後の単語の後に無音がありません。 また、先頭または末尾の無音を 200 ミリ秒より長くしたり、100 ミリ秒より短くしたりしないでください。
自分で実行する
ここでは、録音スタジオに行かず自力で録音したい方のために、基本的な手順を概説します。 自宅録音やポッドキャスティングが普及したおかげで、録音に関する良いアドバイスやリソースをオンラインで見つけることは以前よりずっと簡単になっています。
"録音ブース" には、顕著なエコーまたは "ルーム トーン" がない小部屋を使用してください。できる限りの静かさと防音性を確保してください。 厚手のカーテンで壁を覆うことで、エコーを減らし、部屋の音を中和するか "減衰させる" ことができます。
音声録音用の高品質スタジオ コンデンサー マイクを使用します。 Sennheiser、AKG、さらには最近の Zoom マイクを使用すると良い結果が得られます。 マイクは購入することも、近くの音響映像機器レンタル会社からレンタルすることもできます。 USB インターフェイスが付いたものを探します。 このタイプのマイクは、利便性のために、マイク エレメント、プリアンプ、アナログ/デジタル コンバーターを 1 つのパッケージにまとめて接続を簡素化しています。
アナログ マイクを使用することもできます。 多くのレンタル会社には、ボイス キャラクターで有名な "ヴィンテージ" マイクが用意されています。 プロ用のアナログ機器では、コンシューマー機器で使用されている 1/4 インチ プラグではなく、バランスド XLR コネクターを使用しています。 アナログの場合、これらのコネクターを備えたプリアンプとコンピューター オーディオ インターフェイスも必要になります。
スタンドまたはブーム上にマイクを設置し、マイクの前にポップ フィルターを設置して、"p" や "b" のような "破裂音" の子音のノイズを除去します。一部のマイクには、スタンドの振動からマイクを守るサスペンション マウントが付属し、これが役に立ちます。
ボイス タレントはマイクから一定の距離を保つ必要があります。 床にテープを貼って、どこに立てばよいかの目印にします。 タレントが着席を希望する場合、特に注意を払ってマイクの距離を調整し、椅子が音を立てないようにします。
台本を保持するスタンドを使用します。 マイクに向かって音が反射するようなスタンドの角度を避けます。
録音機器を操作する人 (録音エンジニア) は、タレントとは別の部屋にいて、何らかの方法で録音ブース内のタレントと話をする必要があります ("トークバック回路")。
録音にできるだけノイズが入らないようにして、80 dB 以下を目標にしてください。
"ブース" 内で無音を録音したものをよく聴いて、ノイズの発生源を特定し、原因を取り除きます。 ノイズの発生源としてよくあるのは、通気孔、蛍光灯の安定器、近くの道路の交通、機器のファン (ノートブック PC にもファンが付いている場合があります) などです。 マイクとケーブルが近くの AC 配線から電気的ノイズ (通常、ハムまたはバズ) を拾うことがあります。 バズは、接地ループによって発生することもあります。これは、機器を複数の電気回路に接続していることによって発生します。
ヒント
状況によっては、イコライザーやノイズ リダクション ソフトウェア プラグインを使用して録音からノイズを除去できる場合がありますが、最善なのは常に、発生源でノイズを止めることです。
デジタル録音の利用可能ダイナミック レンジのほとんどがオーバードライブなしで使用されるようにレベルを設定してください。 これは、オーディオの音量を大きく設定しますが、ゆがみが生じるほどは大きくしないことを意味します。 次のイメージに、良好な録音の波形の例を示します。
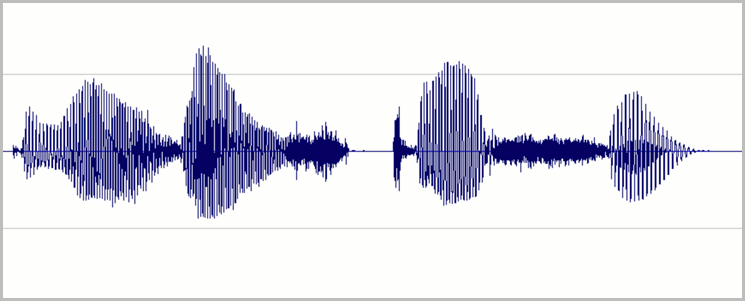
ここでは、レンジ (高さ) のほとんどが使用されていますが、信号の最高ピークはウィンドウの上端または下端に届きません。 録音中の無音部分が細い水平線に近似し、低いノイズ フロアを示していることも確認できます。 この録音のダイナミック レンジと信号対雑音比は許容範囲内です。
使用しているマイクによっては、高品質のオーディオ インターフェイスまたは USB ポートを介してコンピューターに直接録音します。 アナログの場合、マイク、プリアンプ、オーディオ インターフェイス、コンピューターというシンプルなオーディオ チェーンを維持します。 Avid Pro Tools と Adobe Audition はどちらも、手頃な料金で月単位のライセンスを購入できます。 予算が極端に厳しい場合は、無料の Audacity を試してみてください。
44.1 KHz 16 ビット モノラル (CD 品質) 以上で録音します。 機器でサポートされている場合、現在の最先端は 48 KHz 24 ビットです。 Speech Studio に提出する前に、オーディオを 24 KHz 16 ビットにダウンサンプリングします。 それでも、編集が必要な場合には、オリジナルの録音が高品質であることのメリットはあります。
ディレクター、エンジニア、タレントはそれぞれ別の人物が務めるのが理想的です。 何もかも自分一人でやろうとしないでください。 ピンチの場合は、1 人がディレクターとエンジニアの両方を務められます。
セッションの前に
スタジオでの時間を無駄にしないよう、録音セッションの前にボイス タレントと一緒に台本をリハーサルしてください。 ボイス タレントがテキストに慣れてくると、使い慣れない言葉を明瞭に発音できるようになります。
注
ほとんどの録音スタジオの録音ブースでは、台本の電子表示を提供します。 この場合、台本のドキュメントにリハーサルのメモを直接入力します。 それでも、ディレクターはセッション中にメモを取るために紙のコピーが欲しくなるでしょう。 ほとんどのエンジニアもハード コピーを欲しがります。 そして、コンピューターがダウンした場合のタレント用のバックアップとして、3 部目の印刷コピーがやはり欲しくなるでしょう。
発話の中のどの言葉を強調してほしいか、つまり "operative word" (最も重要な言葉) をボイス タレントから質問される場合があります。 何も強調せず自然に読んでほしい、と伝えます。 強調は音声が合成されるときに追加できます。オリジナルの録音に含めるべきではありません。
言葉をはっきり発音するように、タレントに指示します。 台本のすべての言葉が、書かれているとおりに発音される必要があります。 台本でそのように書かれている場合を除き、日常会話でよくあるように音を省略したり、早口であいまいに言ったりしてはなりません。
| 書かれているテキスト | 望ましくないくだけた発音 |
|---|---|
| 決してあなたをあきらめるつもりはありません | 決してあなたをあきらめるつもりはありません |
| 4 つのライトがある | 4 つのライトがある |
| 今日の天気はどう? | 今日の天気 |
| 私の小さな友人に挨拶 | 私の小さな友達に挨拶して |
タレントは単語の間に明確な間を入れないようにしてください。 少し堅苦しく聞こえたとしても、文が自然に流れるようにしてください。 この微妙な区別を正しく理解するには練習が必要かもしれません。
録音セッション
セッションの始めに、典型的な発話のリファレンス録音、またはマッチ ファイルを作成します。 約 1 ページごとにこの台詞を反復するよう、タレントに依頼してください。 毎回、新しい録音をリファレンスと比較します。 この練習は、タレントが音量、テンポ、ピッチ、イントネーションの一貫性を保つのに役立ちます。 一方エンジニアは、音のレベルと全体的な一貫性のリファレンスとしてマッチ ファイルを使用できます。
マッチ ファイルは特に、休憩後または別の日に録音を再開するときに重要です。 タレントのためにマッチ ファイルを何回か再生し、十分に一致するまで毎回、タレントにマッチ ファイルを反復してもらいます。
特定のスタイルでコーパスを記録するには、目的のスタイルを示すスクリプトを慎重に選択します。 録音中に、ボイス タレントがボリューム、テンポ、ピッチ、トーンの一貫性を維持し、意図したスタイルを体現する録音を実現します。
各発話の前に深呼吸して少し間を取るように、タレントを指導します。 発話の間に 2 ~ 3 秒の無音を録音します。 単語は、コンテキストを考慮にいれて、現れるたびに同じように発音される必要があります。 たとえば、動詞としての "録音する" の発音は、名詞としての "録音" とは異なります。
最初の録音の前に約 5 秒の無音を録音して "ルーム トーン" をキャプチャします。 これを実行しておくと、Speech Studio が録音内のノイズを補正するときに役立ちます。
ヒント
キャプチャーする必要があるのはボイス タレントなので、彼らの台詞だけのモノラル (シングル チャンネル) 録音を行うことができます。 ただし、ステレオで録音する場合、特定の台詞またはテイクについての議論を把握するために、2 番めのチャンネルを使用してコントロール ルームの会話を録音できます。 Speech Studio にアップロードされるバージョンからこのトラックを削除します。
ヘッドフォンを使って、ボイス タレントの演技をよく聴きます。 期待するのは、ディクテーションがうまくかつ自然で、発音が正確で、不要な音が含まれていないことです。 これらの基準を満たさない発話の録り直しをタレントに依頼することを遠慮しないでください。
ヒント
多数の発話を使用している場合、1 つの発話が結果のカスタム音声に顕著な影響を与えない可能性があります。 問題のある発話をメモし、それらをデータセットから除外し、カスタム音声がどのように判明するかを確認する方が便利な場合があります。スタジオに戻って、後で見逃したサンプルを記録することができます。
各発話の台本上のテイク番号またはタイム コードをメモします。 録音のメタデータやキュー シートでも、各発話にマークを付けるようエンジニアに依頼します。
ボイス タレントの声を良い状態に保つために、定期的に休憩を取り、飲み物を提供します。
セッション後
最新の録音スタジオはコンピューターでデータを管理します。 セッションの終了後、テープではなく 1 つ以上のオーディオ ファイルを受け取ります。 これらのファイルはおそらく、CD 品質 (44.1 KHz 16 ビット) 以上の WAV または AIFF 形式です。 24 KHz 16 ビットが一般的であり、望ましいものです。 カスタム音声の既定のサンプリング レートは 24 KHz です。 トレーニング データには、24 KHz 以上のサンプル レートを使用することをお勧めします。 通常、それよりも高い 96 KHz などのサンプリング レートは必要ありません。
Speech Studio では、提供される個々の発話が個別のファイルに入っている必要があります。 スタジオから渡される各オーディオ ファイルには、複数の発話が含まれています。 したがって、最重要なポストプロダクション タスクは、録音を分割して提出の準備をすることです。 各発話の開始位置を示すために、録音エンジニアがファイル内にマーカーを配置 (または別個のキュー シートが提供) している可能性があります。
メモを使用して目的のテイクを探し、Avid Pro Tools、Adobe Audition、無料の Audacity などのサウンド編集ユーティリティを使用して、各発話を新しいファイルにコピーします。
各ファイルを注意深く聴きます。 この段階で、台詞前の小さな唇の音など、録音中は気付かなかった小さい不要な音を編集で除去することができますが、実際の音声まで削除しないよう注意してください。 ファイルを修正できない場合は、データ セットからそのファイルを削除し、そうしたことをメモしてください。
保存する前に、各ファイルを 16 ビット、サンプル レート 24 KHz 以上に変換し、スタジオの会話を録音した場合は、2 番目のチャンネルを削除します。 各ファイルを WAV フォーマットで保存し、台本内の発話番号でファイルに名前を付けます。
最後に、各 WAV ファイルを対応する発話のテキスト バージョンに関連付けるトランスクリプトを作成します。 音声モデルのトレーニングには、必要なフォーマットの詳細が含まれています。 テキストは台本から直接コピーできます。 次に、WAV ファイルとテキスト トランスクリプトの Zip ファイルを作成します。
後で必要な場合に備えて、オリジナルの録音を安全な場所に保管します。 台本とメモも保存しておきます。
次のステップ
録音をアップロードしてカスタム音声を作成する準備ができました。